项目结项后的运维阶段是确保软件持续稳定运行、修复问题、满足用户需求的关键时期。在这个阶段,需要建立有效的维护制度,关注各种问题,并采取相应措施来保障系统的可靠性和可持续性。
1 运维团队
开展服务运维工作,首先需要组建运维团队。大体上,根据角色和职责的不同,担任运维任务的人员包括如运维经理、运维工程师、数据库管理员等,不同的角色,对职责和技能要求也有差异。

根据软件系统的规模和复杂性,确定所需的运维人员数量。可以考虑运维团队的规模和组织结构,例如是否需要分为多个小组负责不同的系统或模块。如果项目比较大,系统比较庞杂,就需要组建一个大一些的团队,并招聘具备相关技能和经验的人员,例如具有系统运维、网络管理、数据库管理等方面的知识和经验。可以根据具体的技术栈和需求设置招聘条件。如果系统相对比较简单,也可以有一个技术较全面的人或者沟通能力较强的人,作为和用户沟通的接口,来处理运维问题。
另外,还需要建立良好的团队协作和沟通机制,例如定期开会、使用协同工具和项目管理工具等,以确保团队成员之间的信息流畅和协作高效。也可以根据团队的实际需求和资源情况,考虑外包或合作的方式,例如将一部分运维工作外包给专业的服务提供商,以减轻团队的工作压力。
根据具体项目的情况和团队的需求,可以根据以上原则进行调整和定制,以形成适合自己团队的运维组建方案。
2 故障处理和问题解决
运维一个重要工作内容,就是解决用户在使用软件中碰到的各类问题,特别是结项后的早期,还有一个磨合时间,用户的问题一般也会比较多,这时候就需要投入较多的人力物力来保障系统的正常运行。一般情况下,早期可以指派专人驻场开展技术指导和问题解决,等系统稳定后,再通过远程指导解决。
具体来说,运维人员接收用户或系统监控系统的故障报告,记录故障的详细信息,包括故障发生的时间、具体现象和影响等。然后通过分析故障报告和相关日志信息,确定故障的具体原因和影响范围,以便进一步处理。根据故障的原因和影响,采取相应的措施进行故障恢复,例如重新启动服务、修复代码或配置、切换备用系统等。
处理用户的问题反馈,通过与用户沟通和分析,找出问题的根本原因,并提供解决方案或建议。对于紧急情况,需要迅速响应并采取紧急措施,以最快速度恢复系统的正常运行。对每个故障进行记录和分析,形成故障处理报告,以便后续的故障预防和改进。建立和维护运维知识库和文档,包括故障处理记录、常见问题解决方案等,以便于团队成员之间的知识共享和沉淀。
3 运维工具
运维人员在工作中,通常都会使用一些工具软件,软件项目运维工具有很多,以下列举一些常见的工具。
Ansible:自动化运维工具,可以用于配置管理、应用部署和任务执行等。
Puppet:自动化运维工具,可以用于配置管理和应用部署等。
Chef:自动化运维工具,可以用于配置管理和应用部署等。
Jenkins:持续集成工具,可以用于自动化构建、测试和部署等。
GitLab CI/CD:集成开发和持续部署平台,可以用于代码管理和自动化构建、测试和部署等。
Docker:容器化平台,可以用于应用的打包和部署,提供了快速、轻量和可移植的运行环境。
Kubernetes:容器编排平台,可以用于管理和调度容器化应用,提供了高可用性和弹性扩展的能力。
ELK Stack:日志管理工具,包括Elasticsearch、Logstash和Kibana,可以用于收集、分析和可视化日志数据。
Grafana:监控和可视化工具,可以用于实时监控和展示系统的指标和性能数据。
Nagios:网络和系统监控工具,可以用于实时监控和告警系统的状态和性能。
Zabbix:网络和系统监控工具,可以用于实时监控和告警系统的状态和性能。
Prometheus:监控和告警工具,可以用于收集、存储和查询系统的指标数据,提供了强大的告警和自动化操作的能力。
这些工具可以根据项目的需求和团队的技术栈选择和组合使用,以提高运维工作的效率和质量。
4 系统监控
在运维过程中,工作人员都会对系统进行监控,通过监控数据,运维人员能够对系统的运行状况有一个较好的了解,也可以通过监控数据的分析,对系统进行优化和完善。
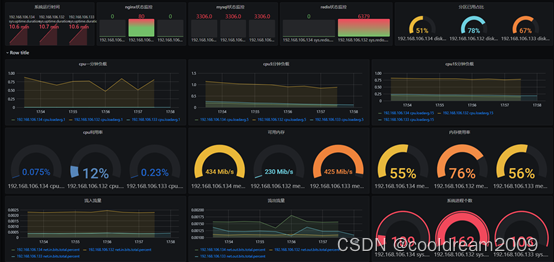
系统监控,首先要确定需要监控的关键指标,包括系统性能、资源利用率、服务可用性等。根据项目需求和业务特点,选择合适的监控指标。其次选择适合项目的监控工具,如Prometheus、Grafana、Zabbix等,用于收集、存储和展示监控数据。配置监控工具,收集系统各项指标的数据。可以通过Agent、API、日志等方式收集数据,并确保数据的准确性和完整性。然后对监控数据进行分析和统计,识别系统的异常和潜在问题。可以使用数据可视化工具,如Grafana,进行实时监控和分析。
根据监控数据的分析结果,设置合适的报警规则。当系统出现异常或达到预设的阈值时,触发报警通知,及时采取措施进行处理。选择合适的报警通知方式,如邮件、短信、即时通讯工具等,确保报警信息能够及时传达给相关人员。根据实际情况,对报警规则进行优化和调整。同时,及时反馈报警信息给相关团队,促进问题的解决和系统的优化。
通过对软件项目系统的实时监控和及时报警,提高系统的可靠性和稳定性。同时,通过对监控数据的分析和优化,可以及时发现潜在问题,预防系统故障的发生。
5 变更管理
运维人员在对用户提供给技术支持的过程中,会碰到各种不同的问题,用户在使用系统的实践过程中,也会思考系统如何调整才能更好的服务业务需求,这就涉及到了一些新的需求,运维人员可以对这些需求变更进行响应。
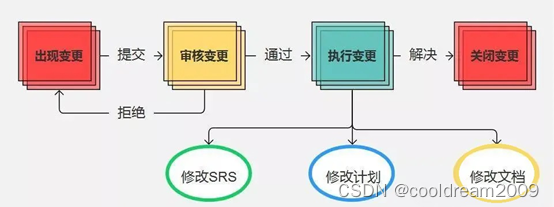
首先收集和记录变更请求的详细信息,包括变更的目的、范围、计划和风险评估等。然后对变更请求进行评审,包括评估变更的必要性、可行性和影响范围等,确定是否批准变更。从而制定变更的详细计划,包括变更的时间、地点、步骤和责任人等,确保变更的顺利实施。
在变更实施之前进行测试,包括功能测试、性能测试和回归测试等,确保变更不会引入新的问题。在变更实施过程中对变更进行控制和监督,确保变更按照计划进行,避免对系统的影响和风险。记录变更的详细信息,包括变更的内容、时间、责任人和结果等,以便后续的跟踪和审计。在变更实施过程中,如果发生问题或风险超出可控范围,需要及时回滚变更,恢复系统的正常状态。对每个变更进行总结和评估,包括变更的成功度、效果和教训等,以便后续的改进和优化。
通过变更管理,可以有效地控制和管理系统的变更,减少对系统的影响和风险,保证系统的稳定性和可靠性。
结语
在项目结项后的维护阶段,持续关注系统的运行状态,及时处理问题,不断优化系统,确保它能够稳定、高效地运行,持续满足用户需求。建立合适的维护制度、制定清晰的流程和计划,以及充分的沟通与协作,都是保障项目维护成功的关键。通过持续改进和创新,可以将项目维护阶段变为一个积极的过程,为用户提供更好的体验。