目录
- 前言
- 泛读
- 摘要
- Introduction
- 小结
- 精讲
- 方法
- Encoder-Decoder框架 for Image Captioning
- Spatial Attention Model
- Adaptive Attention Model
- Implementation Details
- Encoder-CNN
- Decoder-RNN
- Training details
- Related Work
- 实验
- 结论
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
用于密集字幕的全卷积定位网络
作者:Jiasen Lu等
单位:弗吉尼亚理工大学
发表时间:2016 CVPR
Latex 公式编辑器
泛读
摘要
Attention-based neural encoder-decoder frameworks have been widely adopted for image captioning. Most methods force visual attention to be active for every generated word. However, the decoder likely requires little to no visual information from the image to predict non-visual words such as “the” and “of”. Other words that may seem visual can often be predicted reliably just from the language model e.g., “sign” after “behind a red stop” or “phone” following “talking on a cell”.
铺垫现有的问题是什么?
基于注意力的神经网络编码器-解码器框架已被广泛用于图像caption任务。大多数方法都强迫视觉注意力对每个生成的单词都处于激活状态。然而,解码器在预测 "the "和 "of "等非视觉单词时,可能几乎不需要来自图像的视觉信息。其他看似视觉性的单词往往可以通过语言模型可靠地预测出来,例如 "在红灯…的后面 "后的 "标志 "或 "手机通话 "后的 “电话”。
In this paper, we propose a novel adaptive attention model with a visual sentinel. At each time step, our model decides whether to attend to the image (and if so, to which regions) or to the visual sentinel. The model decides whether to attend to the image and where, in order to extract meaningful information for sequential word generation.
本文解决什么?
在本文中,我们提出了一种带有视觉哨点的新型自适应注意力模型。在每个时间步,我们的模型都会决定是关注图像(如果是,则关注哪些区域)还是视觉哨点。该模型会决定是否关注图像以及关注哪些区域,以便提取有意义的信息用于连续单词的生成。
We test our method on the COCO image captioning 2015 challenge dataset and Flickr30K. Our approach sets the new state-of-the-art by a significant margin.
效果如何?
我们在 COCO 2015 图像标题挑战数据集和 Flickr30K 上测试了我们的方法。我们的方法在很大程度上达到了SOTA。
Introduction
为图像自动生成字幕已经成为学术界和工业界的一个突出的跨学科研究问题。它可以帮助视力受损的用户,并使用户很容易地组织和浏览大量典型
的非结构化视觉数据。为了生成高质量的标题,模型需要从图像中结合细粒度的视觉线索。最近,现有研究是基于视觉注意的神经编码器-解码器模型,其中注意机制通常会生成一个空间地图,突出显示与每个生成的单词相关的图像区域。常见框架是注意力机制下的encoder-decoder(CNN+RNN)。
描述完现有的方法和模型后,对现有问题进行分析:
大多数用于图像配图和视觉问题回答的注意力模型在每个时间步都关注图像,而不管接下来将发出哪个单词。然而,并不是所有的文字都有相应的视觉信号。考虑图1中的示例,该图像显示了一个图像及其生成的标题“一
只白色的鸟栖息在红色停止标志上”单词“a”和“of”没有相应的规范视觉信号。此外,语言的相关性使视觉信号变得不必要,比如在生成单词“on”和“top”时,会生成单词“perched”,在生成单词“sign”时,会生成单词“a red stop。事实上,来自非视觉词的梯度可能会误导和降低视觉信号在指导标题生成过程中的整体有效性。
例如下图中单词bird,red对应的图片信号较高,而of,sign得分较少。这里的得分使用的metric是visual grounding(指代理解),主要是看给出的单词或短语对应图片区域的可信度的高低。
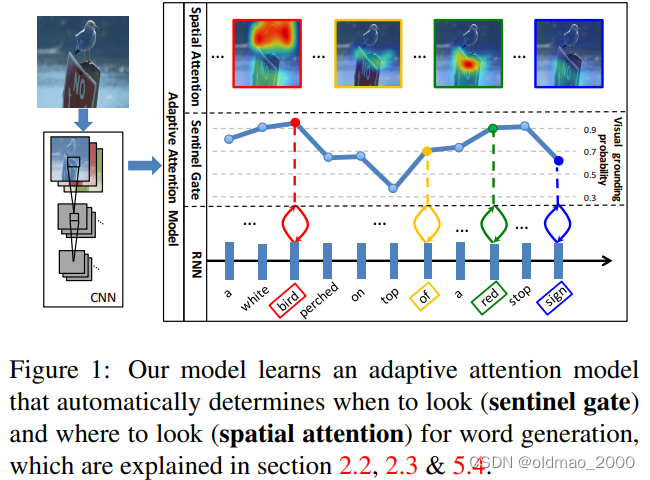
然后顺势提出本文的解决方案:
本文介绍了一种自适应注意力编码器-解码器框架,该框架可以自动决定何时依赖视觉信号,何时仅依赖语言模型。当然,当依赖于视觉信号时,模型也决定它应该关注哪里——哪个图像区域。首先提出了一种新的空间注意力模型来提取空间图像特征。然后,作为我们提出的自适应注意机制,我们引入了一个新的长短期记忆(LSTM)扩展,它产生了一个额外的“视觉哨兵”向量,而不是单一的隐藏状态。“视觉哨兵”是解码器内存的一个额外的潜在表示,为解码器提供了一个备用选项。我们进一步设计了一个新的前哨门,决定解码器希望从图像中获得多少新信息,而不是在生成下一个单词时依赖视觉哨兵。例如,如图1所示,我们的模型在生成单词“white”、“bird”、“red”和“stop”时学习更多地关注图像,在生成单词“top”、“of”和“sign”时更多地依赖视觉哨兵。
最后归纳全面的highlight:
- 我们介绍了一种自适应编码器-解码器框架,它能自动决定何时查看图像,何时依靠语言模型生成下一个单词。(点题)
- 我们首先提出了一种新的空间注意力模型,然后在此基础上设计出了带有 "视觉哨兵 "的新型自适应注意力模型。
- 我们的模型在 COCO 和 Flickr30k 上的表现明显优于其他先进方法。
- 我们对自适应注意力模型进行了广泛的分析,包括单词的视觉接地概率和生成的注意力地图的弱监督定位。
小结
1.引入了Spatial Attention的模型;(图像和文本之间的attention关联依旧很重要)
2.提出了Adaptive Attention,让网络自适应的去决定依靠视觉信息或语言模型:哨兵监控
精讲
方法
related work这节往后放了。
Encoder-Decoder框架 for Image Captioning
给定一个图像和相应的标题,先给出Encoder-Decoder框架的目标函数:
θ
∗
=
arg max
θ
∑
I
,
y
log
p
(
y
∣
I
;
θ
)
\theta^*=\argmax_{\theta}\sum_{I,y}\log p(y|I;\theta)
θ∗=θargmaxI,y∑logp(y∣I;θ)
其中
θ
\theta
θ是模型的参数,
I
I
I为图像,
y
=
{
y
1
,
⋯
,
y
t
}
y=\{y_1,\cdots,y_t\}
y={y1,⋯,yt}caption得到的序列。
利用链式法则,联合概率分布的对数似然可以分解为有序条件:
log
p
(
y
)
=
∑
t
=
1
T
log
p
(
y
t
∣
y
1
,
⋯
,
y
t
−
1
,
I
)
\log p(y)=\sum_{t=1}^T\log p(y_t|y_1,\cdots,y_{t-1},I)
logp(y)=t=1∑Tlogp(yt∣y1,⋯,yt−1,I)
为了方便,我们放弃了对模型参数的依赖。
在编码器-解码器框架中,使用循环神经网络(RNN),每个条件概率被建模为:
log
p
(
y
t
∣
y
1
,
⋯
,
y
t
−
1
,
I
)
=
f
(
h
t
,
c
t
)
(3)
\log p(y_t|y_1,\cdots,y_{t-1},I)=f(h_t,c_t)\tag 3
logp(yt∣y1,⋯,yt−1,I)=f(ht,ct)(3)
其中
f
f
f是非线性函数,
c
t
c_t
ct是在
t
t
t时间步从图像
I
I
I中提取到的上下文向量。
h
t
h_t
ht是RNN在
t
t
t时间步的隐藏层。本文RNN选用的是LSTM,其隐藏层公式为:
h
t
=
LSTM
(
x
t
,
h
t
−
1
,
m
t
−
1
)
h_t=\text{LSTM}(x_t,h_{t-1},m_{t-1})
ht=LSTM(xt,ht−1,mt−1)
x
t
x_t
xt是输入向量,
m
t
−
1
m_{t-1}
mt−1是
t
−
1
t-1
t−1时间步的存储记忆单元。
通常,上下文向量
c
t
c_t
ct是神经编码器-解码器框架中的一个重要因素,它为caption生成提供了视觉证据。
这些建模上下文向量的不同方法分为两类:
1.原版编码器-解码器框架
原版框架中,
c
t
c_t
ct只与编码器有关,一般编码器使用CNN模型。CNN吃进图像
I
I
I,最后从全连接层得到图片的全局特征。在解码过程中,
c
t
c_t
ct相当于常量,不变,不会依赖于编码器的隐藏层。
2.基于注意力的编码器-解码器框架。
在这种框架中,
c
t
c_t
ct与编码和解码器都有关系。在解码过程的第
t
t
t时间步,解码器会根据特定的图片区域,以及对应的区域特征
c
t
c_t
ct来进行计算。已有文献已证明该方法效果很不错。
本文对计算 c t c_t ct提出了spatial attention model,还对齐进行了扩展,升级为: adaptive attention model
Spatial Attention Model
先给出空间注意力模型计算上下文特征
c
t
c_t
ct的公式:
c
t
=
g
(
V
,
h
t
)
c_t=g(V,h_t)
ct=g(V,ht)
其中
g
g
g是注意力函数;
V
=
[
v
1
,
⋯
,
v
k
]
,
v
i
∈
R
d
V=[v_1,\cdots,v_k],v_i\in \mathcal{R}^d
V=[v1,⋯,vk],vi∈Rd是图片空间特征,每一个特征都是对应于图像的一部分的
d
d
d维表示;
h
t
h_t
ht是RNN在
t
t
t时刻的隐藏层。
给定图片空间特征
V
∈
R
d
×
k
V\in \mathcal{R}^{d\times k}
V∈Rd×k,LSTM的隐藏层
h
t
∈
R
d
h_t\in\mathcal{R}^d
ht∈Rd,将它们丢进单层带softmax的神经网络,可获得生成图像
k
k
k个区域上的注意力分布:
z
t
=
w
h
T
tanh
(
W
v
V
+
(
W
g
h
t
)
1
T
)
(6)
z_t=w^T_h\tanh(W_vV+(W_gh_t)\mathbf{1}^T)\tag 6
zt=whTtanh(WvV+(Wght)1T)(6)
α
t
=
softmax
(
z
t
)
(7)
\alpha_t=\text{softmax}(z_t)\tag 7
αt=softmax(zt)(7)
这里的
1
\mathbf{1}
1应该显示为:
但是markdown不支持\mathbb{1}显示。
1
∈
R
k
\mathbf{1}\in\mathcal{R}^k
1∈Rk是一个全1的向量
W
v
,
W
g
∈
R
k
×
d
W_v,W_g\in\mathcal{R}^{k\times d}
Wv,Wg∈Rk×d和
w
h
∈
R
k
w_h\in\mathcal{R}^k
wh∈Rk都是需要训练的参数。
α
t
∈
R
k
\alpha_t\in \mathcal{R}^k
αt∈Rk图片空间特征
V
V
V的注意力权重。
根据注意力分布,上下文向量
c
t
c_t
ct的公式为:
c
t
=
∑
i
=
1
k
α
t
i
v
t
i
c_t=\sum_{i=1}^k\alpha_{ti}v_{ti}
ct=i=1∑kαtivti
c
t
,
h
t
c_t,h_t
ct,ht将合起来预测公式3中的下一个词
y
t
+
1
y_{t+1}
yt+1。
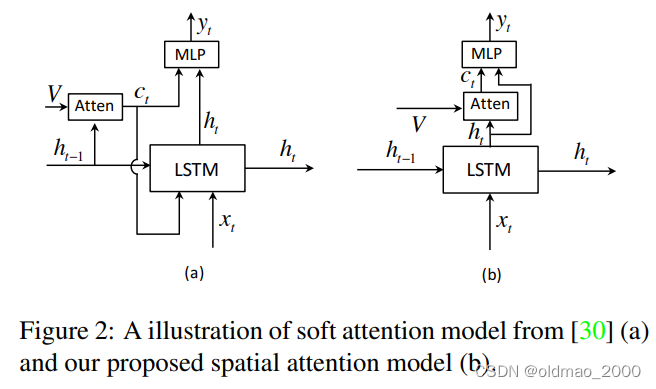
图2中提到的文献30,就是前面第4篇带读的Show, Attend and Tell,这里作者用其为对比,说明本文使用了隐藏层
h
t
h_t
ht来分析要关注图片的区域(也就是生成
c
t
c_t
ct),然后结合这两个信息源来预测下一个单词。我们的动机源于残差网络。生成的上下文向量
c
t
c_t
ct可以看作是当前隐藏状态
h
t
h_t
ht的剩余视觉信息,减少了当前隐藏状态的不确定性或补充了下一个词预测的信息量。我们还从经验上发现,我们的空间注意力模型表现得更好(具体看实验)。
Adaptive Attention Model
虽然基于空间注意力的解码器已被证明对图像caption是有效的,但它们不能确定何时依赖视觉信号,何时依赖语言模型。本文受Merity等[19]的启发,我们引入了一个新概念:“视觉哨兵”,这是解码器已经知道的东西的潜在表示。通过“视觉哨兵”,我们扩展了我们的空间注意力模型,并提出了一个自适应模型,能够确定它是否需要关注图像来预测下一个单词。
然后给出视觉哨兵的定义:
解码器的内存中存储着长期和短期的视觉和语言信息。我们的模型学会了从中提取一个新的组成部分,当模型选择不关注图像时,它就可以利用这个新的组成部分。这一新部分被称为视觉哨兵。而决定是关注图像还是视觉哨兵的门就是哨兵门。当解码器是LSTM时,我们会考虑其存储单元中保存的信息。扩展后的LSTM获取视觉哨兵向量
s
t
s_t
st的公式如下:
g
t
=
σ
(
W
x
x
t
+
W
h
h
t
−
1
)
s
t
=
g
t
⊙
tanh
(
m
t
)
g_t=\sigma(W_xx_t+W_hh_{t-1})\\ s_t=g_t\odot\tanh(m_t)
gt=σ(Wxxt+Whht−1)st=gt⊙tanh(mt)
其中
W
x
,
W
h
W_x,W_h
Wx,Wh是要学习的参数;
x
t
x_t
xt是LSTM在
t
t
t时间步的输入;
g
t
g_t
gt是记忆存储单元
m
t
m_t
mt的门控;
⊙
\odot
⊙表示元素点乘;
σ
\sigma
σ表示逻辑激活函数。
根据视觉哨兵,本文提出了自适应注意力模型来计算上下文向量。如下图所示:
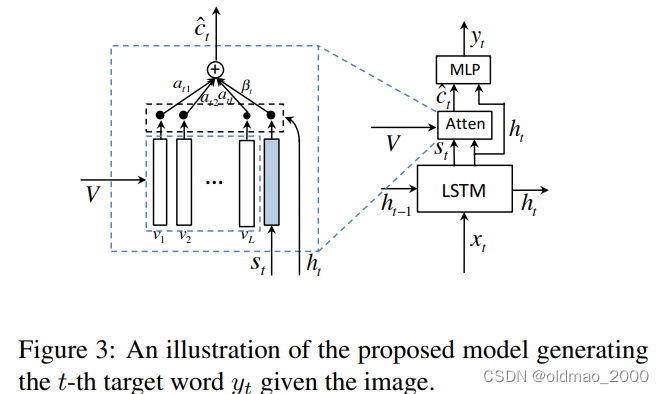
上下文向量为
c
^
t
\hat c_t
c^t,由空间参与图像特征(即空间注意模型的上下文向量)和视觉哨兵向量共同计算得来,该向量可权衡网络从图像中考虑的新信息与它在解码器内存中已经知道的信息(即视觉哨兵)。其公式如下:
c
^
t
=
β
t
s
t
+
(
1
−
β
t
)
c
t
\hat c_t=\beta_ts_t+(1-\beta_t)c_t
c^t=βtst+(1−βt)ct
其中,
β
t
\beta_t
βt是
t
t
t时刻的哨兵门控,与其他门控取值范围一样:
[
0
,
1
]
[0,1]
[0,1]。1表示在生成下一个单词时仅使用视觉哨兵信息(公式的后面一项为0),0则表示仅使用空间图像信息(公式的前面一项为0)。
为计算
β
t
\beta_t
βt,文中定义了空间注意力组件,就是上面公式6中的
z
z
z,它表示网络对于哨兵的关注程度,因此公式7可以写为:
α
^
t
=
softmax
(
[
z
t
;
w
h
T
tanh
(
W
s
s
t
+
(
W
g
h
t
)
)
]
)
\hat\alpha_t=\text{softmax}([z_t;w_h^T\tanh(Wss_t+(W_gh_t))])
α^t=softmax([zt;whTtanh(Wsst+(Wght))])
这里的
[
⋅
;
⋅
]
[\cdot ;\cdot]
[⋅;⋅]表示concat操作,spatial attention部分k个区域的attention分布
α
t
\alpha_t
αt也被扩展成了
α
^
t
\hat\alpha_t
α^t,做法是在
z
t
z_t
zt后面拼接上上面公式的那一坨;
W
s
,
W
g
W_s,W_g
Ws,Wg是权重参数,
W
g
W_g
Wg与公式6中的notation一致,含义也相同;
α
^
t
∈
R
k
+
1
\hat\alpha_t\in\mathcal{R}^{k+1}
α^t∈Rk+1是视觉哨兵(也可以说是空间图片特征,二者是此消彼长的关系)向量的注意力分布。
这里使用
α
^
t
\hat\alpha_t
α^t向量的最后一个元素表示门控值:
β
t
=
α
t
[
k
+
1
]
\beta_t=\alpha_t[k+1]
βt=αt[k+1]
在
t
t
t时刻,从词表中抽取某个词的概率可表示为:
p
t
=
softmax
(
W
p
(
c
^
t
+
h
t
)
)
p_t=\text{softmax}(W_p(\hat c_t+h_t))
pt=softmax(Wp(c^t+ht))
W
p
W_p
Wp是待学习参数。
这个公式表明模型在生成词的时候会自适应图片是哨兵之间的注意力。由于哨兵向量在每个时间步都更新,因此整个框架又称为自适应编码解码图片captioning框架。
Implementation Details
Encoder-CNN
图像选择了ResNet的最后一层卷积层的特征来表示图像,维度是
2048
×
7
×
7
2048\times7\times7
2048×7×7,全局图像特征则是局部特征的平均。局部图像特征需要经过转换,CNN特征的
k
k
k个网格区域表示为
A
=
{
a
1
,
⋯
,
a
k
}
,
a
i
∈
R
2048
A=\{a_1,\cdots,a_k\},a_i\in\mathcal{R}^{2048}
A={a1,⋯,ak},ai∈R2048,全局图片特征为:
a
g
=
1
k
∑
i
=
1
k
a
i
a^g=\cfrac{1}{k}\sum_{i=1}^ka_i
ag=k1∑i=1kai
为了建模方便,这里使用了单层整流激活函数将图片特征向量投影到
d
d
d维的新向量:
v
i
=
ReLU
(
W
a
a
i
)
v
g
=
ReLU
(
W
b
a
g
)
v_i=\text{ReLU}(W_aa_i)\\ v^g=\text{ReLU}(W_ba^g)
vi=ReLU(Waai)vg=ReLU(Wbag)
W
a
,
W
g
W_a,W_g
Wa,Wg是权重参数,投影后的向量可写为:
V
=
[
v
1
,
⋯
,
v
k
]
V=[v_1,\cdots,v_k]
V=[v1,⋯,vk]
Decoder-RNN
将词向量和全局图片特征进行concat后作为LSTM的输入( x t = [ w t ; v g ] x_t=[w_t;v^g] xt=[wt;vg]),然后用单层神经网络将视觉哨兵 s t s_t st和LSTM输出向量 h t h_t ht投影到 d d d维空间。
Training details
使用单层LSTM,隐藏层大小为512,优化器用的Adam,LSTM学习率为
5
e
−
4
5e-4
5e−4,CNN学习率为
1
e
−
5
1e-5
1e−5,momentum和权重衰减分别为0.8和0.999。
先对CNN微调20个epoch,然后把batchsize设置为80,再训练50个epoch,如果训练过程中CIDEr在6个epoch内没有变化则采取early stopping机制提前结束训练。
模型在单张泰坦X GPU上训练30小时就完成既定目标。
Related Work
很多文章把本该放在Introduction后面的这个小节放到介绍自己的框架或者方法后面。
原文大概介绍了图形生成文本的重要作用,然后总结目前生成文本有两种方法:基于模板和基于神经网络。
然后分小节分别进行介绍,基于模板的研究不展开。
基于神经的方法受到机器翻译中序列到序列编码器-解码器框架成功的启发。其观点是图像字幕类似于将图像翻译为文本。
最近,注意机制被引入到图像字幕的编码器-解码器神经框架中。这块花的笔墨较重。
当然最后不免要吹嘘一下自己的工作:
To the best of our knowledge, ours is the first work to reason about when a model should attend to an image when generating a sequence of words.
实验
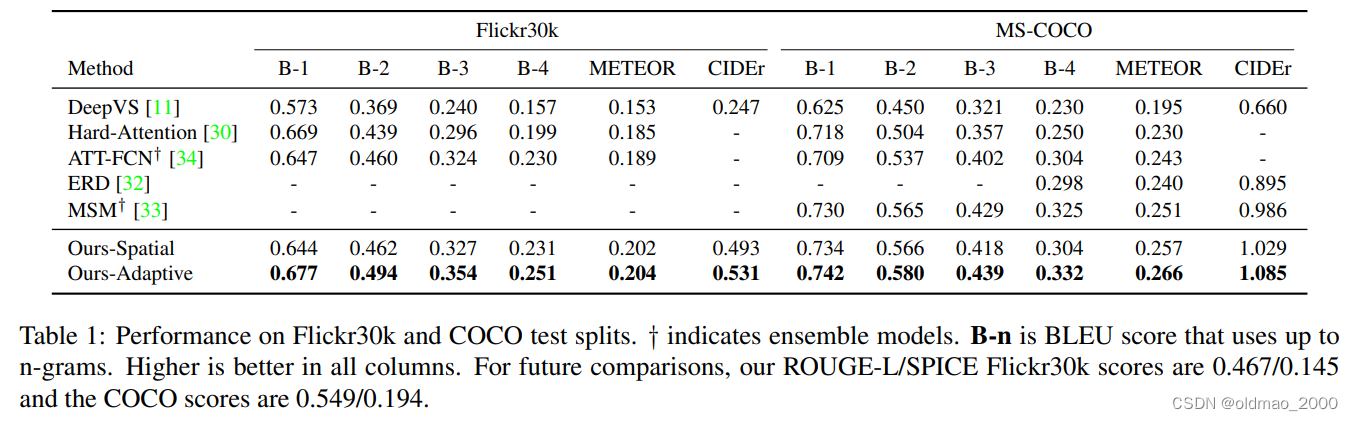
表1给出了不同方法在在Flickr30k和MSCOCO的测试集上的运行结果,Metric包括BLUE、METEOR和CIDEr,分数都是越高越好,可以看到最高分都在Adaptive那行,当然Spatial就很厉害了。
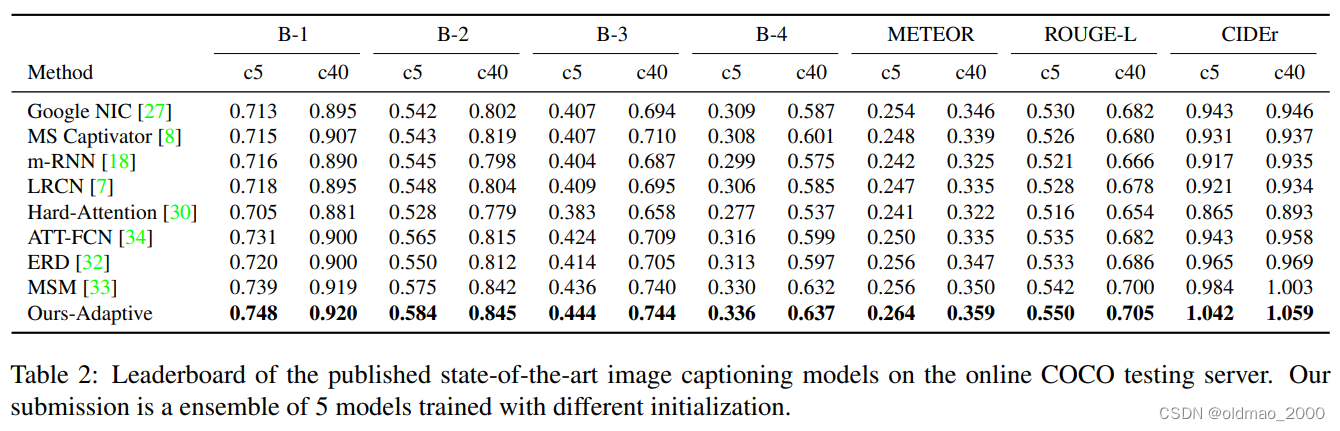
表2直接给出了公共测试服务器上的对比结果,当然本文使用了ensemble。

图4显示了生成的标题和标题中特定单词的空间注意图。前两列是成功的例子,最后一列是失败的例子。我们看到,我们的模型学习的对齐方式与人类直觉强烈一致。请注意,即使在模型产生不准确的标题的情况下,我
们看到我们的模型确实看到了图像中的合理区域,只不过它似乎无法计数或识别纹理(或材质)和细粒度类别。这里作者暗示未来可以针对这里进行改进,如果CNN能够更加强,对应的效果自然会更加好。
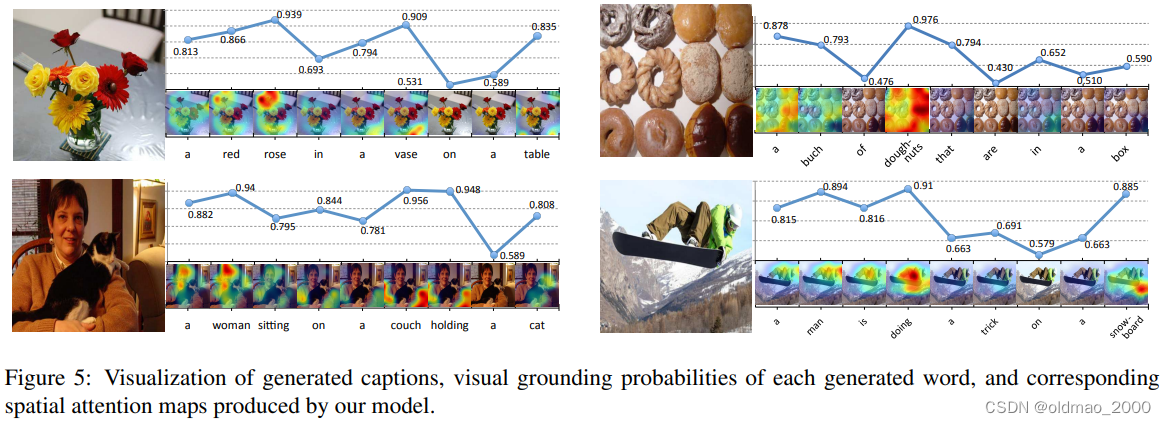
图5主要是哨兵门概率
1
−
β
1−β
1−β的可视化,对于视觉词,模型给出的概率较大,即更倾向于关注图像特征
c
t
c_t
ct,对于非视觉词的概率则比较小(例如:“the”, “of”, “to”等定冠词、介词)。同时,同一个词在不同的上下文中的概率也是不一样的。如"a",在一开始的概率较高,因为开始时没有任何的语义信息可以依赖、以及需要确定单复数。
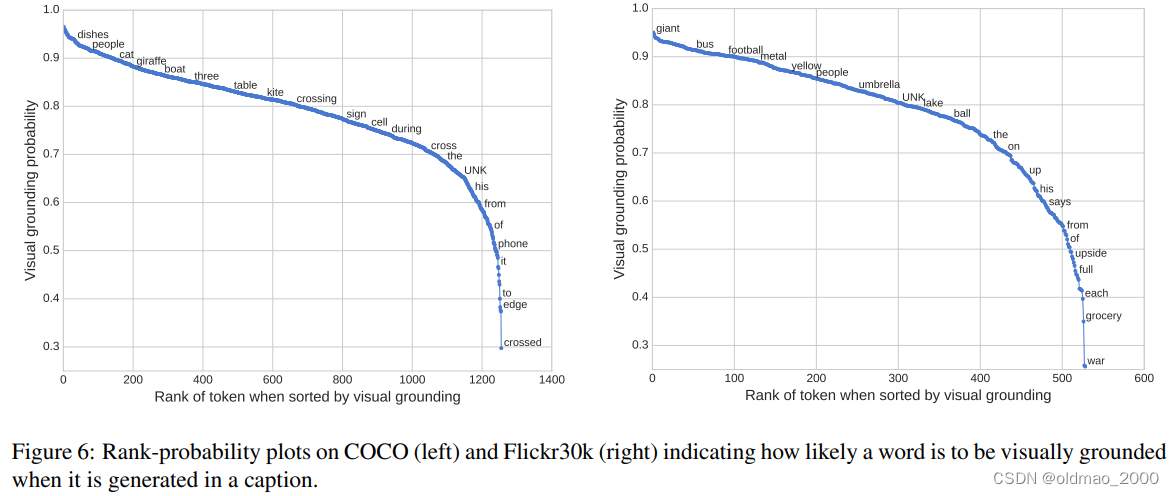
上图将词表中每个单词的 visual grounding probability用点图的方式画出来。每个单词都是计算了生成概率的平均值。从图中可以看到,模型对于实体词:“dishes”, “people”, “cat”,“boat”;描述词(形容词)“giant”, “metal”, “yellow”;数词 “three”等会给比较大视觉注意力,对于定冠词、介词“the”,“of”, “to”等会给比较少,而对于抽象表示词“crossing”, “during” 等会给出介于前面两类之间的视觉注意力。文章还特别指出模型的视觉注意力分布并不依赖于任何语义或者额外的领域知识,都是自动学习的。
有一些例外,例如“phone”获得的视觉注意力较低,因为它在训练数据中通常是以“cell phone”的形式出现,由于“cell”获得的视觉注意力较高,且二者同时出现频率较高(强相关),也就解释了“phone”获得较低视觉注意力的原因。

上图显示了两个模型(spatial和adaptive attention)在COCO数据集中出现最频繁的(top 45)词的定位准确性。对于一些体积较小的物体(“sink”, “surfboard”, “clock” and “frisbee”),其准确率是比较低的,这是因为attention map是从7x7的featuremap中直接放大的,而7x7的feature map并不能很好地包含这些小物体的信息。较大物体反之。(“cat”, “bed”, “bus”, “truck”)
结论
很短,没有讨论和展望。
在本文中,我们提出了一种新的自适应注意力编码器-解码器框架,该框架为解码器提供了一个回退选项。我们进一步引入了一个新的LSTM扩展,它产生了一个额外的“视觉哨兵”。
我们的模型在图像字幕的标准基准上实现了最先进的性能。我们进行广泛的注意评估来分析我们的适应性注意。虽然我们的模型是在图像caption任务上进行评估的,但它也可以应用在其他领域。