案例背景
最近发现科大的讯飞星火大模型可以申请API试用了,我一直想用chatgpt的API,一是因为收费买不起,二是因为网络不方便.....
现在有了科大讯飞这个国内免费的,当然要试试。
目前讯飞星火可以申请试用他们的模型API,但是只有200w的token上限(一下就能花光),而且目前是测试阶段,只能自己做点小玩意试用一下。
本篇就是教大家怎么申请,然后怎么写代码封装为.exe程序,然后随时都可以使用AI进行对话。
申请准备
讯飞星火官网:讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞
然后点击api测试

然后点击申请:
进入申请界面,但别急着填信息,我们要先申请一个APPID号,翻到最下面:
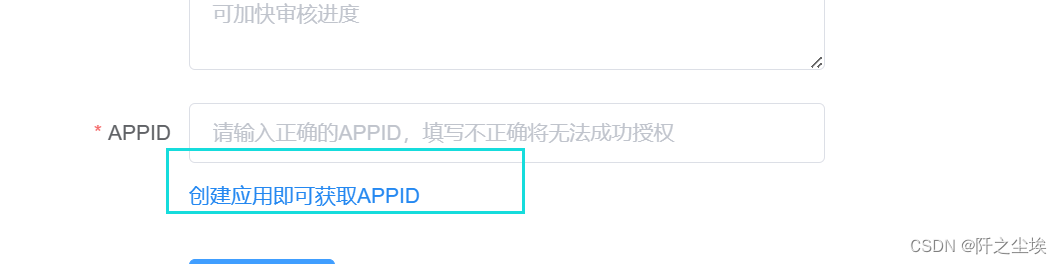
全部都填好:
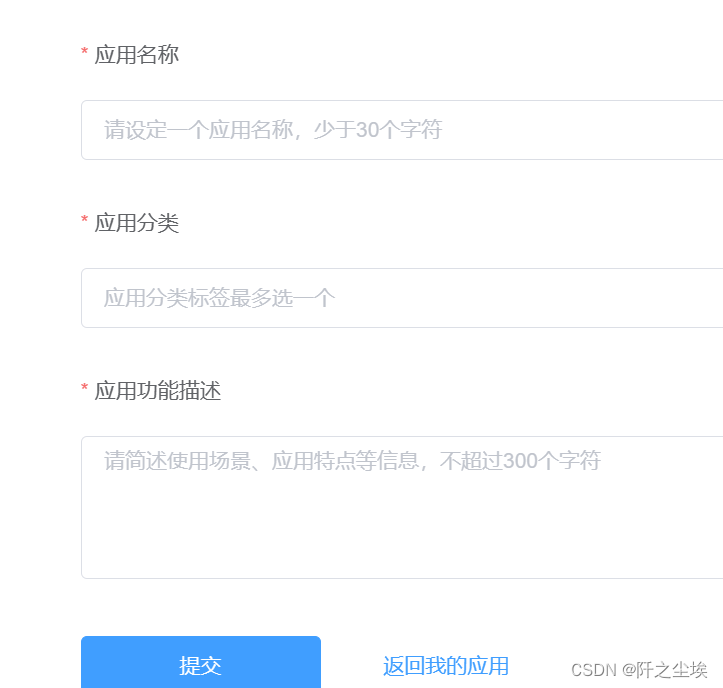
之后就能得到一个APPID:

记住它,然后回到我们刚刚申请的界面,填好所有的信息提交:
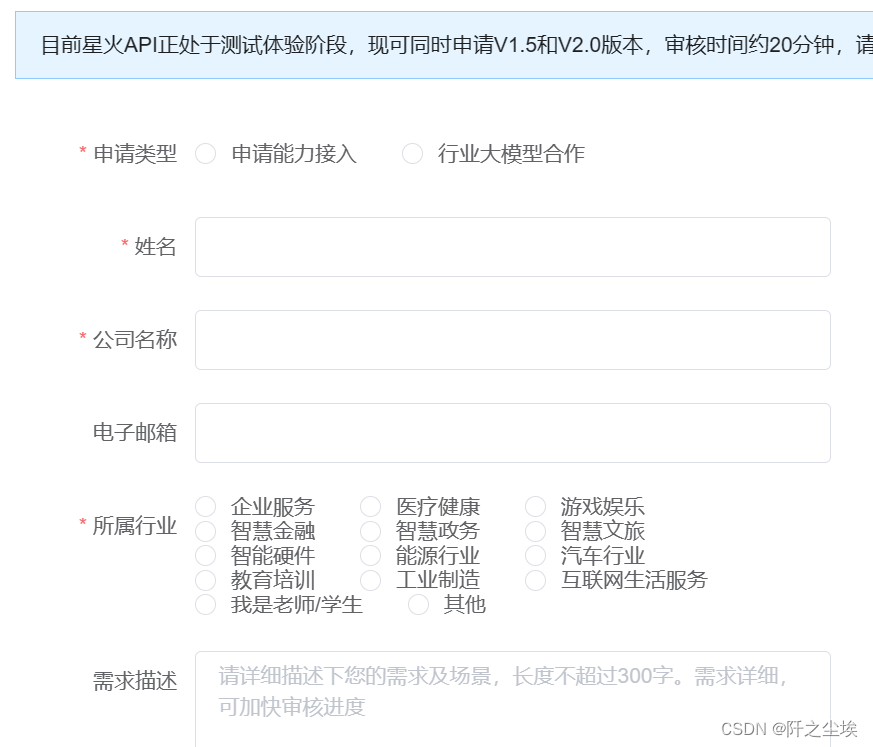
我们需要等一会,大概一个小时内就能通过申请。
通过后,我们可以在工单中心查看自己的信息:
然后我们进入平台首页,查看自己的控制台
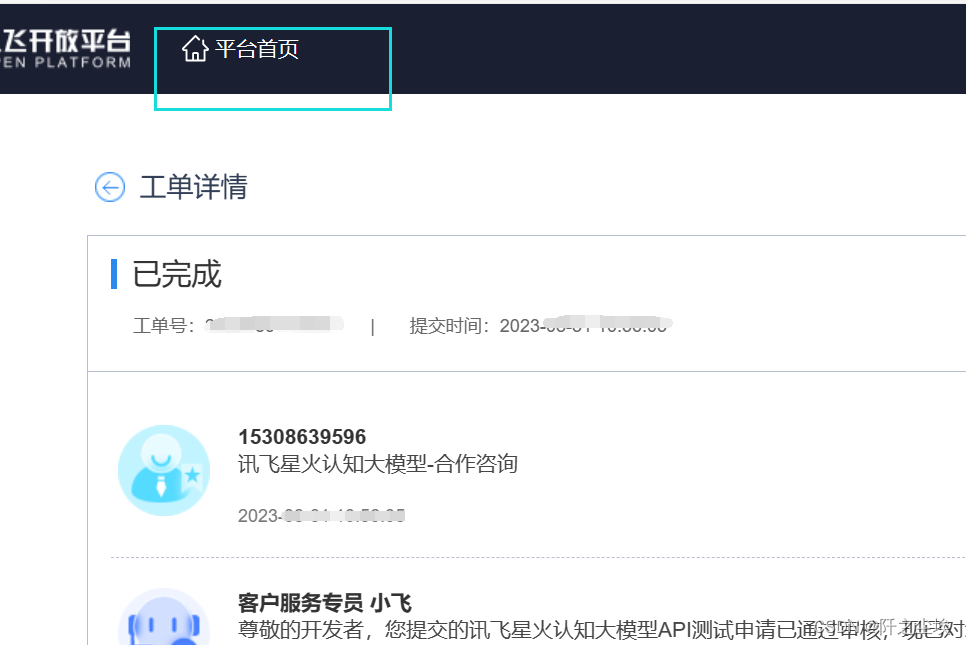
点击我们申请的应用:
点击左边的星火大模型V1.5/V2.0
就能查看到我们这个申请的APPID还有API的密码等等信息:
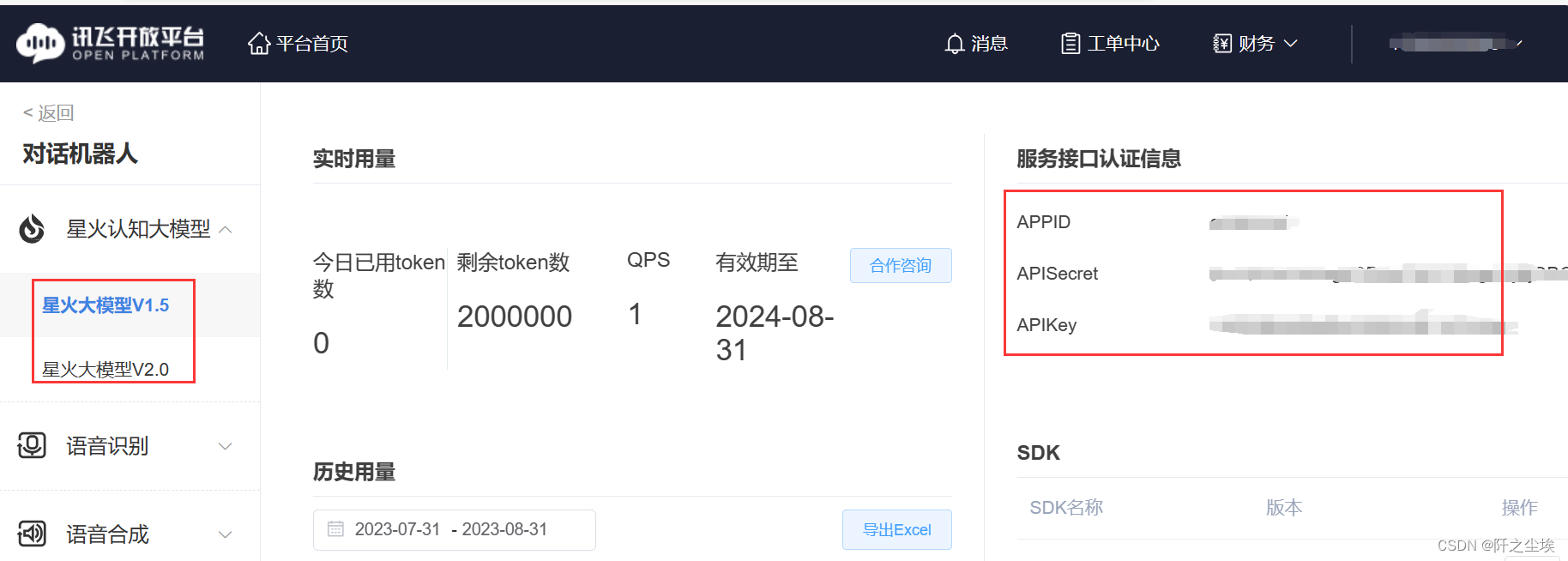
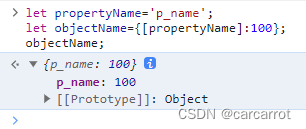
有了这个信息后,就可以写代码了。
编写代码
源文档链接:星火认知大模型Web文档 | 讯飞开放平台文档中心 (xfyun.cn)
想详细了解可以看看,只想学会怎么调用API就看我下面代码就行。
首先要装一个库,websocket 和 websocket_client
先在命令行里面输入:(按win+R,然后输入cmd打开命令行)
pip install websocket可能会比较慢,报错的话多重复试试
然后再安装:
pip install websocket_client就完成了环境的准备。(其他的包应该都是py内置的)
新建一个py文件,名字就命名为讯飞星火,然后输入:
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket # 使用websocket_client
answer = ""
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.Spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws,one,two):
print(" ")
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, domain= ws.domain,question=ws.question))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
# print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
print(content,end ="")
global answer
answer += content
# print(1)
if status == 2:
ws.close()
def gen_params(appid, domain,question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
def main(appid, api_key, api_secret, Spark_url,domain, question):
# print("星火:")
wsParam = Ws_Param(appid, api_key, api_secret, Spark_url)
#websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open)
ws.appid = appid
ws.question = question
ws.domain = domain
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
然后下面的三行信息就需要用刚刚自己的API密钥填写:
#以下密钥信息从控制台获取
appid = "******" #填写控制台中获取的 APPID 信息
api_secret = "****************" #填写控制台中获取的 APISecret 信息
api_key ="***********************8" #填写控制台中获取的 APIKey 信息
#用于配置大模型版本,默认“general/generalv2”
#domain = "general" # v1.5版本
domain = "generalv2" # v2.0版本
#云端环境的服务地址
#Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
text =[]
# length = 0
def getText(role,content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text
if __name__ == '__main__':
text.clear
while(1):
Input = input("\n我:")
question = checklen(getText("user",Input))
answer =""
print("星火:",end = "")
main(appid,api_key,api_secret,Spark_url,domain,question)
getText("assistant",answer)
# print(str(text))
其他完全不用改,直接就能运行了:
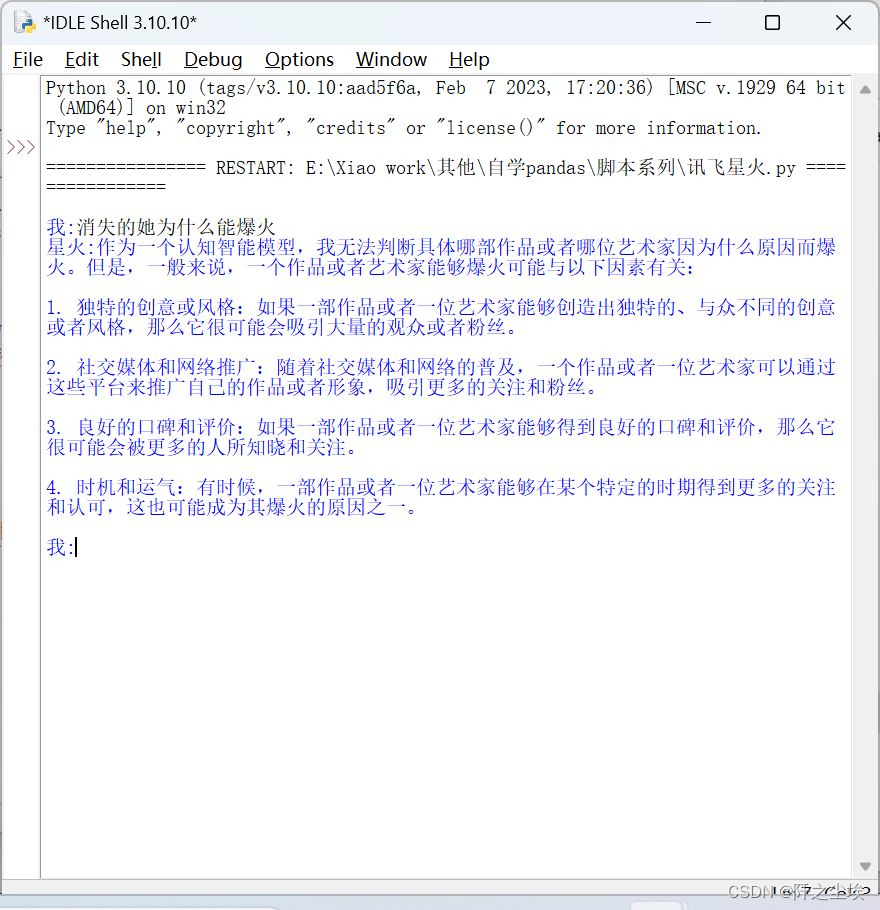
现在就以及能运行了,但是每次都要启动python还是很麻烦,那就把它打包为可执行的程序,这样以后就可以做到随处可用!
(如果有很多文本数据需要进行一一处理,那么使用python循环,然后API回答是最好不过了,比人工聊天一段一段的复制粘贴快很多)
打包程序
主要依靠pyinstaller库实现,安装:
pip install pyinstaller然后win+r,输入cmd打开终端
输入自己的代码文件所在的路径:
cd /d "E:\Xiao work\其他\自学pandas\脚本系列"然后输入打包的文件名称,我的文件名叫讯飞星火.py
pyinstaller --onefile 讯飞星火.py等待就行,后面就可以在这个目录下的dist文件夹里面找到这个程序了。
它才5MB,这么小我是没想到的....
双击打开就能用,输入你想说的话:
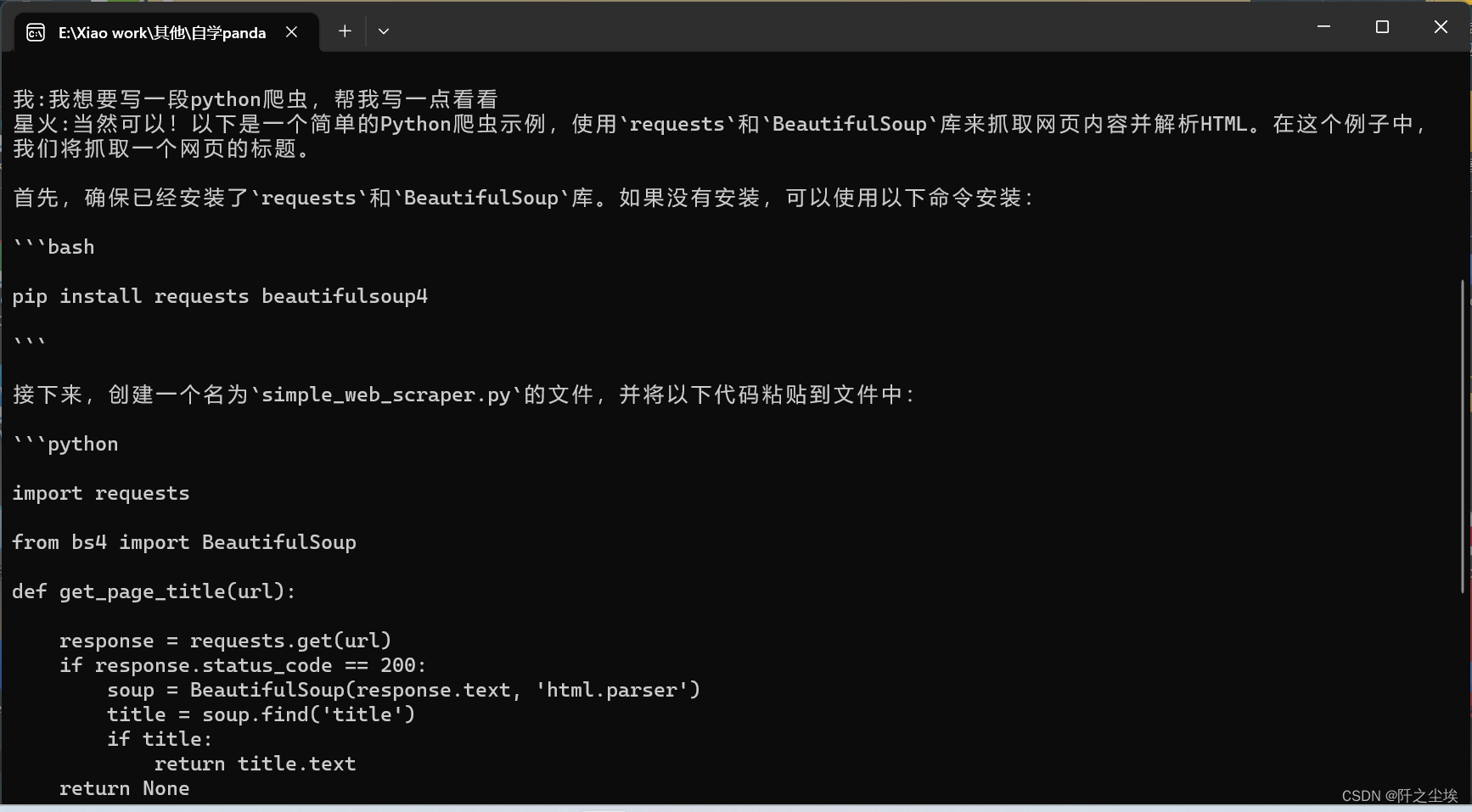
虽然很简陋.....,但很方便,双击打开就能用,只有要电脑有网就能用,文件也不大。
要是有大佬能加个漂亮的图形互动界面就能成为真正的应用程序了。


![[ROS]虚拟机ubuntu18.04系统里面运行usb_cam](https://img-blog.csdnimg.cn/0075c472f40a49ffa79dd9e0852de06a.jpeg)