1、概念
1.1、概述
在MySQL中,高阶语句是指一些复杂、高级的查询语句或操作,用于满足更特定和复杂的数据需求。这些高阶语句通常涉及更多的SQL功能和技巧,以扩展MySQL的功能和性能。
在MySQL中,它们扩展了基本的SELECT、INSERT、UPDATE和DELETE等常见操作,提供了更强大和灵活的数据库查询、处理和管理能力
1.2、常见的MySQL高阶语句的概念:
1. 子查询(Subqueries):子查询是嵌套在其他查询中的查询语句。它可以在主查询中使用子查询的结果来动态生成查询条件,实现更复杂的数据检索和筛选。
2. 联合查询(Joins):通过连接多个相关联的表,从中检索相关的数据。MySQL支持多种连接类型(如INNER JOIN、LEFT JOIN、RIGHT JOIN等),以满足不同的数据关联需求。
3. 窗口函数(Window Functions):窗口函数是一种在查询结果集上执行聚合、排序和排名等操作的高级函数。它可以在查询结果中定义窗口,并对窗口内的数据进行计算和处理。
4. 分组集(GROUPING SETS):分组集允许在单个查询中指定多个分组依据,以得到不同维度的聚合结果。它可以简化复杂的GROUP BY操作,提供更灵活的聚合查询能力。
5. WITH语句(Common Table Expressions):WITH语句允许创建临时命名的查询块,类似于子查询,但可重复使用。它可以提高查询的可读性和可维护性,尤其在复杂查询中。
6. UNION操作符:UNION操作符用于合并多个SELECT语句的结果集,并消除重复行。UNION ALL则包含所有的查询结果,不进行去重。
7. 正则表达式(Regular Expressions):MySQL支持使用正则表达式进行模式匹配和搜索。REGEXP和RLIKE是两个常用的正则表达式操作符,用于在字符串字段中进行高级模式匹配。
8. 分页查询(Pagination):分页查询用于限制查询结果的数量,实现分页展示。使用LIMIT和OFFSET子句可以指定返回的行数和起始位置,实现分页功能。
9. 自定义函数(User-defined Functions):MySQL允许开发者创建自定义函数,扩展SQL的功能。自定义函数可以根据业务需求编写,提供更灵活和个性化的数据处理能力。
这些高阶语句为MySQL查询和操作提供了更丰富、灵活的功能和技巧。通过运用这些高级语句,可以满足复杂业务需求,提高查询性能,实现更精确和高效的数据操作和分析。
1.3、 SQL高阶语句的作用
MySQL的高阶语句提供了更强大和灵活的功能,:
1. 复杂查询:高阶语句使得进行复杂的数据查询变得更加容易。例如,使用子查询可以在查询结果的基础上动态生成查询条件,实现更精确和特定的数据检索。
2. 关联查询:通过联合查询,可以连接多个相关联的表,从中检索出满足特定条件的相关数据。这对于处理多个表之间的关系非常有用,如查询订单与顾客的关联信息。
3. 聚合操作:通过高级聚合函数和分组集,可以对查询结果进行更复杂的聚合操作。例如,在分组查询中可以计算每个组的总数、平均值等统计信息,并得到相应的汇总结果。
4. 分页查询:高阶语句中的LIMIT和OFFSET子句可用于实现分页查询。这对于在Web应用程序中展示大量数据时非常有用,可以根据需要返回指定数量的结果。
5. 数据分析:窗口函数提供了在查询结果上进行排序、排名和分析的能力。通过窗口函数,可以计算累积和、移动平均值等复杂的数据分析指标。
6. 动态SQL:动态SQL允许根据不同的运行时条件和变量构建和修改SQL语句。这在需要根据用户输入或其他动态情况来生成不同查询的场景下非常有用。
7. 存储过程和触发器:存储过程和触发器是一些预定义的SQL代码块,可以实现复杂的业务逻辑和数据处理操作。它们提供了更高级的数据库控制和自动化能力。
通过使用MySQL的高阶语句,可以更灵活地处理和管理数据,满足复杂的查询需求,并进行更高级和精细化的数据操作和分析。这些功能对于开发复杂应用、进行数据挖掘和业务分析等领域非常有帮助。
2、常用查询
增、删、改、查
对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等
2.1、按关键字排序
2.1.1、概述和作用
使用 SELECT 语句可以将需要的数据从 MySQL 数据库中查询出来,如果对查询的结果进行排序,可以使用 ORDER BY 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
先创建好数据
2.1.2、 (1)语法
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC与DESC区别
ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略。SELECT 语句中如果没有指定具体的排序方式,则默认按 ASC方式进行排序。 DESC 是按降序方式进 行排列。当然 ORDER BY 前面也可以使用 WHERE 子句对查询结果进一步过滤。
2.1.3、模板表:ky30
数据库有一张ky30表,记录了学生的id,姓名,分数,地址和爱好
Databascreate table ky30(id int(5) not null,name varchar(20) primary key not null,score decimal(5,2),address varchar(20),hobbid int(5));mysql> insert into ky30 values(1,'liuyi',80,'beijing',2);
mysql> insert into ky30 values(2,'wangwu',90,'shenzhen',2);
mysql> insert into ky30 values(3,'lisi',60,'shanghai',4);
mysql> insert into ky30 values(4,'tianqi',99,'hangzhou',5);
Query OK, 1 row affected (0.00 sec)
mysql> insert into ky29 values(5,'jiaoshou',98,'laowo',3);
mysql> insert into ky30 values(5,'jiaoshou',98,'laowo',3);
Query OK, 1 row affected (0.01 sec)
mysql> insert into ky30 values(6,'hanmeimei',10,'nanjing',3);
Query OK, 1 row affected (0.01 sec)
mysql> insert into ky30 values(7,'lilei',11,'nanjing',5);
Query OK, 1 row affected (0.01 sec)
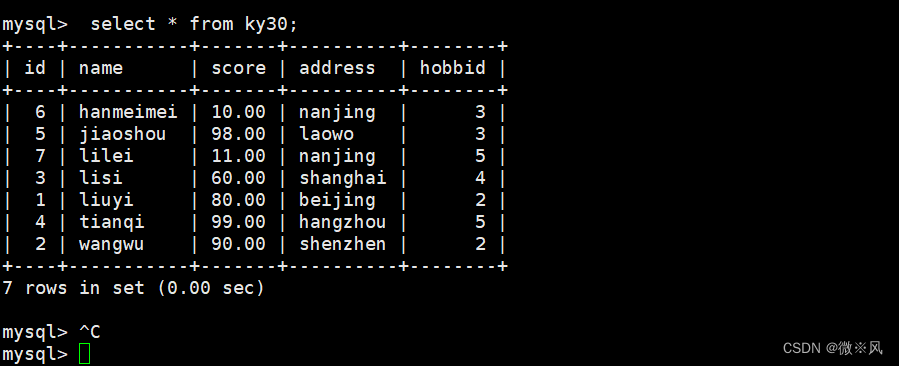
按分数排序,默认不指定是升序排列
mysql> select id,name,score from ky30 order by score; 2.1.4、分数按降序排列
2.1.4、分数按降序排列
mysql> select id,name,score from ky30 order by score desc;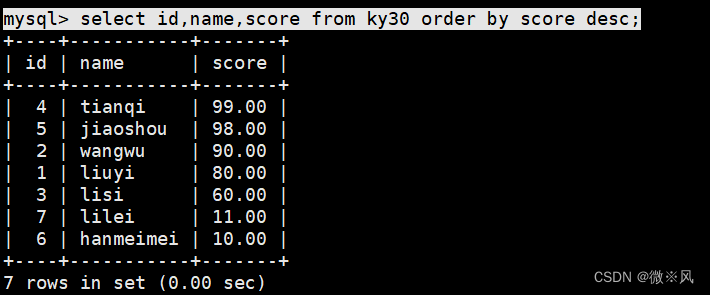
order by还可以结合where进行条件过滤,筛选地址是杭州的学生按分数降序排列
mysql> select name,score from ky30 where address='hangzhou'order by score desc;

2.1.5、ORDER BY 语句
可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定
但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
mysql> select id,name,hobbid from ky30 order by hobbid desc,id desc;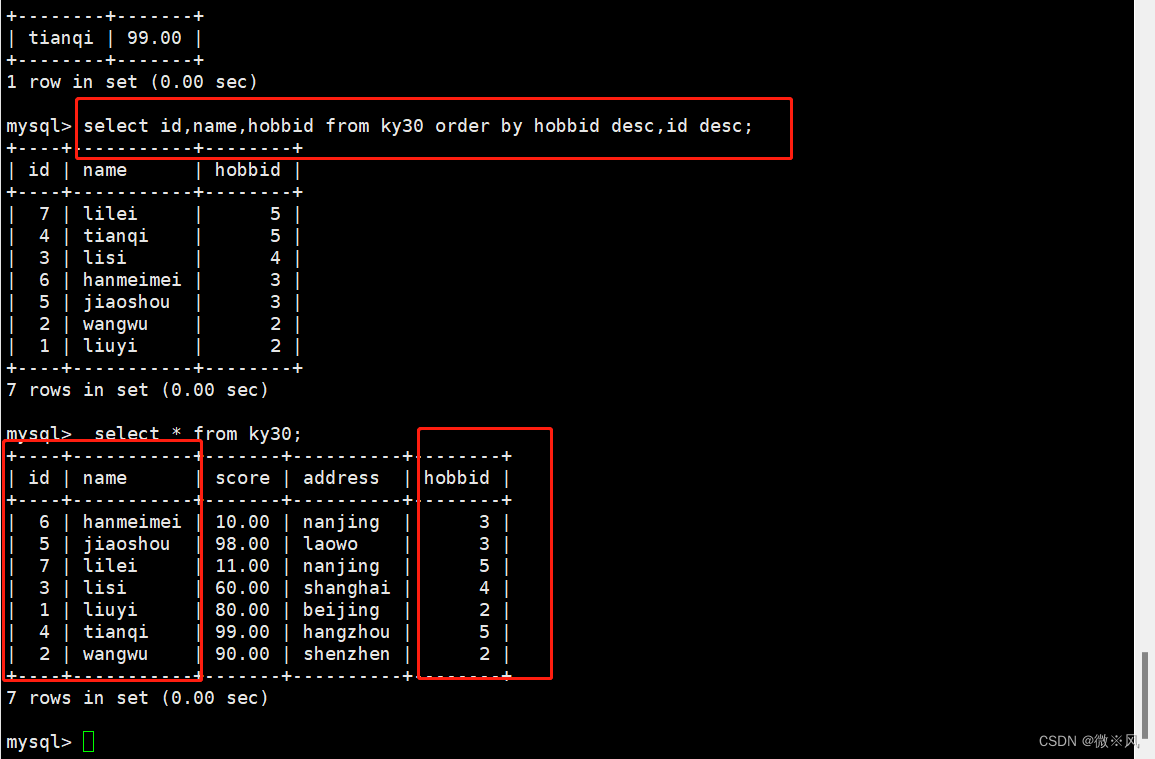 2.1.6、查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
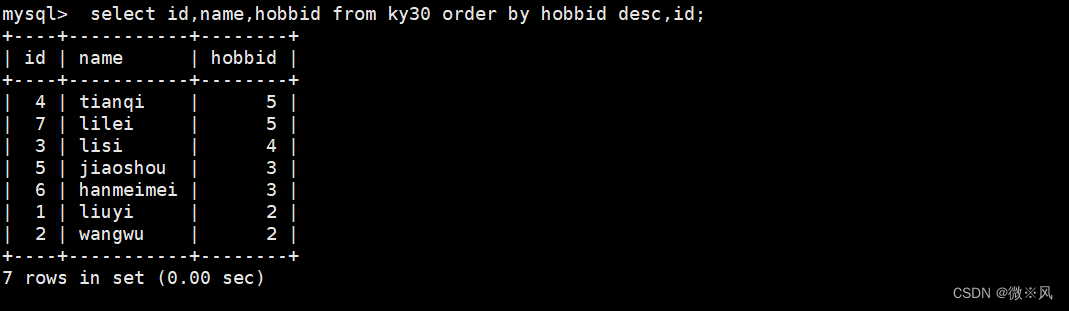
2.1.6、查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
mysql> select id,name,hobbid from ky30 order by hobbid desc,id;
2.1.7、 区间判断及查询不重复记录
2.1.7.1、AND/OR ——且/或
mysql> select * from ky30 where score >70 and score <=90;
mysql> select * from ky30 where score >70 or score <=90;2.1.7.2、嵌套/多条件
mysql> select * from ky30 where score >70 or (score >75 and score <90);

2.1.7.3、distinct 查询不重复记录 语法:
mysql> select distinct hobbid from ky30;

2.2、对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
2.1、语法
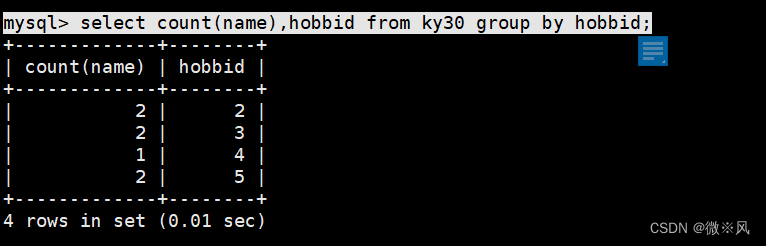
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name;按hobbid相同的分组,计算相同分数的学生个数(基于name个数进行计数)
mysql> select count(name),hobbid from ky30 group by hobbid;
2.2、结合where语句,筛选分数大于等于80的分组,计算学生个数
mysql> select count(name),hobbid from ky30 where score>=80 group by hobbid;
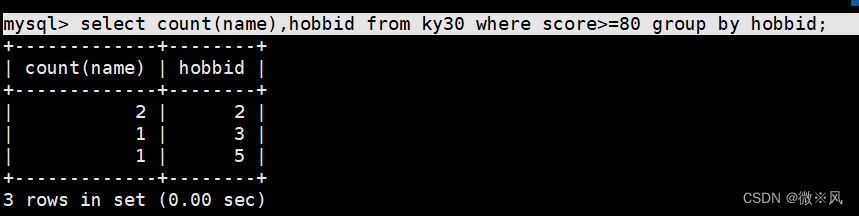
全班同学成绩表
count(name):计数
score 分数 :
score>=80 :优秀
score >=60 and score <80 :优-
2.3、结合order by把计算出的学生个数按升序排列
mysql> select count(name),score,hobbid from ky30 where score>=80 group by hobbid order by count(name) asc;

3、限制结果条目(limit)
limit 限制输出的结果记录
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
3.1、语法
SELECT column1, column2, ... FROM table_name LIMIT [offset,] numberLIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。 如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的 位置偏移量是 0,第二条是 1,以此类推。第二个参数是设置返回记录行的最大数目。
3.2、查询所有信息显示前4行记录
mysql> select * from ky30 limit 3;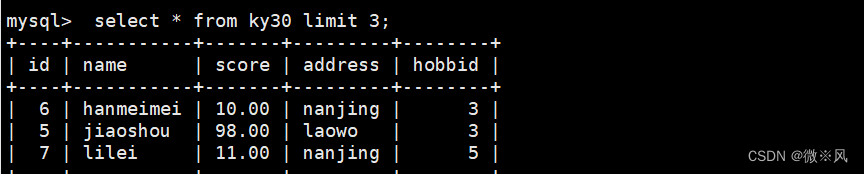
我的虚拟机通过这个命令查询的顺序就是乱的,所以有所不同(每个人情况不同)
3.3、从第4行开始,往后显示3行内容
mysql> select * from ky30 limit 3,3;
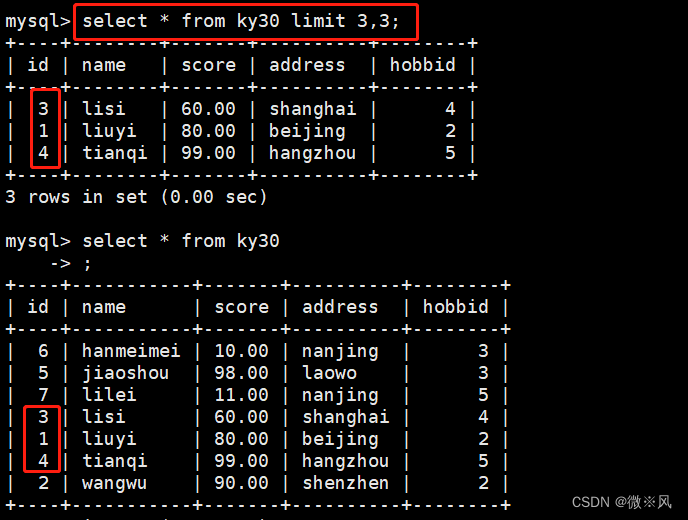
3.4、 结合order by语句,按id的大小升序排列显示前三行
mysql> select id,name from ky30 order by id limit 3;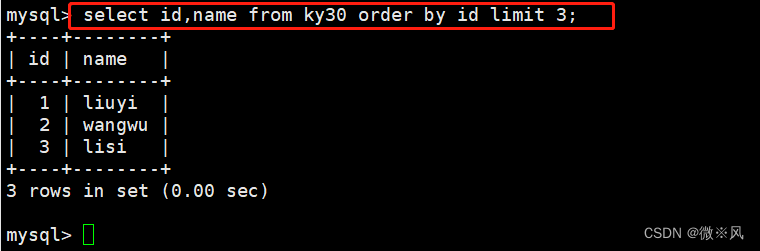
3.5、基础select 小的升阶 怎么输出最后三行
mysql> select id,name from ky30 order by id desc limit 3;

输出前三行,怎么输出 : limit 3 limit 2 您说的是前三行,limit 是做为位置偏移量的定义,他的起始是从0开始,而0表示的是字段
4、设置别名(alias ——》as)
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
4.1、语法
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;在使用 AS 后,可以用 alias_name 代替 table_name,其中 AS 语句是可选的。AS 之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名 或字段名是不会被改变的
4.2、列别名设置示例:
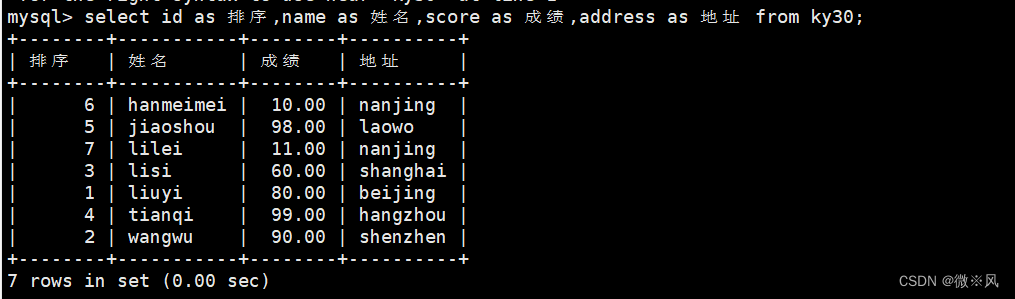
mysql> select id as 排序,name as 姓名,score as 成绩,address as 地址 from ky30;

4.3、 表的长度较长设置别名
如果表的长度比较长,可以使用 AS 给表设置别名,在查询的过程中直接使用别名 临时设置info的别名为i
select i.name as 姓名,i.score as 成绩 from info as i;4.4、查询info表的字段数量,以number显示
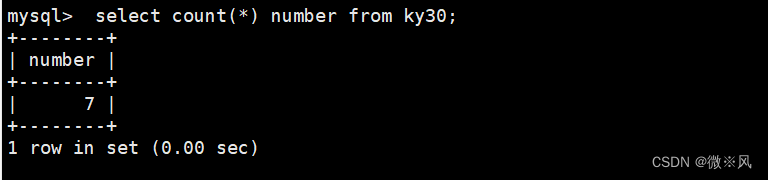
mysql> select count(*) as number from ky30;
不用as也可以显示
4.5、 适用场景:
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂、减短sql语句)
4.6、创建表的连接
此外,AS 还可以作为连接语句的操作符。
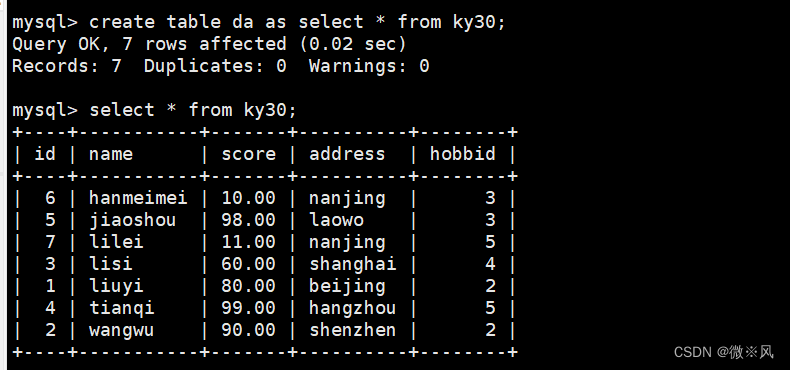
创建da表,将ky30表的查询记录全部插入da表
mysql> create table da as select * from ky30;
Query OK, 7 rows affected (0.02 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> select * from ky30;
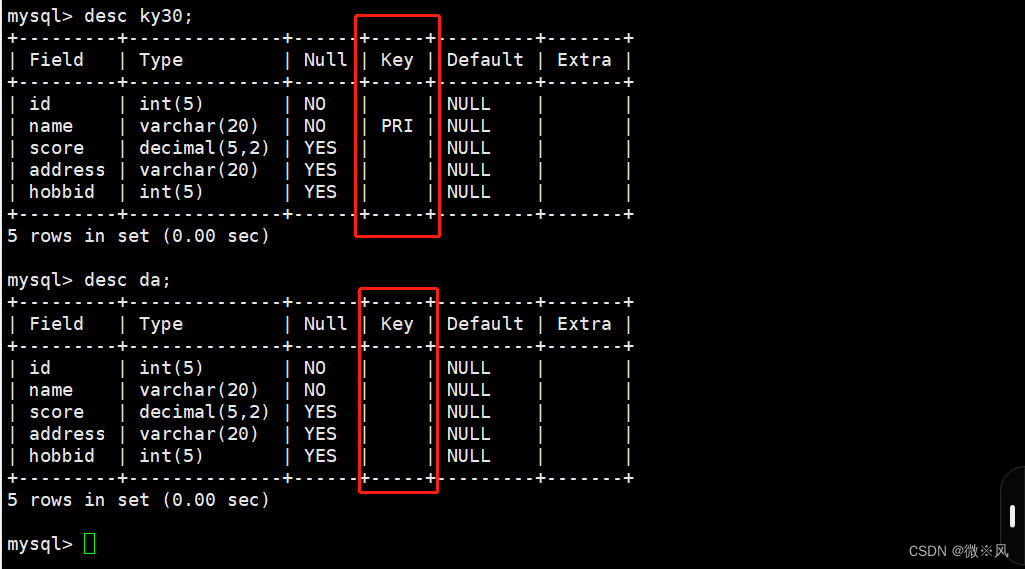
需要注意的是:连接不会复制原表的主键
4.7、as 的作用:
- 创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
- 但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0
4.8、 克隆、复制表结构
create table t1 (select * from info);
可以加入where 语句判断
mysql> create table tda1 as mysql> * from ky30 where score >=60;
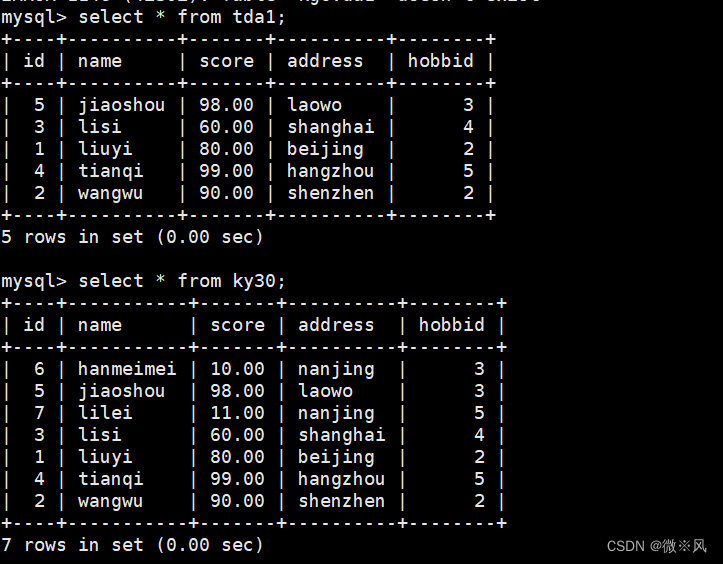
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。 列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
5、通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
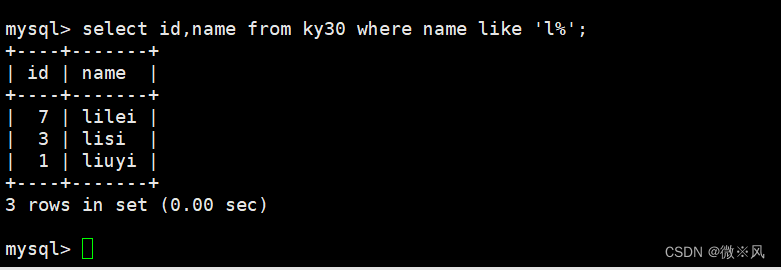
5.1、查询名字是c开头的记录
mysql> select id,name from ky30 where name like 'l%';
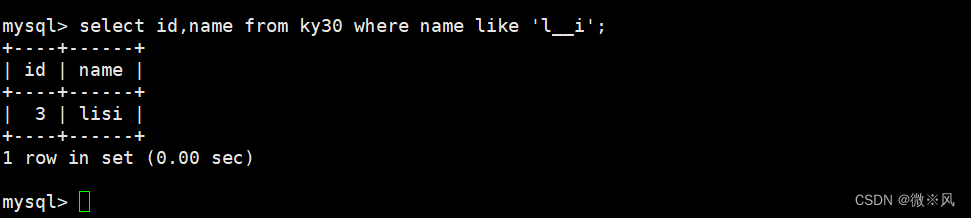
5.2、 查询名字里是l和i中间有两个字符的记录
mysql> select id,name from ky30 where name like 'l__i';
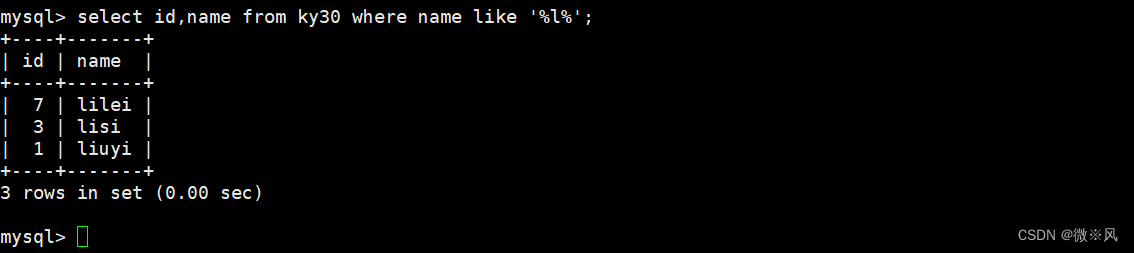
5.3、 查询名字中间有l的记录
mysql> select id,name from ky30 where name like '%l%';
 5.4、查询l后面3个字符的名字记录
5.4、查询l后面3个字符的名字记录
mysql> select id,name from ky30 where name like 'l___';
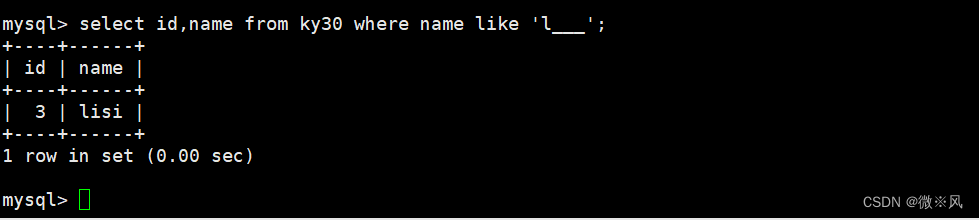
通配符“%”和“_”不仅可以单独使用,也可以组合使用 查询名字以w开头的记录
mysql> select id,name from ky30 where name like 'w%__';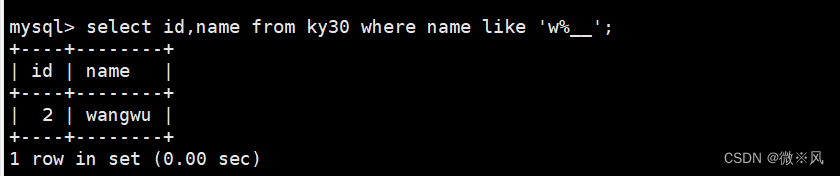
6、子查询
6.1、概述
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语 句。子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤。
6.2、主语句与子语句
子语句可以与主语句所查询的表相同,也可以是不同表
mysql> select name,score from ky30 where id in (select id from ky30 where score>60);
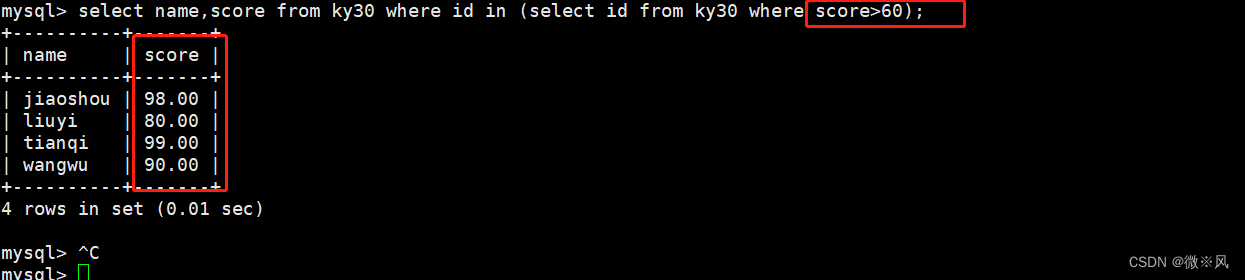 主语句: select name,score from ky30 where id in
主语句: select name,score from ky30 where id in
子语句(集合): (select id from ky30 where score>60);
子语句中的sql语句是为了,最后过滤出一个结果集,用于主语句的判断条件
将主表和子表关联/连接的语法
6.3、不同表/多表示例
mysql> create table ky30_da(id int);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into ky30_da values(1),(2),(3);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select id,name,score from ky30 where id in (select id from ky30_da);
子查询不仅可以在 SELECT 语句中使用,在 INERT、UPDATE、DELETE 中也同样适用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,也就是说可以多层嵌套。
6.4、in与not in
语法
IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用
语法:
.<表达式> [NOT] IN <子查询>
当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE。 若启用了 NOT 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需 求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对。 多数情况下,子查询都是与 SELECT 语句一起使用的
查询分数大于80的记录
mysql> select name,score from ky30 where id in (select id from ky30 where score>80);
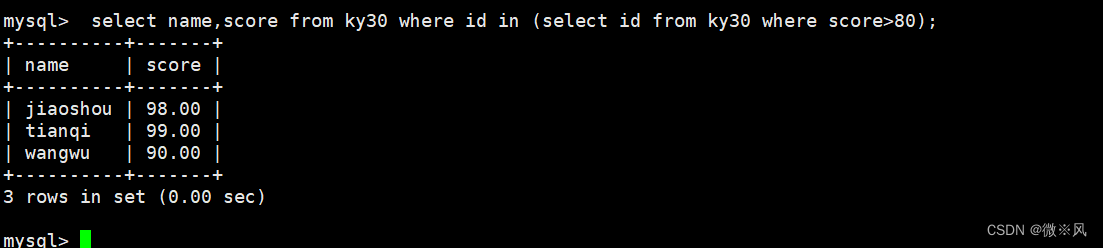
6.5 子查询与insert
子查询还可以用在 INSERT 语句中。子查询的结果集可以通过 INSERT 语句插入到其 他的表中
将t1里的记录全部删除,重新插入info表的记录
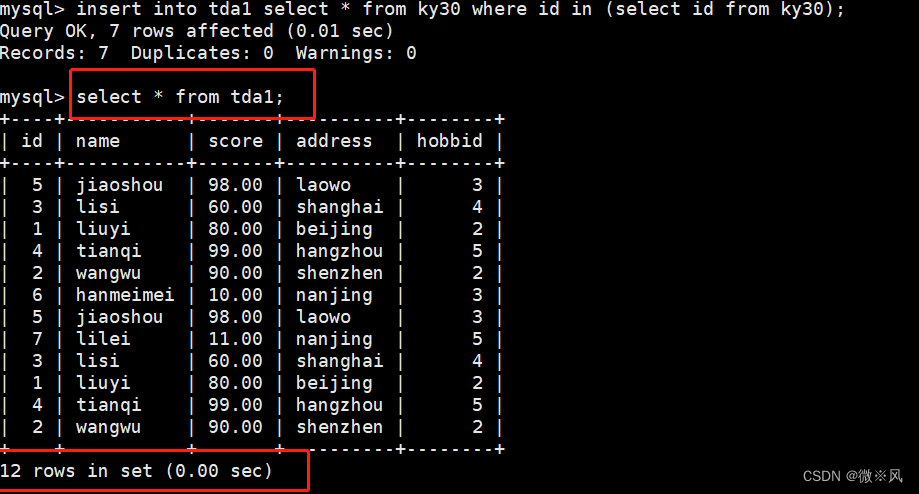
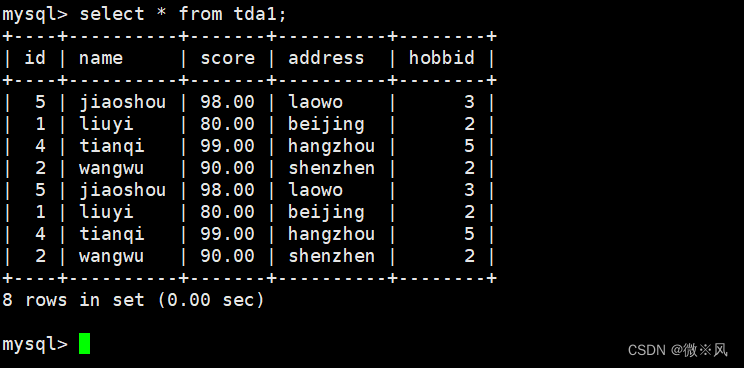
mysql> insert into tda1 select * from ky30 where id in (select id from ky30);
mysql> select * from tda1;
6.6、UPDATE 语句
可以使用子查询。UPDATE 内的子查询,在 set 更新内容时,可以是单独的一列,也可以是多列。
mysql> update da set score=80 where id in (select id from ky30 where id=2);

mysql> update da set score=100 where id not in (select id from ky30 where id >3);

6.7、DELETE 也适用于子查询
删除分数大于80的记录
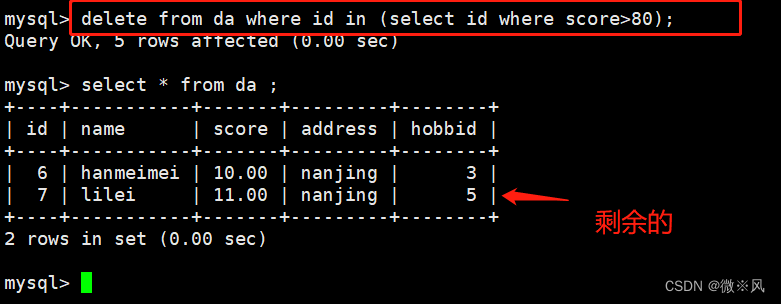
mysql> delete from da where id in (select id where score>80);
Query OK, 5 rows affected (0.00 sec)
在 IN 前面还可以添加 NOT,其作用与IN相反,表示否定(即不在子查询的结果集里面) 删除分数不是大于等于80的记录
删除小于80的
mysql> delete from tda1 where id not in (select id where score>=80);

6.8、EXISTS
这个关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回 TRUE;反之,则返回 FALSE
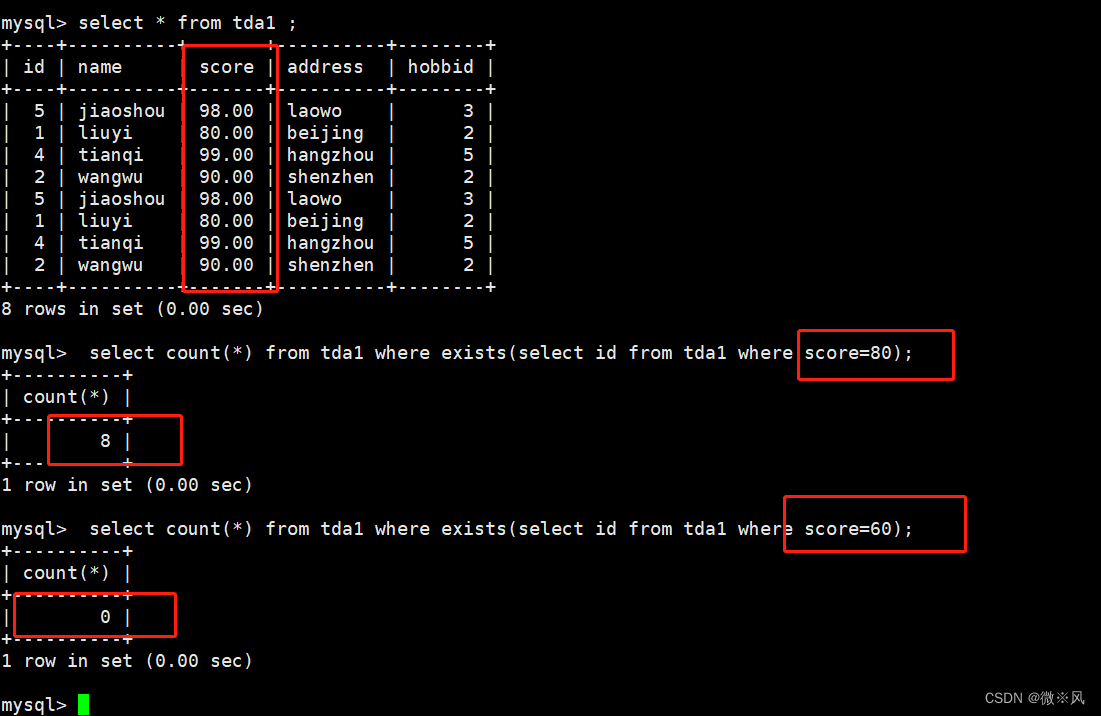
mysql> select count(*) from tda1 where exists(select id from tda1 where score=80);
mysql> select count(*) from tda1 where exists(select id from tda1 where score=60)查询如果存在分数等于80的记录则计算tda1的字段数
查询如果存在分数没有等于60的不记录则计算tda1的字段数
子查询,别名as
将结果集做为一张表进行查询的时候,我们也需要用到别名,
mysql> select a.id from (select id,name from tda1) a;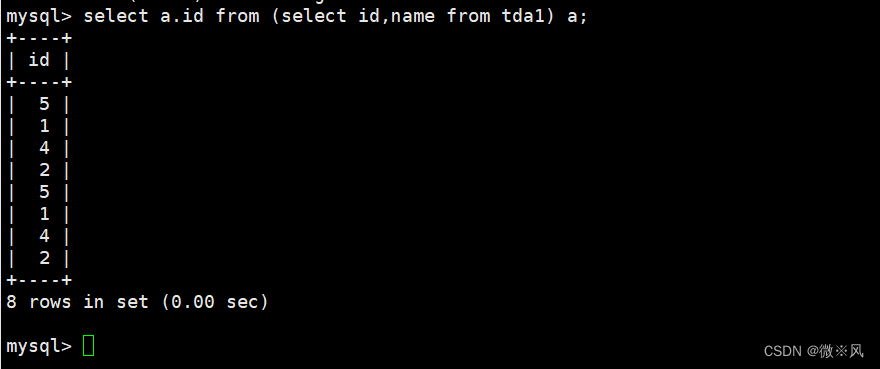
7、MySQL视图
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了真实数据的映射
视图可以理解为镜花水月/倒影,动态保存结果集(数据)
基础表info (7行记录) ——》映射(投影)--视图
作用场景
针对不同的人(权限身份),提供不同结果集的“表”(以表格的形式展示)
7.1、作用范围:
select * from info; #展示的部分是info表
select * from view_name; #展示的一张或多张表
7.2、功能:
简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性 本质而言视图是一种select(结果集的呈现)
视图适合于多表连接浏览时使用!不适合增、删、改
而存储过程适合于使用较频繁的SQL语句,这样可以提高执行效率!
视图和表的区别和联系
7.3、区别
①、视图是已经编译好的sql语句。而表不是
②、视图没有实际的物理记录。而表有。 show table status\G
③、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
④、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
⑤、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
⑥、视图的建立和删除只影响视图本身,不影响对应的基本表。(但是更新视图数据,是会影响到基本表的)
7.4、联系:
视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
7.5、实例:
满足80分的学生展示在视图中
这个结果会动态变化,同时可以给不同的人群(例如权限范围)展示不同的视图
7.5.1、创建ky30的视图
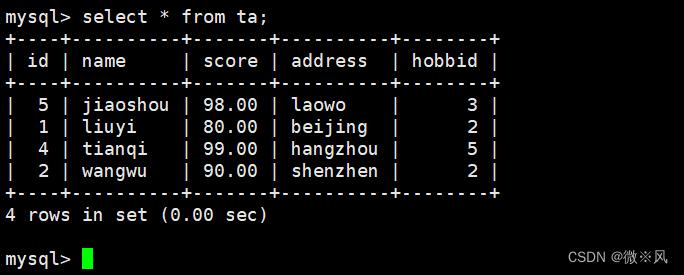
mysql> create view ta as select * from ky30 where score>=80;
7.5.2、 查看视图
 7.5.3、查看视图与源表结构
7.5.3、查看视图与源表结构
7.5.4、修改原表数值
当达到视图表要求的范围,则视图表也随之改变
mysql> update ky30 set score=88 where id=3;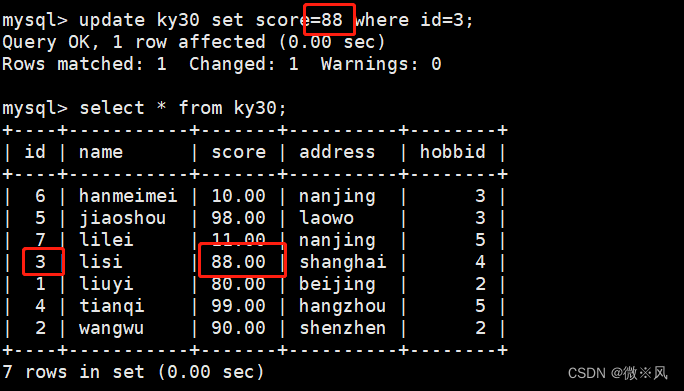
视图的数据

7.5.5、 视图与源的结构
视图结构
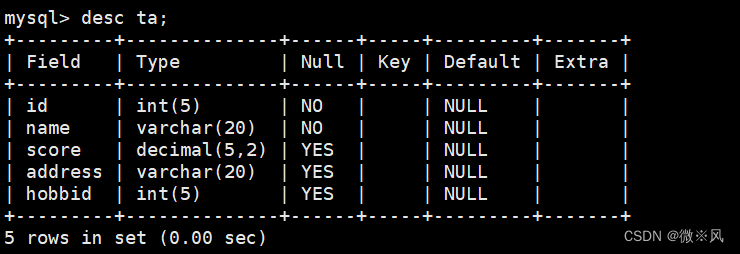 源的结构
源的结构

7.6、多表创建视图
mysql> create table ky10 (id int,name varchar(10),age char(10));
mysql> insert into ky10 values(1,'zhangsan',20);
mysql> insert into ky10 values(2,'lisi',30);
mysql> insert into ky10 values(3,'wangwu',29);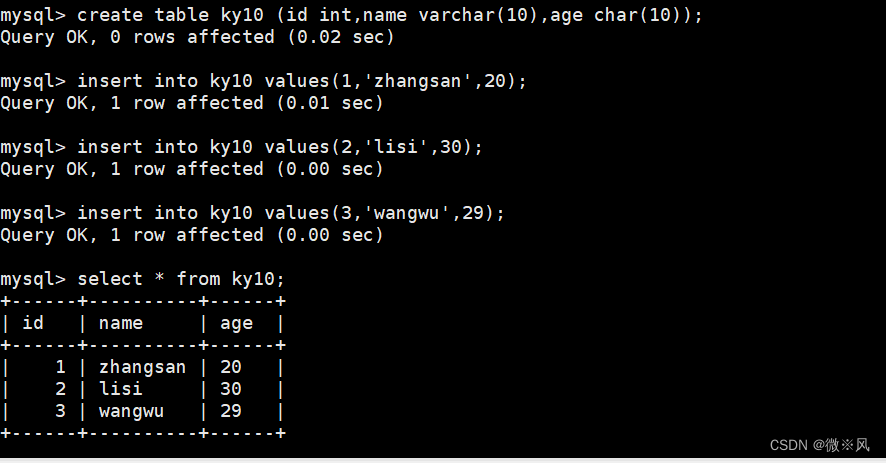
null值
概述
在 SOL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULI关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0或者空白 (spaces)的字段是不同的,值为 NULI 的字段是没有 值的。在 SOL 语句中,使用 IS NULL可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值。
查询info表结构,name字段是不允许空值的
nu11值与空值的区别(空气与真空)
空值长度为0,不占空间,NULL值的长度为nul1,占用空间is null无法判断空值空值使用"="或者"<>"来处理 (!=)
count () 计算时,NULL会忽略,空值会加入计算
在计算机编程中,"null"值和"空"值(Empty value)是两个不同的概念。
1. "null"值:它表示一个变量或表达式没有有效的值或未被赋值。通常用于指示缺少数据、未知或无效的情况。在许多编程语言中,"null"是一个特殊的关键字或保留字,用于表示空引用或空对象。
2. "空"值:它表示一个变量或数据结构中没有任何数据或内容。与"null"不同,"空"值仍然被认为是一个有效的值,只是它表示没有具体的数据内容。
简而言之,"null"值表示缺少或无效的数据,而"空"值表示存在但没有具体内容。在某些编程语言中,"null"可以作为特殊的值进行处理,而"空"值则是一种数据状态或占位符。需要根据所使用的编程语言和上下文来理解和使用这两个概念。
常见的应用场景:
- 变量初始化:在声明变量时,可以将其初始值设置为"null",表示该变量暂时没有有效的值。
- 解除引用:将一个对象或变量的引用置为"null",可以释放对该对象的引用,从而帮助垃圾回收器回收内存。
- 条件检查:可以使用"null"值来检查变量是否存在有效的值,避免出现空指针异常等错误。
需要注意的是,每种编程语言对于"null"值的处理方式可能不同。某些语言可能会提供更丰富的空值处理机制,如"Optional"类型或"Maybe"类型,以更好地处理空值的情况。因此,在具体的编程环境中,建议查阅相关文档或参考相应的语言规范以了解准确的行为。
内连接 左连接 右链接
左连接:将两张表的内容及逆行匹配,按照
区别
左连接(Left Join):
左连接是关系型数据库中的一种连接操作,它将两个表按照指定的条件(通常是两表之间的某个字段的值相等)进行连接,并返回左表中所有的记录以及与右表匹配的记录。如果右表中没有匹配的记录,则返回NULL值。
右连接(Right Join):
右连接也是关系型数据库中的一种连接操作,它与左连接的原理类似,只是返回的结果集包括右表中所有的记录以及与左表匹配的记录。如果左表中没有匹配的记录,则返回NULL值。
内连接(Inner Join):
内连接是关系型数据库中最常用的连接操作之一。它仅返回两个表中满足连接条件的记录。也就是说,只有在左表和右表之间存在匹配的记录时,才会将这些记录返回。
三者之间的区别在于返回结果的不同:
- 左连接返回左表的全部记录以及与右表匹配的记录。
- 右连接返回右表的全部记录以及与左表匹配的记录。
- 内连接只返回符合连接条件的记录。
需要注意的是,连接操作需要指定连接条件,即表之间关联的字段。根据实际需求选择正确的连接类型可以帮助我们获取所需的数据结果。
![[ROS]虚拟机ubuntu18.04系统里面运行usb_cam](https://img-blog.csdnimg.cn/0075c472f40a49ffa79dd9e0852de06a.jpeg)