作者:张政俊 中欧财富数据库负责人

中欧财富是中欧基金控股的销售子公司,旗下 APP 实现业内基金品种全覆盖,提供基金交易、大数据选基、智慧定投、理财师咨询等投资工具及服务。中欧财富致力为投资者及合作伙伴提供一站式互联网财富管理解决方案,自 2015 年成立以来业务持续保持稳健的增长。
本文介绍了中欧财富在分布式数据库领域的探索历程,以及如何成功将业务系统迁移到 TiDB 平台的实践。文章详述了中欧财富采用 TiDB 的四个上线阶段,展现了 TiDB 在应对数据增长、处理 DDL 挑战以及优化写入性能等方面的卓越表现。此外,文章还特别强调了 TiDB 7.1 LTS 版本所带来的新特性,包括资源管控、Partitioned Raft KV 等,这些创新极大地提升了中欧财富的业务效益和性能水平。
分布式数据库的应用历程
中欧财富从 2021 年开始调研分布式数据库,希望通过使用分布式数据库来实现原有 MySQL 数据库不能满足的需求,从而解决业务层面遇到的技术难题。期间对 TiDB 做了全方位测试,证实了 TiDB 从架构角度是兼容的、从性能角度是达标的。2022 年,我们采购服务器开始部署 TiDB 集群,逐步将一些周边系统迁移到 TiDB 上 。今年,我们做了更详细的测试和验证,将更多更复杂的业务系统切换到 TiDB,上半年上线了四个系统,下半年计划再上线六个系统。
中欧财富的分布式数据库上线工作可以分为四个阶段:
第一阶段是业务的深度测试 。通过搭建和生产配置相同的并行环境,使用生产数据进行深度的测试。每个业务系统有各自的特点,场景都不一样。每次上线前,必须要保证测试是充分的:业务层面的测试要保证所有的业务都可以跑通;性能方面,每个业务的性能指标不能低于其原先在 MySQL 上的性能指标。横向对实时业务和跑批任务的效率进行对比,找出慢 SQL 并进行优化。
第二阶段是进行数据的同步 。通过 TiDB 提供的 DM 工具,将数据从生产 MySQL 实时同步至 TiDB 集群。当数据完成实时同步之后,再将原架构中 MySQL 下游的同步链路(MySQL 原生同步、Canal、FlinkCDC 等)全部切至 TiDB(通过 TiCDC 输出) ,之后进行两到三周的数据同步观察,校验数据的一致性。
第三阶段是应用上线 。一般会找一个小的停机窗口,关闭 DM 同步,确保数据的一致性之后,把应用切到 TiDB 上。
第四阶段就是上线后的保障工作 ,对已上线应用的运行情况和数据库的性能表现做跟踪观察。有些业务上线之后,可能会遇到一些测试上没有遇到的问题,也可能突然会有执行计划跳变这样的特殊情况,需要人工去进行处理。基本上我们每个系统上线,都会遵循这四个步骤去做。
下图是目前中欧财富 TiDB 集群的架构示意图。存储层采用 3 台 TiKV 每台 3 副本的配置,一共 9 个 TiKV 节点。3 个 TiDB 节点,TiDB 和 PD 采用混合部署模式。另外准备了两台内存配置较高的 TiDB 节点,将一些特殊的、较大的 SQL、比较占内存的 SQL 和慢 SQL 单独扔到这两台 TiDB Server 上去跑,一定程度上起到资源隔离的作用(生产使用 V6 版本暂时没有资源隔离功能)。此外,还有 3 台 TiFlash 节点,两台物理机用做 TiCDC 。

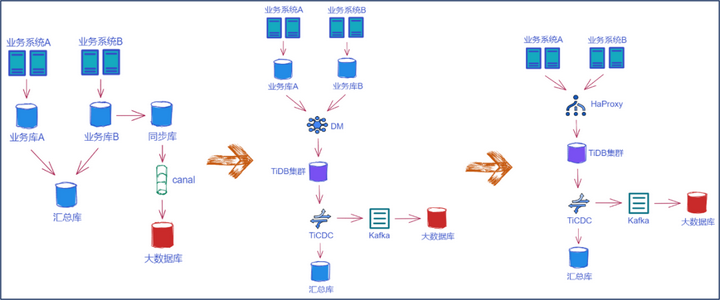
下面具体讲下业务的上线步骤。业务 A 和 业务 B 做了一些分表分库,分完库之后还需要做数据聚合,再同步到 MySQL 汇总库。除了汇总库之外,我们还有大数据平台,通过 Canal 去 MySQL 里面抽一些同步的数据,处理之后扔到大数据库。当要切到 TiDB 上的时候,我们先把 MySQL 的数据通过 DM 同步到 TiDB,TiDB 再通过 TiCDC 将数据写入到下游的汇总库,另一端输出到 Kafka 同步到大数据库。这个架构跑了一段时间,验证了数据同步是没问题后,就会把业务应用真正切到 TiDB 集群上。切换到时候只需要把 JDBC 链接内的地址配成 HAProxy 的地址,就完成一个业务系统的上线。
目前,中欧财富已经在 TiDB 集群上线了多套业务系统,包括费率系统、基金数据系统、风控系统、大事件系统、渠道系统和会员系统。我们计划在下半年上线更多的业务系统。TiDB 的应用正在向核心场景延伸,我们最新的组合投顾系统、营销系统、产品系统、用户系统,包括交易系统都已经在计划之中。
使用分布式数据库的收益
2021 年我们调研分布式数据库的时候,主要是因为我们的业务遇到了三个方面的挑战。
首先, 单表的数据增长非常迅速 ,我们开发和运维经常要配合着做各种分库分表,有些时候一个业务库没办法再分了。分表分库非常耗费人力成本,有些表刚分完没多久,单表数据量又很快增长到 5 亿+,数据需要再重新分片,这个工程量是非常巨大的。
其次,就是 大表的 DDL 。上两周就遇到这个问题,某个业务场景发生了变更,需要扩长字段,一张分表的 DDL 就要跑 6 小时,然后一共有十张分表,非常浪费时间。而且 DDL 在业务繁忙时间还不能跑,所以一个业务逻辑的 DDL 变更,DBA 可能需要拆分成几天,甚至几周去完成,对于运维的负担非常大。
第三,是 单节点写入 的问题。在 MySQL 传统的一主多从架构下,只有一个主节点可以写入,当遇到清算、调仓、跑批任务时,不能满足业务对写入吞吐量的要求。TiDB 是存算分离的架构,能在线扩容缩容,可以支撑高并发的 OLTP 场景,且满足金融级的高可用要求。
业务上线 TiDB 后,完美地解决了上述 3 个问题,从人力到成本都取得了非常大的收益。
TiDB V7.1 新特性探索
TiDB 每次大版本迭代,我们都会第一时间关注,因为一些新功能确实能解决一些用户的痛点。像我们以前用 MySQL 的话,没有遇到灾难级 BUG 的情况下,基本不会去升级 MySQL 的版本。因为我们觉得很久能带来的收益并不是很大,没必要去冒着风险。而 TiDB 的升级迭代,推出的新功能还是非常吸引人的。
比如 TiDB 7.1 LTS 版本,我们就发现里面的一些新特性非常有用。于是开始搭建环境进行探索,这里例举了四个我们的业务场景比较看重,而且后续会用到的新功能。
首先, 最重要是资源管控,也就是多租户功能 。数据库集群被划分为多个逻辑单元,可以将多个不同的应用放入一个集群中,即使某个业务应用出现负载飙升的情况,也不会影响其他业务的正常运行。金融业务场景下,统一集群启用资源管控之后,可以保证在线交易业务不会受批量或分析类业务的影响。
原有的 MySQL 架构还是一主两从,因为写入量比较大,而且还开着半同步复制,处理量大的时候,MySQL 主库还是有些延迟的,导致读写分离功能并不适用,两个从库基本上就是做灾难恢复用的,所以整体的资源使用率非常低。另外一些业务的流量高峰期是不同的,白天可能大家都在进行买卖,或者各渠道在推送数据,到了晚上可能就清算跑批。TiDB 可以通过多租户实现削峰填谷,提升整体资源使用率,降低运维成本。
另外资源管控还能起到限流的作用。生产上遇到 Bad SQL,或者是超级慢的 SQL 是很常见。如果遇到这种情况,我们在通过 SQL binding 的功能和资源管控的功能,结合起来使用,就能起到临时限流的作用。一般来说,限流做在 Proxy 层会比较多一点,但是我们现在不具备这种能力,如果数据库层遇到突发情况能做一个 SQL 级的、针对单 SQL 的限流,这是非常好的一个功能,不用去改代码重发应用,直接在数据库侧通过简单的 SQL Binding 和资源组就能做到。
第二个是 Partitioned Raft KV ,每个 Region 的数据都可以独立存储在单个实例中。这样每个 TiKV 实例可以存储更多的数据,我们比较关注的写入性能提升是非常大的,缩容扩容的速度也得到了显著提升。
第三个是负载自适应读取 。我们现在的业务包括之后要上的一些比较大的业务,都会出现读热点的情况,之前的打散热点方案都不适合我们的业务。有了负载自适应读取功能后,请求可以从其他 TiKV 节点读取副本,无需在热点 TiKV 节点排队等待。热点情况下,读取吞吐量可以提升 70% 到 200%,这个提升非常可观。
第四个是全局递增列 。这是 TiDB 6.5 的一个功能,但是我们生产在使用 6.1.2 版本,还没用上这个特性。全局递增列能保证 ID 唯一且单调递增,与 MySQL 的自增键完全一致了。之前预分配 ID 会导致我们部分业务的分页逻辑无法实现,需要开发同学对业务逻辑进行调整。有了全局自增列后,后面的业务上线时无需再对分页逻辑进行改造,进一步减少了开发成本。
未来展望
最后谈谈对 TiDB 的未来展望。
首先是希望推出 TiProxy,用来替代我们正在使用的 HAproxy。当前情况下如果 3 台 TiDB-server 进行升级,应用可能会连断三次,非常不友好,而 TiProxy 可以做到无损升级或重启。另外可以在 TiPrxoy 加上熔断和限流的功能,让整个架构更加灵活、可靠。TiProxy 甚至可以抓起整个数据库流量,并重放到其他环境或其他高版本的 TiDB 上,以检测新版本集群的稳定性,尤其在数据库版本迭代快速的情况下,让用户能更好地评估新版本是否可以用于生产。
第二,希望 TiDB 可以把功能平台进行集成。TiDB 提供很多工具平台,例如 Dashboard、TiUniManager、DM-web 等都是独立的平台,希望把这些工具都集成在一个集中管理平台上,甚至加上 TiCDC 的管理,这样对于运维人员的使用来说会更加便捷。
第三,希望提供巡检功能。系统上线之后查看问题都是靠人去 Dashboard 或 Grafna 平台查看具体情况,如果有巡检功能的话,可以省去人力开销。结合现在的 AI 技术,让 TiDB 出具一份集群的运行情况报告和优化建议,对用户来说是非常有意义的。