Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
33、Flink之hive介绍与简单示例
42、Flink 的table api与sql之Hive Catalog
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例: Apache Hive
- 1、支持的Hive版本
- 2、依赖项
- 1)、使用 Flink 提供的 Hive jar
- 2)、用户定义的依赖项
- 3)、移动 planner jar 包
- 3、Maven 依赖
- 4、连接到Hive
- 5、DDL&DML
本文介绍了Apache Hive连接器的使用,以具体的示例演示了通过java和flink sql cli创建catalog。
本文依赖环境是hadoop、zookeeper、hive、flink环境好用,本文内容以flink1.17版本进行介绍的,具体示例是在1.13版本中运行的(因为hadoop集群环境是基于jdk8的,flink1.17版本需要jdk11)。
更多的内容详见后续关于hive的介绍。
一、Table & SQL Connectors 示例: Apache Hive
Apache Hive 已经成为了数据仓库生态系统中的核心。 它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样它也是一个数据管理平台,可用于发现,定义,和演化数据。
Flink 与 Hive 的集成包含两个层面。
一是利用了 Hive 的 MetaStore 作为持久化的 Catalog,用户可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。 例如,用户可以使用HiveCatalog将其 Kafka 表或 Elasticsearch 表存储在 Hive Metastore 中,并后续在 SQL 查询中重新使用它们。
二是利用 Flink 来读写 Hive 的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以"开箱即用"的访问其已有的 Hive 数仓。 您不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
关于flink与hive集成的部分请参考:42、Flink 的table api与sql之Hive Catalog
1、支持的Hive版本
Flink 支持以下的 Hive 版本。
- 2.3
2.3.0
2.3.1
2.3.2
2.3.3
2.3.4
2.3.5
2.3.6
2.3.7
2.3.8
2.3.9 - 3.1
3.1.0
3.1.1
3.1.2
3.1.3
某些功能是否可用取决于您使用的 Hive 版本,这些限制不是由 Flink 所引起的:
- Hive 内置函数在使用 Hive-2.3.0 及更高版本时支持。
- 列约束,也就是 PRIMARY KEY 和 NOT NULL,在使用 Hive-3.1.0 及更高版本时支持。
- 更改表的统计信息,在使用 Hive-2.3.0 及更高版本时支持。
- DATE列统计信息,在使用 Hive-2.3.0 及更高版时支持。
2、依赖项
要与 Hive 集成,您需要在 Flink 下的/lib/目录中添加一些额外的依赖包, 以便通过 Table API 或 SQL Client 与 Hive 进行交互。 或者,您可以将这些依赖项放在专用文件夹中,并分别使用 Table API 程序或 SQL Client 的-C或-l选项将它们添加到 classpath 中。
Apache Hive 是基于 Hadoop 之上构建的, 首先您需要 Hadoop 的依赖,请参考 Providing Hadoop classes:
export HADOOP_CLASSPATH=`hadoop classpath`
有两种添加 Hive 依赖项的方法。第一种是使用 Flink 提供的 Hive Jar包。您可以根据使用的 Metastore 的版本来选择对应的 Hive jar。第二个方式是分别添加每个所需的 jar 包。如果您使用的 Hive 版本尚未在此处列出,则第二种方法会更适合。
注意:建议您优先使用 Flink 提供的 Hive jar 包。仅在 Flink 提供的 Hive jar 不满足您的需求时,再考虑使用分开添加 jar 包的方式。
1)、使用 Flink 提供的 Hive jar
下表列出了所有可用的 Hive jar。您可以选择一个并放在 Flink 发行版的/lib/ 目录中。

2)、用户定义的依赖项
您可以在下方找到不同Hive主版本所需要的依赖项。
- Hive 2.3.4
/flink-1.17.1
/lib
// Flink's Hive connector.Contains flink-hadoop-compatibility and flink-orc jars
flink-connector-hive_2.12-1.17.1.jar
// Hive dependencies
hive-exec-2.3.4.jar
// add antlr-runtime if you need to use hive dialect
antlr-runtime-3.5.2.jar
- Hive 3.1.0
/flink-1.17.1
/lib
// Flink's Hive connector
flink-connector-hive_2.12-1.17.1.jar
// Hive dependencies
hive-exec-3.1.0.jar
libfb303-0.9.3.jar // libfb303 is not packed into hive-exec in some versions, need to add it separately
// add antlr-runtime if you need to use hive dialect
antlr-runtime-3.5.2.jar
3)、移动 planner jar 包
把 FLINK_HOME/opt 下的 jar 包 flink-table-planner_2.12-1.17.1.jar 移动到 FLINK_HOME/lib 下,并且将 FLINK_HOME/lib 下的 jar 包 flink-table-planner-loader-1.17.1.jar 移出去。 具体原因请参见 FLINK-25128。你可以使用如下命令来完成移动 planner jar 包的工作:
mv $FLINK_HOME/opt/flink-table-planner_2.12-1.17.1.jar $FLINK_HOME/lib/flink-table-planner_2.12-1.17.1.jar
mv $FLINK_HOME/lib/flink-table-planner-loader-1.17.1.jar $FLINK_HOME/opt/flink-table-planner-loader-1.17.1.jar
只有当要使用 Hive 语法 或者 HiveServer2 endpoint, 你才需要做上述的 jar 包移动。 但是在集成 Hive 的时候,推荐进行上述的操作。
3、Maven 依赖
如果您在构建自己的应用程序,则需要在 mvn 文件中添加以下依赖项。 您应该在运行时添加以上的这些依赖项,而不要在已生成的 jar 文件中去包含它们。
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.17.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.17.1</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
4、连接到Hive
通过 TableEnvironment 或者 YAML 配置,使用 Catalog 接口 和 HiveCatalog连接到现有的 Hive 集群。
以下是如何连接到 Hive 的示例:
- java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/opt/hive-conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
// set the HiveCatalog as the current catalog of the session
tableEnv.useCatalog("myhive");
----------------------示例----------------------------
import java.util.List;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* @author alanchan
*
*/
public class TestHiveCatalogDemo {
/**
* @param args
* @throws DatabaseNotExistException
* @throws CatalogException
*/
public static void main(String[] args) throws CatalogException, DatabaseNotExistException {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
String name = "alan_hive";
// testhive 数据库名称
String defaultDatabase = "testhive";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog("alan_hive", hiveCatalog);
// 使用注册的catalog
tenv.useCatalog("alan_hive");
List<String> tables = hiveCatalog.listTables(defaultDatabase);
for (String table : tables) {
System.out.println("Database:testhive tables:" + table);
}
}
}
- sql
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'mydatabase',
'hive-conf-dir' = '/opt/hive-conf'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;
------------------具体示例如下----------------------------
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
+-----------------+
1 row in set
Flink SQL> CREATE CATALOG alan_hivecatalog WITH (
> 'type' = 'hive',
> 'default-database' = 'testhive',
> 'hive-conf-dir' = '/usr/local/bigdata/apache-hive-3.1.2-bin/conf'
> );
[INFO] Execute statement succeed.
Flink SQL> show catalogs;
+------------------+
| catalog name |
+------------------+
| alan_hivecatalog |
| default_catalog |
+------------------+
2 rows in set
Flink SQL> use alan_hivecatalog;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.CatalogException: A database with name [alan_hivecatalog] does not exist in the catalog: [default_catalog].
Flink SQL> use catalog alan_hivecatalog;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+-----------------------------------+
| table name |
+-----------------------------------+
| alan_hivecatalog_hivedb_testtable |
| apachelog |
| col2row1 |
| col2row2 |
| cookie_info |
| dual |
| dw_zipper |
| emp |
| employee |
| employee_address |
| employee_connection |
| ods_zipper_update |
| row2col1 |
| row2col2 |
| singer |
| singer2 |
| student |
| student_dept |
| student_from_insert |
| student_hdfs |
| student_hdfs_p |
| student_info |
| student_local |
| student_partition |
| t_all_hero_part_msck |
| t_usa_covid19 |
| t_usa_covid19_p |
| tab1 |
| tb_dept01 |
| tb_dept_bucket |
| tb_emp |
| tb_emp01 |
| tb_emp_bucket |
| tb_json_test1 |
| tb_json_test2 |
| tb_login |
| tb_login_tmp |
| tb_money |
| tb_money_mtn |
| tb_url |
| the_nba_championship |
| tmp_1 |
| tmp_zipper |
| user_dept |
| user_dept_sex |
| users |
| users_bucket_sort |
| website_pv_info |
| website_url_info |
+-----------------------------------+
49 rows in set
- ymal
execution:
...
current-catalog: alan_hivecatalog # set the HiveCatalog as the current catalog of the session
current-database: testhive
catalogs:
- name: alan_hivecatalog
type: hive
hive-conf-dir: /usr/local/bigdata/apache-hive-3.1.2-bin/conf
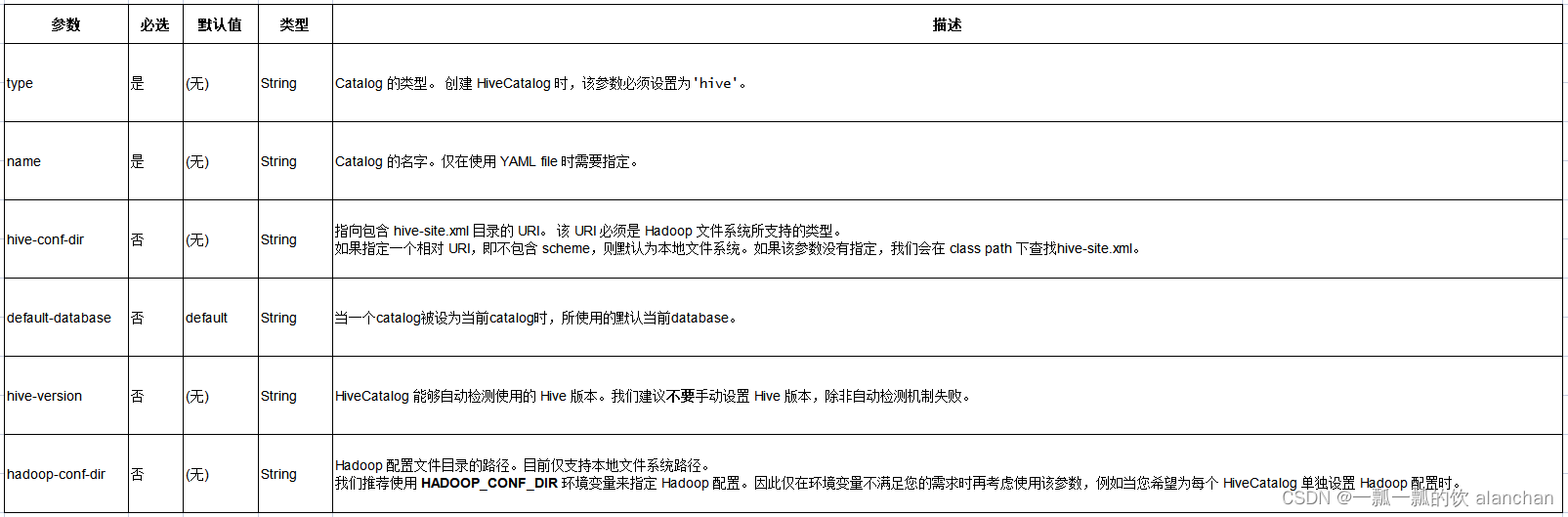
下表列出了通过 YAML 文件或 DDL 定义 HiveCatalog 时所支持的参数。
5、DDL&DML
在 Flink 中执行 DDL 操作 Hive 的表、视图、分区、函数等元数据时,参考:33、Flink之hive
Flink 支持 DML 写入 Hive 表,请参考:33、Flink之hive
以上,介绍了Apache Hive连接器的使用,以具体的示例演示了通过java和flink sql cli创建catalog。