总结来自:拓跋阿秀大佬的面试知识网站,侵权删
一.程序的内存分区/程序模型
内存分区分别是堆、栈,自由存储区,全局/静态存储区、常量存储区和代码存储区。
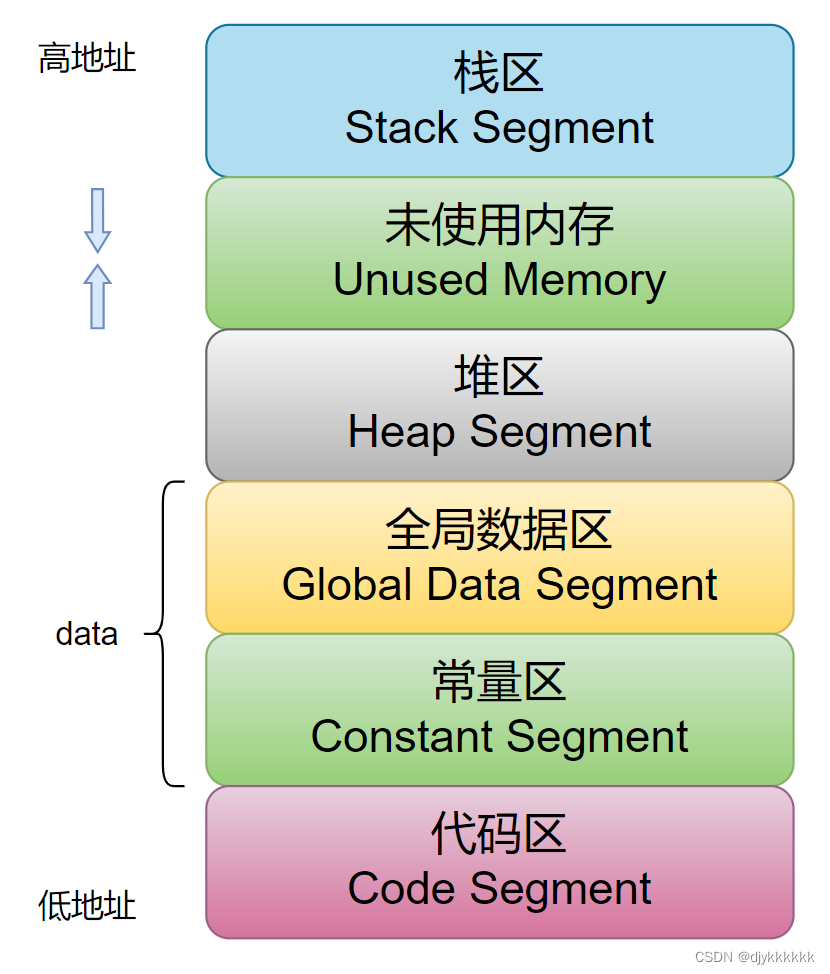
栈:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集里面,效率很高,但是分配的内存容量有限。
堆:就是哪些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
自由存储区:如果说堆是操作系统维护的一块内存,那么自由存储区就是C++中通过new和delete动态分配和释放对象的抽象概念。需要注意的是,自由存储区和堆比较像,但不等价。
全局/静态存储区:全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量和静态变量又分为初始化的和未初始化的,在C++中没有这个区分,它们共占同一块内存区,在该区定义的变量若没有初始化,则会被自动初始化,例如int型变量自动初始化为0。
常量存储区:这是一块比较特殊的存储区,这里面存放的是常量,不允许修改。
代码区:存放函数体的二进制代码。
二.多态的实现
在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据所指对象的实际类型来调用相应的函数,如果对象类型是派生类,就调用派生类的函数,如果对象类型是基类,就调用基类的函数。
#include<iostream>
#include<vector>
using namespace std;
class A {
public:
virtual void prints() {
cout << "A::prints" << endl;
}
A() {
cout << "A:构造函数" << endl;
}
};
class B:public A {
public:
virtual void prints() {
cout << "B::prints" << endl;
}
B() {
cout << "B:构造函数" << endl;
}
};
class C :public A {
public:
};
int main() {
A *b = new B();
b->prints();
b = new C();
b->prints();
return 0;
}
子类B重写了基类A的虚函数,子类C并没有重写,从结果分析,依然是体现了多态性???
虚表和虚基表指针
要理解这个问题,我们要引出虚表和虚基表
虚表:虚函数表的缩写,类中含有 virtual 关键字修饰的方法时,编译器会自动生成虚表,它是在编译器确定的
虚表指针:在含有虚函数的类实例化对象时,对象地址的前四个字节存储的指向虚表的指针,它是在构造函数中被初始化的
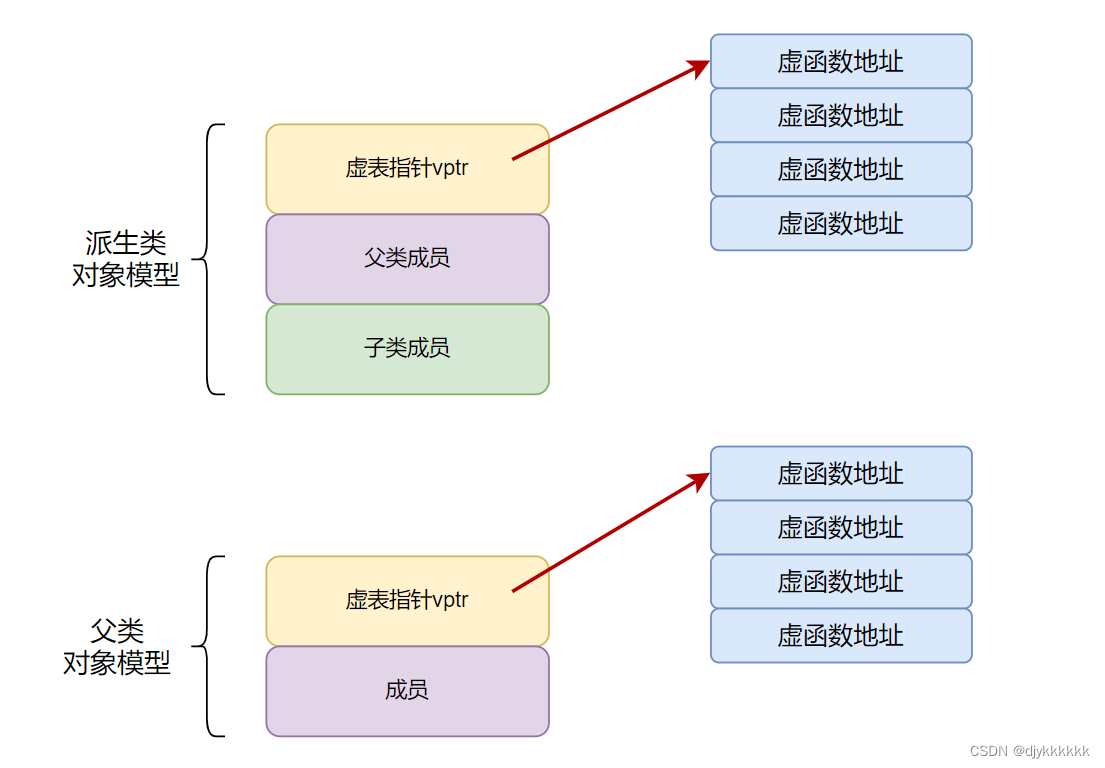
上图就是虚表和虚表指针在基类对象和派生类对象中的模型,下面阐述实现多态的过程:
1.编译器在发现基类中含有虚函数时,会自动为每个含有虚函数的类生成一份虚表,该表是一个一维数组,虚表里保存了虚函数的入口地址
2.编译器会在每个对象的前四个字节中保存一个虚表指针,即vptr,指向对象所属类的虚表
3.所谓的合适时机,在派生类定义对象时,程序运行会自动调用构造函数,在构造函数中创建虚表并对虚表指针进行初始化。在构造子类对象时,会先调用父类的构造函数,此时,编译器只“看到了”父类,并为父类对象初始化虚表指针,令它指向父类的虚表;当调用子类的构造函数时,为子类对象初始化虚表指针,令它指向子类的虚表
4.当派生类对基类的虚函数没有重写时,派生类的虚表指针指向的是基类的虚表;当派生类对基类的虚函数重写时,派生类的虚表指针指向的是自身的虚表;当派生类中有自己的虚函数时,在自己的虚表中将此虚函数地址添加在后面。
所以,指向派生类的基类指针在运行时,就可以根据派生类对虚函数的重写情况动态的进行调用,从而实现多态性。
三.为什么析构函数一般写成虚函数?
由于类的多态性,通常通过父类指针或引用来操作子类对象。因为多套允许我们以统一的方式处理不同的派生类对象,并且在运行时确定要调用的方法。
如果析构函数不被声明为虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样会造成派生类析构不完全,造成内存泄漏。
这种行为是为了确保资源的正确释放。由于我们只知道父类的类型,编译器无法确定指针指向的是哪个子类对象,因此只能调用父类的析构函数来释放资源。
没有虚析构:
#include<iostream>
#include<vector>
using namespace std;
class A {
public:
virtual void prints() {
cout << "A::prints" << endl;
}
A() {
cout << "A:构造函数" << endl;
}
virtual ~A() {
cout << "A:析构函数 " << endl;
}
};
class B:public A {
public:
virtual void prints() {
cout << "B::prints" << endl;
}
B() {
cout << "B:构造函数" << endl;
}
~B() {
cout << "B:析构函数 " << endl;
}
};
int main() {
A *b = new B();
b->prints();
delete b;
b = NULL;
return 0;
}
虚析构:
#include<iostream>
#include<vector>
using namespace std;
class A {
public:
virtual void prints() {
cout << "A::prints" << endl;
}
A() {
cout << "A:构造函数" << endl;
}
virtual ~A() {
cout << "A:析构函数 " << endl;
}
};
class B:public A {
public:
virtual void prints() {
cout << "B::prints" << endl;
}
B() {
cout << "B:构造函数" << endl;
}
~B() {
cout << "B:析构函数 " << endl;
}
};
int main() {
A *b = new B();
b->prints();
delete b;
b = NULL;
return 0;
} 
分析:可以看到析构函数是,先从子类析构,再到父类析构
四.sort()函数中的排序函数是快排还是插入排序?
sort()源码中采用的是 IntroSort内省式排序的混合式排序算法。
第一步:
- 首先进行判断排序的元素是否大于 stl_threshould ,stl_thresould是一个常量值是16,意思是说我传入的元素规模小于16的时候直接采用插入排序。
- (为啥呢?因为插入排序在面对“几近排序”的序列时,表现更好,而快排是通过递归实现的,会为了极小的子序列产生很多的递归调用,在区间长度小的时候经常不如插入排序效率高)
第二步:
- 如果说我们的元素规模大于16,那就需要判断是不是能采用快速排序,如何判断呢?
- 快排是使用递归来实现的,如果说我们进行判断我们的递归升读有没有到达递归升读的限制阈值 2*lg(n) ,如果递归深度没到达就使用快速排序。
第三步:
- 如果说大于我们的最深递归深度阈值的话,这个时候说明快排复杂度退化了(比如很不巧基准元素多次选取到了当前区间中最小或最大的元素,这种情况下,每次划分只能将区间缩小1个元素,造成递归深度过深)
- 此时采用堆排序,堆排序是可以保证稳定 O(nlogn) 的时间复杂度的。
五.STL中map、set、unordered_set、unordered_map的区别和应用场景
map
map支持键值的自动排序,底层机制是红黑树,红黑树的查询和维护时间复杂度均为 O(logn) ,但是占用空间比较大,因为每个节点都要保持父节点、孩子节点及颜色信息。
set
set与map类似,set的底层实现通常也是红黑树。set是一种特殊的Map,只有键没有值。
unordered_map
unordered_map是C++ 11 新添加的容器,底层机制是哈希表,通过hash函数计算元素位置,其查询时间复杂度为 O(1) ,维护时间与 buclet 桶所维护的 list 长度有固安,但是建立 hash 表耗时较大。
unordered_set
unordered_set与unordered_map 类似,unordered_set的底层实现通常也是哈希表。unordered_set 是一种特殊的unordered_map,只有键没有值。
从底层机制和特点可以看出:map适用于有序数据的应用场景,unordered_map适用于高效查询的应用场景。
六.move用过吗?(不太明白)
C++中的move语义是一种高效的资源转移机制,可以帮助我们避免不必要的拷贝操作,提高程序性能。
std::move 的使用场景
当需要将资源从一个对象转移到另一个对象时,可以使用std::move。例如,在容器中移动元素,在算法中交换数据等。需要注意的是,只有可移动的对象才能使用移动语义,否则可能导致未定义行为。(比如容器加了const,无法修改)
避免不必要的拷贝
使用移动语义可以避免不必要的拷贝操作,从而提高性能。例如,在复制一个大型对象时,如果使用移动语义,只需要进行一次内存分配和一次指针拷贝,而不需要进行多次拷贝操作。