本文提出了一个多帧光流估计模型 VideoFlow,旨在充分挖掘视频中的时序信息和运动规律,避免当前主流方法只以两帧图片作为输入而面临的信息瓶颈,显著提升了光流估计的性能。
在公开的 Sintel Bechmark 上,VideoFlow 在 Clean 和 Final 两个子集分别取得了 0.991 与 1.649 AEPE,与之前发表的最好结果(1.073 和 1.943)相比,误差下降了 7.6% 和 15.1%,并且是首个在 Clean 子集实现亚像素级别误差的模型。在自动驾驶 KITTI-2015 Benchmark 上,VideoFlow 实现了 3.65% 的 Fl-all error,相比之前发表的最好结果(4.52%)误差降低了 19.2%。模型与训练代码均已开源。
论文标题:
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
论文链接:
https://arxiv.org/abs/2303.08340
代码链接:
https://github.com/XiaoyuShi97/VideoFlow

是基于什么样的思考完成了这篇文章?
光流的目标是估计源图象中每个像素在目标图片的对应位置。在许多下游视频处理任务中,如视频修复、动作识别、视频压缩、视频插帧,光流是表征图片间对应关系和场景内运动信息的基础性方法。
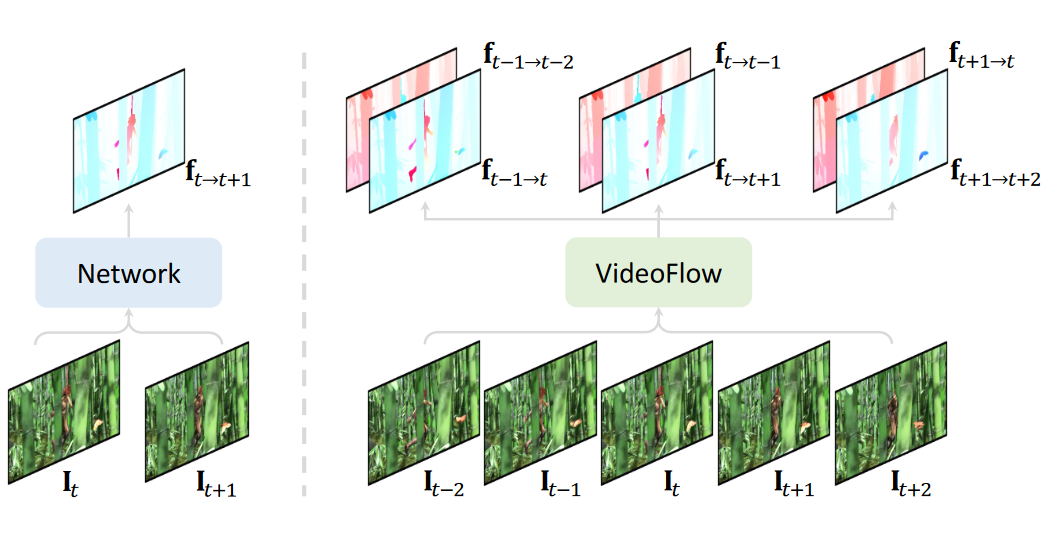
然而,主流的光流估计模型普遍只以相邻的两帧图片作为输入,面临以下两个问题。
两帧模型面临信息瓶颈:由于遮挡、大范围移动、弱纹理等情况存在,只以两帧图片作为输入进行光流预测面临极大的歧义(ambiguity)。
两帧模型与下游任务需求不匹配:大多数下游视频任务需要对视频的所有帧进行光流估计,由于缺乏相应的多帧光流模型,下游任务只能通过多次使用两帧模型获得光流估计。
因此,在本篇文章中,我们聚焦于多帧光流模型设计,充分利用更多帧输入图片带来的信息,大幅提高光流估计的准确性。另一方面,VideoFlow 同时估计双向光流,并且可以处理任意帧数的视频,更好满足下游视频任务的需求。

这项工作做了什么?
VideoFlow 主要由两部分组成。我们首先考虑以相邻三帧图片作为输入时,模型应该如何设计。我们提出了 TRi-frame Optical Flow(TROF)模块,核心在于同时预测从中间帧到前后两帧的光流,因为这两个方向的光流从相同的像素出发,避免之前方法由于单向 warp 光流无法对齐而产生的误差。
当输入帧数大于三帧时,基于三帧模块 TROF,我们额外引入一个运动传递(Motion Propagation)模块(MOP),通过在相邻的三帧模块之间传递运动信息,增大了在时序维度的感受野,进一步提高光流估计的准确性。
2.1 三帧模型
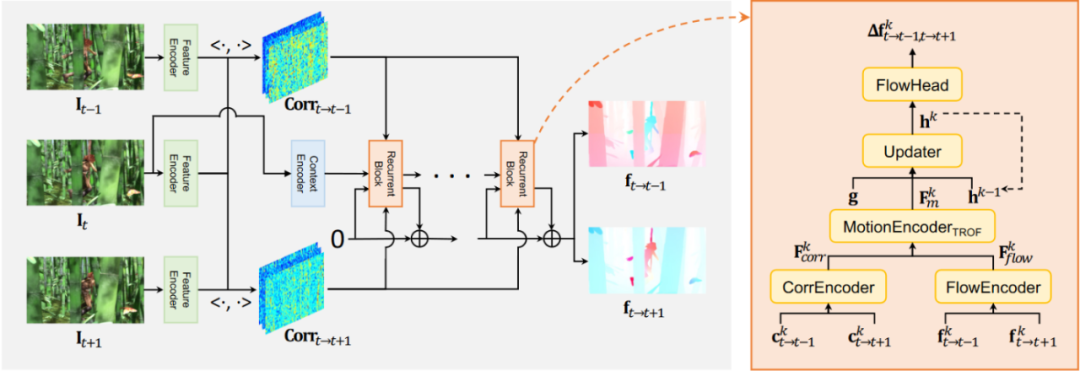
当输入为三帧相邻的图片时,使用共享权重的特征编码器获得对应特征图,然后分别构建中间帧与前后两帧的 cost volume。我们采用类似 RAFT 的结构,迭代优化光流估计。不同之处在于,在每一步迭代时,我们采用最简单的 concat 操作,将输入变为双方向的 cost feature 和当前估计的双向光流值。通过综合双向的相似性信息和运动信息,TROF 模型能利用额外的一帧提高光流估计的准确性。
2.2 多帧模型
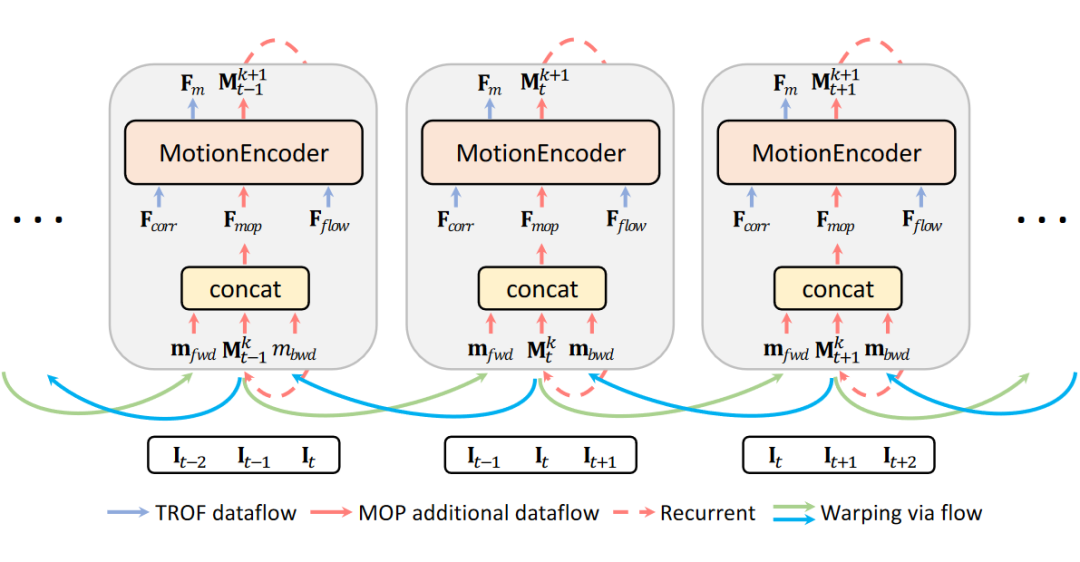
当输入多于三帧时,我们以相邻的三帧作为基础单元(stride 为 1),在每个三帧单元中延续之前的 TROF 模型。为了实现不同单元之间信息的传递与融合,我们提出了运动传递(Motion Propagation)模块(MOP)。
具体来说,每个三帧单元额外维护一个运动状态向量 M_t,在每一步迭代更新之前,前后两个三帧单元的运动状态向量(m_fwd 和 m_bwd)会根据光流 warp 到中间的三帧单元,实现相邻单元的信息传递。每个一步结束后,运动状态向量都会更新。由于我们采用迭代更新的方式,随着迭代步数的增加,时序维度的感受野会不断变大,每个三帧单元能获得更多的信息,因而能更加准确地估计光流。

实验结果
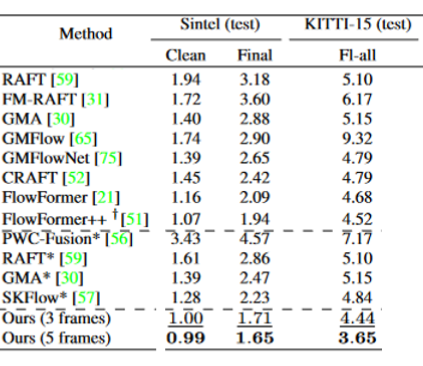
我们在 Sintel 和 KITTI-2015 两个数据集上评测 VideoFlow。其中 Sintel 有 Clean 和 Final 两个子集,它们内容相同的,但是 Final 子集中的图象存在运动模糊,因而更加困难。
我们的三帧模型已经超越了之前所以发表的方法。五帧模型进一步提高了准确度。值得注意的是,VideoFlow 是首个在 Sintel Clean 子集实现亚像素级别误差的方法。
具体而言,在 Sintel Bechmark 上,VideoFlow 在 Clean 和 Final 两个子集分别取得了 0.991 与 1.649 AEPE,与之前发表的最好结果(1.073 和 1.943)相比,误差下降了 7.6% 和 15.1%。在自动驾驶 KITTI-2015 Benchmark 上,VideoFlow 实现了 3.65% 的 Fl-all error,相比之前发表的最好结果(4.52%)误差降低了 19.2%。

可视化分析

我们展示了 KITTI-2015 Benchmark 上的两个典型例子,其中白色表示预测结果为静止,不同颜色代表不同预测方向。
在第一行中,蓝框中的一束白光是典型的镜头炫光现象,FlowFormer++ 错误的将其识别成了运动的前景物体,而 VideoFlow 没有受到干扰,正确预测背景房屋的光流。
第二行蓝框中,指示牌反面与路过车辆颜色同为接近的灰色,因此 FlowFormer++ 将指示牌误认为车辆一部分(预测光流接近)。VideoFlow 得益于多帧信息,成功区分出指示牌为静止前景(蓝框内白色圆形区域),与移动的背景车辆运动不同。
更多阅读



#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·









![java八股文面试[数据库]——MySQL索引的数据结构](https://img-blog.csdnimg.cn/46dccb866952400abe51c0c9661e8bbb.png)