伴随着业务的不断发展,逐渐由单库单表向分库分表进行发展。在这个过程中不可避免的一个问题是确保主键要的唯一性,以便于后续的数据聚合、分析等等场景的使用。在进行分库分表的解决方案中有多种技术选型,大概分为两大类客户端分库分表、服务端分库分表。例如 Sharding-JDBC、ShardingSphere、 MyCat、 ShardingSphere-Proxy等等。
在这个燥热的夏天,又突然收到告警,分库分表的主键冲突了,这还能忍?不,坚决不能忍,必须解决掉!后面咱们慢慢道来是如何破局的,如何走了一条坎坷路……
翻山第一步
咱们的系统使用的是ShardingSphere进行分库分表的,大概的配置信息如下: (出于信息的安全考虑,隐藏了部分信息,只保留的部分内容,不要在意这些细节能说明问题即可)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd http://shardingsphere.apache.org/schema/shardingsphere/sharding http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd">
<!--数据源-->
<bean id="database1" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
</bean>
<bean id="database2" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
</bean>
<bean id="database3" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
</bean>
<sharding:inline-strategy id="databaseStrategy" sharding-column="cloum1" algorithm-expression="table1_$->{(Math.abs(cloum1.hashCode()) % 512).intdiv(32) }" />
<sharding:inline-strategy id="orderNoDatabaseStrategy" sharding-column="cloum2" algorithm-expression="table2_$->{(Math.abs(cloum2.hashCode()) % 512).intdiv(32) }" />
<sharding:inline-strategy id="businessNoDatabaseStrategy" sharding-column="cloum3" algorithm-expression="table3_$->{(Math.abs(cloum3.hashCode()) % 512).intdiv(32) }" />
<!-- 主键生成策略 -雪花算法-->
<sharding:key-generator id="idKeyGenerator" type="SNOWFLAKE" column="id" props-ref="snowFlakeProperties"/>
<sharding:data-source id="dataSource">
<sharding:sharding-rule data-source-names="database1,database2,database3">
<sharding:table-rules>
<sharding:table-rule logic-table="table1"
actual-data-nodes="database1_$->{0..15}.table1_$->{0..31}"
database-strategy-ref="orderNoDatabaseStrategy"
table-strategy-ref="order_waybill_tableStrategy"
key-generator-ref="idKeyGenerator"/>
<sharding:table-rule logic-table="table2"
actual-data-nodes="database2_$->{0..15}.table2_$->{0..31}"
database-strategy-ref="databaseStrategy"
table-strategy-ref="waybill_contacts_tableStrategy"
key-generator-ref="idKeyGenerator"/>
<sharding:table-rule logic-table="table3"
actual-data-nodes="database3_$->{0..15}.table3->{0..31}"
database-strategy-ref="databaseStrategy"
table-strategy-ref="waybill_tableStrategy"
key-generator-ref="idKeyGenerator"/>
</sharding:table-rules>
</sharding:sharding-rule>
</sharding:data-source>
<bean id="sqlSessionFactory" class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:spring/mybatis-env-setting.xml"/>
<property name="mapperLocations" value="classpath*:/mapper/*.xml"/>
</bean>
</beans>
从上面的配置可以看出配置的是"SNOWFLAKE" 主键使用的是雪花算法,雪花算法产生的ID的组成总计64位,第一位为符号位不用,后41位为时间戳用于区别不同的时间点,在后面10位为workId用于区别不同的机器,最后12位为sequence用于同一时刻同一机器的并发数量。

那接下来就看看咱们自己的系统是怎么配置的吧,其中的属性snowFlakeProperties配置如下,其中的max.vibration.offset配置表示sequence的范围为1024。按照正常的理解任何单个机器的配置都很难达到这个并发量,难道是这个值没有生效?
<sharding:key-generator id="idKeyGenerator" type="SNOWFLAKE" column="id" props-ref="snowFlakeProperties"/>

shardingsphere中实现获取主键的实现源码如下简述,具体的实现类org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator,从源码看源码竟然一个日志都没有,那让咱们怎么去排查呢?怎么证明咱们的猜想是否正确的呢?囧……
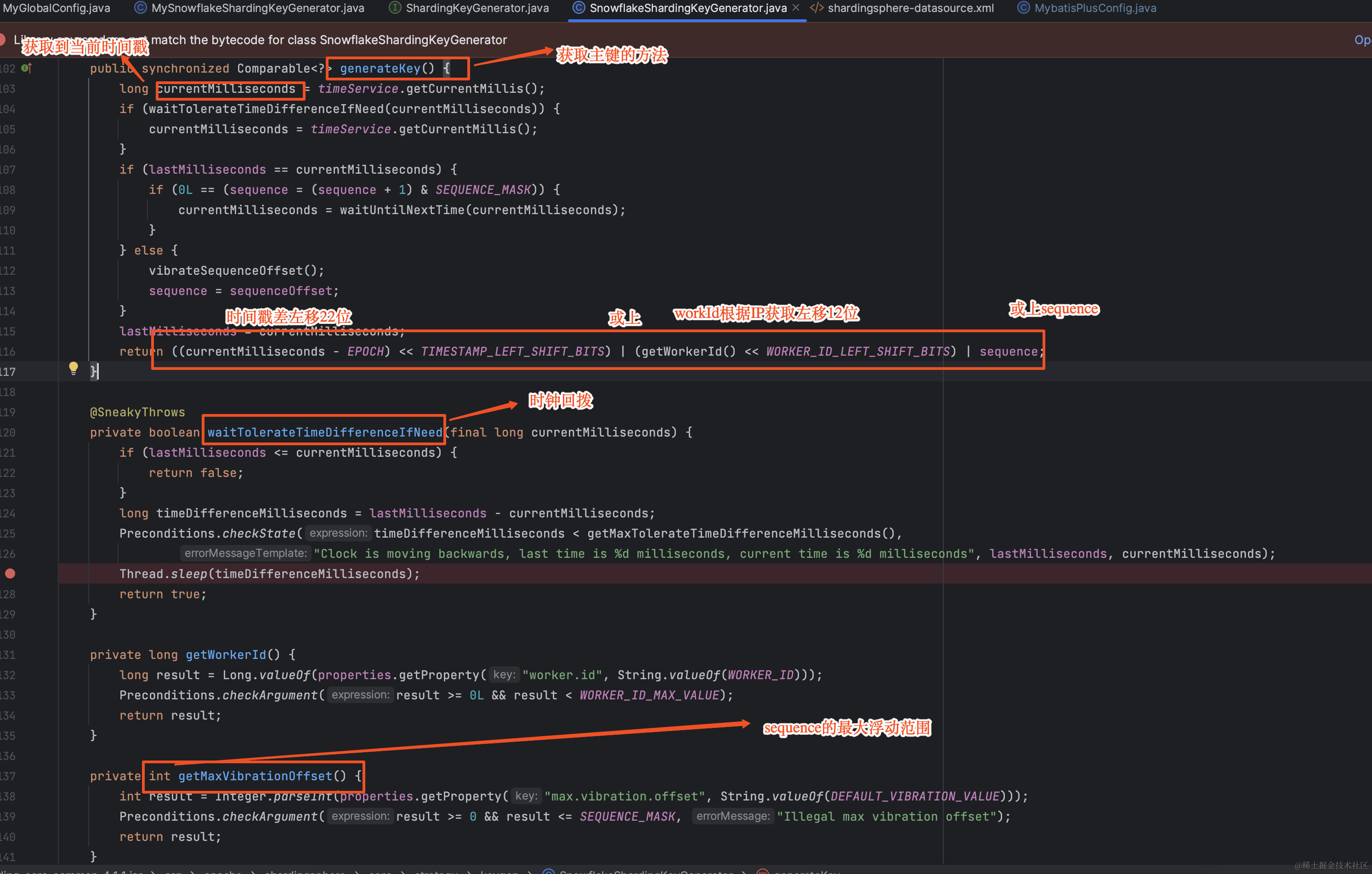
真是败也萧何成也萧何,shardingsphere是通过java的SPI的方式进行的主键生成策略的扩展。自定义实现方式如下:实现org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator接口,如果自己想要实现使用SPI方式进行加载即可,那就让咱们自己加日志吧,走你……

既然都自己写实现了,那日志就该加的都加吧,咱这绝不吝啬这几行日志
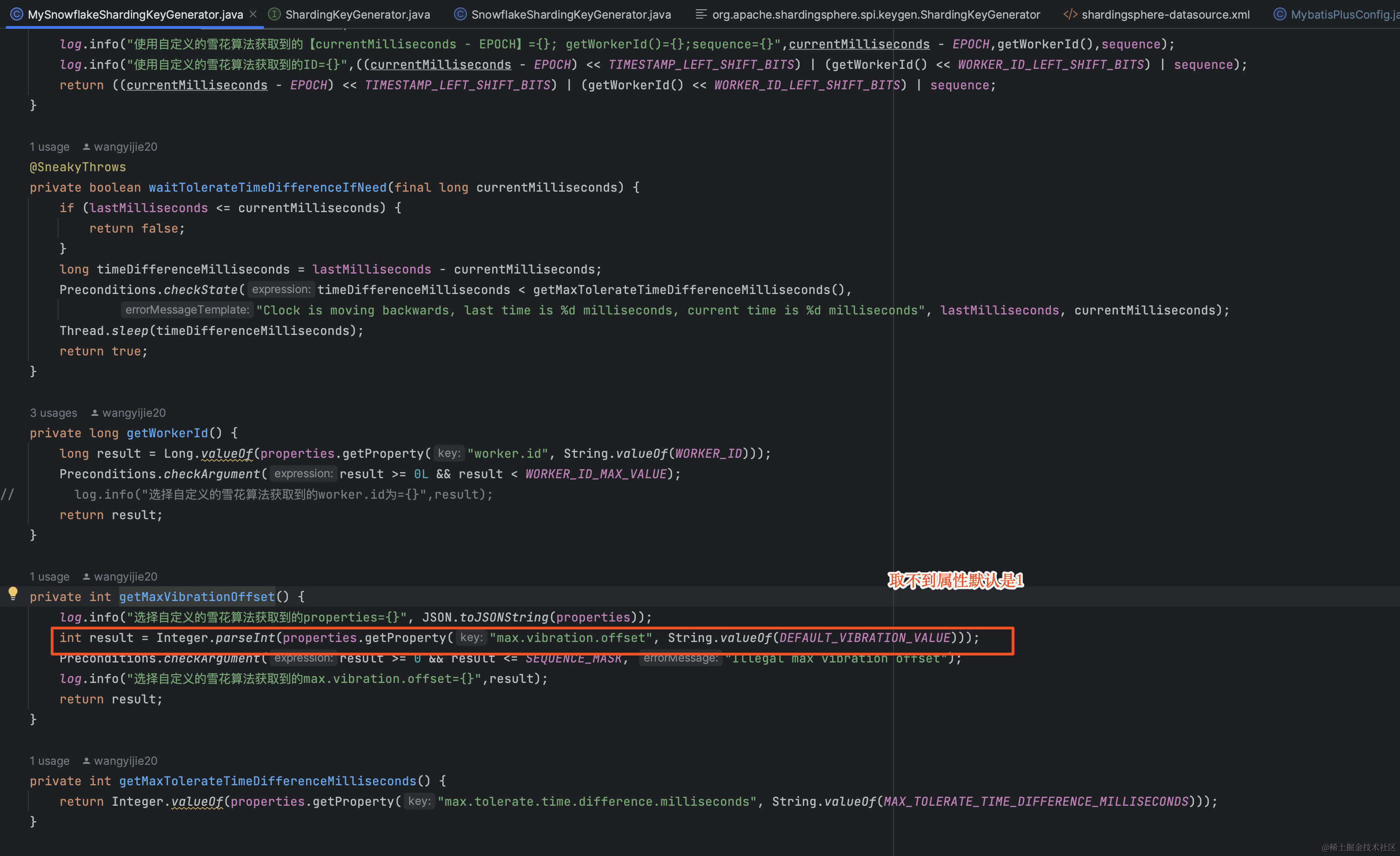
修改主键选择生成策略为自己实现的类 type=“MYSNOWFLAKE”
<sharding:key-generator id="idKeyGenerator" type="MYSNOWFLAKE" column="id" props-ref="snowFlakeProperties"/>
启动看日志,属性中有max.vibration.offset=1024这个属性,竟然依旧拿到的还是默认的值1,惊讶中,细细一瞅,终究发现了问题,在getProperty(key)时如果返回的不是String类型那么为null,进而取值默认值1。从咱们的系统配置中可以看到系统配置的int类型的的1024,所以取值默认值1就说通了。
INFO 2023-08-17 14:07:51.062 2174320.63604.16922524693996408 176557 com.jd.las.waybill.center.config.MySnowflakeShardingKeyGenerator.getMaxVibrationOffset(MySnowflakeShardingKeyGenerator.java:107) -- 选择自定义的雪花算法获取到的properties={"max.vibration.offset":1024,"worker.id":"217","max.tolerate.time.difference.milliseconds":"3000"}
INFO 2023-08-17 14:07:51.063 2174320.63604.16922524693996408 176558 com.jd.las.waybill.center.config.MySnowflakeShardingKeyGenerator.getMaxVibrationOffset(MySnowflakeShardingKeyGenerator.java:110) -- 选择自定义的雪花算法获取到的getMaxVibrationOffset=1


截止到目前主键重复的问题终于可以解释的通了,因为并发支持的是0~1总共2个并发,所以在生产系统中尤其出现生产波次的时候出现重复值的可能性是存在的,然后把1024变成字符串修改上线,相信系统后面应该不会产生此类问题了。
越岭第二步
如果生活总是喜欢跟你开玩笑,逗你玩,那你就配合它笑一笑吧。
当上完线后,过了一段时间发现重复主键的问题竟然依旧存在只是频率少了些,不科学呀……
重新梳理思路,进行更详细的日志输出,下单进行验证,将接单落库这坨代码一并都加上日志以及触发雪花算法的生成的ID也加上日志

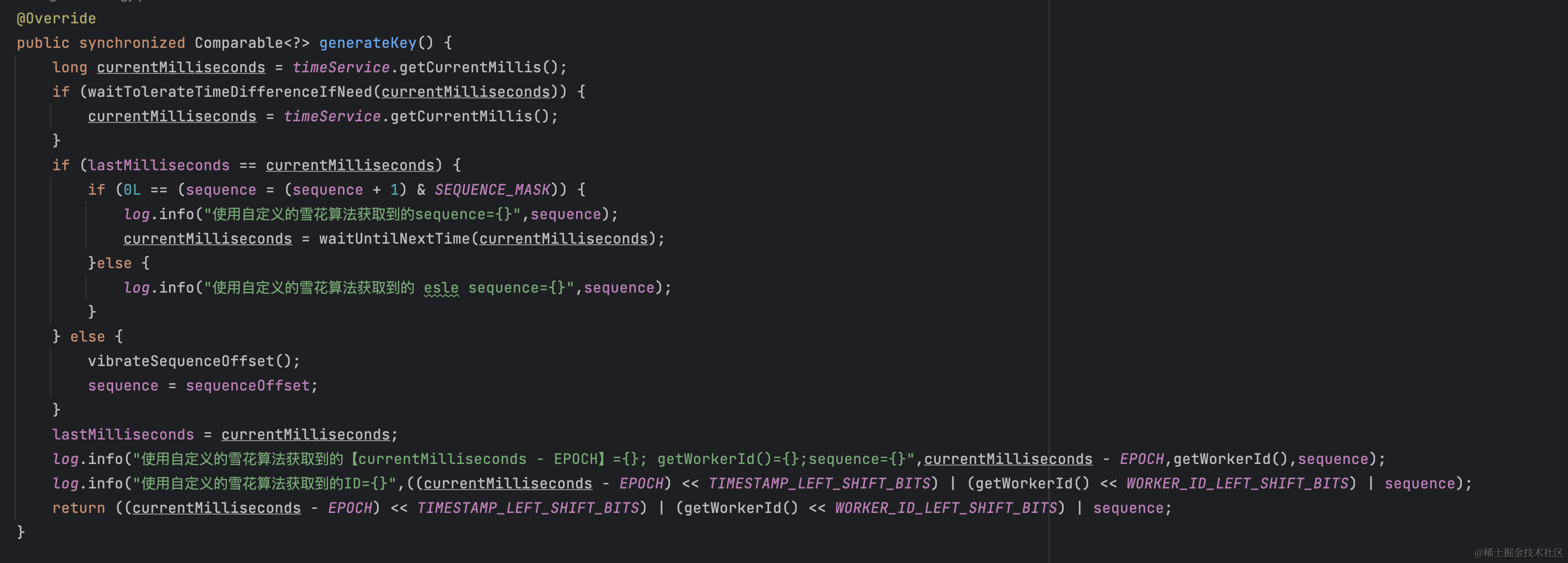
通过日志分析,又又又发现"灵异事件",10条插入SQL,只有两条触发了shardingsphere的雪花算法,诧异的很呀~

查看其他8张表落库的ID数据如下图,ID(1692562397556875266) 都为1692开头且长度20位,而shardingsphere产生的ID(899413419526356993)都为899开头且长度19位,很明显这8张表的主键不是shardingsphere生成的,那是这20位的数据哪来的呢???从ID上看明显也不是自增产生的主键,又不科学了……

又是一个深夜……
梳理思路重新在锊,主键相关的除了数据自增长、shardingsphere配置的雪花还有唯一的一个相关的组件那就是mybatis,由于项目是很早之前的应用了,使用的是baomidou的mybaits插件,如图是插件的入口,MybatisSqlSessionFactoryBean实现FactoryBean, InitializingBean, ApplicationListener几个Spring的接口

baomidou涉及该块问题的源码如下:

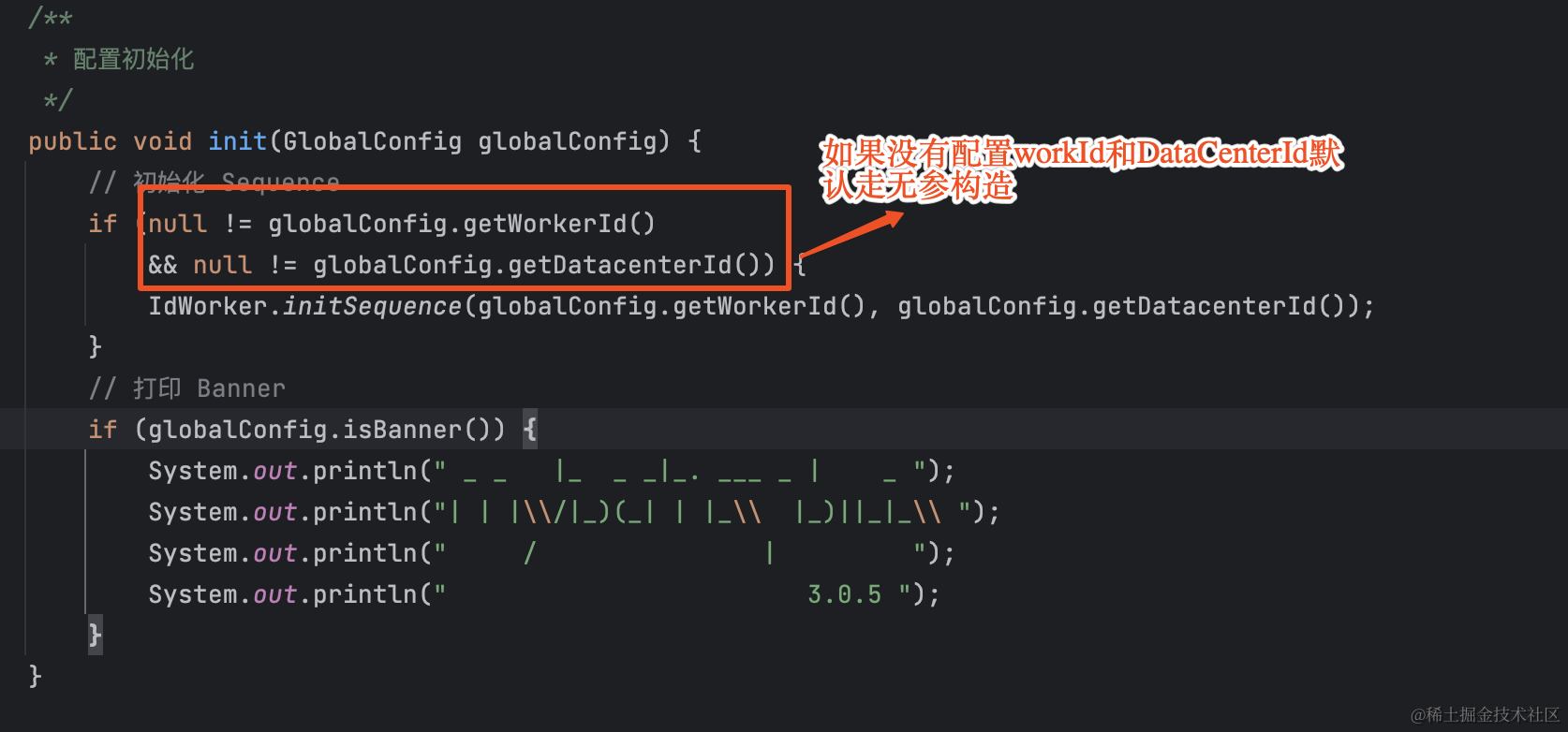
如果GlobalConfig没有配置workId和DataCenterId会使用无参构造,默认的workId
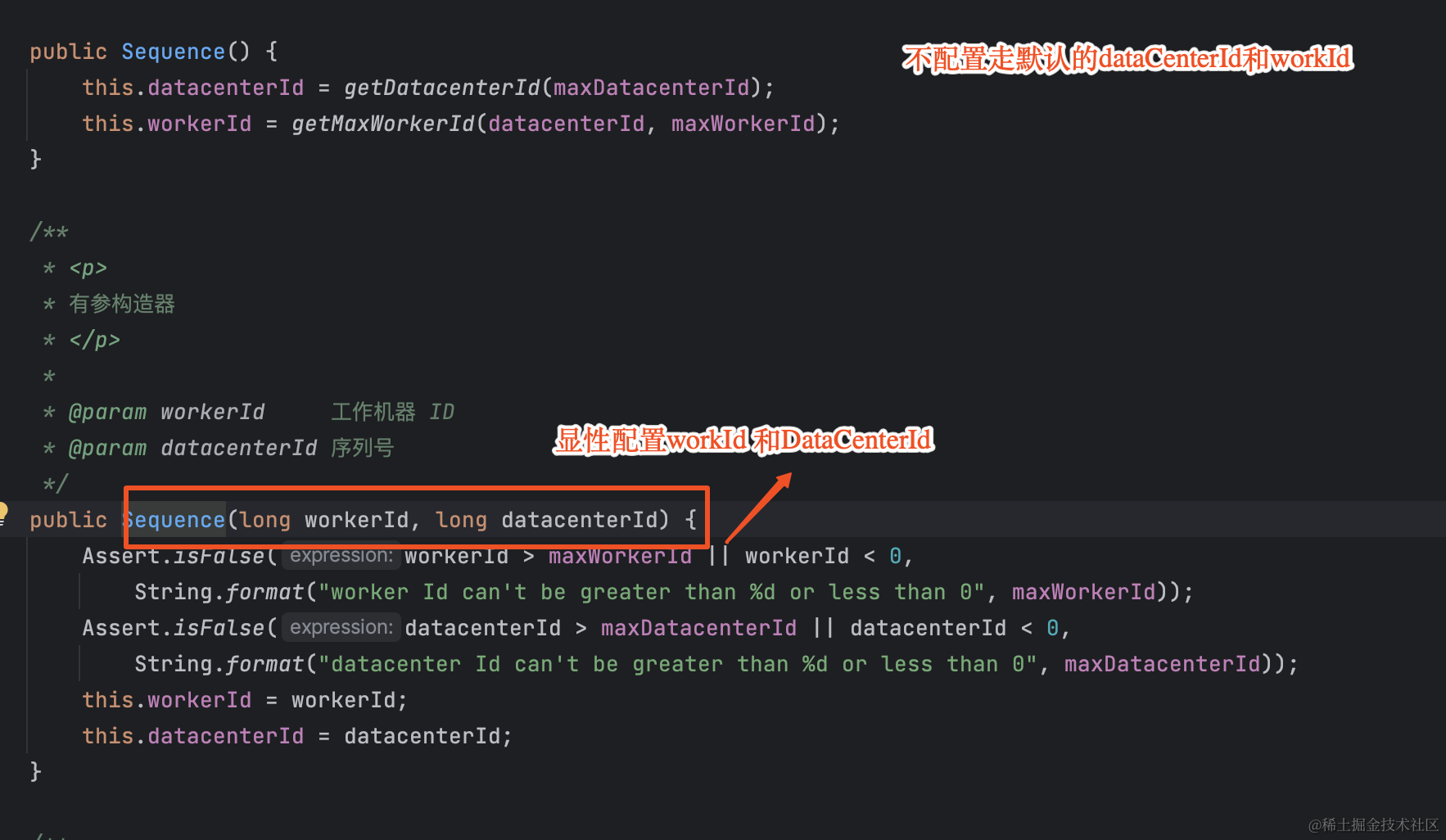

baomidou的雪花算法和shardingphere思路一致有一点点区别在于第12位和22位有datacenter<<17|workId<<12获取,且datacenter和workId需要在0~31之间

不同机器的Name:
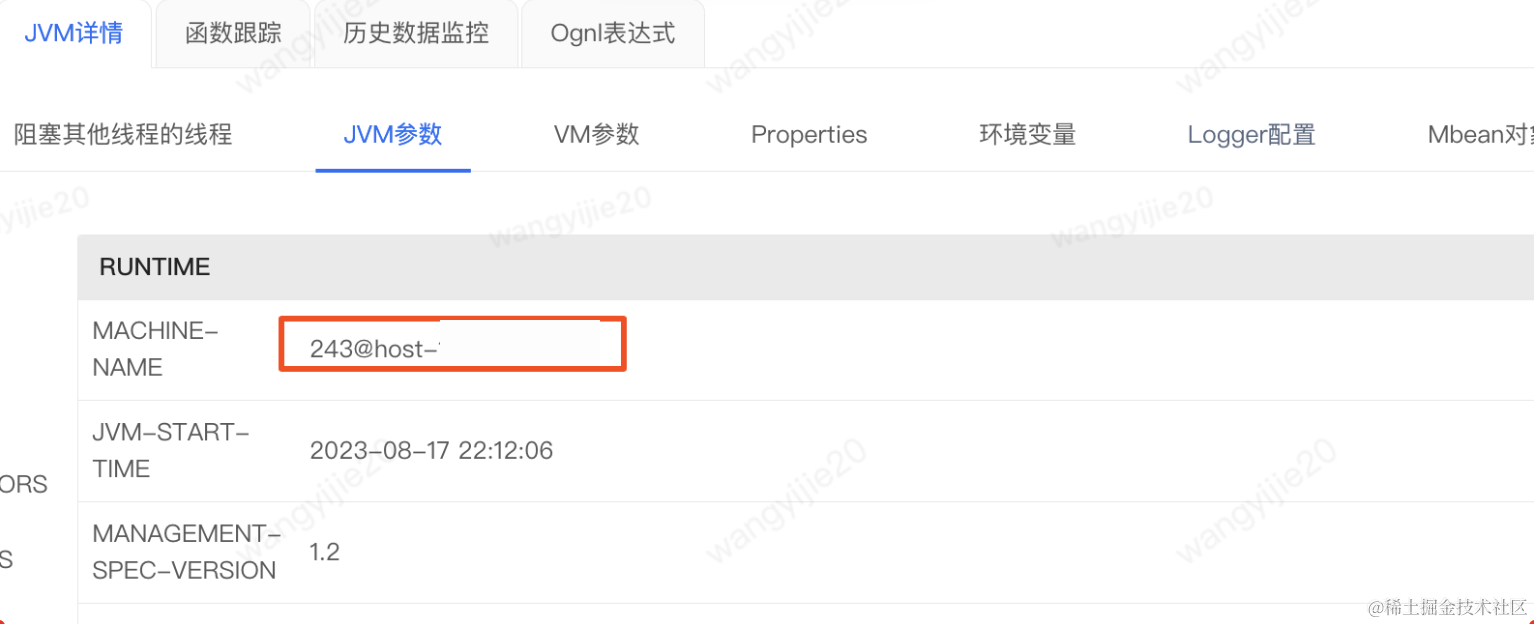
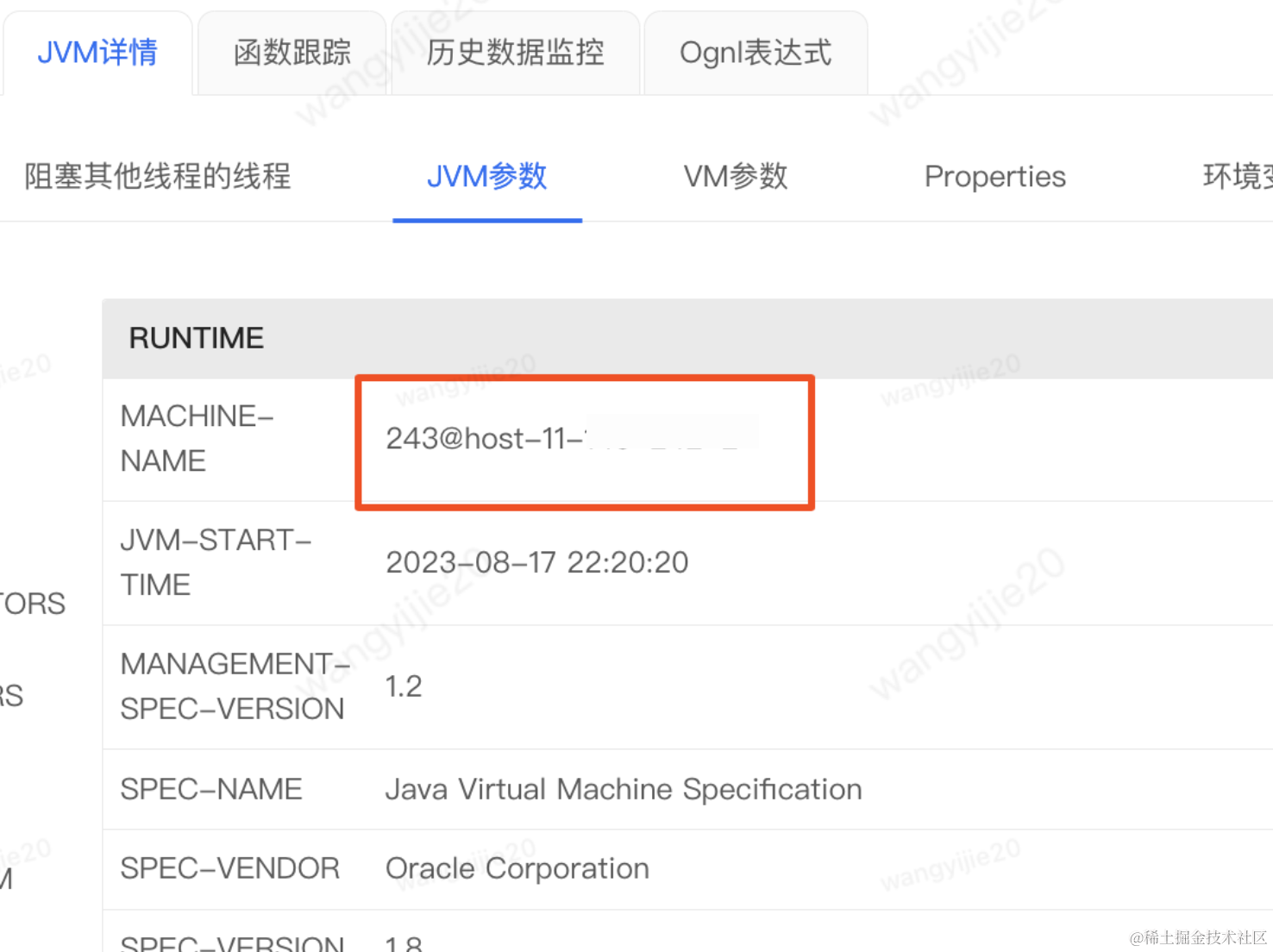
所以又解释了为什么不同机器会出现相同的主键问题,但是如果有细心的同学就会问为啥10张表中有8张表走的是baomidou的雪花算法呢,那是因为baomidou会判断保存的入参实体bean上是否有id字段,是否能匹配上该字段,如果存在则在baomidou这层就给赋值了baomidou雪花算法生产的ID,后续就不会再次触发shardingsphere中ID生成,进而导致该问题。
截止到目前终于又解释通了为什么跨机器会产生相同的主键问题。
问题的解决方式:
baomidou配置的过程中指定workId和centerDataId,但是需要确保centerDataId<<17|workId<<12确保唯一。类比shardingphere,借用shardingphere中的12~22位唯一数,前5高位给(centerDataId<<17),后5低位给workId<<12;
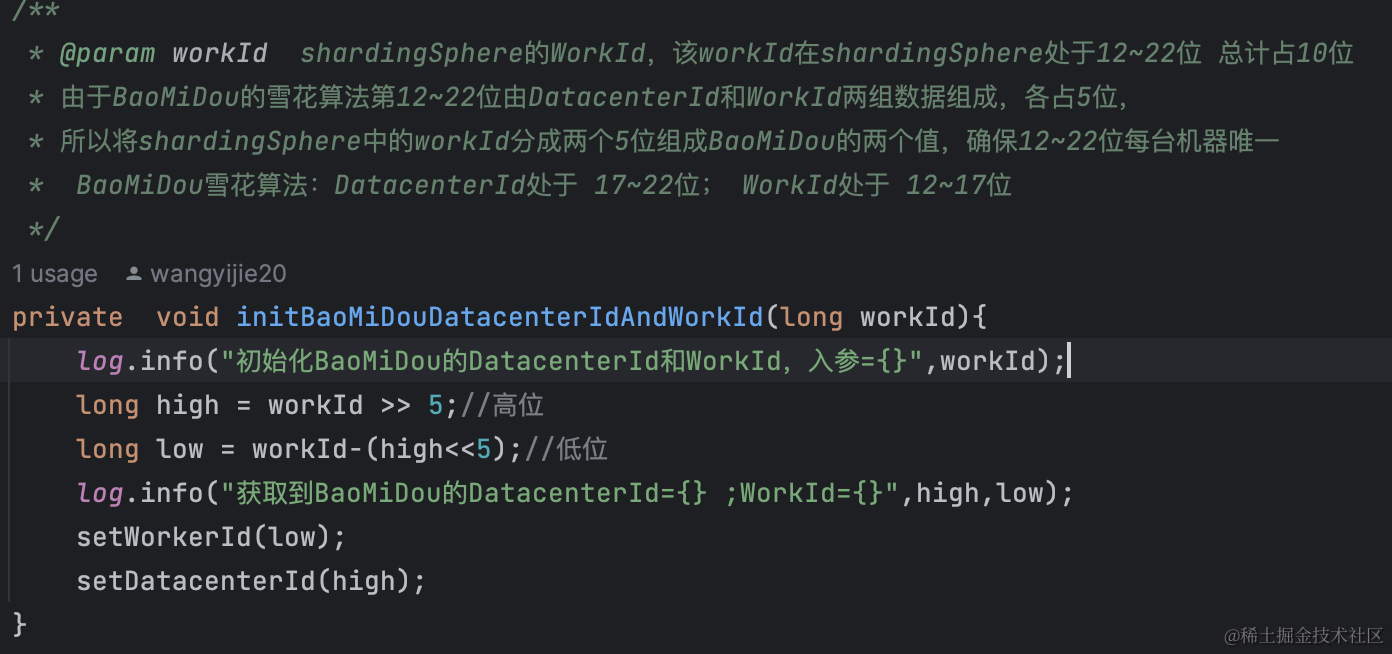
夜已沉默……
生产环境已上线验证通过
作者:京东物流 王义杰
来源:京东云开发者社区 自猿其说Tech 转载请注明来源