官方文档:http://www.plumelog.com/zh-cn/docs/FASTSTART.html
简介
- 无代码入侵的分布式日志系统,基于log4j、log4j2、logback搜集日志,设置链路ID,方便查询关联日志
- 基于elasticsearch作为查询引擎
- 高吞吐,查询效率高
- 全程不占应用程序本地磁盘空间,免维护;对于项目透明,不影响项目本身运行
- 无需修改老项目,引入直接使用,支持dubbo,支持springcloud
架构

- 应用服务通过整合plumelog客户端,搜集日志并推送kafka,redis等队列
- plumelog-server 负责把队列中的日志日志异步写入到elasticsearch
- plumelog_ui为操作界面客户端,用于查询日志,使用各种定制功能
常见部署模型
- 单redis小集群模式,大部分中小规模项目

- kafka集群模式,每个项目量都很大

功能
日志查询

扩展字段
-
在系统扩展字段里添加扩展字段,字段值为 orderid 显示值为 订单编号
-
查询的时候选择应用名,下面会显示扩展字段,可以通过扩展字段查询
MDC.put("orderid","1");
MDC.put("userid","4");
logger.info("扩展字段");
链路追踪
设置追踪码后,支持注解手动打点和切面全局打点
滚动日志
可以连接到机器上,查看实时日志
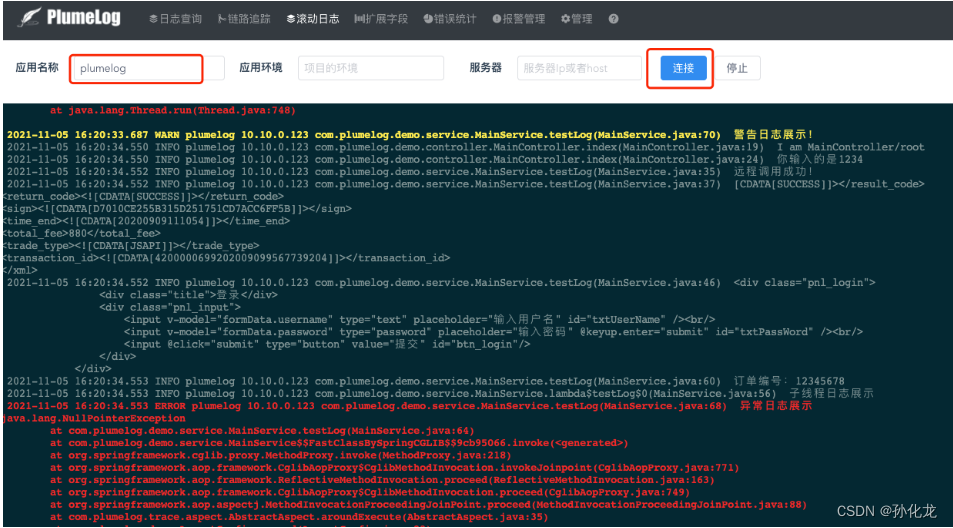
错误统计
错误报警
支持通过webhook自定义报警
索引管理
查看和操作ES索引
plumelog&ELK
- plumelog日志是客户端上报的方式,客户端配置极其简单,不需要像logstash一样去解析日志的格式,因为plumelog客户端已经格式化好了,traceid的设计都是内置的,这些用户都不用刻意去管,跨线程跨应用链路传递都是内置的组件
- 部署简单,你只要个有redis,就行了,ELK组合要完成完整部署,可能还需要配置kafka,filebeat之类的组件,而且版本需统一
- 日志的查询速度大于ELK,因为plumelog查询是优化过的,比kibanna通用查询快很多,plumelog的查询界面就是专门按照国人习惯设计的
- 很多人用ELK到了大量日志的时候发现,检索效率极其下降,那是因为ES的索引等设计不合理造成的,plumelog专业处理日志,索引的设置都已经早就设计好了,不需要使用者自己去优化
- ELK不是专业处理日志的,plumelog在日志上功能就很多,例如扩展字段,链路追踪,错误报警,错误统计后续还有QPS统计等功能,ELK都是没有的
多大体量
根据用户反馈,目前搜集到最大的用户每日日志量已经到达3TB,并稳定运行
部署应用
第一步:安装 redis 或者 kafka(一般公司redis足够) redis 官网:https://redis.io kafka:http://kafka.apache.org
第二步:安装 elasticsearch 官网下载地址:https://www.elastic.co/cn/downloads/past-releases
第三步:下载安装包,plumelog-server 下载地址:https://gitee.com/plumeorg/plumelog/releases
第四步:配置plumelog-server,并启动,redis和kafka作为队列模式下可以部署多个plumelog-server达到高可用,配置一样即可
第五步:后台查询语法详见plumelog使用指南
应用案例
以mservice为例,查询线上问题时,提供的是用户Id或订单号
之前查日志:
- 根据custId找到udid,根据订单号找到custId再找到udid。
- 到kibana根据udid和时间点找到对应的请求记录,找到对应的机器,找到请求的唯一标识“tc”
- 登录机器,根据“tc”参数查询elk日志,找到对应的线程号。
- 根据线程号和时间范围过滤default日志。
现在查询日志:
- 登录plumeLog页面,根据用户Id或订单号查询,即可查询到关键日志,大致定位问题。
- 根据日志的hostIp参数登录到机器根据追踪码过滤即可得到详细日志。
整合过程
-
pom添加依赖
<dependency> <groupId>com.plumelog</groupId> <artifactId>plumelog-logback</artifactId> <version>3.5.2</version> </dependency> -
logback.xml添加appender,注意区分测试和线上环境
<appenders> <!--使用redis启用下面配置--> <appender name="plumelog" class="com.plumelog.logback.appender.RedisAppender"> <appName>plumelog</appName> <redisHost>172.16.249.72:6379</redisHost> <redisAuth>123456</redisAuth> </appender> <!-- 使用kafka启用下面配置 --> <appender name="plumelog" class="com.plumelog.logback.appender.KafkaAppender"> <appName>plumelog</appName> <kafkaHosts>172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092</kafkaHosts> </appender> <!-- 使用lite模式启用下面配置 --> <appender name="plumelog" class="com.plumelog.logback.appender.LiteAppender"> <appName>worker</appName> <plumelogHost>localhost:8891</plumelogHost> </appender> </appenders> <!--使用上面三个三选一加入到root下面--> <root level="INFO"> <appender-ref ref="plumelog"/> </root> <!-- 结合环境配置案例--> <springProfile name="dev"> <root level="INFO"> <appender-ref ref="plumelog" /> </root> </springProfile> <springProfile name="test"> <root level="INFO"> <appender-ref ref="plumelog" /> </root> </springProfile> <springProfile name="prod"> <root level="INFO"> <appender-ref ref="plumelog" /> </root> </springProfile> -
代码调整输出日志
- 当前只把部分关键日志输出到plumeLog,可以解决大部分问题,每条日志都有机器IP
- 把用户Id作为扩展字段,方便搜索。
- 链路追踪:将“tc”参数作为追踪码,调用交易时,将其放到head中传给交易,可以直接根据追踪码搜索,串联mservice和交易系统。
- 将“tc”参数放到MDC中,输出到日志头,可以直接根据“tc”参数过滤日志
-
下载server包,调整server配置文件
spring.application.name=plumelog_server
spring.profiles.active=test-confidential
server.port=8891
spring.thymeleaf.mode=LEGACYHTML5
spring.mvc.view.prefix=classpath:/templates/
spring.mvc.view.suffix=.html
spring.mvc.static-path-pattern=/plumelog/**
spring.boot.admin.context-path=admin
#值为4种 redis,kafka,rest,restServer
#redis 表示用redis当队列
#kafka 表示用kafka当队列
#rest 表示从rest接口取日志
#restServer 表示作为rest接口服务器启动
#ui 表示单独作为ui启动
#lite 简易模式启动不需要配置redis等
plumelog.model=kafka
#plumelog.lite.log.path=/Users/chenlongfei/lucene
# 如果使用kafka,启用下面配置
plumelog.kafka.kafkaHosts=broker.kafka.mid:443,broker.kafka.mid:443
plumelog.kafka.kafkaGroupName=logConsumer
#队列redis地址,model配置redis集群模式,哨兵模式用逗号隔开,队列redis不支持集群模式
#plumelog.queue.redis.redisHost=127.0.0.1:6379
#如果使用redis有密码,启用下面配置
#plumelog.queue.redis.redisPassWord=123456
#plumelog.queue.redis.redisDb=0
#哨兵模式需要配置的
#plumelog.queue.redis.sentinel.masterName=myMaster
#管理端redis地址 ,集群用逗号隔开,不配置将和队列公用
plumelog.redis.redisHost=127.0.0.1:8389,127.0.0.1:8388
#如果使用redis有密码,启用下面配置
#plumelog.redis.redisPassWord=123456
#plumelog.redis.redisDb=0
#哨兵模式需要配置的
#plumelog.redis.sentinel.masterName=myMaster
#如果使用rest,启用下面配置
#plumelog.rest.restUrl=http://127.0.0.1:8891/getlog
#plumelog.rest.restUserName=plumelog
#plumelog.rest.restPassWord=123456
#redis解压缩模式,开启后不消费非压缩的队列
#plumelog.redis.compressor=true
#elasticsearch相关配置,Hosts支持携带协议,如:http、https
plumelog.es.esHosts=127.0.0.1:9200
plumelog.es.shards=5
plumelog.es.replicas=0
plumelog.es.refresh.interval=30s
#日志索引建立方式day表示按天、hour表示按照小时
plumelog.es.indexType.model=day
#plumelog.es.maxShards=100000
#ES设置密码,启用下面配置
#plumelog.es.userName=elastic
#plumelog.es.passWord=elastic
#是否信任自签证书
#plumelog.es.trustSelfSigned=true
#是否hostname验证
#plumelog.es.hostnameVerification=false
#单次拉取日志条数
plumelog.maxSendSize=100
#拉取时间间隔,kafka不生效
plumelog.interval=100
#plumelog-ui的地址 如果不配置,报警信息里不可以点连接
plumelog.ui.url=http://plumelog.ck.api:8891
#管理密码,手动删除日志的时候需要输入的密码
admin.password=123456
#日志保留天数,配置0或者不配置默认永久保留
admin.log.keepDays=30
#链路保留天数,配置0或者不配置默认永久保留
admin.log.trace.keepDays=30
#登录配置,配置后会有登录界面
#login.username=admin
#login.password=admin
- 部署server,当前已部署6个pod。
- 当前实际应用中,日常每天日志总量200多万条。2G左右。