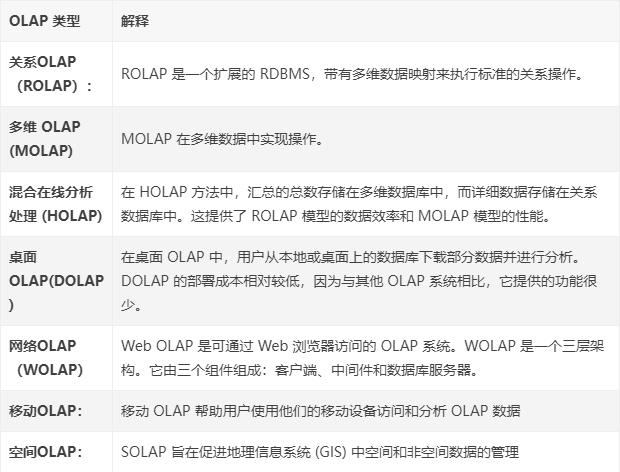
1.案例背景
1.1 Kohonen网络
Kohonen网络是自组织竞争型神经网络的一种,该网络为无监督学习网络,能够识别环境特征并自动聚类。Kohonen神经网络是芬兰赫尔辛基大学教授Teuvo Kohonen 提出的,该网络通过自组织特征映射调整网络权值,使神经网络收敛于一种表示形态。在这一形态中,一个神经元只对某种输人模式特别匹配或特别敏感。Kohonen网络的学习是无监督的自组织学习过程,神经元通过无监督竞争学习使不同的神经元对不同的输人模式敏感,从而特定的神经元在模式识别中可以充当某一输入模式的检测器。网络训练后神经元被划分为不同区域,各区域对输入模型具有不同的响应特征。
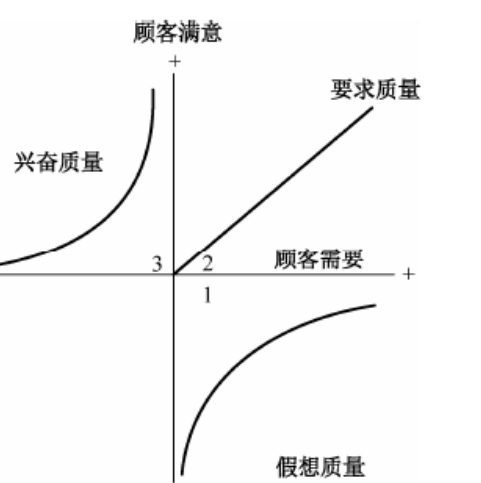
Kohonen神经网络结构为包含输入层和竞争层两层前馈神经网络:第1层为输入层,输入层神经元个数同输入样本向量维数一致,取输人层节点数为m;第2层为竞争层,也称输出层,竞争层节点呈二维阵列分布,取竞争层节点数为n。输入节点和输出节点之间以可变权值全连接,连接权值为wij(i=1,2,…,m;j=1,2,……,n)。Kohonen 网络拓扑结构示意图如图38-1所示。
Kohonen神经网络算法工作机理为:网络学习过程中,当样本输入网络时,竞争层上的神经元计算输人样本与竞争层神经元权值之间的欧几里得距离,距离最小的神经元为获胜神经元。调整获胜神经元和相邻神经元权值,使获得神经元及周边权值靠近该输人样本。通过反复训练,最终各神经元的连接权值具有一定的分布,该分布把数据之间的相似性组织到代表各类的神经元上,使同类神经元具有相近的权系数,不同类的神经元权系数差别明显。需要注意的是,在学习的过程中,权值修改学习速率和神经元领域均在不断较少,从而使同类神经元逐渐集中。Kohonen网络训练步骤如下。


1.2 网络入侵检测
网络入侵是指试图破坏计算机和网络系统资源完整性、机密性或可用性的行为。其中,完整性是指数据未经授权不能改变的特性;机密性是指信息不泄露给非授权用户、实体或过程,或供其利用的特性;可用性是可被授权实体访问并按要求使用的特性。人侵检测是通过计算机网络或计算机系统中的若干关键点搜集信息并对其进行分析,从中发现网络或系统中是否有违反安全策略的行为或人侵现象。
常规的入侵检测方法可以按检测对象、检测方法和实时性等方面进行分类。其中,按检测对象可以分为基于主机的入侵检测系统、基于网络的入侵检测系统和混合型入侵检测系统;按检测方法可以分为误用检测和异常检测;按定时性可以分为定时系统和实时系统。
近年来,研究人员又提出了一些新的入侵检测方法,比如基于归纳学习的入侵检测方法、基于数据挖掘的人侵检测方法,基于神经网络的人侵检测方法、基于免疫机理的入侵检测方法和基于代理的人侵检测方法等。其中,基于数据挖掘的入侵检测方法是采用数据挖掘中的关联分析,序列模式分析、分类分析或聚类分析来处理数据,从中抽取大量隐藏安全信息,抽象出用于判断和比较的模型,然后利用模式识别入侵行为。
2 模型建立
基于Kohonen网络的网络入侵攻击聚类算法流程如图38-2所示。

数据归一化是指把网络人侵数据进行归一化处理。
网络初始化根据入侵数据特点初始化网络,由于网络入侵数据有38维,人侵数据来自于5种不同类型的网络入侵模式,所以输人层节点数为38。竞争层节点代表输入数据潜在的分类类别,竞争层节点数一般大大多于数据实际类别,选择竞争层节点数为36个,竞争层节点排列在一个6行6列的方阵中。
按公式(38-1)计算和输入样本最接近的竞争层节点作为该样本的优胜节权值调整根据公式(38-2)调整优胜节点领域半径r内节点权值,其中领域半径和学习速率随着进化过程逐渐变小,这样输入数据逐渐向几个节点集中,从而使网络实现聚类功能。本案例中最大领域rlmax为1.5,最小领域rlmin为0.4,最大学习概率ratelmax为0.1,最小学习概率ratelmin为0.01。网络共学习调整10 000次。
3.编程实现
根据Kohonen网络原理,在 MATLAB软件中编程实现基于Kohonen 网络的网络入侵分类算法。完整代码如下:
%% 该代码为基于Kohonen网络的分类算法
%% 清空环境变量
clc
clear
%% 数据处理
load data
input=datatrain(:,1:38);
%数据归一化
[inputn,inputps]=mapminmax(input);
%inputn=inputn';
[nn,mm]=size(inputn);
%% 网络构建
%输入层节点数
Inum=38;
%Kohonen网络
M=6;
N=6;
K=M*N;%Kohonen总节点数
%Kohonen层节点排序
k=1;
for i=1:M
for j=1:N
jdpx(k,:)=[i,j];
k=k+1;
end
end
%学习率
rate1max=0.2;
rate1min=0.05;
%学习半径
r1max=1.5;
r1min=0.8;
%权值初始化
w1=rand(Inum,K); %第一层权值
%% 迭代求解
maxgen=10000;
for i=1:maxgen
%自适应学习率和相应半径
rate1=rate1max-i/maxgen*(rate1max-rate1min);
r=r1max-i/maxgen*(r1max-r1min);
%从数据中随机抽取
k=unidrnd(4000);
x=inputn(k,:);
%计算最优节点
[mindist,index]=min(dist(x,w1));
%计算周围节点
d1=ceil(index/6);
d2=mod(index,6);
nodeindex=find(dist([d1 d2],jdpx')<r);
%权值更新
for j=1:K
%满足增加权值
if sum(nodeindex==j)
w1(:,j)=w1(:,j)+rate1*(x'-w1(:,j));
end
end
end
%% 聚类结果
Index=[];
for i=1:4000
[mindist,index]=min(dist(inputn(i,:),w1));
Index=[Index,index];
end netattack. mat里面共有4000组数据,其中第1~1383组数据属于第1类网络入侵方式,第1384~3 238组属于第2类网络入侵方式,第3239~3 357组属于第3类人侵方式,第3358~3948组属于第4类入侵方式,第3949~4000组属于第5类入侵方式。通过计算得到各类入侵数据的优胜节点,如表38-1所列。
竞争层优胜节点分布如图38-3所示。其中,①代表第1类入侵数据所属节点,②代表第2类入侵数据所属节点,③代表第3类人侵数据所属节点,④代表第4类人侵数据所属节点,⑤代表第5类人侵数据所属节点。空白表示节点不属于任何类。从图38-3可以看出,不同类别的优胜节点基本按块分布,分类算法取得了良好的效果。


4.案例扩展
4.1有监督Kohonen网络原理
上述内容表明Kohonen网络可以对未知类别数据进行无监督分类,但是分类结果中同一类别数据对应不同的网络节点,如果按照一个节点对应一类来说,Kohonen网络分类的类别比实际数据类别要多。Kohonen网络可以通过在竞争层后增加输出层变为有监督学习的网络(S Kohonen网络),S_Kohonen网络同Kohonen网络相比,增加一层输出层,输出层节点个数同数据类别相同,每个节点代表一类数据。输出层节点和竞争层节点通过权值相连,数据输人S_Kohonen网络,在权值调整时,不仅调整输入层同竞争层优胜节点领域内节点权值,同时调整竞争层优胜节点领域内节点同输出层节点权值,调整方式如下:
S_Kohonen 网络训练过程同Kohonen网络训练类似,不同的是在调整输人层同竞争层获胜节点权值的同时按公式(38-4)调整竞争层获胜节点同输出层节点之间的权值。
网络训练完后可对未知样本进行分类,分类时首先计算同未知样本最近的竞争层节点作为优胜节点,与获胜节点连接权值最大的输出层节点代表类别为未知样本类别。
对于本案例来说,由于数据来源于5种类型的入侵数据,所以网络结构为38—36—5,输入层和竞争层的权值a,随机初始化,竞争层和输出层的权值wjk初始为0。取4 500组网络攻击数据,从中随机抽取4 000组数据训练网络,500组数据测试网络分类能力,MATLAB程序如下。
%% 该代码为基于有导师监督的Kohonen网络的分类算法
%% 清空环境变量
clc
clear
%% 数据处理
load data
input=datatrain(:,1:38);
attackkind=datatrain(:,39);
%数据归一化
inputn=input;
[nn,mm]=size(inputn);
[b,c]=sort(rand(1,nn));
%网络期望输出
for i=1:nn
switch attackkind(i)
case 1
output(i,:)=[1 0 0 0 0];
case 2
output(i,:)=[0 1 0 0 0];
case 3
output(i,:)=[0 0 1 0 0];
case 4
output(i,:)=[0 0 0 1 0];
case 5
output(i,:)=[0 0 0 0 1];
end
end
%训练数据
input_train=inputn(c(1:4000),:);
output_train=output(c(1:4000),:);
%% 网络构建
%输入层节点数
Inum=38;
%Kohonen网络
M=6;
N=6;
K=M*N;%Kohonen总节点数
g=5; %输出层节点数
%Kohonen层节点排序
k=1;
for i=1:M
for j=1:N
jdpx(k,:)=[i,j];
k=k+1;
end
end
%学习率
rate1max=0.1;
rate1min=0.01;
rate2max=1;
rate2min=0.5;
%学习半径
r1max=1.5;
r1min=0.4;
%权值初始化
w1=rand(Inum,K); %第一层权值
w2=zeros(K,g); %第二层权值
%% 迭代求解
maxgen=10000;
for i=1:maxgen
%自适应学习率和相应半径
rate1=rate1max-i/maxgen*(rate1max-rate1min);
rate2=rate2min+i/maxgen*(rate2max-rate2min);
r=r1max-i/maxgen*(r1max-r1min);
%从数据中随机抽取
k=unidrnd(4000);
x=input_train(k,:);
y=output_train(k,:);
%计算最优节点
[mindist,index]=min(dist(x,w1));
%计算周围节点
d1=ceil(index/6);
d2=mod(index,6);
nodeindex=find(dist([d1 d2],jdpx')<=r);
%权值更新
for j=1:length(nodeindex)
w1(:,nodeindex(j))=w1(:,nodeindex(j))+rate1*(x'-w1(:,nodeindex(j)));
w2(nodeindex(j),:)=w2(nodeindex(j),:)+rate2*(y-w2(nodeindex(j),:));
end
end
%% 聚类结果
Index=[];
for i=1:4000
[mindist,index]=min(dist(inputn(i,:),w1));
Index=[Index,index];
end
inputn_test=datatest(:,1:38);
%样本验证
for i=1:500
x=inputn_test(i,:);
%计算最小距离节点
[mindist,index]=min(dist(x,w1));
[a,b]=max(w2(index,:));
outputfore(i)=b;
end
length(find((datatest(:,39)-outputfore')==0))
plot(outputfore,'linewidth',1.5)
hold on
plot(datatest(:,39),':r','linewidth',1.5)
title('网络分类','fontsize',12)
xlabel('数据样本','fontsize',12)
ylabel('分类类别','fontsize',12)
legend('预测类别','期望类别')4.2 运行结果分析
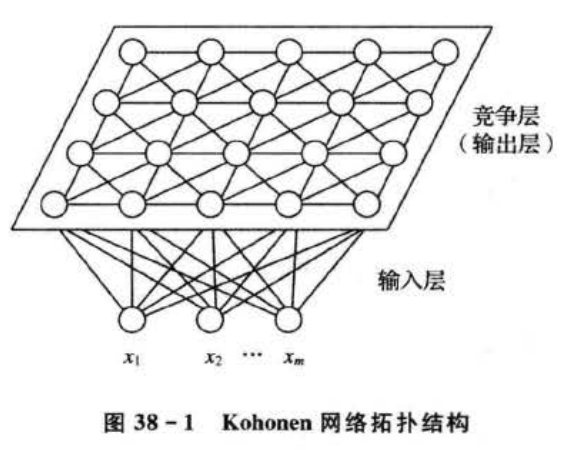
用训练好的S_Kohonen网络分类测试样本数据,分类数据共有500组,分类结果如图38-4所示。从预测结果可以看出,绝大部分测试数据网络分类类别同期望类别一致,500组测试数据分类正确的有492组,正确率为98.4%。


![java八股文面试[数据库]——B树和B+树的区别](https://img-blog.csdnimg.cn/e3340931f2e1432eacc7536f91775af0.png)