数组:
固定长度,从栈中分配空间,对于程序方便快速,但是自由度小。
优点:下标定位,随机访问性强,查找速度快;
缺点:插入、删除效率低,内存利用率低,内存空间要求高,必须有足够的连续内存空间。
链表:
动态进行存储分配,从堆中分配空间,自由度大但是申请管理麻烦。
优点:插入和删除的效率高,内存利用率高,不会浪费内存;
缺点:定位查询速度慢,修改慢。
哈希表:
在JDK1.8版本前:数组 + 链表
在JDK1.8版本后:数组 + 链表 +红黑树
初始化时,内存默认创建长度为16,加载因子是0.75。
扩容因子值越大,触发扩容的元素个数越多,虽然空间利用率高,但是哈希冲突概率增加。
扩容因子值越小,触发扩容的元素个数越少,哈希冲突概率减少,但是占用内存,增加扩容频率。
扩容因子的值的设置,是在统计学中泊松分布有关,再冲突和空间利用率之间的平衡。
1、List
1)ArrayList
底层是基于数组实现的,默认大小是10。数量达到10会进行自动扩容,创建新的数组长度为原来的1.5倍,用 Arrays.copyOf 方法旧数组数据拷贝进去,再添加新的进去。
优点:查询快,修改快;
缺点:增删慢,线程不安全。
2)LinkedList
底层是基于双向链表实现的。不存在扩容问题。
优点: 适合数据的动态插入和删除;
缺点:不适合查询、修改数据,随机访问和遍历速度较慢。线程不安全。
3)Vector
底层是基于数组实现的,支持线程同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,因此,比访问 ArrayList 慢。
2、set
1)HashSet
底层是哈希表
- 元素是无序的
- HashSet不是同步的,线程不安全
- 集合元素值允许为null,但只能有一个
2)TreeSet
底层是TreeMap实现的,底层用到的数据结构是红黑树。当构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若需要使用自定义的比较器,则需要使用带比较器的参数。
- 自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
- 自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法。
- 如果要按序保存条目,并且按照升序或者降序对集合进行访问和遍历,那么TreeSet就应该作为首选集合。升序方式的操作与视图性能要强于降序方式。
3)LinkedHashSet
底层是LinkedHashMap实现的,继承HashSet。
- 元素没有重复
- 元素有顺序
- 可以存储null值
- 线程不安全
3、Map
1)HashMap
底层是哈希表,无序集合,最大容量Integer.MAX_VALUE,2 的 31 次方-1。
非线程安全,可以存储null键和null值。只能有一个null键。
当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。
| JDK1.7 | JDK1.8 | |
| 底层 | entry数组+链表 | node数组+链表+红黑树 (链表长度>8 && 元素数量>64) |
| 扩容 | 颠倒链表顺序并在元素插入前检测是否需要扩容,扩容后,元素重新计算,降低哈希冲突 | 保持原链表的顺序并且在元素插入后检测是否需要扩容,扩容后,不会重新计算 |
| 初始容量 | 0(第一次执行put初始) | 16(put时初始) |
| 插入 | 头插法 | 尾插法 |
HashMap hashMap=new HashMap(3);
put第4个数据时,不会报错,会自动扩容的,是在容量*0.75即就是4*0.75=3,put第三次完成之后开始扩容,新容量=旧容量*2,即就是4*2=8。
为什么要右移16位异或?
主要目的是为了让hash值的散列度更高,尽可能减少哈希表的hash冲突,从而提升数据查找的性能。
再HashMap的put方法里,通过key的hash值与数组的长度取模运算得到数组的位置,大部分情况下,n取消小于2^16,也就是i的值是哈希的第十六位和n-1取模运算,造成key的散列度不高,导致key集中存储在固定的几个数组位置,影响查找性能。
右移16位,就是把hashCode高位移动到低位,再进行异或运算,降低hash冲突概率。
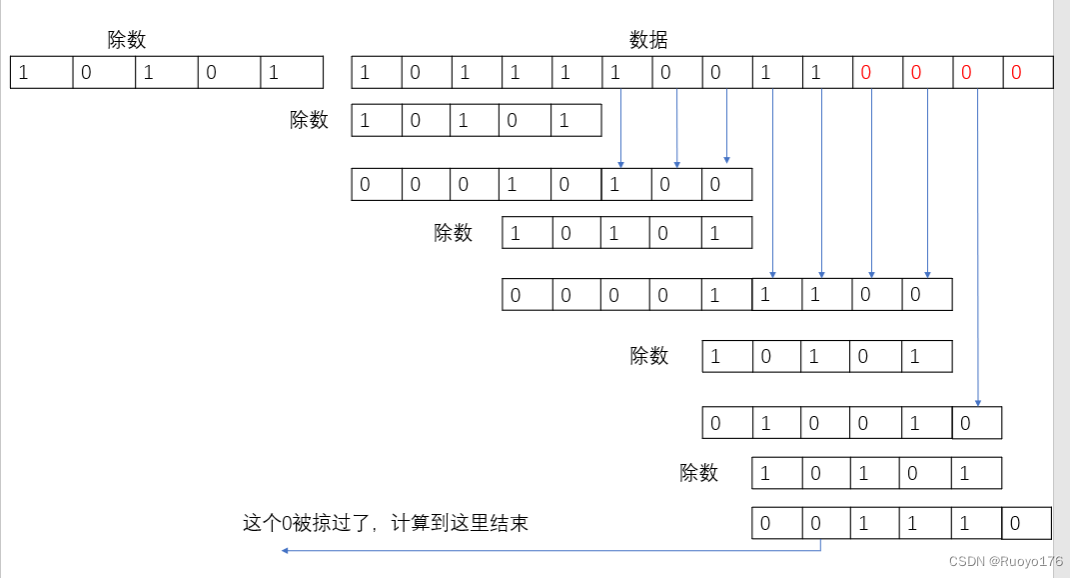
常见死循环问题?
只会在1.7中出现,1.7采用的是数组+链表且是头插法。
当有两个线程TA和TB,对HashMap进行扩容,都指向链表头结点NA,而TA和TB的next都是NB,假设TB休眠,TA执行扩容操作,一直到TA完成后,TB被唤醒,TB.next还是NB,但是TA执行成功已经发生了顺序改变,如下图,出现一个死循环。
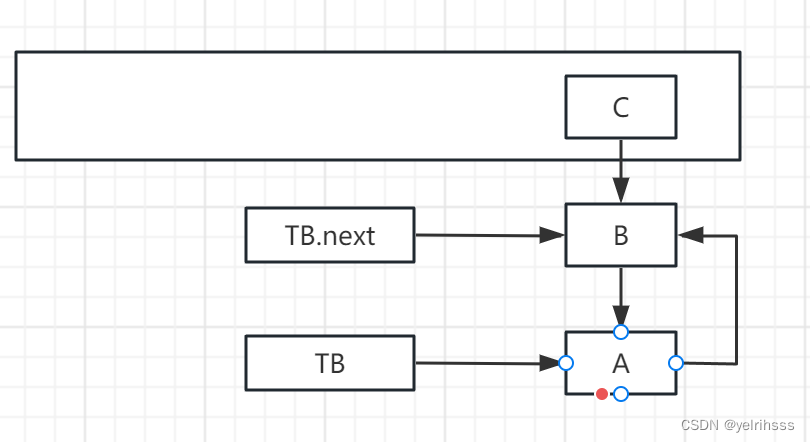
解决方案:
使用ConcurrentHashMap
使用HashTable,性能低不建议
使用synchronized 或 Lock 加锁之后,再进行操作,多线程排队性能低
2)ConCurrentHashMap
底层:分段数组+链表
线程安全
key和value都不能为null
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)Segment是一个可重入锁。
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
3)LinkedHashMap
有序(插入有序,访问节点后移到最后)
非线程安全
key和value都可以为null
键重复,即被覆盖
- 没有重写父类HashMap的put和get方法,而是对子方法addEntry、createEntry、newNode、
LinkNodeLast,实现双向链表的特点。
4)TreeMap
底层是红黑树
双列集合
键不能重复,元素有序
每次新增或删除一个kv,都可能导致红黑树的重排,因此,适用与Map元素基本不变,主要用于遍历迭代获取数据,不同的k的场景下使用。