技术背景
在前面一篇文章中,我们介绍了MindSponge的两种不同的安装与使用方法,让大家能够上手使用。这篇文章主要讲解MindSponge的软件架构,并且协同mindscience仓库讲解一下二者的区别。
整体架构
首先我们来了解一下MindSponge独立仓库的软件架构,其实核心部分的软件架构跟mindscience是一致的。
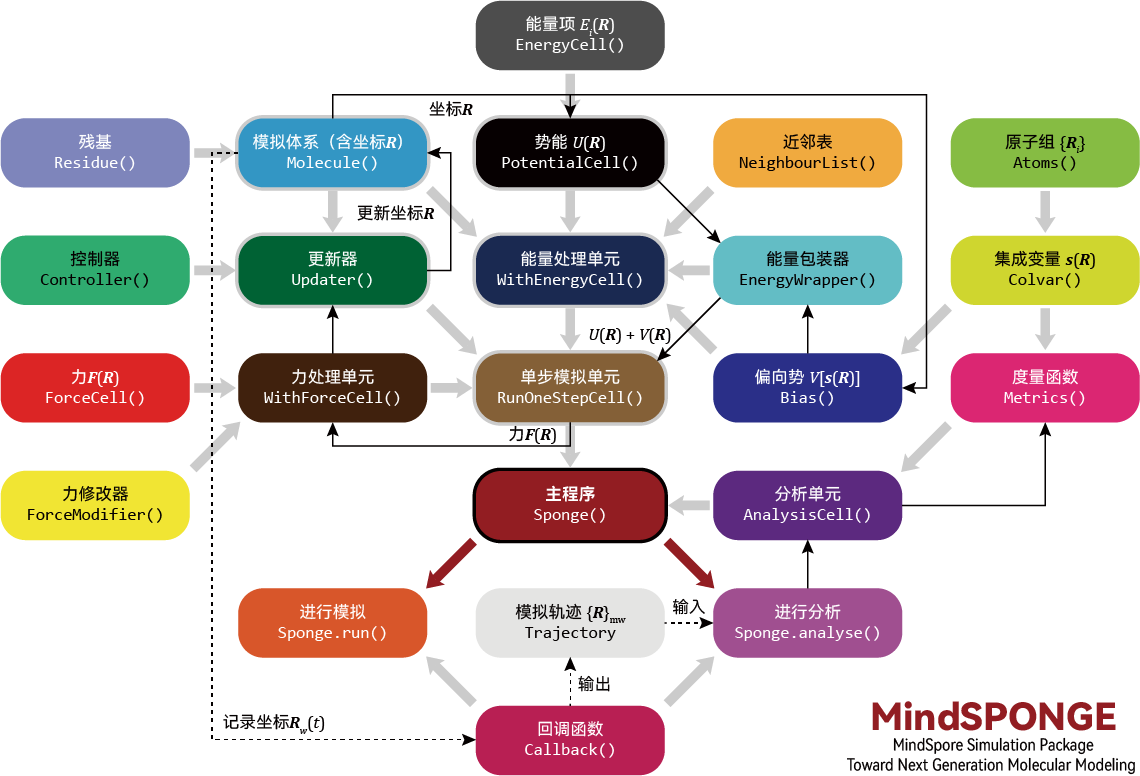
在这个架构图中,我们不仅可以看到MindSponge的内部模块划分,还能看到一个分子模拟数据处理的流程。
-
首先从一个模拟体系Molecule()开始,这个Molecule()可以独立定义,可以自行封装,也可以用Residue()来构建,里面存储有分子的基本信息,如坐标、原子名称等。
-
然后根据Molecule()提供的信息构建一个力场,形成一个PotentialCell()势能函数。这个势能函数,是基于模块化的EnergyCell()搭建的一个整体。而且除了力场本身之外,还可以接收外界输入的EnergyWrapper(),可用于添加神经网络力场,或者是增强采样产生的Bias()。这也是该架构的一个先进性的体现,虽然是一个MD软件,但不仅仅局限于做MD。
-
我们可以使用MindSpore内置的优化器,如Adam等,对Molecule()的Parameter进行更新迭代,可以自定义Updater()来对Molecule()进行更新。一般情况下,更新的依据主要来自于对PotentialCell()的自动微分。当然,也可以自行定义ForceCell()的内容。如果我们在动力学模拟的过程中,需要定义一些约束算法,或者是控温控压算法,都可以将相关的Controller()传入到Updater()中。
-
接下来的重点是要通过PotentialCell()来获取力,如果是以往传统的做法,只能通过取两点做差分的方法来得到一个作用力。但如果我们这里的所有计算都通过MindSpore的内置算子来实现的话,就可以使用MindSpore的自动微分来计算这个力。最终我们会得到一个ForceCell()传到Updater()里面,但是这一步对用户是不感知的,用户只需要定义好PotentialCell()这一块就足够了。或者用户也可以自行定义一个ForceModifier()传入到WithForceCell(),来构建一个自定义力场。
-
在具备了体系Molecule()、优化器Optimizer()和力场WithForceCell()之后,我们就可以开始基本的动力学模拟计算,此时就需要用到主程序Sponge()来对整个流程进行管理。并且,我们可以定义一些回调函数CallBack()给Sponge()进行任务追踪。比如RunInfo()可以在屏幕上输出指定步长的能量,或者是WriteH5MD可以将整个MD的轨迹保存到一个指定的hdf5格式的文件中,文件后缀名为
h5md,可以在VMD中增加一个hdf5的插件来进行动态可视化。
软件模块
我们先来看一下MindSponge这边的软件项目主页:
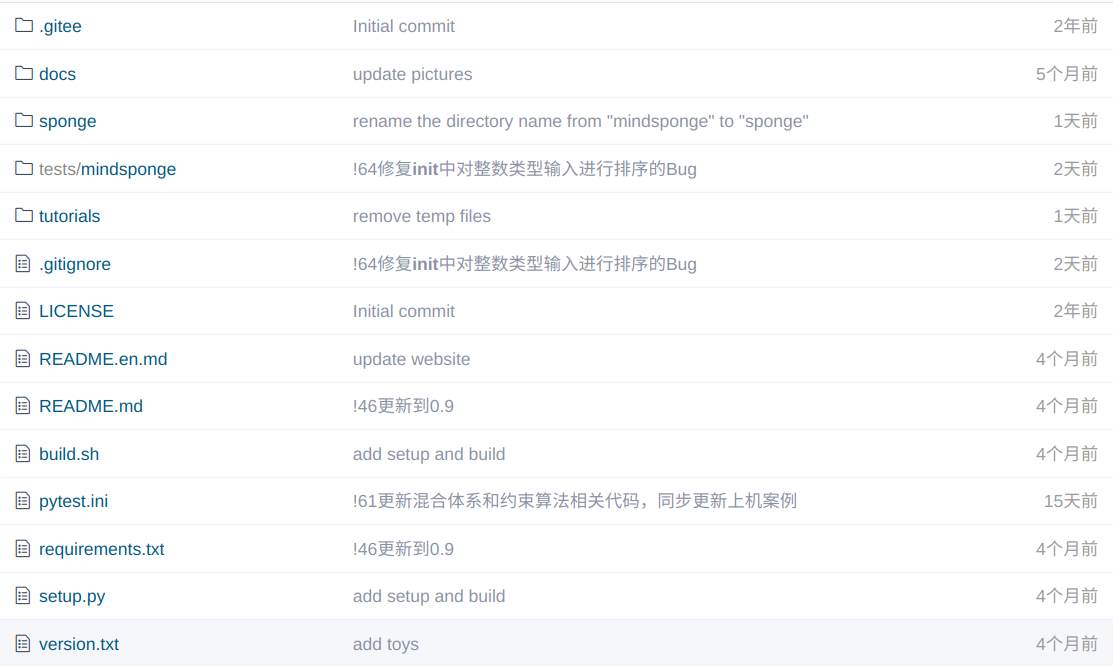
针对于这其中的内容我们简单梳理一下:sponge/是核心目录,tutorials/和tests/显然是一些案例或者是测试用例的路径,docs/是一些文档或者是图片,其他的文件基本上是一些跟mindsponge仓库的安装相关的内容,所以我们重点关注下sponge/下的内容:
这里我们对照每一个目录来进行内容解析:
-
callback:回调函数。在运行分子动力学模拟程序的过程中,我们可能会有记录一些能量、力、速度、轨迹的需求,这时候就需要调用回调函数,对相应的内容进行输出。目前比较常用的回调函数,是RunInfo和WriteH5MD。RunInfo可以在屏幕上输出运行的结果,WriteH5MD则是把轨迹等输出到一个hdf5格式的文件里面,后缀为
*.h5md,可以用https://gitee.com/helloyesterday/VMD-h5mdplugin这个VMD插件来进行可视化。 -
colvar:各种形式的参量。这里预定义了一些常用的参量,比如分子质心、原子间键长键角等。当然,用户也可以自己开发一些参量,可以用于增强采样。
-
control:控制器和约束算法。顾名思义,就是要对原子系统迭代的过程进行控制,比如温度参数和压强参数,甚至是控制键长键角,都是可以的。
-
core:主程序。这里就是Sponge()的存放路径,对整个模拟过程进行管理。
-
data:参数文件和模板文件。我们在使用模板构建分子系统力场的时候,会使用到一些模板文件和力场参数文件,这些文件就都存储在data目录下,并且有相应的文件读取函数。
-
function:非内置函数。对于一些公用的函数,一般都集中放在function路径下。
-
metrics:度量函数。在机器学习中一般该函数被用于衡量模型的好坏,这里我们一般就用来计算某个特定的参数,比如设定一个自定义的CV函数,可以与colvar中的内容配合使用。
-
optimizer:优化器和积分器。之所以我们可以使用AI框架来实现一个分子动力学模拟的框架,正是得益于分子动力学模拟与AI训练/推理之中的共性。在神经网络的训练中我们可以使用优化器来迭代损失函数,而在分子动力学模拟中就可以使用积分器(如Leap-Frog和Velocity-Verlet)来迭代势能函数。
-
partition:近邻表。在分子系统较大时,就不能考虑全连接的相互作用,只能考虑局部相互作用。而分子模拟的过程中,近邻表实际上每一步都在变化,因此需要一个单独用于计算近邻关系的Cell。
-
potential:势能函数。这个就不需要过多解释了,相当于力场里面每一项的内容分开写在了几个文件里面。
-
sampling:增强采样函数。可用于修改势能项,也可以直接修改力,可以加快采样的进程。
-
system:分子系统基类。存储有一个分子系统的基本信息,如原子名称、残基名称,还有最核心的原子构象坐标等等。
总结概要
分子模拟具有众多的应用场景,比如制药领域和材料领域,做好分子模拟的工作,可以极大程度上缩减新药物新材料的研发成本和研发周期。近几年随着GPT-4和Diffusion Model的大火,让大家意识到了AI已经具备了相当的解决问题的能力。因此基于AI的框架和模型,对比AI训练与分子模拟之间的共性,可以实现一个面向AI时代的分子模拟框架。本文主要介绍基于MindSpore框架实现的,MindSponge分子动力学模拟框架的软件架构。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/structure.html
作者ID:DechinPhy
更多原著文章请参考:https://www.cnblogs.com/dechinphy/
打赏专用链接:https://www.cnblogs.com/dechinphy/gallery/image/379634.html
腾讯云专栏同步:https://cloud.tencent.com/developer/column/91958
CSDN同步链接:https://blog.csdn.net/baidu_37157624?spm=1008.2028.3001.5343
51CTO同步链接:https://blog.51cto.com/u_15561675