任务目标
- 在浏览器加载网页的过程中,网页的有些元素时常会有延迟的现象,在HTML元素还没有准备好的情况下去操作这个HTML元素必然会出现错误,这个时候Selenium需要等待HTML元素。例如:上节实例中出现的select的下拉框元素,选项填充需要执行JavaScript脚本。
- 我们来学习如果使用Selenium等待延迟的HTML元素并最终爬取元素的数据。
创建Ajax网站
phone.html 如下:
注:phone.html 文件要位于 templates 这个目录下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form name="frm" action="/">
<div>
<span id="msg"></span>
<label for="xmark"></label><select id="xmark"></select>
</div>
<input type="submit" value="提交" id="submit" disabled="true">
</form>
</body>
<script>
function loadMarks(){
var http=new XMLHttpRequest();
http.open("get","/marks",true);
http.send(null);
http.onreadystatechange=function(){
// onreadystatechange存储函数,每当 readyState 属性改变时,就会触发调用该函数。
// readystate存有 XMLHttpRequest 的状态。从 0 到 4 发生变化。
// 0: 请求未初始化 1: 服务器连接已建立 2: 请求已接收 3: 请求处理中 4: 请求已完成,且响应已就绪
// status,200(OK),404(未找到页面)
if (http.readyState===4 && http.status===200){ //请求完成并且成功返回
var xmark=document.getElementById("xmark");
var xcolor=document.getElementById("xcolor");
marks=eval("("+http.responseText+")");// JS中将JSON的字符串解析成JS对象格式
for(var i=0;i<marks.length;i++)
xmark.options.add(new Option(marks[i],marks[i]));
document.getElementById("submit").disabled=false;
document.getElementById("msg").innerHTML="品牌";
}
};
}
loadMarks();
</script>
</html>创建服务器程序
服务器server.py程序如下:
import flask
import json
import time
app = flask.Flask(__name__)
@app.route("/")
def index():
return flask.render_template("phone.html")
@app.route("/marks")
def loadMarks():
time.sleep(1)
marks = ["华为", "苹果", "三星"]
return json.dumps(marks) # 将JSON的对象格式转化成str格式
app.run()
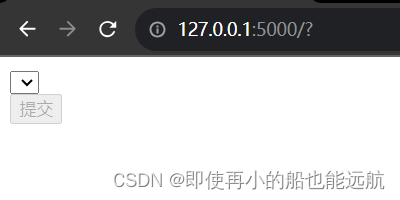
模拟网站结果如下:

Selenium强制等待
必须等待的时间,缺点:不能准确把握需要等待的时间(有时操作还未完成,等待就结束了,导致报错;有时操作已经完成了,但等待时间还没有到,浪费时间),如果在用例中大量使用,会浪费不必要的等待时间,影响测试用例的执行效率。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("http://127.0.0.1:5000")
# 设置强制等待1.5秒,
time.sleep(1.5)
marks = driver.find_elements(By.XPATH, "//select/option")
print("品牌数量:", len(marks))
for mark in marks:
print(mark.text)
form = driver.find_element(By.XPATH, "//form")
print(form.get_attribute("innerHTML").strip())
time.sleep(5)
driver.close()
Selenium隐性等待
该方法是浏览器对象调用的方法,即设置浏览器打开网页均等待的时长, 同样如果设置的隐性等待时间不够长, 还是爬取不到需要的数据。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
# 设置隐性加载时间1.5秒,即网页在加载时最长等待 seconds 秒
driver.implicitly_wait(1.5)
driver.get("http://127.0.0.1:5000")
marks = driver.find_elements(By.XPATH, "//select/option")
print("品牌数量:", len(marks))
for mark in marks:
print(mark.text)
form = driver.find_element(By.XPATH, "//form")
print(form.get_attribute("innerHTML").strip())
time.sleep(5)
driver.close()