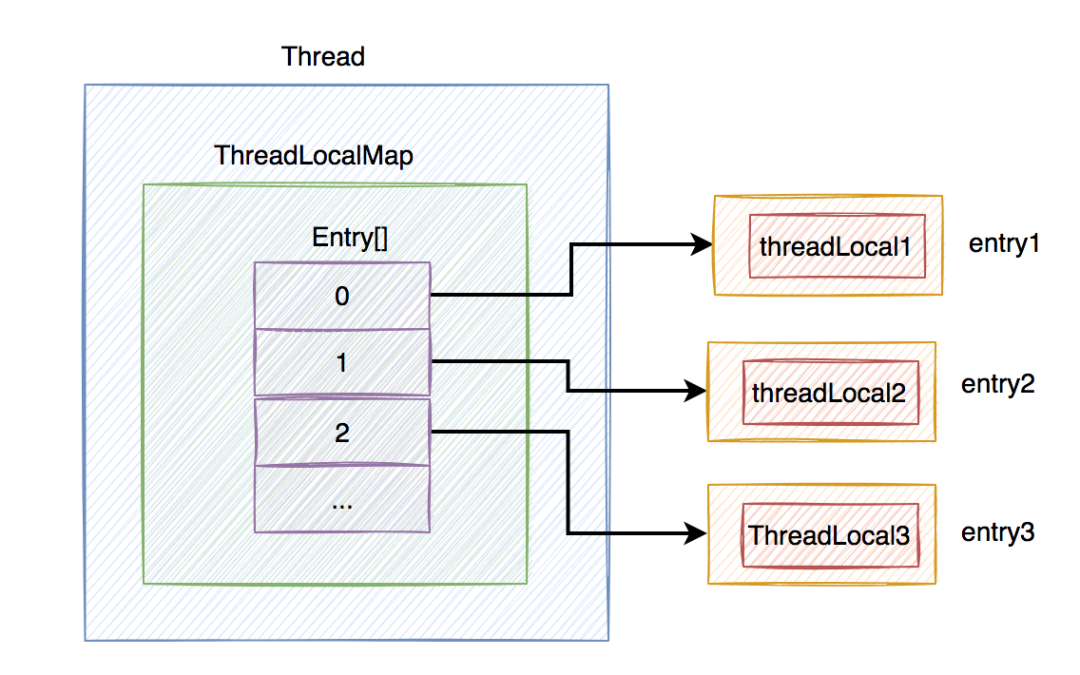
优化案例5:视图目标列改写优化
- 1. 问题描述
- 2. 分析过程
- 2.1 目标SQL
- 2.2 解决思路
- 1)效率低的执行计划
- 2)视图过滤性
- 3)查看已有索引定义
- 2.3 视图改写
- 2.4 增添复合索引
- 3. 优化总结
DM技术交流QQ群:940124259
1. 问题描述
视图改写优化单独拿出一例分享,未做hint优化,简单地改写视图列和增加一个索引就能搞定。
这条SQL本身很简单,被广州同事使出三板斧(统计信息、索引、ET耗时、HINT、清理执行计划),招式使尽,却没去留意视图定义本身内容的特点,利用视图的谓词下推的策略,就能达到优化目的。
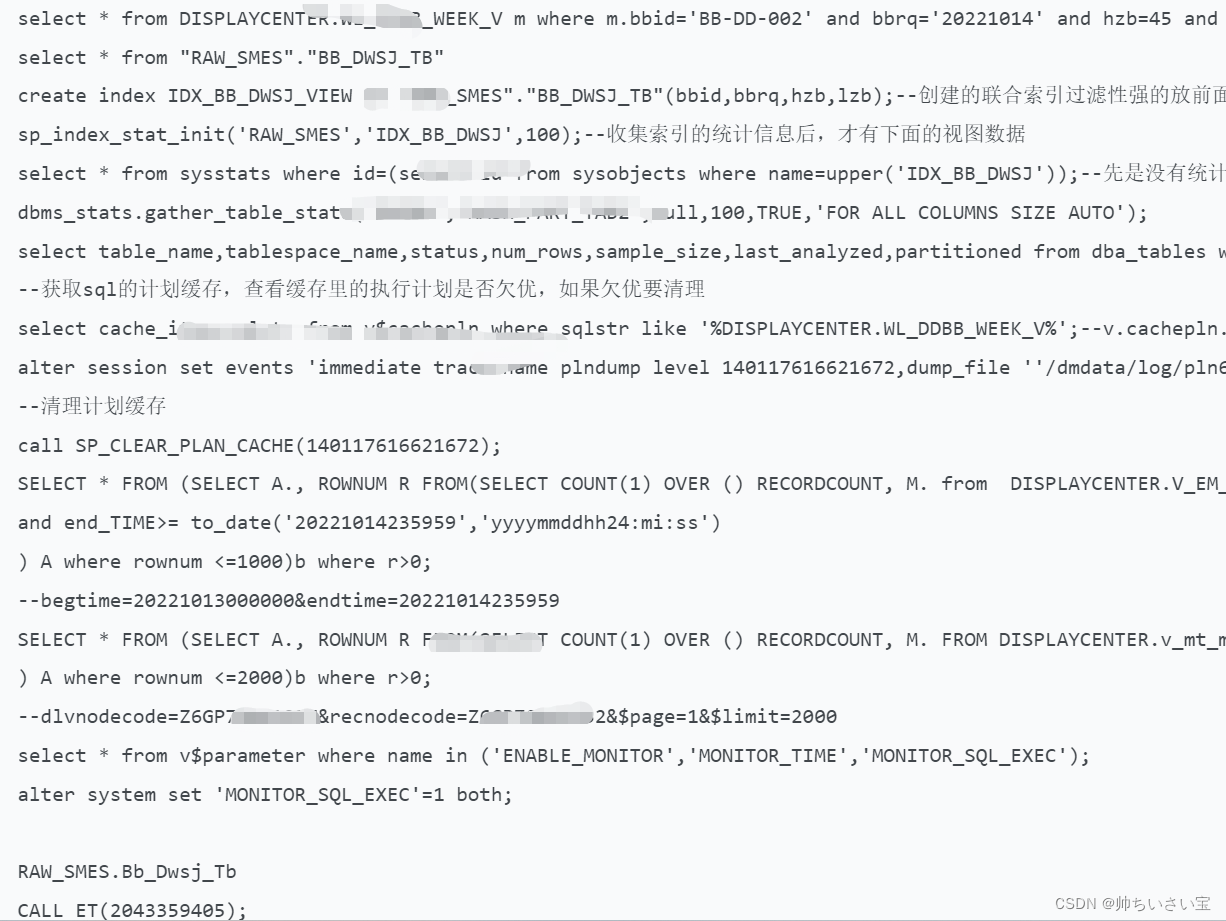
截图为同事部分一堆骚操作:
2. 分析过程
2.1 目标SQL
-- 原始SQL代码
SELECT *
FROM (SELECT A.,
ROWNUM R
FROM(SELECT COUNT(1) OVER () RECORDCOUNT,
M.
from DISPLAYCENTER.WL_DDBB_WEEK_V m
where m.bbid='BB-DD-002'
and bbrq='20221014'
and hzb=45
and lzb=6 ) A
where rownum <=1000)b
where r>0; -- telphoning --4ms
-- 视图原始定义WL_DDBB_WEEK_V
CREATE OR REPLACE VIEW WL_DDBB_WEEK_V AS
SELECT t1.bbzd_id bbid, '' bbmc,
SUBSTR (t1.bbzd_date, 1, 4) || SUBSTR (t1.bbzd_date, 7, 2) || SUBSTR (t1.bbzd_date, 9, 2) AS bbrq,
t1.hzd_nm hzb, t1.lzd_nm lzb, dyzd_sj as VALUE
FROM (SELECT
T1.*
FROM RAW_SMES.Bb_Dwsj_Tb T1) t1 ;
2.2 解决思路
1)效率低的执行计划
/*
-- predicate condition
1 #NSET2: [6597, 1, 912]
2 #PRJT2: [6597, 1, 912]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [6597, 1, 912]; B.R > var2
4 #PRJT2: [6597, 1, 912]; exp_num(8), is_atom(FALSE)
5 #RN: [6597, 1, 912]
6 #PRJT2: [6597, 1, 912]; exp_num(7), is_atom(FALSE)
7 #TOPN2: [6597, 1, 912]; top_num(exp11)
8 #AFUN: [6597, 1, 912]; afun_num(1); partition_num(0); order_num(0)
9 #PRJT2: [6597, 34, 912]; exp_num(6), is_atom(FALSE)
10 #SLCT2: [6597, 34, 912]; (exp_cast(T1.HZD_NM) = 45 AND exp_cast(T1.LZD_NM) = 6 AND exp11 || exp11 || exp11 = '20221014')
11 #BLKUP2: [6597, 2754812, 912]; IDX_BB_DWSJ(T1)
12 #SSEK2: [6597, 2754812, 912]; scan_type(ASC), IDX_BB_DWSJ(BB_DWSJ_TB as T1), scan_range[('BB-DD-002',min,min,min),('BB-DD-002',max,max,max))
*/
从执行计划步骤12 SSEK2和步骤10 SLCT2操作符的附加信息可以看出视图的过滤条件被下放。 但回表大严重(2754812行),由此可以推断这表很大,然而看着应用复合索引,只能命中一个字段定位,二次回表再过滤,不慢才怪。 所以影响此SQL的罪魁祸首是回表200+W的数据,造成大量的逻辑读和磁盘读。
2)视图过滤性
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V ; -- 110 265 448 1亿1千万的数据行
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V m where m.bbid='BB-DD-002' and m.bbrq='20221014'; -- 816 过滤性极强
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V m where m.bbid='BB-DD-002' and hzb=45 and lzb=6 and bbrq='20221014'; -- 1
视图里面只有一个基表且数据量庞大,bbid和bbrq组合条件过滤性很强,对它们建个索引效果更好。
3)查看已有索引定义
/*
-- 表定义
CREATE TABLE "RAW_SMES"."BB_DWSJ_TB"
(
"QYZD_BH" VARCHAR2(40),
"DWZD_BH" VARCHAR2(30),
"BBZD_ID" VARCHAR2(20),
"BBZD_DATE" VARCHAR2(10),
"BBZD_YEAR" VARCHAR2(10),
"BBZD_MON" VARCHAR2(10),
"BBZD_DAY" VARCHAR2(10),
"BBZD_QUA" VARCHAR2(10),
"BBZD_TENDAY" VARCHAR2(10),
"BBZD_WEEK" VARCHAR2(10),
"HZD_ZB" NUMBER,
"LZD_ZB" NUMBER,
"H_BZBM" VARCHAR2(30),
"L_BZBM" VARCHAR2(30),
"DYZD_SJ" VARCHAR2(500),
"DYZD_DATA" NUMBER(20,6),
"XSSX" NUMBER,
"HZD_NM" VARCHAR2(50),
"LZD_NM" VARCHAR2(50),
"INSERT_ODS_TIME" TIMESTAMP(0),
"UPDATE_ODS_TIME" TIMESTAMP(0),
"M_ROW$$" VARCHAR2(128)) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;
-- 索引定义
CREATE UNIQUE INDEX "UK_M_ROW" ON "RAW_SMES"."BB_DWSJ_TB"("M_ROW$$" ASC) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;
CREATE INDEX "IDX_BB_DWSJ" ON "RAW_SMES"."BB_DWSJ_TB"("BBZD_ID" ASC,"BBZD_DATE" ASC,"HZD_NM" ASC,"LZD_NM" ASC) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;
*/
看到索引定义("BBZD_ID" ASC,"BBZD_DATE" ASC,"HZD_NM" ASC,"LZD_NM" ASC) 时,知道他们离优化成功半步之遥,不懂BBZD_DATE字段被视图转换拼接, 已不再是原始字段,所以这个索引无法利用上第2个字段,则解释清楚1)所说的执行计划涉及的回表严重。
2.3 视图改写
原始视图的bbrq视图列定义SUBSTR (t1.bbzd_date, 1, 4) || SUBSTR (t1.bbzd_date, 7, 2) || SUBSTR (t1.bbzd_date, 9, 2) AS bbrq, 写得太复杂,无非就是从字符类型的bbzd_date截取出合法的日期格式数据,把一大趾函数转换简单化,变成stuff函数,减少复杂计算, 还能让后面建函数索引更简单方便。-- redefination view reduce function cost
CREATE OR REPLACE VIEW DISPLAYCENTER.WL_DDBB_WEEK_V
AS
SELECT
t1.bbzd_id bbid,
'' bbmc ,
stuff(t1.bbzd_date, 5, 2, '') AS bbrq, -- 改写位置
t1.hzd_nm hzb ,
t1.lzd_nm lzb ,
dyzd_sj as VALUE
FROM
(
SELECT T1.* FROM RAW_SMES.Bb_Dwsj_Tb T1
)
t1 ;
2.4 增添复合索引
create index idx_comb_bbid_hzb_lzb on “RAW_SMES”.“BB_DWSJ_TB”(BBZD_ID, STUFF(bbzd_date, 5, 2, ‘’), HZD_NM,LZD_NM ) ONLINE;
将就原来他们建的索引IDX_BB_DWSJ的逻辑,把第2个字段替换成stuff函数。再来一探执行计划的变化,不出意外的话,将会充分利用上索引前两个字段的过滤性。
/* 执行时间:4毫秒
1 #NSET2: [163, 1, 912]
2 #PRJT2: [163, 1, 912]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [163, 1, 912]; B.R > var2
4 #PRJT2: [163, 1, 912]; exp_num(8), is_atom(FALSE)
5 #RN: [163, 1, 912]
6 #PRJT2: [163, 1, 912]; exp_num(7), is_atom(FALSE)
7 #TOPN2: [163, 1, 912]; top_num(exp11)
8 #AFUN: [163, 1, 912]; afun_num(1); partition_num(0); order_num(0)
9 #PRJT2: [163, 68469, 912]; exp_num(6), is_atom(FALSE)
10 #SLCT2: [163, 68469, 912]; (exp_cast(T1.HZD_NM) = 45 AND exp_cast(T1.LZD_NM) = 6)
11 #BLKUP2: [163, 68469, 912]; IDX_COMB_BBID_HZB_LZB(T1)
12 #SSEK2: [163, 68469, 912]; scan_type(ASC), IDX_COMB_BBID_HZB_LZB(BB_DWSJ_TB as T1), scan_range[('BB-DD-002','20221014',min,min),('BB-DD-002','20221014',max,max))
*/
3. 优化总结
懂得索引合理创建,不要乱建索引,复合索引的组合字段弄得太多不是好事,因为能利用上的索引键就一个或两个,完全没意义弄这么多索引键,潜在隐藏一个信息,索引体积太大,索引B+树庞大,可能引起大量的IO读写,影响索引扫描的效率。
一定要充分利用索引特性,够小(体积小,可以理解为表的瘦身版),够高效(过滤性强)。
明白视图的优化手段,无非包含视图上拉、视图合并等等优化思想。






![[CFI-CTF 2018]powerPacked 题解](https://img-blog.csdnimg.cn/b11d54e6970748fa959021924ba7dc32.png)