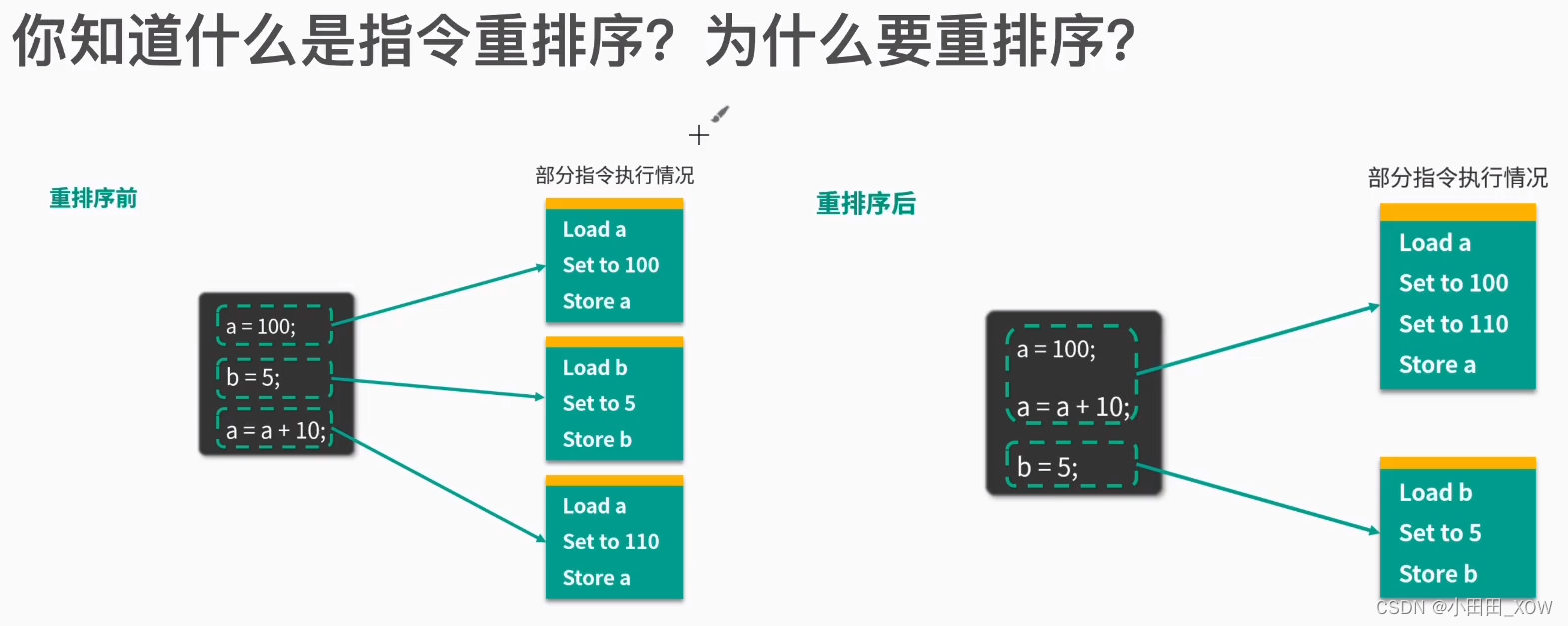
关于a的操作,由原来的6个指令,变成了4个指令。
1. 指令重排序的介绍
1)指令重排序的类型
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
重排序分三种类型:
编译器优化的重排序 编译器在不改变单线程程序语义的前提下(代码中不包含synchronized关键字),可以重新安排语句的执行顺序。
指令级并行的重排序 现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排序 由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行
重排序又可以分为两大类,
一是编译器重排序:编译器优化重排序,
二是处理器重排序:指令级并行重排序、内存系统重排序。
2)重排序的流程
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

3)重排序意义
处理器为提高运算速度而做出违背代码原有顺序的优化。
4)存在的问题
这三种重排序方法都可能会导致多线程程序出现内存可见性问题。
2. 内存系统重排序
1)内存系统的读操作
为提高从内存读取的效率,对读操作进行优化,将其称为程序乱序执行优化。CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令必须是独立的、没有依赖关系,cpu一般是依赖指令间的内存引用关系来判断的指令间的”独立关系”。
2)内存系统的写操作
写操作的优化称为合并写入技术。现代的处理器使用写缓冲区来临时保存向内存写入的数据。
写操作优化的过程:乱序当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区。这一技术称为合并写入技术。
在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区,该缓冲区大小和一个cache line大小,一般都是64字节。这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响。当后续的写操作需要修改相同的缓存行时,在将后续的写操作提交到L2缓存之前,可以进行缓冲区写合并。
这些64字节的缓冲区维护了一个64位的字段,每更新一个字节就会设置对应的位,来表示将缓冲区交换到外部缓存时哪些数据是有效的。当然,如果程序读取已被写入到该缓冲区的某些数据,那么在读取缓存数据之前会先去读取本缓冲区的。经过上述步骤后,缓冲区的数据还是会在某个延时的时刻更新到外部的缓存(L2_cache).如果能在缓冲区传输到缓存之前将其尽可能填满,这样的效果就会提高各级传输总线的效率,以提高程序性能。
3)写缓冲区造成的优势
优势1,合并写缓冲区中对同一内存地址的多次写操作,可以减少对内存总线的占用;
优势2,通过以批处理的方式刷新写缓冲区;
优势3,写缓冲区可以保证指令流水线持续运行,避免由于处理器停顿下来等待向内存写入数据而产生的延迟。
4)出现问题的原因
在单核时代处理器做出的优化可以保证执行结果不会远离预期目标,但是,在多核时代却并非如此。在多核时代,同时会有多个核同时执行指令,每一个核的指令都可能被乱序。另外,处理器还引入了L1,L2,…,Ln等多级缓存机制,每个核心都有自己的缓存机制,这样就导致了逻辑次序上后写入内存的数据未必真的最后写入。最后就带来一个问题,如果不做任何防护措施,处理器最终得出的结果和逻辑得出结果会大不相同。
比如,在一个核上执行写入操作,并在最后写一个标记用来表示操作完毕,之后从另外一个核上通过判断这个标记来判定所需要的数据是否已经就绪,这种做法就存在一定风险:标记位先被写入但之前的操作却并未完成(可能是未计算完成,也可能是数据没有从处理器缓存刷新到主存中,最终导致另外的核使用了错误的数据)。
3. 内存屏障
3.1. 硬件内存屏障
1)CPU内存屏障(硬件内存屏障)
功能:为了解决代码的乱序执行问题,在CPU级别上引入了内存屏障,这里跟JAVA的内存屏障不是一个问题。
分类:
指令 功能
sfence 在sfence指令前的写操作必须在sfence指令后的写操作之前完成
lfence 在lfence指令前的读操作必须在lfence指令后的读操作之前完成
mfence 在mfence指令前的读写操作必须在mfence指令后的读写操作之前完成
原子指令:例如X86中的lock指令,执行时会锁住内存子系统来保障执行顺序不改变,甚至能跨多个CPU。
Software Locks通常使用内存屏障和原子指令来实现变量的可见性和执行顺序不变。
3.2. 内存系统的内存屏障
1)使用背景
对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
2)基本使用
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。
JMM把内存屏障指令分为下列四类:
LoadLoad屏障 语句:Load1; LoadLoad; Load2
在Load2及后续读取操作要在读取的数据被访问前,保证Load1要读取的数据被读取完毕
StoreStore屏障 语句:Store1; StoreStore; Store2
在Store2及后续写入操作执行前,保证Store1的写入操作对其他处理器可见
LoadStore屏障 语句:Load1; LoadStore; Store2
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕
StoreLoad屏障 语句:Store1; StoreLoad; Load2
在Load2及后续所有读取操作执行前,保证Store1的写入对其他处理器是可见
3)StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)
4)允许指令重排序的列表
下面是常见处理器允许的重排序类型的列表:

注:上表单元格中的“N”表示处理器不允许两个操作重排序,“Y”表示允许重排序。
从上表我们可以看出:常见的处理器都允许Store-Load重排序;常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO和x86拥有相对较强的处理器内存模型,它们仅允许对写-读操作做重排序(因为它们都使用了写缓冲区)。
4. happens-before关系
1)基本介绍
JSR-133使用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
2)happens-before规则
与程序员密切相关的happens-before规则如下:
程序顺序规则 一个线程中的每个操作,happens- before 于该线程中的任意后续操作
监视器锁规则 对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁
volatile变量规则 对一个volatile域的写,happens- before 于任意后续对这个volatile域的读
传递性 如果A happens- before B,且B happens- before C,那么A happens- before C
Start规则
Join规则
特殊说明:两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。
3)happens-before与JMM的关系

如上图所示,一个happens-before规则通常对应于多个编译器和处理器重排序规则。对于java程序员来说,happens-before规则简单易懂,避免java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。
3.5. as-if-serial语义
1)数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:

上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
注:这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
2)as-if-serial语义
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变,编译器,runtime 和处理器都必须遵守as-if-serial语义。即编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
参考:
【23版面试突击】你知道什么是指令重排序?为什么要重排序?_哔哩哔哩_bilibili
指令重排序_Waiting_Mr_Liu的博客-CSDN博客