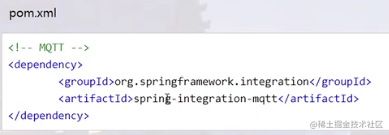
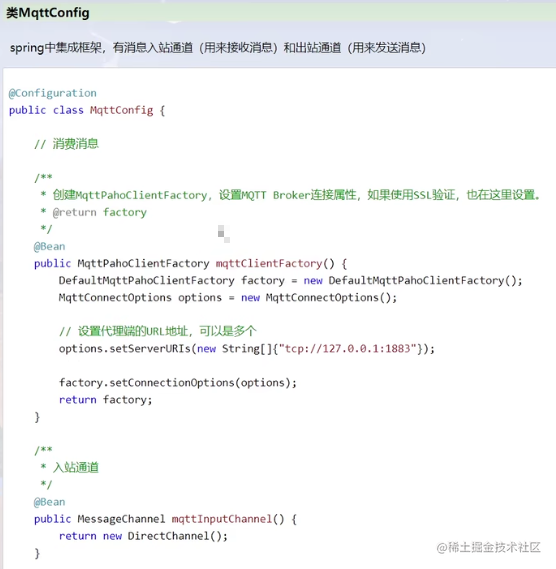
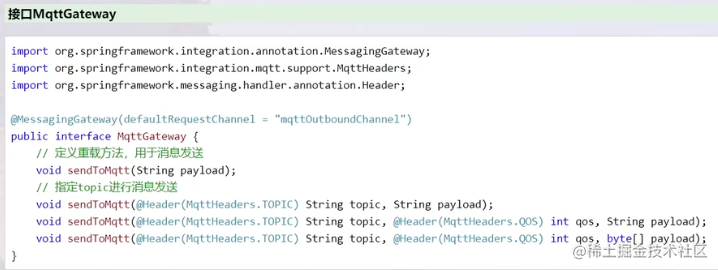
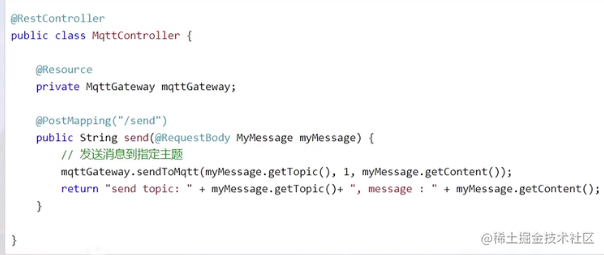
消费





Netty的优点有很多:
API使用简单,学习成本低。
功能强大,内置了多种解码编码器,支持多种协议。
性能高,对比其他主流的NIO框架,Netty的性能最优。
社区活跃,发现BUG会及时修复,迭代版本周期短,不断加入新的功能。
Dubbo、Elasticsearch都采用了Netty,质量得到验证。
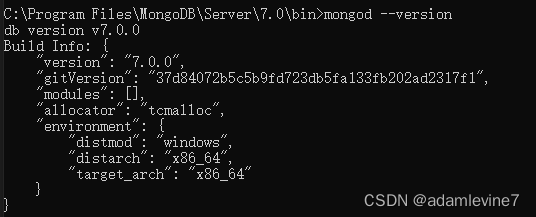
在 Mac 上安装 Cassandra 的 cqlsh 可以使用以下步骤:
安装 Homebrew:如果您尚未安装 Homebrew,请在终端中运行以下命令:/usr/bin/ruby -e "$(curl -fsSL raw.githubusercontent.com/Homebrew/in…[1])"
安装 Cassandra:使用以下命令安装 Cassandra:brew install cassandra
启动 Cassandra:使用以下命令启动 Cassandra 服务:cassandra -f
运行 cqlsh:使用以下命令启动 cqlsh:cqlsh
Cassandra cqlsh - connection refused
启动cqlsh时,保存如下:
在启动时,指定连接的IP和端口
输出结果如下:
Connected to Test Cluster at 100.106.242.180:9042.``[cqlsh 5.0.1 | Cassandra 3.9 | CQL spec 3.4.2 | Native protocol v4]``Use HELP ``for help.``cqlsh>
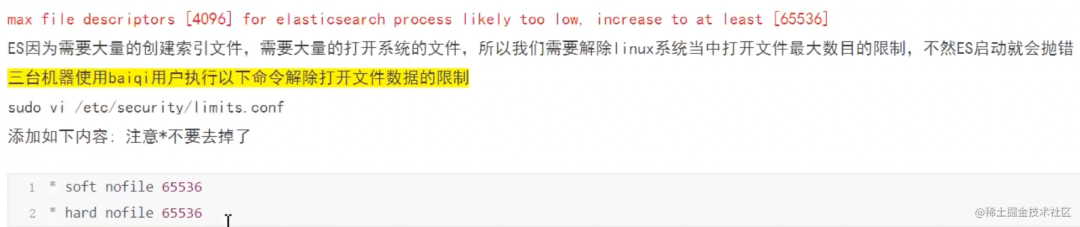

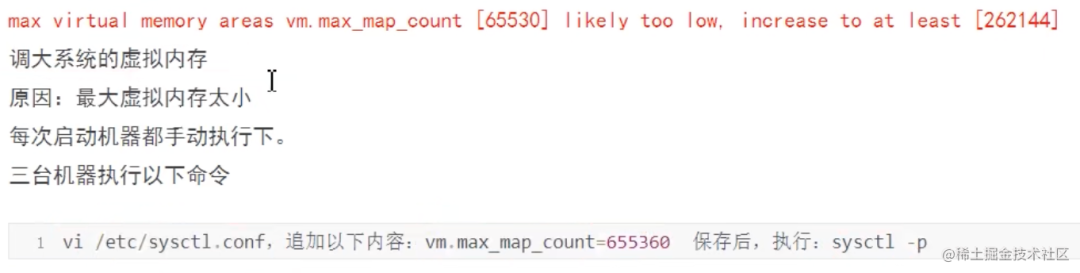
/etc/security/limits.conf
Open
elasticsearch.ymal;add
bootstrap.system_call_filter: false

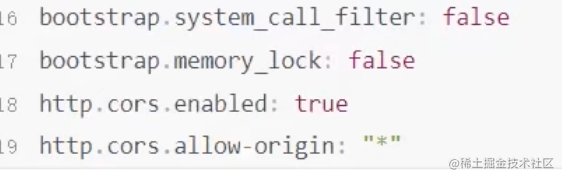
查看用户
cat /etc/passwd查看用户组
cat /etc/group查看当前活跃的用户列表
要在 Vite 配置中启用 Gzip 压缩,你需要做以下几个步骤:
首先,安装
vite-plugin-compression插件,它可以帮助你在构建时启用 Gzip 压缩。在终端中运行以下命令:
npm install vite-plugin-compression --save-dev在你的 Vite 配置文件(通常是
vite.config.js)中,导入vite-plugin-compression并在plugins数组中添加该插件的配置:
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import viteCompression from 'vite-plugin-compression'; // 导入插件
export default defineConfig({
// ...其它配置...
plugins: [
// ...其它插件...
// 添加 vite-plugin-compression 插件
viteCompression({
algorithm: 'gzip', // 使用 Gzip 压缩算法
ext: '.gz', // 压缩文件的扩展名
deleteOriginFile: false, // 是否删除原始文件
}),
],
// ...其它配置...
});保存并关闭配置文件。
这样,当你运行 Vite 构建命令时,vite-plugin-compression 将会在构建完成后自动对生成的静态资源文件进行 Gzip 压缩。

ribbon:
eager-load:
enabled: true # 开启Ribbon的饥饿加载模式,启动时创建 RibbonClient
MaxAutoRetries: 1 # 同一台实例的最大重试次数,但是不包括首次调用,默认为1次
MaxAutoRetriesNextServer: 2 # 重试负载均衡其他实例的最大重试次数,不包括首次调用,默认为0次
OkToRetryOnAllOperations: true # 是否对所有操作都重试,默认false
ServerListRefreshInterval: 2000 # 从注册中心刷新服务器列表信息的时间间隔,默认为2000毫秒,即2秒
retryableStatusCodes: 400,401,403,404,500,502,504
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RetryRule #配置规则 重试
ConnectTimeout: 3000 #连接建立的超时时长,默认1秒
ReadTimeout: 3000 #处理请求的超时时间,默认为1秒
MaxTotalConnections: 1000 # 最大连接数
MaxConnectionsPerHost: 1000 # 每个host最大连接数
restclient:
enabled: true下载并解压缩
首先是下载。在apache的官方网站提供了好多镜像下载地址,然后找到对应的版本,目前最新的是3.4.13。
http://mirrors.cnnic.cn/apache/ZooKeeper/ZooKeeper-3.4.13/ZooKeeper-3.4.13.tar.gz
mkdir -p /work/zookeeper/zooKeeper-3.4.13
tar -zxvf /work/zookeeper/zooKeeper-3.4.13.tar.gz -C /work/zookeeper/zooKeeper-3.4.13安装Zookeeper
安装集群的第一步,在安装目录下,创建好两个目录:日志目录、数据目录。
mkdir -p /work/zookeeper/zooKeeper-3.4.13/data
mkdir -p /work/zookeeper/zooKeeper-3.4.13/logs进入 /work/zookeeper/zooKeeper-3.4.13/conf目录,把zoo_sample.cfg文件复制一份名字改成zoo.cfg。
cp zoo_sample.cfg zoo.cfg1、安装JDK
java -version 保证JDK至少在1.8.0_73以上
2、下载elasticsearch
brew install elasticsearch 3、启动,或者直接elasticsearch命令
brew services start elasticsearch
<script type="text/javascript" src="http://webapi.amap.com/maps?v=1.4.4&key=粘贴刚刚复制好的key"></script>module.exports = {
configureWebpack: {
externals: {
'AMap': 'AMap' // 表示CDN引入的高德地图
}
}
}<template>
<div class="box">
<div id="container" style="width:500px; height:300px"></div>
<div class="info">
<div class="input-item">
<div class="input-item-prepend">
<span class="input-item-text" style="width:8rem;">请输入关键字</span>
</div>
<input id='tipinput' type="text">
</div>
</div>
</div>
</template>
<script>
import AMap from 'AMap' // 引入高德地图
import { onMounted } from 'vue'
export default {
name: 'Login',
setup () {
onMounted(() => {
const map = new AMap.Map('container', { // 这里表示创建地图 第一个参数表示地图的div的id
resizeEnable: true // 表示是否在加在所在区域的地图,如果定了别的区域,比如北京,就会默认加载北京
})
// 使用AMap插件 第一个是搜索框插件,第二个地址信息(经纬度名字之类)的插件
AMap.plugin(['AMap.Autocomplete', 'AMap.PlaceSearch'], function() {
const autoOptions = {
// 使用联想输入的input的div的id
input: 'tipinput'
}
const autocomplete = new AMap.Autocomplete(autoOptions)
const placeSearch = new AMap.PlaceSearch({
city: '长沙',
map: map
})
AMap.event.addListener(autocomplete, 'select', function(e) {
console.log(e.poi.location) // 获取选中的的地址的经纬度
placeSearch.search(e.poi.name)
})
})
})
return {
}
}
}
</script>
<style scoped lang="scss">
@import "~@/styles/scss/_global.scss";
.info {
padding: .5rem .7rem;
margin-bottom: 1rem;
border-radius: .25rem;
position: fixed;
top: 1rem;
background-color: white;
width: auto;
min-width: 15rem;
border-width: 0;
right: 1rem;
box-shadow: 0 2px 6px 0 rgba(240, 131, 0, .5);
.input-item {
position: relative;
display: flex;
flex-wrap: wrap;
align-items: center;
width: 100%;
height: 2.2rem;
border: 1px solid $themeTextColor;
border-radius: .2rem;
.input-item-prepend {
margin-right: -1px;
}
.input-item-prepend {
width: 35%;
font-size: 13px;
border-right: 1px solid $themeTextColor;
height: 100%;
display: flex;
align-items: center;
background: rgba(240, 131, 0, .1);
span {
text-align: center;
}
}
input {
width: 60%;
background: #fff;
padding: .2rem .6rem;
margin-left: .3rem;
border: none;
}
}
}
</style>spring cloud 脚手架,上手即用,集成swagger,对外rest接口,集成主流互联网saas架构,包含es,hbase,kafka,redis,mongo等

在 Spring Boot 中,BigDecimal 是 Java 中的一个类,用于进行高精度的十进制计算。它通常用于处理需要精确计算的金融、货币和其他需要保持精度的数值运算。
BigDecimal 的设计目的是避免浮点数计算中的精度问题。浮点数在计算机中是以二进制表示的,所以在某些情况下会产生舍入误差,特别是在涉及小数点后很多位的计算中。而 BigDecimal 使用了大整数和小数的组合表示,可以精确地处理小数位数较多的数值,避免了舍入误差。
在 Spring Boot 中,你可以使用 BigDecimal 类来进行精确的数值计算,比如货币计算、税金计算等。以下是一个简单的示例,展示了如何在 Spring Boot 中使用 BigDecimal:
import java.math.BigDecimal;
public class BigDecimalExample {
public static void main(String[] args) {
BigDecimal num1 = new BigDecimal("10.25");
BigDecimal num2 = new BigDecimal("5.75");
// 加法
BigDecimal sum = num1.add(num2);
System.out.println("Sum: " + sum);
// 减法
BigDecimal difference = num1.subtract(num2);
System.out.println("Difference: " + difference);
// 乘法
BigDecimal product = num1.multiply(num2);
System.out.println("Product: " + product);
// 除法
BigDecimal quotient = num1.divide(num2, 2, BigDecimal.ROUND_HALF_UP);
System.out.println("Quotient: " + quotient);
}
}在这个示例中,我们使用了 BigDecimal 类来执行加法、减法、乘法和除法操作,并且可以通过指定精度和舍入模式来得到预期的结果。
各子目录
蓝色 表示文件夹;
灰色 表示普通文件;
绿色 表示可执行文件;
红色 表示压缩文件;
天蓝色 表示链接文件(快捷方式);
常用目录的作用如下:
bin: 存放普通用户可执行的指令,普通用户也可以执行;
dev : 设备目录,所有的硬件设备及周边均放置在这个设备目录中;
boot : 开机引导目录,包括 Linux 内核文件与开机所需要的文件;
home: 这里主要存放你的个人数据,具体每个用户的设置文件,用户的桌面文件夹,还有用户的数据都放在这里。每个用户都有自己的用户目录,位置为:/home/用户名。当然,root 用户除外;
usr: 应用程序放置目录;
lib: 开机时常用的动态链接库,bin 及 sbin 指令也会调用对应的 lib 库;
tmp: 临时文件存放目录 ;
etc: 各种配置文件目录,大部分配置属性均存放在这里;
一些常用的命令见下:
| 作用 | 命令 |
|---|---|
| 切换目录 | cd |
| 显示当前目录完整路径 | pwd |
| 查看目录下的信息(包括隐藏文件) | ls(ls -a) |
| 列出目录下的文件和详细信息 | ls-l (ll) |
| 创建目录 | mkdir |
| 创建文件 | touch |
| 复制文件(文件夹) | cp(cp -r) |
| 移动/重命名文件夹和目录 | mv |
| 删除文件(目录) | rm(rm -rf) |
| 删除空文件夹 | rmdir |
| 查找文件 | find |
| 获取帮助 | man / info |
常用的快捷键:
| 作用 | 快捷键 |
|---|---|
| 清空至行首 | Ctrl + U |
| 清空至行尾 | Ctrl + K |
| 清屏 | Ctrl + L |
| 终止执行的命令 | Ctrl + C |
tree 命令查看目录树
首先安装一下 sudo yum -y install tree
vim 编辑器使用方法
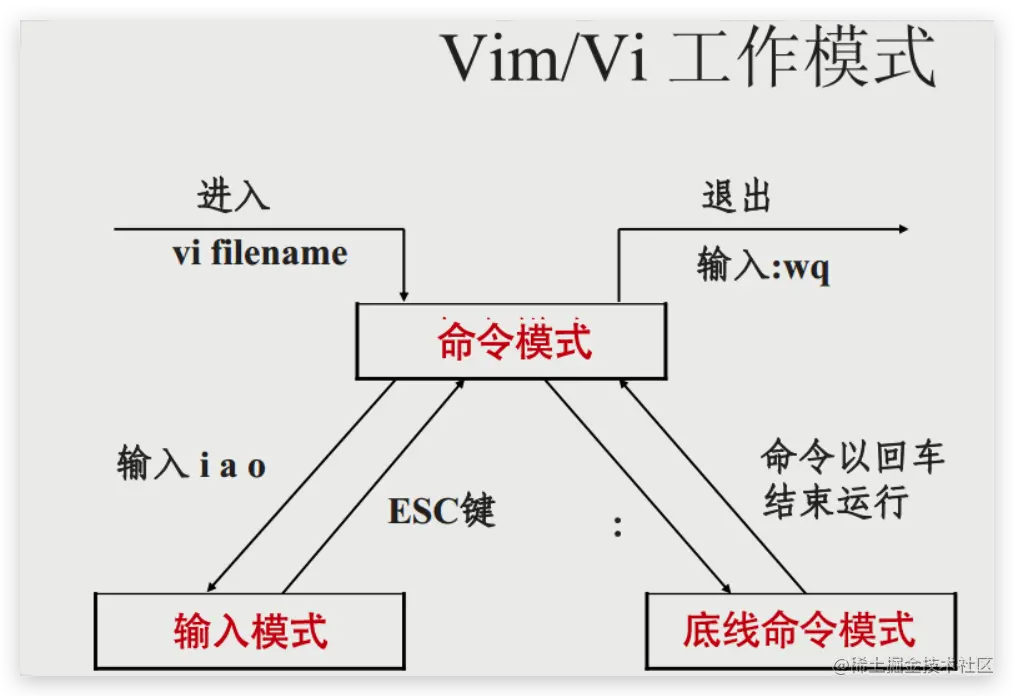
命令模式
i 切换到输入模式,以输入字符;
: 切换到底线命令模式,以在最底一行输入命令;
a 切换到输入文字模式;
输入模式
在命令模式下按下 i 就进入了输入模式。在输入模式中,可以使用以下按键:
| 功能 | 命令 |
|---|---|
| 向上翻页 | PageDown / Ctrl + F |
| 向下翻页 | PageUp / Ctrl + B |
| 跳转到文件首行 | 1G / gg |
| 跳转到末尾行 | G |
| 跳转到第 # 行 | #G |
| 行号显示 | :set nu |
| 行号显示取消 | :set nonu |
| 插入 | d / Del |
| 删除当前行 | dd |
| 复制 | yy |
| 将缓冲区中的内容粘贴到光标位置处之后 | p |
底线命令模式
基本的命令
:q 退出程序;
:q! 放弃对文件内容的修改并退出;
:w 保存文件;
:w /root/xx 另存为;
:wq 保存文件并退出;
查看文件内容
一些常见查看文件内容的命令:
| 功能 | 命令 |
|---|---|
| 浏览文件全部内容 | more / less |
| 查看文件内容(显示行号) | cat (cat -n) |
| 在文本文件中查找字符串(显示行号) | grep (grep <关键字> <要查找的文件> -n) |
进程管理
ps 命令:
ps aux ,查看系统中所有进程,使用 BSD 操作系统格式;
ps -le ,查看系统中所有进程,使用 Linux 标准命令格式;
输出的格式含义:
USER:该进程由哪个用户产生的;
PID:进程的 ID;
%CPU:进程占用 CPU 资源的百分比;
%MEM:进程占用物理内存的百分比;
VSZ:进程占用虚拟内存的大小,单位 KB;
RSS:进程占用实际物理内存的大小,单位 KB;
TTY:进程在哪个终端运行的,tty1-tty7 代表本地控制台终端,tty1-tty6 是本地的字符界面终端,tty7 是图形终端,pts/0-255 代表虚拟终端,如果是 ? 则代表是系统进程;
STAT:进程状态,R-运行,S-睡眠,T-停止,s-包含子进程,+-位于后台;
START:进程启动时间;
TIME:进程占用 CPU 的运算时间,注意不是系统时间;
COMMAND,产生此进程的命令名;
top 命令可以查看系统健康状态,和 Windows 系统中的系统管理器类似。
top 命令的交互模式中可以执行下面命令:
?/h : 显示交互模式的帮助;
P :以 CPU 使用率排序,默认就是此项;
M:以内存的使用率排序;
N :以 PID 排序;
q :退出 top;
杀死进程
杀死进程主要有下面几个命令:
| 功能 | 命令 |
|---|---|
| 杀死某个进程 | kill |
| 按照进程名杀死进程 | killall |
| 按照进程名杀死进程,加 -t 可以按照终端号踢出用户 | pkill |
常用杀死进程的命令:正常杀死 kill -1 2235 或者强制杀死 kill -9 2235
SSH 操作
Secure Shell(SSH)是建立在应用层基础上的安全网络协议,是专为远程登录会话和其他网络服务提供安全性的协议,可有效弥补网络中的漏洞。通过 SSH,可以把所有传输的数据进行加密,也能够防止 DNS 欺骗和 IP 欺骗。还有一个额外的好处就是传输的数据是经过压缩的,所以可以加快传输的速度,已经成为Linux系统的标准配置。
SSH 登陆服务器
ssh -p port <username>@<hostname or IP address>比如我这里购买的腾讯云服务器就可以使用 ssh root@<公网IP/域名> 连接,如果你设置过域名对 IP 的映射,那么 @ 后面写你的域名也可以
SSH 上传/下载文件
SSH 可以通过 scp 命令来上传文件,是 Linux 系统下基于 SSH 登陆进行安全的远程文件拷贝命令,scp 是 secure copy 的简写,可以使用它上传本地文件夹到远程服务器,也可以从远程服务器上下载文件夹到本地:
# 上传文件夹到远程服务器
scp -P port -r /local/dir username@servername:/remote/dir
# scp -p 2333 -r /test/a root@192.168.0.101:/var/b
# 从远程服务器下载文件夹
scp -P port -r username@servername:/remote/dir/ /local/dir
# scp -p 2333 -r root@192.168.0.101:/var/b /test/a-r 参数表示递归复制,即复制该目录下面的文件和目录,如果要上传单个文件,只要把 -r 删除。大写的 P 表示的是端口,如果还是默认的 SSH 端口 22 没有更改,则不需要 -P。
在 Vue 3 项目中使用 Vite 作为构建工具,配置文件是 vite.config.js 而不是 vue.config.js。对于性能分析,speed-measure-webpack-plugin 通常与 Webpack 一起使用,而 Vite 使用的是 ESBuild 作为默认的构建工具,所以不能直接在 Vite 中使用这个插件。但是,你可以使用其他方式来进行性能分析。
在 Vite 项目中进行性能分析,你可以考虑使用 Vite 的官方插件 vite-plugin-analysis。以下是在 vite.config.ts 中添加 vite-plugin-analysis 插件的步骤:
安装插件:
在你的 Vue 3 + Vite 项目根目录下,打开终端或命令行工具,并执行以下命令:
npm install vite-plugin-analysis --save-dev配置插件:
打开你的 vite.config.ts 文件,并添加以下配置:
import ViteAnalysis from 'vite-plugin-analysis';
export default {
plugins: [
ViteAnalysis({
// 可选配置项,详见插件文档
}),
],
};以上配置中,我们导入了 vite-plugin-analysis 插件,并将其作为 Vite 的插件配置项之一。
运行开发服务器:
在终端或命令行工具中运行以下命令以启动 Vite 开发服务器:
npm run devVite 将会在终端输出详细的性能分析结果,包括模块大小、构建时间等信息,帮助你了解构建过程中的性能状况。
总之,虽然不能直接在 Vite 中使用 speed-measure-webpack-plugin,但使用 Vite 的 vite-plugin-analysis 插件也能帮助你实现类似的性能分析目标。
Apache Kafka起源于LinkedIn,后来于2011年成为开源Apache项目,然后于2012年成为First-class Apache项目。Kafka是用Scala和Java编写的。 Apache Kafka是基于发布订阅的容错消息系统。 它是快速,可扩展和设计分布。
在大数据中,使用了大量的数据。 关于数据,我们有两个主要挑战。第一个挑战是如何收集大量的数据,第二个挑战是分析收集的数据。 为了克服这些挑战,您必须需要一个消息系统。
Kafka专为分布式高吞吐量系统而设计。 Kafka往往工作得很好,作为一个更传统的消息代理的替代品。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
什么是消息系统?
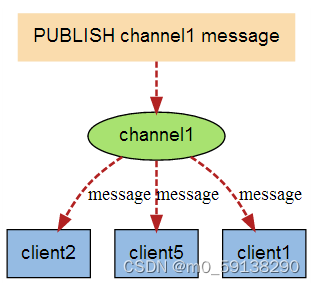
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。 分布式消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用 - 一种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。 大多数消息模式遵循 ****pub-sub ****。
点对点消息系统
在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消费。 一旦消费者读取队列中的消息,它就从该队列中消失。 该系统的典型示例是订单处理系统,其中每个订单将由一个订单处理器处理,但多个订单处理器也可以同时工作。 下图描述了结构。
发布 - 订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview
参考资料
[1]
https://raw.githubusercontent.com/Homebrew/install/master/install: https://link.juejin.cn/?target=https%3A%2F%2Fraw.githubusercontent.com%2FHomebrew%2Finstall%2Fmaster%2Finstall