目录
- 一、前言
- 二、目标介绍
- 三、使用 pgsql 实现
- 3.1 拆分 content 字段
- 3.2 拆分 level 字段
- 3.3 拼接两个拆分结果
- 四、使用 ODPS SQL 实现
- 4.1 拆分 content 字段
- 4.2 拆分 level 字段
- 4.3 合并拆分
- 五、使用 MySQL 实现
- 六、总结
一、前言
商业场景中,经常会出现新的业务,继而产生新的业务数据,这也难免会导致一些数据被孤立,所以便需要对数据进行同步整合。在清洗数据的过程中,难免也会出现同一个 SQL 逻辑需要使用不同的平台各自支持的一套 SQL 语言来实现。
本文介绍的就是一个同样的 SQL 逻辑,通过不同的平台进行操作。
相关平台:阿里云的 postgresql 和 阿里云的 MaxCompute SQL(下面称 ODPS SQL)。
版本说明:
PostgreSQL:PostgreSQL 11.3 64-bit
MySQL:MySQL 8.0.16
ODPS SQL:odps-sql-function version: r570e07eb77a5063f8c5715b0fa0beeba(阿里云似乎会默认更新到最新版)
二、目标介绍
首先介绍下抽象出来的数据,有一个表,记录2列数据,可以看做是一个答题记录,content列记录用户的某个类的答题内容,而level列记录用户对应类的等级信息,结构如下:

创建临时数据集的 SQL:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
select *
from t1;
最终处理效果为:
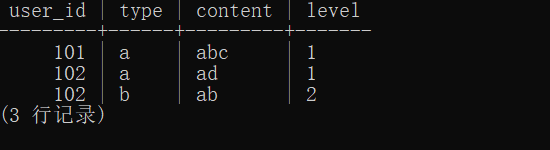
将content和level里的键值信息分别都取出来,然后拼接成一个用户在某个类型的答题内容和等级信息表单,方便做业务分析。
基本分析:content和level的字符类型都是字符串,但他们的数据结构比较特殊,content是一个 Json 数组结构的字符串,而level是一个键值对结构的字符串。 进行处理的过程中可以将他们转为 Json 字符类型进行处理。
由于不同的用户的行为不同,Json 的元素的长度也是不一致的,所以要将类型(type)展开,需要分别处理两个字段,最后再进行联结。
三、使用 pgsql 实现
pgsql 有比较强大的 json 函数,可以通过相关的 json 函数辅助处理 json 结构的数据,参考 阿里云的 postgresql 的 json 函数文档
3.1 拆分 content 字段
content是一个 Json 数组结构的字符串,所以可以通过::json函数转化为 json 数据类型之后,通过json_array_elements()函数进行元素拆分,一行一个元素。
SQL 参考如下:
-- 拆元素
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
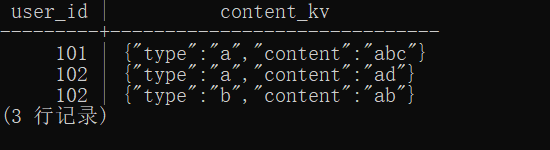
select user_id,json_array_elements(content::json) as "content_kv"
from t1;
拆分结果如下,可以看到已将content数据中的每一个元素都拆分开,一行保留一个元素,这时用户 102 有两行记录。
接下来就是把上面的结果中,以键为字段名,以值为字段值,将固定长度的键值对处理为两个新列type和content。直接通过键取值即可,参考 SQL 如下:
-- 拆元素并取值
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
select user_id
,json_array_elements(content::json) as "content_kv"
,json_array_elements(content::json)->>'type' as "type"
,json_array_elements(content::json)->>'content' as "content"
from t1;
结果如下:
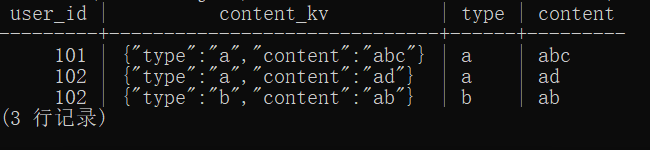
返回结果中,user_id、type和content三个字段便是最终需要的字段。所以拆分原始content字段的任务到此完成。
3.2 拆分 level 字段
接下来拆分level字段。level是一个键值对结构字符串,键值对是标准 json 结构,所以可以通过转化为 json 数据类型之后,再借助json_object_keys()提取键值对中的所有键,一行一个,顺带也将键对应的值提取出来。
先将键取出来,SQL 如下:
-- 取键值对的键
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
select user_id,level,json_object_keys(level::json) as "type"
from t1;
结果如下:
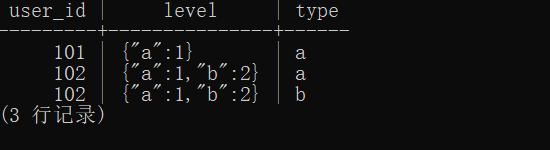
有了键,再取值,就很方便了,通过->取值即可。参考 SQL 如下:
-- 取键值对的键和值
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
select user_id
,level
,json_object_keys(level::json) as "type"
,level::json -> json_object_keys(level::json) as "level"
from t1;
结果如下:
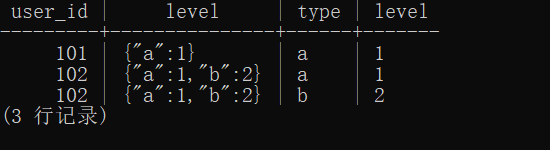
返回结果中,user_id、type和level三个字段便是最终需要的字段。所以拆分原始level字段的任务到此完成。
3.3 拼接两个拆分结果
拼接这步则相对比较简单,分别将以上的两个拆分的结果作为两个子查询,然后通过user_id和type进行连接即可。
参考 SQL 如下:
-- 拼接
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
select t1_content.user_id,t1_content.type,t1_content.content,t1_level.level
from(
select user_id
,json_array_elements(content::json)->>'type' as "type"
,json_array_elements(content::json)->>'content' as "content"
from t1
)t1_content
left join(
select user_id
,json_object_keys(level::json) as "type"
,level::json -> json_object_keys(level::json) as "level"
from t1
)t1_level on t1_level.user_id=t1_content.user_id and t1_level.type=t1_content.type
;
最终结果如下:
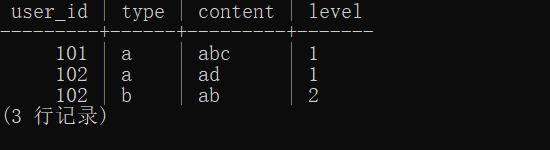
通过 pgsql 处理还是比较简单的,基本上就是四个函数便可解决,四个函数分别是:::json、json_array_elements()、json_object_keys()、->和->>。
但是使用 ODPS SQL 就没有那么便捷了!
四、使用 ODPS SQL 实现
ODPS 是阿里基于Hive的核心思想构建的,不同的是 Hive 的文件存储在 hdfs 上,ODPS 则存在阿里的盘古里,而且 ODPS 针对 Hive 做了一些优化,所以 ODPS SQL 和 HQL 比较接近,和 MySQL 也有一定的相似性。
由于 ODPS SQL 没有像 pgsql 那么便捷的 json 函数,所以需要通过其他的方式进行拆分元素。通过查阅官方的 SQL 文档,发现可以通过以下的方式进行替换,仅展示主要函数:
| Postgres SQL | ODPS SQL |
|---|---|
| ::json | json_parse() |
| json_array_elements() | regexp_count()、lateral view explode() |
| json_object_keys() | str_to_map()、map_values()、lateral view explode() |
| -> | [] 或 json_extract() |
| ->> | json_extract() |
参考:ODPS SQL 的 json 等复杂函数。
下面具体来介绍一下。
4.1 拆分 content 字段
由于 ODPS SQL 不能一步到位将 json 数据拆开,由一行变成多行,所以需要通过另外的方式进行行向扩展,即通过lateral view视图将数据进行发散,而发散多少行呢?这个由 json 的元素的个数来决定,所以需要先计算元素的个数。
ODPS SQL 提供了regexp_count()函数,可以通过计算数组元素的个数来确定。
那么如何计算数组的元素个数呢?通过观察数据的结构特点,我通过识别元素的分割符},{作为标识,即regexp_count(content,'}\\s*,\\s*{'),具体含义如下:
\s:匹配任何空白符,避免因为出现空格而匹配不上,等价于** [\t\n\f\r ]**\\:由于系统采用反斜线\作为转义符,因此正则表达式的模式中出现的\都要进行二次转义。例如正则表达式要匹配字符串a+b。其中+是正则中的一个特殊字符,因此要用转义的方式表达,在正则引擎中的表达方式是a\\+b。由于系统还要解释一层转义,因此能够匹配该字符串的表达式是a\\\+b。简单理解就是在 SQL 中使用特殊字母转义时需要多加一层转义,即多加一个**\**。*:匹配前面的子表达式0次或多次。
下面来看看处理效果
参考 SQL:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,content
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
from t1
)
select *
from t1_json t1;
输出结果:
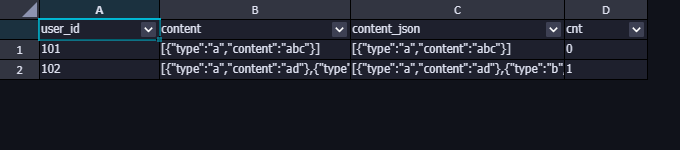
接下来就是将返回的结果根据cnt字段进行发散,这里有一个临界点问题,就是当cnt=0时,表示只有一个元素,当cnt=1则是两个,依次类推。数组的索引是从 0 开始的,所以通过lateral view创建的视图,在发散时,需要注意起点和临界值的处理。发散之后,通过发散的序号来进行索引,取出每一个元素的值。
下面直接看下 SQL 来讲解:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,content
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
from t1
)
select t1.user_id
,t1.content_json
,t1.cnt
,index_tbl.index_no
,json_extract(t1.content_json, concat('$[',index_tbl.index_no,']')) as "content"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
;
上面 SQL 通过lateral view发散,将一行扩展到四行,数据增大了4倍,然后再通过限制index_tbl.index_no<=t1.cnt取出符合期望的行,可以看看下面这张图,返回的结果是没有加上最后where条件的结果,从图中可以看出,101 用户发散的四条记录中,只有一条是有用的,其他三条返回的content都是空值,这些空值的行可以过滤掉,这就是where的作用。
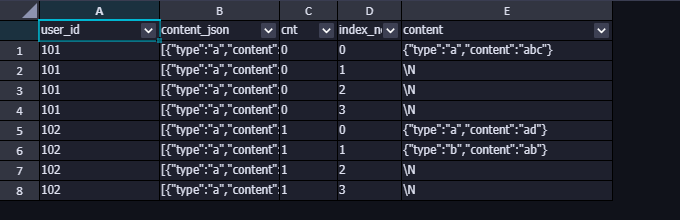
至此,仅完成了前面json_array_elements()的处理结果,而我们的目标是要将处理结果中的键值对的type对应的值和content对应的值取出来,然后使用对应的键来命名,接下来就把值取出。
取值使用的函数也是一样的,使用json_extract()来取,所以直接在上面的 SQL 中的json_extract()加上键即可,具体 SQL 如下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,content
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
from t1
)
select t1.user_id
,t1.content_json
,json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].type')) as "type"
,json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].content')) as "content"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
;
返回结果如下:
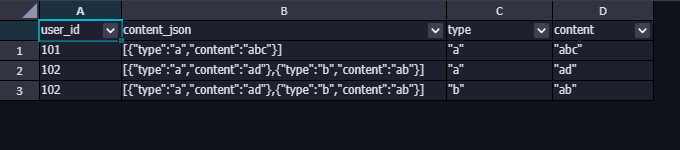
从返回的结果可以看到,type和content都是带引号的,这是因为json_extract()函数返回的数据类型是 JSON 类型,而不是字符串,所以还需要进行一步数据类型的显性转换。
最终的 SQL 如下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,content
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
from t1
)
select t1.user_id
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].type')) as string) as "type"
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].content')) as string) as "content"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
;
4.2 拆分 level 字段
拆分level字段的时候,可以用类似拆分content字段的方法,对level字段计算元素的个数,然后使用lateral view视图进行发散,再取非空的行。
由于level字段的元素个数和content字段的元素个数是一致的,所以,可以使用前面已经统计好的cnt字段,因为这二者都是通过这种方法进行发散,最终是可以进行合并处理的,为了不混淆,统一使用cnt字段。
SQL 如下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
from t1
)
select *
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
接下来,有一个难点,就是怎么知道level的键是什么?前面content拆分完,键都是一致的,但是这里的键是可变长的,可能是 1 个,或 2 个,或 3 个,或十几个等,所以这里不能一个个逻列,需要使用其他的方法“智能”取键。
通过阅读官方文档(参考:ODPS SQL 的 json 等复杂函数),发现了可以通过转为map数据类型进行处理,先通过str_to_map()转为map类型,然后使用map_keys()取键,前面是通过键取值,但是在map类型中,还提供了map_values()函数,也就是说,可以直接取值,不通过键,一步到位!
下面来实现一下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
from t1
)
select t1.user_id
,t1.level
,str_to_map(regexp_extract(t1.level,'{(.*?)}'),',',':') as level_map
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
注意:以上对t1.level进行了一层处理:regexp_extract(t1.level,'{(.*?)}'),目的是将外层的花括号去掉,使用str_to_map()不需要花括号,有键值对的结构即可。str_to_map(<col_nmae>,',',':')再根据逗号进行切割元素,通过冒号处理为键值对。其实处理前后的“长相”是一样!
以上 SQL 的返回结果如下,虽然看上去一样,但是数据类型是不一样的,level是 string 类型,level_map是 map 类型,绕了这圈子,其实就是转换下数据类型,那能不能直接转呢,至少目前从官方文档看不到这样的功能。
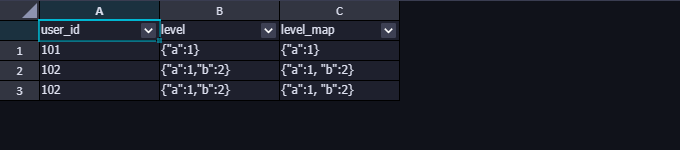
转换为 map 类型之后,再使用map_keys()和map_values()分别取出键和值的数组,然后再根据索引取出对应的值。索引取值可以使用[]或json_extract()取值。
SQL 如下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
from t1
)
select t1.user_id
,t1.level
,map_keys(str_to_map(regexp_extract(t1.level,'{(.*?)}'),',',':'))[index_tbl.index_no] as "type"
,map_values(str_to_map(regexp_extract(t1.level,'{(.*?)}'),',',':'))[index_tbl.index_no] as "level"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
运行结果如下:
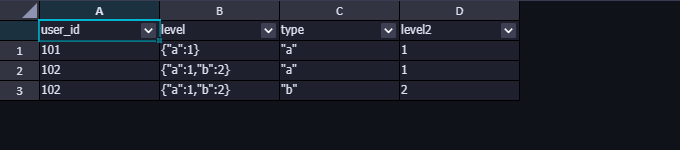
注意:这里返回的结果也需要进行数据类型转换,type转为 string 类型,而level2(有重名,被自动标记序号)转为 int 或 bigint 类型。
到这里会有另外一个小细节需要处理,就是当将type转换为 string 类型之后,可以发现type字段依旧带有双引号。这是因为字符串是"a",即带双引号的a,字符长度是 3。
怎么办呢?再做一层处理,可以在处理后将双引号去掉,也可以在一开始的时候就将双引号去掉。
下面展示一开始就去掉双引号的方法参考:
使用replace()先将·level字段的双引号去掉,最后再转换数据类型。
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
from t1
)
select t1.user_id
,t1.level
,cast(map_keys(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as string) as "type"
,cast(map_values(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as int) as "level"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
至此,完成拆分level字段。
4.3 合并拆分
接下来将上面两步拆分进行合并。直接来看看代码:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
-- ,REGEXP_COUNT(level,':') as level_cnt
from t1
)
select t1.user_id
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].type')) as string) as "type1"
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].content')) as string) as "content"
,cast(map_keys(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as string) as "type2"
,cast(map_values(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as int) as "level"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt;
返回结果如下:
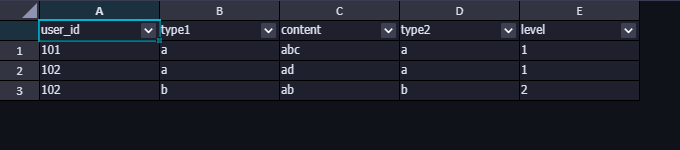
至此,是不是就大功告成了呢?
不!还不行,还有两个问题没有解决。
问题1、数组的元素是有顺序保证的,但是键值对不一定是按照数组的元素的顺序排列,有可能会出现二者错位的现象,只是刚好的举的例子没有错位。为了保证类型(type)一致,需要再加一层操作,将上述的 SQL 返回的临时表进行自联结。参考 SQL 如下:
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
-- ,REGEXP_COUNT(level,':') as level_cnt
from t1
)
,temp as(
select t1.user_id
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].type')) as string) as "type1"
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].content')) as string) as "content"
,cast(map_keys(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as string) as "type2"
,cast(map_values(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as int) as "level"
from t1_json t1
-- 一行变成四行,发散4倍
lateral view explode(array(0,1,2,3)) index_tbl as index_no
-- 限制发散的值 index_no 小于等于 t1.cnt 的行,把大于 t1.cnt 的行去掉
where index_tbl.index_no<=t1.cnt
)
select t2.user_id,t2.type1 as "type",t2.content,t3.level
from temp t2, temp t3
where t2.user_id=t3.user_id and t2.type1=t3.type2
最终结果如下:
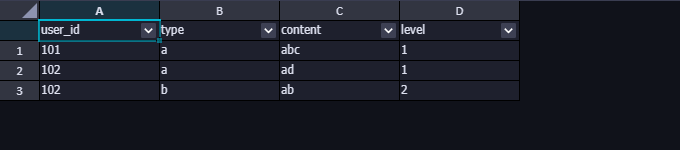
问题2、要发散多少行呢? 可能前面的时候你会觉得纳闷,为什么是array(0,1,2,3),而不是其他?使用array(0,1,2,3)是方便理解,先把数据跑通,实际上这样的处理存在很大的风险,一旦元素的个数超过了 4 个就会有数据丢失,所以如果使用该方法,可能需要把数组的元素加的足够长,以规避该风险。但是将元素加得足够大之后,原有的行记录都放大对应的倍数,会极大消耗资源,是否有更好的方法呢?
带着这个问题求助下 GPT,得到了一个反馈,可以通过sequence(start, stop)函数来动态生成数组,将start设置为 0,而·stop设置为元素的个数cnt便可实现动态发散。参考 SQL 如下:
参考:阿里云 sequence 函数文档
with t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select user_id
,level
,json_parse(content) as content_json
,regexp_count(content,'}\\s*,\\s*{') as cnt
,json_parse(level) as level_json
-- ,REGEXP_COUNT(level,':') as level_cnt
from t1
)
,temp as(
select t1.user_id
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].type')) as string) as "type1"
,cast(json_extract(t1.content_json, concat('$[',index_tbl.index_no,'].content')) as string) as "content"
,cast(map_keys(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as string) as "type2"
,cast(map_values(str_to_map(regexp_extract(replace(t1.level,'"',''),'{(.*?)}'),',',':'))[index_tbl.index_no] as int) as "level"
from t1_json t1
-- 使用 sequence() 动态发散
lateral view explode(sequence(0, t1.cnt)) index_tbl as index_no
)
select t2.user_id,t2.type1 as "type",t2.content,t3.level
from temp t2, temp t3
where t2.user_id=t3.user_id and t2.type1=t3.type2
至此,大功告成!
五、使用 MySQL 实现
本来到这里就结束了,突然心血来潮,试试 MySQL 是否有方便的处理方法。
参考:MySQL8 官方 json 函数介绍
实践之后发现,并没有!流程和 ODPS SQL 实现过程差不多,不过函数有好些差异。下面提供一份 SQL 参考:
with
-- 递归创建数字序列
RECURSIVE index_tbl AS (
SELECT 0 AS index_no
UNION ALL
SELECT index_no + 1 FROM index_tbl WHERE index_no < 10
)
,t1 as(
select 101 as user_id,'[{"type":"a","content":"abc"}]' as "content",'{"a":1}' as "level" union all
select 102 as user_id,'[{"type":"a","content":"ad"},{"type":"b","content":"ab"}]','{"a":1,"b":2}'
)
,t1_json as(
select
user_id
,cast(content as json) "content_json"
,cast(level AS json) "level_json"
,json_length(cast(content as json)) "cnt"
from t1
)
,temp as(
select
t1.user_id
,json_unquote(json_extract(content_json, concat('$[',index_tbl.index_no,'].type'))) as "type1"
,json_unquote(json_extract(content_json, concat('$[',index_tbl.index_no,'].content'))) as "content"
,json_unquote(json_extract(json_keys(level_json) , concat('$[',index_tbl.index_no,']'))) as "type2"
,json_unquote(json_extract(level_json, concat('$.',json_unquote(json_extract(json_keys(level_json) , concat('$[',index_tbl.index_no,']')))))) as "level"
from t1_json t1
-- 发散
join index_tbl on index_tbl.index_no<cnt
)
select t2.user_id,t2.type1 as "type",t2.content,t3.level
from temp t2, temp t3
where t2.user_id=t3.user_id and t2.type1=t3.type2
;
MySQL 没有像 ODPS SQL 的lateral view和explode()函数,所以不能直接展开,MySQL 通过RECURSIVE实现递归创建一个数字序列,然后直接和元素个数的字段进行join并设置好边界值实现相同的效果。
使用RECURSIVE创建数字序列表时,可以把index_no的上限设置稍微大一些,后续关联直接动态限制发散的行数,而不是直接放大倍数,数据不会全部暴涨到index_no上限值的倍数,和lateral view直接发散关联有一定区别。
MySQL 有json_length()函数,可以直接计算元素个数,相对 ODPS SQL 比较便利;也支持json_keys()直接取键,这个和 pgsql 类似,只不过 pgsql 直接进行了发散,将键拆分为一行一个,而 MySQL 还需要结合index_tbl数字序列表手动发散;另外,MySQL 还提供了一个json_unquote()函数,可以直接将json_extract()返回的 json 类型转为 字符串。
六、总结
本文分别通过 pgsql、ODPS SQL 和 MySQL 三种 SQL 语法进行 json 类型的处理。其中,使用 pgsql 处理方式最简单且简洁,而 ODPS SQL 最复杂,中间进行了多次数据类型的变更,甚至还需要使用一种更少见的数据类型 map 类型来辅助处理;而 MySQL 则处于二者之间。
下面通过一张表格对比下三者实现同样功能需要使用到的函数:
| Postgres SQL | ODPS SQL | MySQL |
|---|---|---|
| ::json | json_parse() | cast() 或隐式转换 |
| json_array_elements() | regexp_count()、lateral view explode()、sequence()、json_extract()、cast() | RECURSIVE、json_extract()、json_unquote() |
| json_object_keys() | str_to_map()、map_values()、regexp_extract()、replace()、regexp_count()、lateral view explode()、sequence()、json_extract()、cast() | RECURSIVE、json_extract()、json_unquote()、json_keys() |
| -> | [] 或 json_extract() | json_extract() |
| ->> | json_extract() | json_extract() |
往期回顾:
阿里云大数据实战记录7:如何处理生产环境表单的重复数据
阿里云大数据实战记录6:修改生产环境表单字段数据类型
阿里云大数据实战记录5:修改生产环境表单字段名称