目录
下在两阶段提交的不同时刻,MySQL异常重启会出现什么现象。
那么, MySQL怎么知道binlog是完整的?
redo log 和 binlog是怎么关联起来的?
处于prepare阶段的redo log加上完整binlog,重启就能恢复,MySQL为什么要这么设计?
如果这样的话,为什么还要两阶段提交呢?⼲脆先redo log写完,再写binlog。崩溃恢复的时候,必须 得两个⽇志都完整才可以。是不是⼀样的逻辑?
不引⼊两个⽇志,也就没有两阶段提交的必要了。只⽤binlog来⽀持崩溃恢复,⼜能⽀持归档,不就可以了?
能不能反过来,只⽤redo log,不要binlog?
redo log一般设置多大?
正常运⾏中的实例,数据写⼊后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
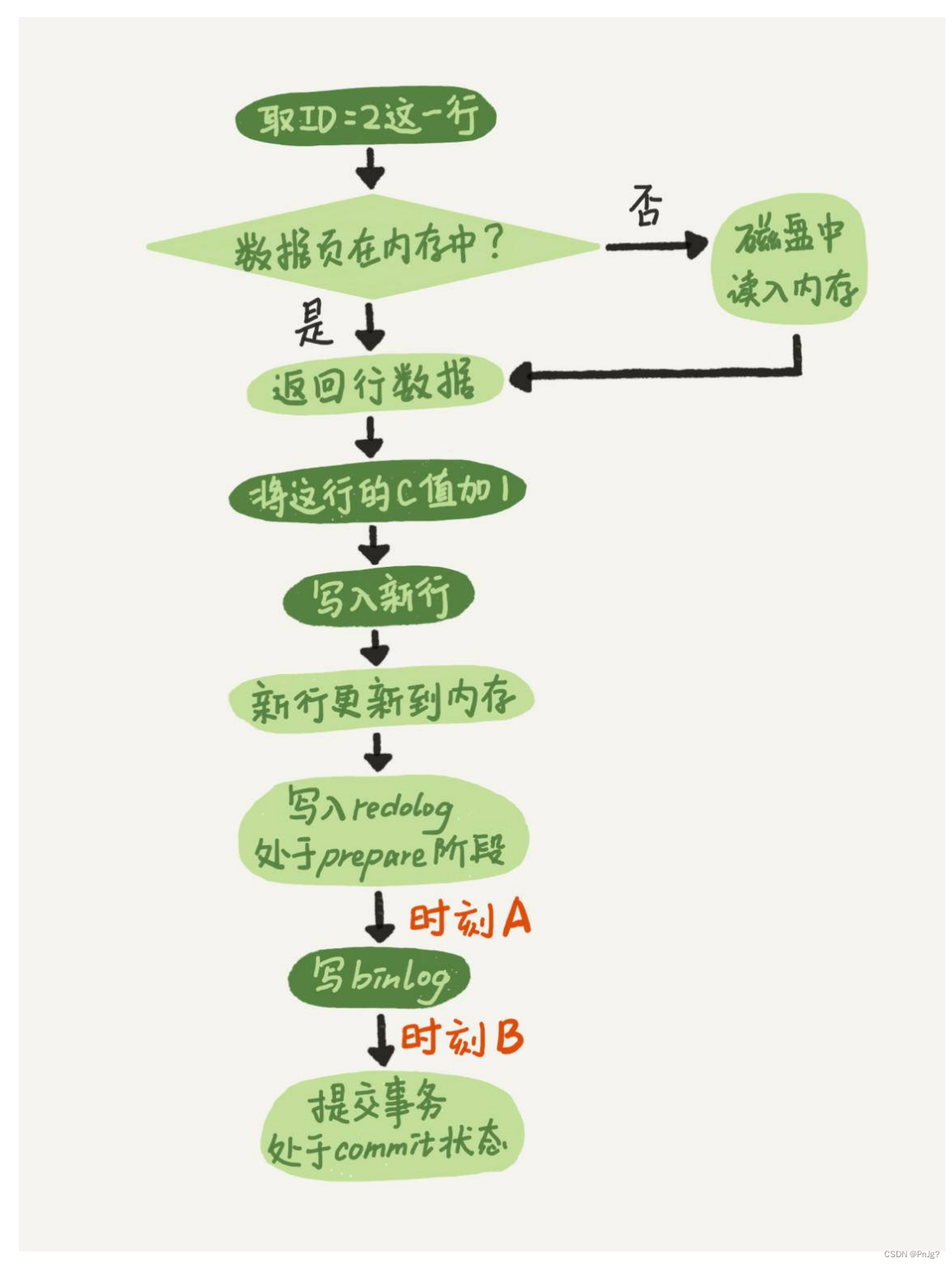
下在两阶段提交的不同时刻,MySQL异常重启会出现什么现象。
如果在图中时刻A的地⽅,也就是写⼊redo log 处于prepare阶段之后、写binlog之前,发⽣了崩溃(crash),由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库。
对于时刻B,也就是binlog写完,redo log还没commit前发⽣crash,那崩溃恢复的时候MySQL会 怎么处理? 我们先来看⼀下崩溃恢复时的判断规则。:
1. 如果redo log⾥⾯的事务是完整的,也就是已经有了commit标识,则直接提交;
2. 如果redo log⾥⾯的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
这⾥,时刻B发⽣crash对应的就是2(a)的情况,崩溃恢复过程中事务会被提交。
那么, MySQL怎么知道binlog是完整的?
⼀个事务的binlog是有完整格式的:
statement格式的binlog,最后会有COMMIT;
row格式的binlog,最后会有⼀个XID event。
另外,在MySQL 5.6.2版本以后,还引⼊了binlog-checksum参数,⽤来验证binlog内容的正确性。对于binlog⽇志由于磁盘原因,可能会在⽇志中间出错的情况,MySQL可以通过校验checksum的结果来发现。所以,MySQL还是有办法验证事务binlog 的完整性的。
redo log 和 binlog是怎么关联起来的?
它们有⼀个共同的数据字段,叫XID。崩溃恢复的时候,会按顺序扫描redo log:
- 如果碰到既有prepare、⼜有commit的redo log,就直接提交
- 如果碰到只有parepare、⽽没有commit的redo log,就拿着XID去binlog找对应的事务。
处于prepare阶段的redo log加上完整binlog,重启就能恢复,MySQL为什么要这么设计?
其实,这个问题还是跟我们在反证法中说到的数据与备份的⼀致性有关。在时刻B,也就是binlog写完以后MySQL发生崩溃,这时候binlog已经写⼊了,之后就会被从库(或者⽤这个binlog恢复出来的库)使⽤。
所以,在主库上也要提交这个事务。采⽤这个策略,主库和备库的数据就保证了⼀致性。
如果这样的话,为什么还要两阶段提交呢?⼲脆先redo log写完,再写binlog。崩溃恢复的时候,必须 得两个⽇志都完整才可以。是不是⼀样的逻辑?
两阶段提交是经典的分布式系统问题,并不是MySQL独有的。如果必须要举⼀个场景,来说明这么做的必要性的话,那就是事务的持久性问题。
对于InnoDB引擎来说,如果redo log提交完成了,事务就不能回滚(如果这还允许回滚,就可能覆盖掉别的事务的更新)。⽽如果redo log直接提交,然后binlog写⼊的时候失败,InnoDB⼜回滚不了,数据和binlog⽇志⼜不⼀致了。两阶段提交就是为了给所有⼈⼀个机会,当每个⼈都说“我ok”的时候,再⼀起提交。
不引⼊两个⽇志,也就没有两阶段提交的必要了。只⽤binlog来⽀持崩溃恢复,⼜能⽀持归档,不就可以了?
这个问题的意思是,只保留binlog,然后可以把提交流程改成这样:… -> “数据更新到内存” -> “写 binlog” -> “提交事务”,是不是也可以提供崩溃恢复的能⼒?
答案是不可以的。只⽤binlog来实现崩溃恢复的流程,如图所示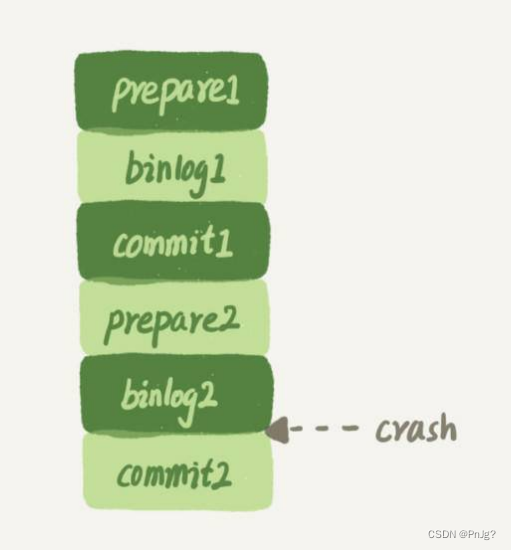
这样的流程下,binlog还是不能⽀持崩溃恢复的。:binlog没有能⼒恢复“数据⻚”
如果在图中标的位置,也就是binlog2写完了,但是整个事务还没有commit的时候,MySQL发⽣了crash。
重启后,引擎内部事务2会回滚,然后应⽤binlog2可以补回来;但是对于事务1来说,系统已经认为提交完成了,不会再应⽤⼀次binlog1。
但是,InnoDB引擎使⽤的是WAL技术,执⾏事务的时候,写完内存和⽇志,事务就算完成了。如果之后崩溃,要依赖于⽇志来恢复数据⻚。 也就是说在图中这个位置发⽣崩溃的话,事务1也是可能丢失了的,⽽且是数据⻚级的丢失。此时,binlog⾥⾯并没有记录数据⻚的更新细节,是补不回来的。
能不能反过来,只⽤redo log,不要binlog?
可以把binlog关掉,这样就没有两阶段提交了,但系统依然是crash-safe的。⼀个是归档。redo log是循环写,写到末尾是要回到开头继续写的。这样历史⽇志没法保留,redo log也就起不到归档的作用。
⼀个就是MySQL系统依赖于binlog。binlog作为MySQL⼀开始就有的功能,被⽤在了很多地⽅。其中,MySQL系统⾼可⽤的基础,就是binlog复制。
redo log一般设置多大?
4个1G文件。
正常运⾏中的实例,数据写⼊后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
实际上,redo log并没有记录数据⻚的完整数据,所以它并没有能⼒⾃⼰去更新磁盘数据⻚,也就不存在“数据最终落盘,是由 redo log更新过去”的情况。
1. 如果是正常运⾏的实例的话,数据⻚被修改以后,跟磁盘的数据⻚不⼀致,称为脏⻚。最终数据落盘,就是把内存中的数据⻚写盘。这个过程,甚⾄与redo log毫⽆关系。
2. 在崩溃恢复场景中,InnoDB如果判断到⼀个数据⻚可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存⻚变成脏⻚,就回到了第⼀种情况的状态。