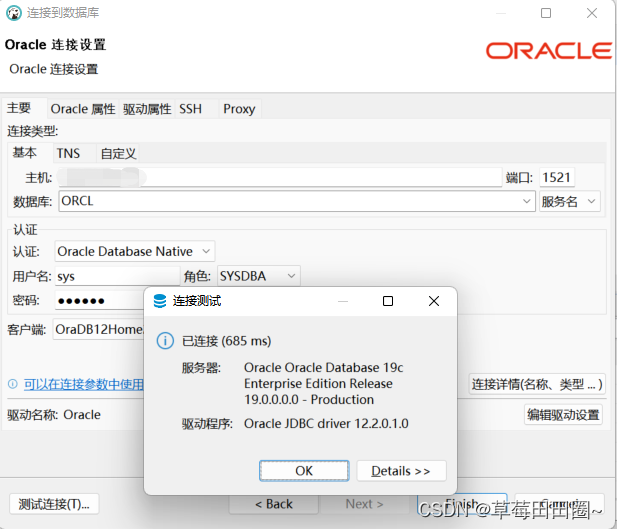
TI C2000系列的DSP芯片算力有限,用于来控制有时候常会出现控制程序无法实现实时运行的情况,因此从本文开始,将陆续推出几篇DSP算法加速的方法
此方法只需要添加一行代码和一个预定义,即可达到算法整体加速的目的。先声明本文是讲的是TMS320F28377D,其他C2000系列芯片操作类似。
1 一行代码
#pragma CODE_SECTION(testfunction,".TI.ramfunc");或者
#pragma CODE_SECTION(testfunction,"ramfunc");这行代码,我认为标准做法是放于 "声明testfunction的.h文件"中。这个testfunction就是你需要加速的算法函数。
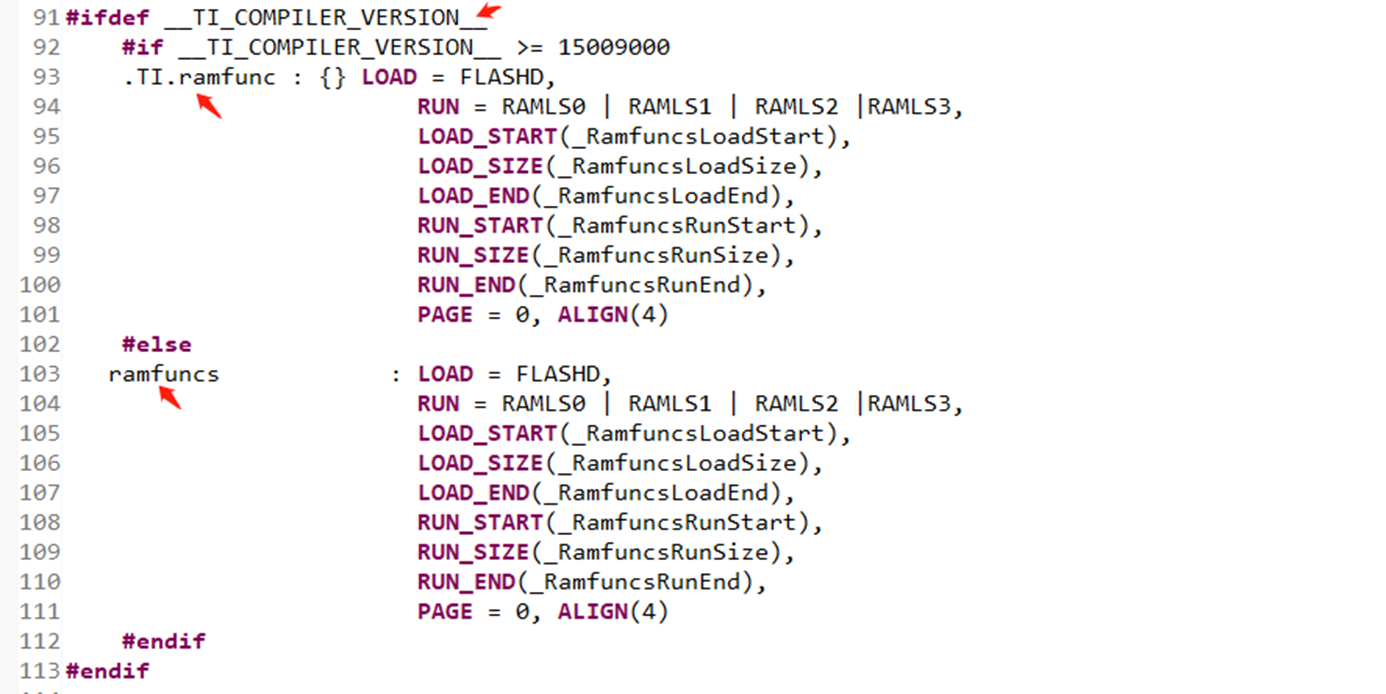
那上述有两行代码,我到底应该选择哪一行呢? 它们的区别是".TI.ramfunc"和"ramfunc",用哪个其实主要取决于你的编译器版本。 我用的是CCS 7.4.0,这两行代码我都测试过,用"ramfunc"会进入错误异常中断。而用".TI.ramfunc"则功能可正常实现。
2 一个预定义
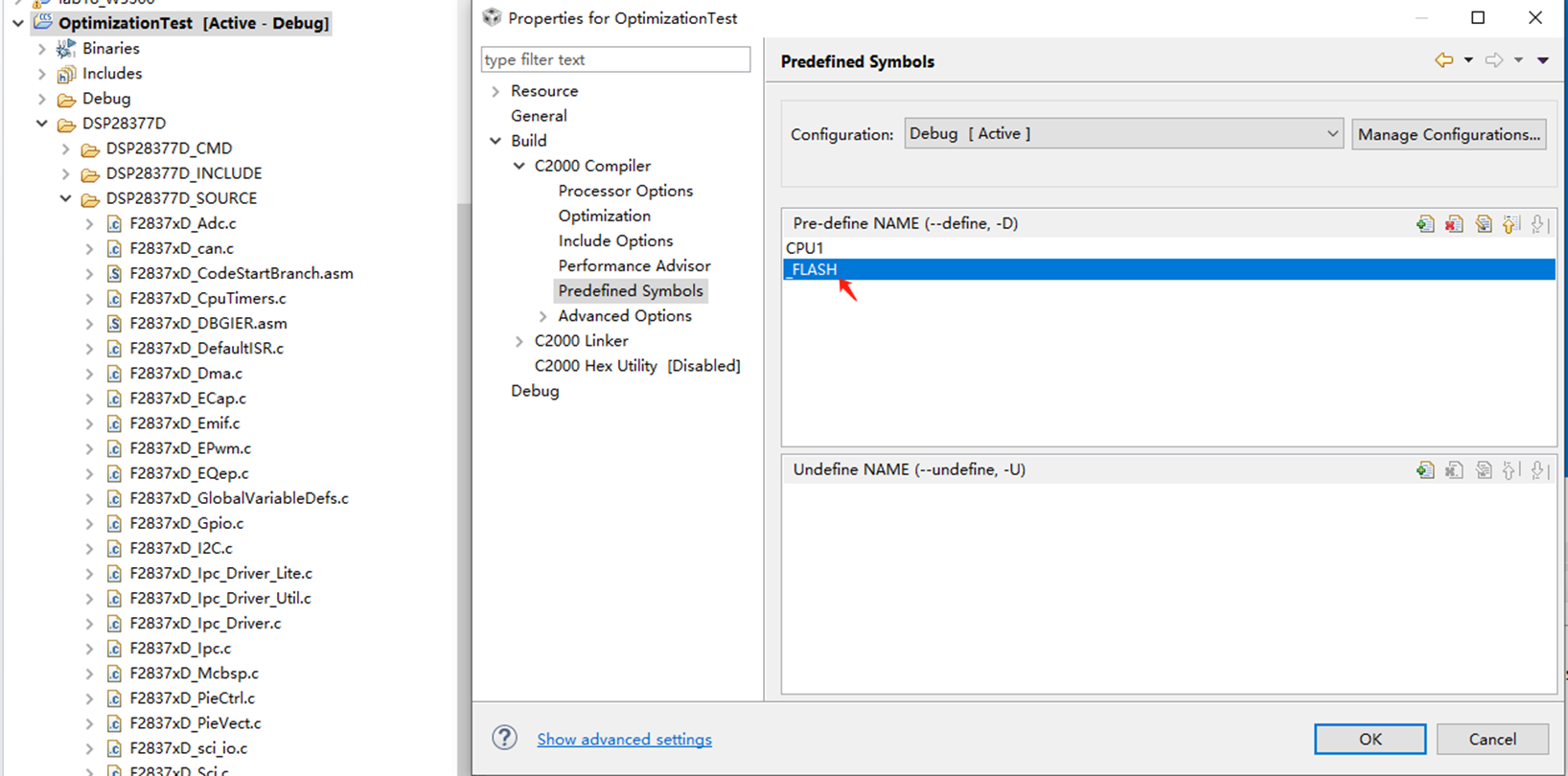
另外需要注意的一点是项目文件需要预定义 _FLASH。 在InitSysCtrl函数中,只有你预定义了_FLASH,才会执行下面这行代码。而这行代码的执行对于我们需要的功能是至关重要的。
memcpy(&RamfuncsRunStart, &RamfuncsLoadStart, (size_t)&RamfuncsLoadSize);void InitSysCtrl(void)
{
//
// Disable the watchdog
//
DisableDog();
//
// Copy time critical code and Flash setup code to RAM. This includes the
// following functions: InitFlash()
//
// The RamfuncsLoadStart, RamfuncsLoadSize, and RamfuncsRunStart
// symbols are created by the linker. Refer to the device .cmd file.
//
#ifdef _FLASH
memcpy(&RamfuncsRunStart, &RamfuncsLoadStart, (size_t)&RamfuncsLoadSize);
//
// Call Flash Initialization to setup flash waitstates. This function must
// reside in RAM.
//
InitFlash();
#endif
具体操作如下:
3 测试方法
测试方法很简单,就是对比优化前和优化后测试的功能模块的运行时间。如何获取代码块的运行时间我这里就不赘述了,我以前写过一个相关博客:DSP_TMS320F28377D_使用定时器实现<获取代码块运算时间>的功能_江湖上都叫我秋博的博客-CSDN博客。
4 普通程序测试
我28377D的程序框架还是延用
DSP_基于TMS320F28377D双核芯片和CCS7.40的编程入门_ccs双核芯片下载_江湖上都叫我秋博的博客-CSDN博客
这篇博客的风格,下面我贴出和测试相关的部分。
main.c
#include <main.h>
void main(void)
{
InitSysCtrl();
DINT;
InitPieCtrl();
InitGpio();
IER = 0x0000;
IFR = 0x0000;
InitPieVectTable();
InitCpuTimers();
runtime_init();
while(1){
runtime_start();
testfunction();
runtime_stop();
}
}
void testfunction(void){
int i = 0;
int sum = 0;
for(i = 0; i < 1000; i++){
sum = sum+i;
}
}
main.h
#include <F28x_Project.h>
#include <runtime.h>
#pragma CODE_SECTION(testfunction,".TI.ramfunc");
void testfunction(void);
测试结果
加速前 85us,加速后70us,约加速20%。
5 中断程序测试
除了上述测试以外,我还说测试了中断处理函数。我把testfunction放在中断里面执行。
main.c
#include <main.h>
void main(void)
{
InitSysCtrl();
DINT;
InitPieCtrl();
InitGpio();
IER = 0x0000;
IFR = 0x0000;
InitPieVectTable();
InitCpuTimers();
/* 定时器中断配置 */
ConfigCpuTimer(&CpuTimer0, 200, 1000000/5000);
CpuTimer0Regs.TCR.bit.TIE = 1; // 1: The CPU-Timer interrupt is enabled
// TIMER0 INT1.7 [Page102: Table 3-2.PIE Channel Mapping]
EALLOW;
PieVectTable.TIMER0_INT = &CpuTimer0ISR; // Specify the interrupt service routine
EDIS;
IER |= M_INT1; // Enable CPU Level interrupt
PieCtrlRegs.PIEIER1.bit.INTx7 = 1; // Enable PIE Level interrupt
PieCtrlRegs.PIECTRL.bit.ENPIE = 1; // Enable the PIE block
EINT; // Turn on the switch of system global interrupt
ERTM;
CpuTimer0Regs.TCR.bit.TSS = 0; // Start CPU Timer 0
runtime_init();
while(1){
}
}
interrupt void CpuTimer0ISR(void){
runtime_start();
testfunction();
runtime_stop();
PieCtrlRegs.PIEACK.all = PIEACK_GROUP1;
}
void testfunction(void){
int i = 0;
int sum = 0;
for(i = 0; i < 1000; i++){
sum = sum+i;
}
}
main.h
#include <F28x_Project.h>
#include <runtime.h>
interrupt void CpuTimer0ISR(void);
#pragma CODE_SECTION(testfunction,".TI.ramfunc");
void testfunction(void);
测试结果
加速前 90us,加速后70us。 同样的代码,放在中断里面运行还慢了点,这个有点匪夷所思,不过加速后的运算速度是一样的。
注意
这里需要提醒一下, 如果你在中断处理函数里面调用了其他的函数,比如CpuTimer0ISR调用testfunction。
#pragma CODE_SECTION(CpuTimer0ISR,".TI.ramfunc");这样写是无法加速的。
要想实现对中断程序整体的加速,你有三种选择
1 你还是加速testfunction
#pragma CODE_SECTION(testfunction,".TI.ramfunc");2 你把testfunction函数实现的内容直接写到CpuTimer0ISR里面
#pragma CODE_SECTION(CpuTimer0ISR,".TI.ramfunc");
interrupt void CpuTimer0ISR(void){
runtime_start();
// testfunction();
int i = 0;
int sum = 0;
for(i = 0; i < 1000; i++){
sum = sum+i;
}
runtime_stop();
PieCtrlRegs.PIEACK.all = PIEACK_GROUP1;
}
3 你把两个函数都搬到RAM里面运行,即
#pragma CODE_SECTION(CpuTimer0ISR,".TI.ramfunc");
#pragma CODE_SECTION(testfunction,".TI.ramfunc");
后续会再推出几篇DSP算法加速的方法与大家探讨。感谢您的阅读,如果您有什么优化方法,欢迎留言分享、收藏、点赞。