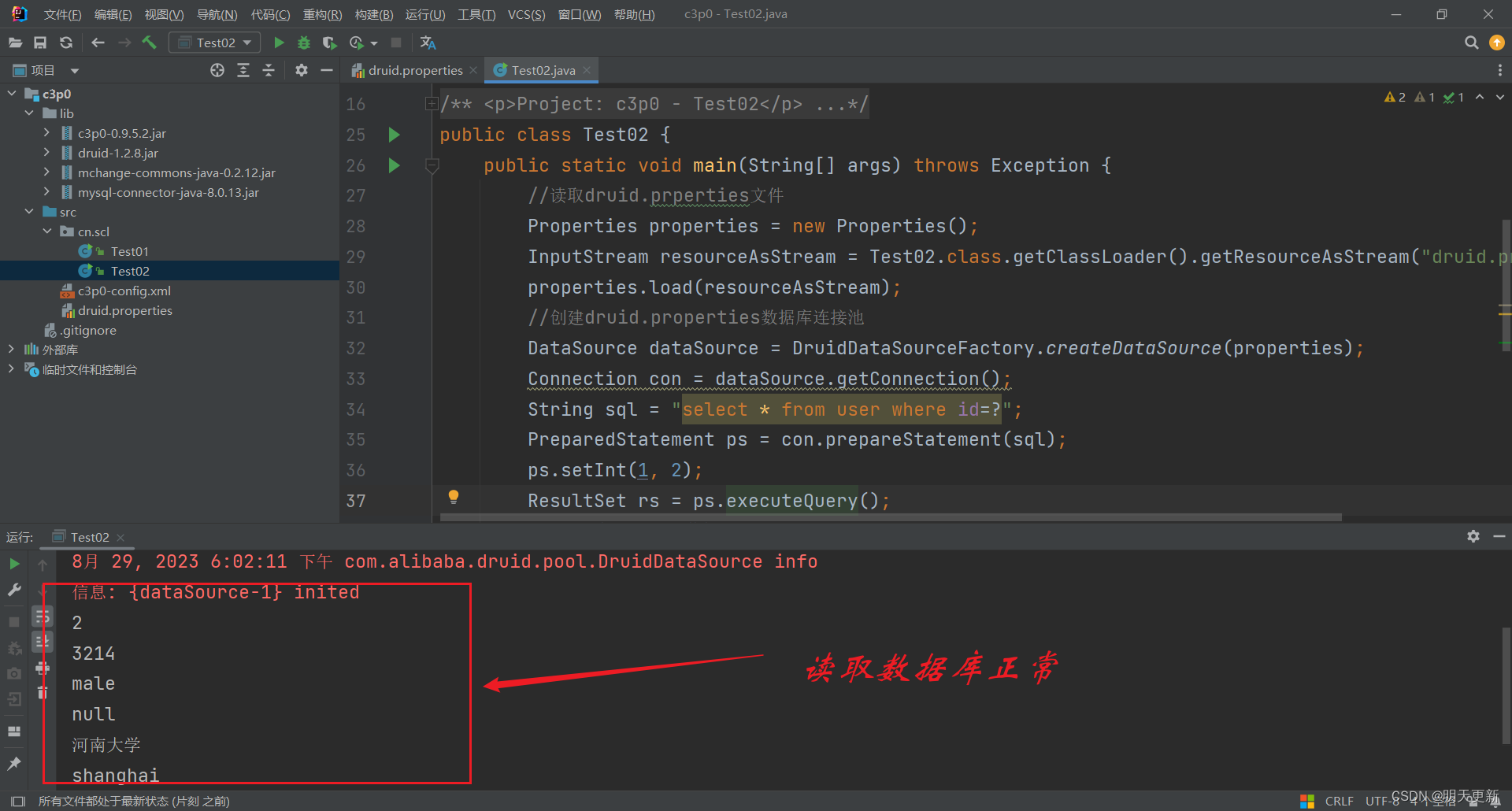
基于学习方法,机器学习大致可分为监督学习和无监督学习两种。在无监督学习中,我们需要用某种算法去训练无标签数据集,从而帮助模型找到这组数据的潜在结构。
为了进行无监督学习,在OpenAI成立早期,他们认为通过压缩可以通向这一路径。随后,他们发现“预测下一个词元(token)”正是无监督学习可以追求的目标,并且意识到,预测就是压缩。这也正是后来ChatGPT成功的关键思想之一。
他们通过不断训练自回归生成模型实现了数据压缩,如果数据被压缩得足够好,就能提取其中存在的所有隐藏信息。这样GPT模型就可以准确地预测下一个词元,文本生成的准确度也就越高。
近期,OpenAI联合创始人和首席科学家Ilya Sutskever在UC伯克利的一场演讲中提出,希望通过压缩视角来解释无监督学习问题。不过值得一提的是,他指出,GPT模型也可以不通过压缩理念进行理解。
(以下内容由OneFlow编译发布,转载请联系授权。https://simons.berkeley.edu/talks/ilya-sutskever-openai-2023-08-14)
来源 | Simons Institute
OneFlow编译
翻译|宛子琳、杨婷
1
无监督学习理论
通过压缩来解决
众所周知,我们可以将压缩看做是一种预测过程,每个压缩器都可以转化为一个预测器,反之亦然。所有压缩器和预测器之间都存在一一对应的关系。为说明对无监督学习的思考,我认为,使用压缩进行论述更具优势。
无监督学习能否形式化?
那么我们该如何将无监督学习形式化呢?在接下来的内容中,我会交替使用压缩和预测场景进行描述。假设你有一个机器学习算法 A,它试图对 Y 进行压缩,如果算法 A 可以访问 X,其中 X 文件编号为 1,Y 文件编号为 2,你希望机器学习算法(即压缩器)能够压缩 Y,并且这可以通过使用 X 来实现。那么使用这个特定算法会带来什么样的遗憾(regret)?
如果任务完成得足够好,遗憾程度较低,则意味着我已经从未标记数据中获得了所有可能的帮助,对此我毫无遗憾,数据中已经没有其他预测价值可供更好的算法利用,我已经从未标记数据中获得了最大收益,已经做到了极致。

我认为,这是思考无监督学习的重要步骤。你不知道自己的无监督数据集是否真正有用,它可能用处很大,包含了答案,也可能毫无用处,还可能是均匀分布的数据集。但是,如果你在监督学习算法上的遗憾较小,就可以判断出自己的无监督数据集是第一种还是第二种情况。我确信我已经尽了最大努力,从未标记数据中取得了最大收益,没人能比我做得更好。
2
Kolmogorov 复杂度作为终极压缩器
接下来讲一讲 Kolmogorov 复杂度(Kolmogorov complexity),它被称为终极压缩器,可以提供终超低遗憾算法。实际上,Kolmogorov 复杂度并不是一个可计算的算法。很多人也许都不了解,其实它很简单。

假设给我一些数据,我将提供可能存在的最短程序对其进行压缩,如果运行这个最短程序,它会输出数据。这个输出Y的最短程序长度就等于 Kolmogorov 复杂度K(X) 。直观来说,可以看出这个压缩器非常有效,因为这个定理很容易就能证明。如果用 Kolmogorov 压缩器来压缩字符串,压缩质量的遗憾会很小。如果你要压缩字符串 X,那么输出 X 的最短程序的长度要比压缩器所需的输出长度更短,而且不论压缩器如何压缩数据,都可以得到一个很小的项,这个小项是实现压缩器所需的代码字符数量。

“计算”K(X)
现在让我们将 Kolmogorov 复杂度进行泛化,使其能够调用其他信息。再次重申,Kolmogorov 压缩器是不可计算、不可判定的,这一点非常重要,但它会搜索所有程序。就像你对一些百层的神经网络参数上做随机梯度下降(SGD),它自动地就像在一台拥有一定内存大小和步数的计算机上做程序搜索,这在某种程度上有点类似于微型 Kolmogorov 压缩器,二者之间具有非常微妙的相似性。

神经网络可以模拟小程序,它们就像小型计算机,由电路构成,电路是计算机的基本组成部分,而计算机本质上就是一台机器。随机梯度下降(SGD)在程序上进行搜索,整个深度学习都围绕 SGD 展开,实际上我们可以用 SGD 来训练这些计算机,从数据中找到电路。因此,我们可以计算出我们的微型 Kolmogorov 压缩器,模拟论证在这里同样适用。
条件 Kolmogorov 复杂度作为解决方案
条件 Kolmogorov 复杂度可以作为监督学习的解决方案。

如图所示,这就是无监督学习的超低遗憾解决方案,尽管它不可计算,但我认为,这是一个有用的框架。这里的条件是一个数据集,而非示例。这里我们是基于数据集而不是单个样本进行条件设置,这个方法将从 X 中提取所有预测 Y 的值(value)。

“压缩一切”的可行性
条件 Kolmogorov 复杂度,其中涉及压缩算法,压缩器会尝试在接触一个数据时对另一个数据进行压缩,在机器学习语境下,尤其处理大数据集时,这种情况并不自然。
上面的式子表明,如果你对监督任务 Y 进行预测,那么使用旧式(old-fashioned) Kolmogorov 压缩器对 X 和 Y 的连接数据进行压缩,与使用条件(conditional ) Kolmogorov 压缩器的效果一样好。这里我只做简单介绍,其中的细节还有更多微妙之处。这基本上证明了我们之前所讲的内容,即可以通过条件 Kolmogorov 压缩器解决监督学习问题。
也就是说,我们也可以使用常规(regular) Kolmogorov 压缩器,使用时只需将所有数据收集起来,然后将所有文件连接在一起进行压缩,就能很好地预测我们关心的监督任务。

总之,对于无监督学习的解决方案,就是将所有数据输入到 Kolmogorov 压缩器中进行 Kolmogorov 复杂度计算。
3
如果没有过度拟合,那么联合压缩就是最大似然

最后我想说的是:如果没有过拟合,那么联合压缩就是最大似然估计。如果有一个数据集,那么给定参数的似然之和就是对数据集进行压缩的成本,此外,你还需支付压缩参数的成本。但如果你现在想要压缩两个数据集,那么只需在总和中添加更多的数据集。
在机器学习的语境下,这种通过连接数据进行联合压缩的方式非常自然。这也是我们花时间来说明条件 Kolmogorov 复杂度的原因,尽管我还不能为以上这些论证提供强有力的支撑,但我们通过压缩所有 Kolmogorov 复杂度仍然是有效的。
大型神经网络上的随机梯度下降(SGD)相当于大型程序搜索,神经网络越大,就越能更好地接近 Kolmogorov 压缩器,这或许就是我们喜欢大型神经网络的原因之一, 因为我们能够以此近似不可实现的无遗憾常规 Kolmogorov 压缩器思想,希望随着训练的神经网络越来越大,遗憾度越来越低。
4
是否适用于GPT模型的压缩?
5
线性表征
我喜欢压缩理论,长期以来我一直受困于无监督学习无法进行严格思考这个问题,但现在我们可以在一定程度上做到这一点了。目前压缩理论并不能解释为什么表征是线性可分的,也无法解释为什么需要线性探头。线性表征无时不在,其形成的原因必定十分深刻,未来也许我们能够清晰地阐明这一点。
我还观察到一个有趣现象:自动发布下一个像素预测模型(或自回归模型)在线性表征方面的表现要优于 BERT。目前我还无法确定其中的原因,如果我们能够理解线性表征的成因可能会有所帮助。
我认为,下一个像素预测任务需要从之前所有的像素中进行预测,因此需要考虑到长程结构(long range structure)。而在 BERT 中,你有自己的向量表示,假设在这种情况下你丢弃了 25% 的词元或像素,那么你的任何预测实际上都可以通过略微查看过去和未来的情况很好地补全。相比之下,下一个像素中最难的预测任务比 BERT 中最难的预测任务要困难得多,目前这还只是一种猜测,但我们可以通过实验来对其进行验证。
6
答听众问
问:是否存在更加鲁棒(robust)的二维版本的下一个像素预测模型?
答:任何将神经网络转变为将概率分配给不同输入的概率模型,都可以被看作是更加鲁棒的二维版本的下一个像素预测模型。扩散模型 (diffusion models)是另一种常见的下一个词元预测模型。在高质量图像生成中使用的扩散模型并没有真正最大化其输入步骤的似然,它们有着不同的目标。然而,最初的公式确实是最大化似然。
需要注意的是,扩散模型与下一个词元预测模型是互斥的。我认为,出于与BERT模型相同的原因,扩散模型的表征比下一个词元预测模型的表征更差,这进一步增加了线性表征形成原因的神秘感。
问:Transformer SGD 是否可以看做是最好的压缩器程序?
Ilya Sutskever:没错,还有另一种假设。假设有一个神经网络(不一定是Transformer),这些神经网络可以为数据分配对数概率,在有大量训练样本的情况下,我们可以运行该神经网络,并计算每个样本的对数概率,然后对这些概率进行求和,得到神经网络分配给整个数据集的对数概率。然而,这种特定形式的神经网络无法明确地注意到数据顺序中的时间或其他结构。尽管如此,我仍然认为可以计算整个数据集的对数概率,从而得到负对数概率,实际上是使用此神经网络作为压缩器压缩该数据集所需的位数。
问:你提到了将压缩作为理解和推动无监督学习的框架。同时,你在最后提到,如果将这个框架应用于语言模型的下一个词预测,可能会有些表面,因为任何文本任务都可以转换为下一个词预测任务。因此,对于文本任务来说,无监督学习在表面上与监督学习有些相似。然而,图像 GPT 无法像预测下一个像素那样明确定义文本任务,但我们可以利用线性表征,展示压缩可以形成良好的无监督学习。不过,高度有效的压缩器可能无法提供有用的线性表征。因此,我想知道是否存在无监督学习和监督学习表面上并不相同,但无需压缩器提供有效的线性表征以证明压缩是一个良好的无监督学习目标的情况。
答:好的线性表征只是一个额外的好处,这并不意味着线性表征应该出现,但这一理论确实主张应该有良好的微调。因为联合压缩就像是使用糟糕的搜索算法(SGD)进行近似查找。早期实验表明,在图像上运行时,BERT 所学习的线性表征比下一个像素预测要差,扩散模型可能也是如此。因此,对比微调扩散模型的结果非常有趣,或许已经有人进行了研究。