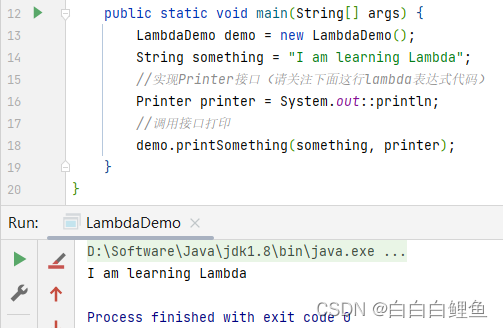
Background
- 全参微调
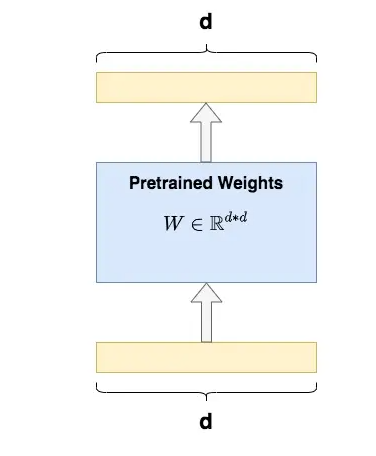
全量微调指的是,在下游任务的训练中,对预训练模型的每一个参数都做更新。例如图中,给出了Transformer的Q/K/V矩阵的全量微调示例,对每个矩阵来说,在微调时,其d*d个参数,都必须参与更新。
- 全量微调的显著缺点是,训练代价昂贵。例如GPT3的参数量有175B,我等单卡贵族只能望而却步,更不要提在微调中发现有bug时的覆水难收。同时,由于模型在预训练阶段已经吃了足够多的数据,收获了足够的经验。
- 因此我只要想办法给模型增加一个额外知识模块,让这个小模块去适配我的下游任务,模型主体保持不变(freeze)即可。
- 局部微调办法
Adapter Tuning:
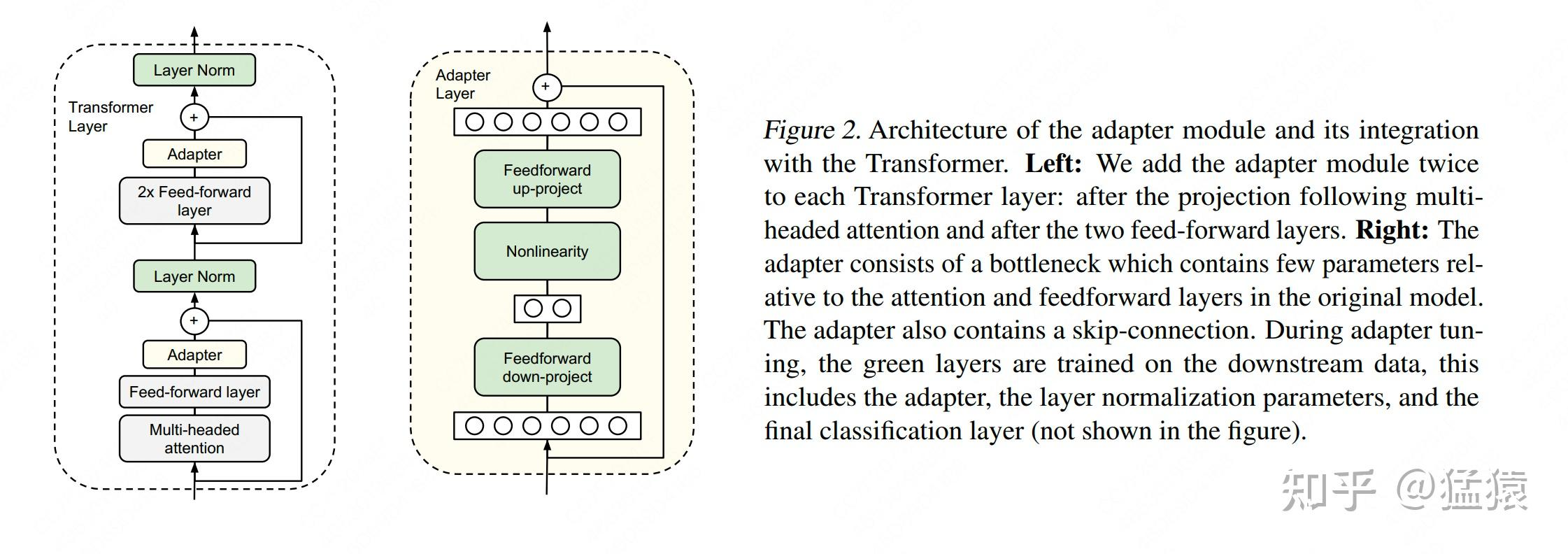
- 图例中的左边是一层Transformer Layer结构,其中的Adapter就是我们说的“额外知识模块”;右边是Adatper的具体结构。在微调时,除了Adapter的部分,其余的参数都是被冻住的(freeze),这样我们就能有效降低训练的代价。
但这样的设计架构存在一个显著劣势:添加了Adapter后,模型整体的层数变深,会增加训练速度和推理速度,原因是:
- 需要耗费额外的运算量在Adapter上
- 当我们采用并行训练时(例如Transformer架构常用的张量模型并行),Adapter层会产生额外的通讯量,增加通讯时间
Prefix Tuning

通过对输入数据增加前缀(prefix)来做微调。当然,prefix也可以不止加载输入层,还可以加在Transformer Layer输出的中间层。
对于GPT这样的生成式模型,在输入序列的最前面加入prefix token,图例中加入2个prefix token,在实际应用中,prefix token的个数是个超参,可以根据模型实际微调效果进行调整。
对于BART这样的Encoder-Decoder架构模型,则在x和y的前面同时添加prefix token。在后续微调中,我们只需要冻住模型其余部分,单独训练prefix token相关的参数即可,每个下游任务都可以单独训练一套prefix token。
- 那么prefix的含义是什么呢?
prefix的作用是引导模型提取x相关的信息,进而更好地生成y。
例如,我们要做一个summarization的任务,那么经过微调后,prefix就能领悟到当前要做的是个“总结形式”的任务,然后引导模型去x中提炼关键信息;
如果我们要做一个情感分类的任务,prefix就能引导模型去提炼出x中和情感相关的语义信息,以此类推。这样的解释可能不那么严谨,但大家可以大致体会一下prefix的作用。
Prefix Tuning虽然看起来方便,但也存在以下两个显著劣势;
较难训练,且模型的效果并不严格随prefix参数量的增加而上升,这点在原始论文中也有指出会使得输入层有效信息长度减少。为了节省计算量和显存,我们一般会固定输入数据长度。增加了prefix之后,留给原始文字数据的空间就少了,因此可能会降低原始文字中prompt的表达能力。
LoRA
全参数微调太贵,Adapter Tuning存在训练和推理延迟,Prefix Tuning难训且会减少原始训练数据中的有效文字长度,那是否有一种微调办法,能改善这些不足呢?
- 在这样动机的驱动下,作者提出了LoRA(Low-Rank Adaptation,低秩适配器)这样一种微调方法。
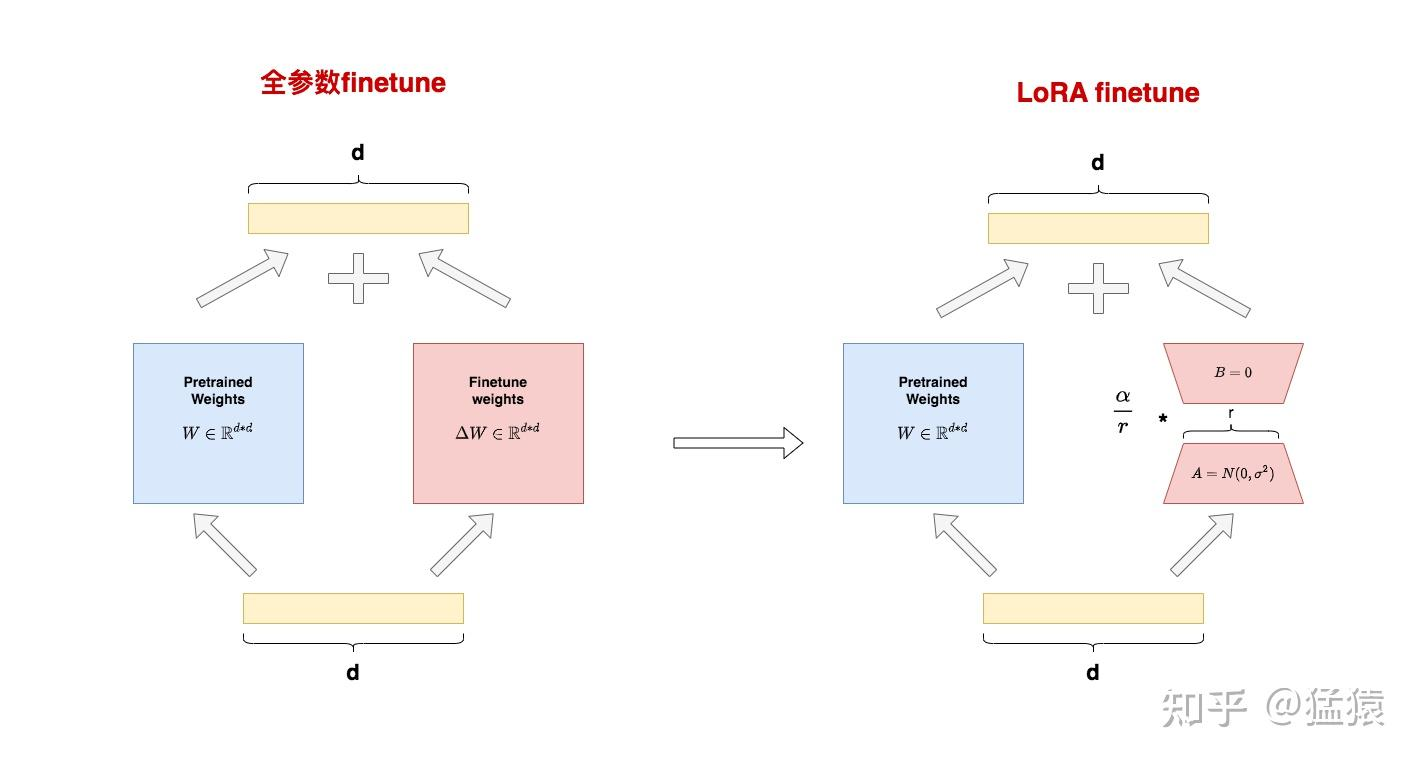

核心思想 - SVD


- 小小的总结一下:W矩阵SVD分解(近似1),然后取三个分解矩阵的top r行(近似2)= W最重要的特征
SVD Code
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
- 输出的结果不变,参数量减小很多
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40
很有意思的自相矛盾

超参数 α \alpha α

实验验证:
尽管理论上我们可以在模型的任意一层嵌入低秩适配器(比如Embedding, Attention,MLP等),但LoRA中只选咋在Attention层嵌入,并做了相关实验

LoRA使用
下游任务的example
LoRA源码
class LoRALayer():
def __init__(
self,
r: int, # 矩阵的秩
lora_alpha: int, # 超参数a
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
Embedding层
class Embedding(nn.Embedding, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
r: int = 0,
lora_alpha: int = 1,
merge_weights: bool = True,
**kwargs
):
nn.Embedding.__init__(self, num_embeddings, embedding_dim, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=0,
merge_weights=merge_weights)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = nn.Embedding.forward(self, x)
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
Linear层实现
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
class MergedLinear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
enable_lora: List[bool] = [False],
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
assert out_features % len(enable_lora) == 0, \
'The length of enable_lora must divide out_features'
self.enable_lora = enable_lora
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0 and any(enable_lora):
self.lora_A = nn.Parameter(
self.weight.new_zeros((r * sum(enable_lora), in_features)))
self.lora_B = nn.Parameter(
self.weight.new_zeros((out_features // len(enable_lora) * sum(enable_lora), r))
) # weights for Conv1D with groups=sum(enable_lora)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
# Compute the indices
self.lora_ind = self.weight.new_zeros(
(out_features, ), dtype=torch.bool
).view(len(enable_lora), -1)
self.lora_ind[enable_lora, :] = True
self.lora_ind = self.lora_ind.view(-1)
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def zero_pad(self, x):
result = x.new_zeros((len(self.lora_ind), *x.shape[1:]))
result[self.lora_ind] = x
return result
卷积层
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
# Can Extend to other ones like this
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)