关于牛脸识别相关的项目开发实践,在我前面的一篇文章中已经有非常详细的实践记录了,感兴趣的话可以自行移步阅读即可:
《助力养殖行业数字化转型,基于深度学习模型开发构建牛脸识别系统》
在我们以往接触到的项目或者是业务场景中,大多牵涉到生物特征识别的任务基本都是人脸识别,这也是目前我们每天都会接触到的应用,比如:上下班的打卡、支付时的刷脸等等,这也是比较成熟的一项AI应用。
在前文中我们总结回归了目前为止比较经典的人脸识别相关的技术模型,这里不做赘述,简单提取下不同算法模型的优缺点,如下所示:
VGGFace
优点:
构建简单,易于理解和实现。
VGGFace模型具备较强的特征表达能力和模式识别能力,适合用于人脸识别和验证任务。
缺点:
模型参数量较大,导致计算复杂度较高,需要更多的计算资源。
该模型在训练和部署时可能遇到困难,由于模型结构庞大,需要更多的存储和内存。
FaceNet
优点:
通过三元组损失函数学习到的特征具有较好的表达能力,适合用于人脸识别和验证任务。
使用三元组损失函数能够直接优化特征向量的距离度量,使得相同人的特征更加接近,不同人的特征更加分散。
缺点:
模型相对复杂,训练过程可能较为耗时。
需要大规模的训练数据和计算资源。模型的性能高度依赖于训练数据的质量和数量。
需要注意的是,FaceNet模型中还可以应用其他技术进行改进,如加权三元组损失函数、在线硬负采样和样本挖掘等。这些改进技术可以进一步提升模型性能和鲁棒性。
DeepFace
优点:
DeepFace模型具有较强的特征表达能力和模式识别能力,适合用于人脸识别任务。
通过人脸对齐技术,可以减少人脸间的姿态和尺度差异带来的影响,提高了模型的鲁棒性和准确性。
缺点:
DeepFace模型的训练和调参可能需要大量的计算资源和时间。
由于模型结构庞大,部署和推理的复杂性可能增加。
需要注意的是,DeepFace模型在提出时在LFW(Labeled Faces in the Wild)数据集上取得了很好的性能。然而,它也面临一些限制,如对于遮挡和光照变化的敏感性。为了获得更好的性能,可以结合其他的预处理方法和技术,如数据增强、特征融合等。
ArcFace
优点:
ArcFace模型在人脸识别任务中具备较高的准确性和鲁棒性。通过引入角度余弦间隔,提高了特征的可分性。
可以通过调整ArcMargin Loss的超参数来灵活控制特征向量的边界,使得模型适应各种复杂性和类别之间的差异。
缺点:
ArcFace模型在训练过程中需要大规模和均衡的数据集,对数据质量和数量有一定的要求。
模型相对复杂,需要更多的计算资源和时间来进行训练和推理。
需要注意的是,ArcFace模型的性能还受到超参数设置的影响,如角度余弦间隔的大小和ArcMargin Loss的权重。合适的超参数设置对于获得最佳性能非常关键。
OpenFace
优点:
OpenFace模型是开源的,提供了开源的实现代码和预训练模型,方便使用和定制。
通过人脸对齐操作,可以有效处理姿态和尺度变化带来的影响,提高了模型的准确性和鲁棒性。
模型具备一定的通用性,适用于不同的人脸识别和验证任务。
缺点:
OpenFace模型在大规模和复杂数据集上的性能可能有所限制。
模型在性能和速度方面可能不如某些专门优化的商业人脸识别模型。
模型的准确性受人脸检测和对齐算法的质量和稳定性影响。
SphereFace
优点:
SphereFace模型的特征映射到球面上,这利用了球面几何的特点,使特征向量具有更好的可分性。
通过优化角度余弦的Margin,该模型通过强制不同类别的特征向量之间的分离度,提高了人脸识别的准确性和稳定性。
缺点:
SphereFace模型对于面部姿态和遮挡等复杂情况的鲁棒性可能稍弱,对输入图像的质量和预处理要求较高。
由于特征映射到球面上的操作,模型的复杂度增加,可能导致训练和推理的计算开销加大。感兴趣的话可以自行深入了解学习即可。
前文中我给出来了整个项目开发的详细流程示意图:

核心的实现思路是借助于arcFace模型来实现牛脸图像数据的向量化,之后借助于faiss来实现大模型向量数据库的检索匹配计算,整体技术方案和流程实现是没有问题。
本文的主题依旧围绕牛脸识别,但是想从另一个维度切入探索实现落地的可行性,这里主要的目的是想要引入孪生神经网络模型。首先看下效果图:

孪生神经网络(Siamese Neural Network)是一种特殊的神经网络结构,用于学习和比较输入之间的相似性。它包含两个共享参数的子网络,并通过共享权重来处理输入对。以下是孪生神经网络的详细构建原理:
-
孪生神经网络架构:孪生神经网络由两个相同的子网络组成,每个子网络都有相同的结构和参数。子网络可以是任意类型的神经网络,如卷积神经网络(CNN)或全连接神经网络(FCN),取决于具体的应用场景。
-
共享权重:两个子网络的参数是共享的,即它们具有相同的权重和偏置。这意味着两个子网络可以学习到相同的特征表示。
-
输入对处理:孪生神经网络接受成对的输入,每个输入代表一个样本。这对输入通过各自的子网络进行前向传播,并生成对应的特征表示。
-
相似性计算:通过设计特定的相似性度量方法,如欧氏距离或余弦相似度,比较两个子网络输出的特征表示之间的相似性。常见的方法是使用L1或L2距离来计算输入对的相似性得分。
-
训练和优化:孪生神经网络的训练目标通常是最小化相似对的相似性得分,最大化非相似对的相似性得分。可以使用交叉熵、对比损失或三元组损失等来优化网络参数,以便学习到更有意义的特征表示。
构建特定任务的孪生神经网络时,可以根据任务的需求进行定制。例如,在人脸识别任务中,子网络可以是用于人脸特征提取的CNN模型,而相似性得分可以使用余弦相似度来计算。
孪生神经网络的优点:
- 相较于传统的单输入输出神经网络,孪生神经网络在学习输入之间的相似性方面表现更优秀。
- 通过共享权重,减少了网络的参数量,提高了计算效率和模型的鲁棒性。
- 能够学习到表示不同输入之间相似度关系的特征,适用于比较和匹配任务。
孪生神经网络的缺点:
- 构建和训练孪生神经网络需要额外的计算资源和时间,因为需要处理成对的输入数据。
- 在处理大规模数据集时,计算成对的相似度得分可能会带来较大的计算开销。
总而言之,孪生神经网络是一种用于学习和比较输入之间相似性的特殊神经网络结构。它通过共享权重和特定的相似性度量方法来处理输入对,并能够学习到表示输入相似性的特征表示。在比较、匹配和相关任务中具有广泛应用的潜力。
从孪生神经网络的定义和构建原理不难看出它主要是为了度量相似度任务诞生的,将其运用到人脸识别甚至是牛脸识别任务中,就要考虑将识别或者是前文中1vsN的检索任务转化为1vs1的度量计算任务,本文中使用到的数据集与前文完全相同,这里就不再赘述了。
下面是一个base版的基于keras框架实现的孪生神经网络模型代码,如下所示:
from keras.models import Model
from keras.layers import Input, Dense
def create_siamese_network(input_shape):
# 孪生网络的输入
input_left = Input(input_shape)
input_right = Input(input_shape)
# 共享的子网络结构
shared_network = create_shared_network(input_shape)
# 孪生网络的特征提取
feature_left = shared_network(input_left)
feature_right = shared_network(input_right)
# 相似度度量
similarity_score = calculate_similarity_score(feature_left, feature_right)
# 创建孪生网络模型
model = Model(inputs=[input_left, input_right], outputs=similarity_score)
return model
def create_shared_network(input_shape):
# 创建共享的子网络结构,可以根据任务的具体需求选择合适的模型
# 以下是一个简单的全连接网络结构示例
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=input_shape))
model.add(Dense(64, activation='relu'))
return model
def calculate_similarity_score(feature_left, feature_right):
# 使用余弦相似度计算特征对的相似度得分
# 根据任务的需求,可以选择其他相似度度量方法
cosine_similarity = dot([feature_left, feature_right], axes=1, normalize=True)
return cosine_similarity当然也可以基于一些内置的预训练模型实现更加高效的计算都是可以的。简单PyTorch实例如下所示:
import torch
import torch.nn as nn
from nets.vgg import VGG16
class SiameseModel(nn.Module):
def __init__(self, input_shape, pretrained=False):
super(SiameseModel, self).__init__()
self.vgg = VGG16(pretrained, 3)
self.fc1 = torch.nn.Linear(input_shape, 512)
self.fc2 = torch.nn.Linear(512, 1)
def forward(self, X):
X1, X2 = X
X1 = self.vgg.features(X1)
X2 = self.vgg.features(X2)
X1 = torch.flatten(X1, 1)
X2 = torch.flatten(X2, 1)
X= torch.abs(X1 - X2)
X = self.fc1(X)
X = self.fc2(X)
return X
社区里面也有很多优秀的开源项目,也都是可以先拿来直接使用的,这里就不再赘述了,模型的训练会是一个漫长的过程,这里就不做记录了。
默认100次epoch的迭代计算,这里记录了整个训练过程中完整的loss数据,如下所示:
0.6955525741814086 0.685587237562452
0.6902110472969387 0.6653802888734001
0.6637471784716067 0.5677376176629748
0.6285249979599662 0.5299186706542969
0.5838085820215829 0.4202789340700422
0.5300411830037277 0.3758478198732649
0.4769054629047465 0.26953053857598985
0.4474117699432077 0.2700199906315122
0.4045300439277791 0.19387647807598113
0.3849721683756165 0.1986046633550099
0.35295190356718087 0.17597684285470416
0.3335671839043961 0.1182361816721303
0.30077713612258805 0.10762198982494219
0.28059095613982366 0.09263752230576107
0.26192621699308755 0.08953030141336578
0.24962900671529473 0.07422396870596068
0.23615058351840293 0.07251949980854988
0.22604790216554765 0.05717766843736172
0.20813286237372375 0.05367749168404511
0.1961980062704649 0.05534461518483502
0.191272405201789 0.040519437406744276
0.17238319083261563 0.04525824029530798
0.17125932105255792 0.03171133143561227
0.16278751368015448 0.034069083364946504
0.1574035486703889 0.024365605786442757
0.15757207648817056 0.0226481720539076
0.14088329971299407 0.02277404010029776
0.13017253510029234 0.015652759665889398
0.1342334189735677 0.01783241338229605
0.13309422318146835 0.029217104467430286
0.12359316380960601 0.013788682860987528
0.12340885935270268 0.011438016427148666
0.11935074973319258 0.01318096597013729
0.11505029778002027 0.016614699317142368
0.11475191379301482 0.0124727554153651
0.10623092823864325 0.011576966169689383
0.10215862645472613 0.007561055051961116
0.10106064023461586 0.008928090087803348
0.10151654127291086 0.008410952639366899
0.09638518015767292 0.006147108586238963
0.09377755090501738 0.012568129186651537
0.09016226219904164 0.011172266607172788
0.08651868418807754 0.0057730450694050105
0.08499294782335066 0.005962212623230049
0.08144575822375344 0.004712638268912477
0.07178199275032333 0.0040686159294896895
0.08071162342816962 0.005855099494302911
0.07431250991103072 0.00551563131489924
0.07509016846624776 0.004742926049844495
0.07076757133400403 0.006236325071326324
0.06691590962376191 0.007614519852878792
0.06723944414609476 0.0031199949361117823
0.06735928374796712 0.005569151097110339
0.06336869515033196 0.004416679634180452
0.06397452244465673 0.005675427758667086
0.058081838866313976 0.0033837439824960062
0.056820151090957456 0.004463032949050622
0.0583794480160758 0.0045965686074591105
0.055845767375290026 0.004053972165898553
0.05408345035896261 0.0021182163102951433
0.052181277523881624 0.005262626153749547
0.050827684013248185 0.002660957640702171
0.05140729247728328 0.0020925066650046833
0.04754799776725031 0.005687861565300929
0.04872655929413317 0.002164454232635243
0.046700213053871106 0.0030593727050083025
0.04223761892434996 0.0018079519471419709
0.042030469505029575 0.0022231877665035427
0.044137909880445934 0.002154701906588993
0.04268070929813899 0.0020497356325254908
0.04122306984308413 0.0022900596227762955
0.03944597493203484 0.0020951689104549585
0.04020858695405183 0.0013084668034155453
0.0430029640234544 0.004530186939518899
0.03729947069327214 0.0052595803164877
0.03604389345258914 0.0018884392239020339
0.03651091757646953 0.0016862660979053805
0.03675193889341346 0.001120888102533562
0.03654824974093447 0.001296478950618101
0.03586494711571899 0.0020495674556254275
0.03596495050374384 0.0014180863492323885
0.03290823474996405 0.0024229631285249656
0.03758502853253382 0.003758411348098889
0.031757292204669545 0.0011320600144764674
0.03453905884934277 0.0025484279696164386
0.0328233460100333 0.0010131140281113664
0.03042100972723019 0.0014705808450733977
0.03360418879509446 0.0013867150393447707
0.031514424260890815 0.0017793651054879385
0.030826039272447273 0.0011290412196623427
0.03239736887619119 0.001541762802350734
0.029425927781664783 0.0019687855084027563
0.030886391524127137 0.0016334658405477446
0.03111831574362373 0.0016229371340679272
0.030236442805476115 0.0012914258537680976
0.028646316401362535 0.0016845007427036761
0.03197887695144272 0.0014361011662653515
0.030544301349617633 0.0013694876131402063
0.028220375623808514 0.002001629362348467
0.030638592561377177 0.0010386178885320467这里对其进行对比可视化,如下所示:

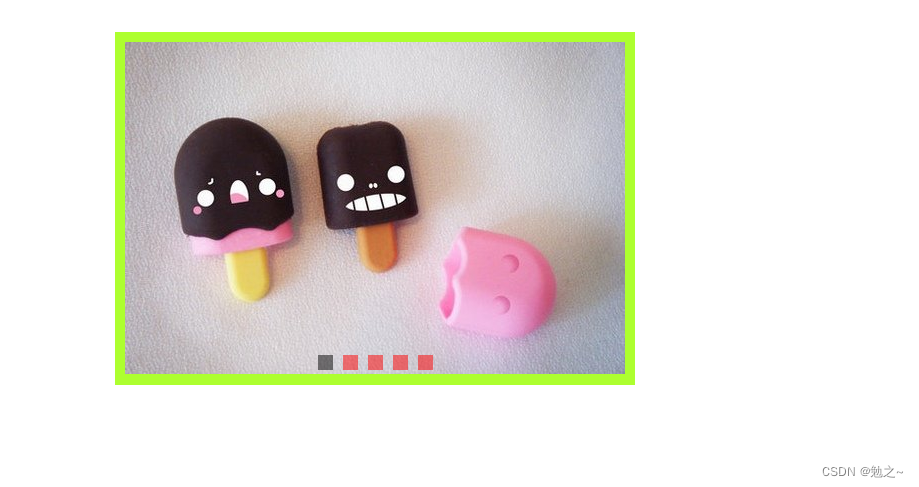
之后就可以推理进行预测计算,简单看下实例结果:

这里的匹配测量如下所示:

整体还是比较好理解的,这里就不再赘述了,为了美观便捷使用,这里做了可视化系统界面,如下所示: