一、Hive 小文件概述
在Hive中,所谓的小文件是指文件大小远小于HDFS块大小的文件,通常小于128 MB,甚至更少。这些小文件可能是Hive表的一部分,每个小文件都包含一个或几个表的记录,它们以文本格式存储。
Hive通常用于分析大量数据,但它在处理小文件方面表现不佳,Hive中存在大量小文件会引起以下问题:
-
存储空间占用过多:在Hadoop生态系统中,每个小文件都将占用一定的存储空间,而且每个小文件也需要一个块来存储。如果存在大量的小文件,将浪费大量的存储空间。
-
处理延迟:小文件数量过多,会引起大量IO操作,导致处理延迟。
-
查询性能下降:小文件用于分区和表划分,可能导致查询延迟并降低查询性能。此外,小文件还会增加元数据的数量,使得Hive在查询元数据时变得更加缓慢。
-
数据倾斜:如果数据分布不均匀,会导致一些Reduce任务处理了完全不同的分区,这会使某些Reduce任务的运行速度与其他Reduce任务相比非常慢。
因此,为了避免这些问题,我们需要对Hive中小文件的处理进行优化,减少小文件数量和大小,以提高数据处理效率和准确性。
二、如何排查小文件
1)获取fsimage信息
hdfs dfsadmin -fetchImage ./
2)格式化fsimage为可读文本
hdfs oiv -i ./fsimage_0000000007979236585 -t ./tmp/ -o ./fsimage.csv -p Delimited -delimiter ","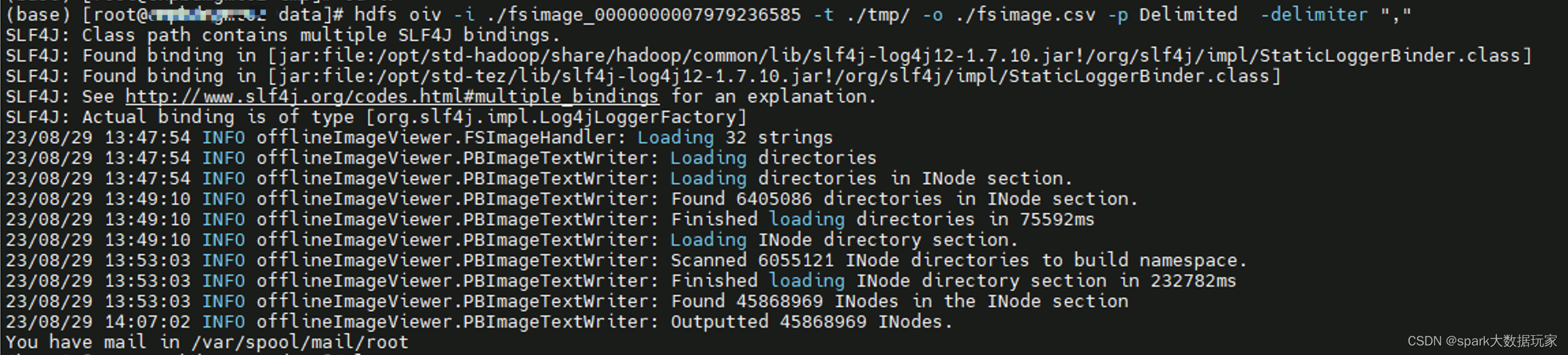
注意:需要创建tmp临时目录缓存中间结果,缓解内存的压力,否则将oom

3)建立存储fsimage的表
CREATE TABLE `tmp.fsimage_info_csv`(
`path` string,
`replication` int,
`modificationtime` string,
`accesstime` string,
`preferredblocksize` bigint,
`blockscount` int,
`filesize` bigint,
`nsquota` string,
`dsquota` string,
`permission` string,
`username` string,
`groupname` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/fsimage_info_csv';4)上传数据到hdfs
hdfs dfs -put /data/fsimage.csv /user/hive/warehouse/fsimage_info_csv/5) 逐级目录统计文件数量
以查找三级目录下的小文件数量为例,如下:
SELECT
dir_path ,
COUNT(*) AS small_file_num
FROM
( SELECT
relative_size,
dir_path
FROM
( SELECT
(
CASE filesize < 4194304
WHEN TRUE
THEN 'small'
ELSE 'large'
END) AS relative_size,
concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2], '/',split(PATH,'\/')[3], '/',split(PATH,'\/')[4], '/', split(PATH,'\/')[5], split(PATH,'\/')[6]) AS dir_path
FROM
tmp.fsimage_info_csv
WHERE
replication = 0 and path like '/hive/warehouse/%') t1
WHERE
relative_size='small') t2
GROUP BY
dir_path
ORDER BY
small_file_num desc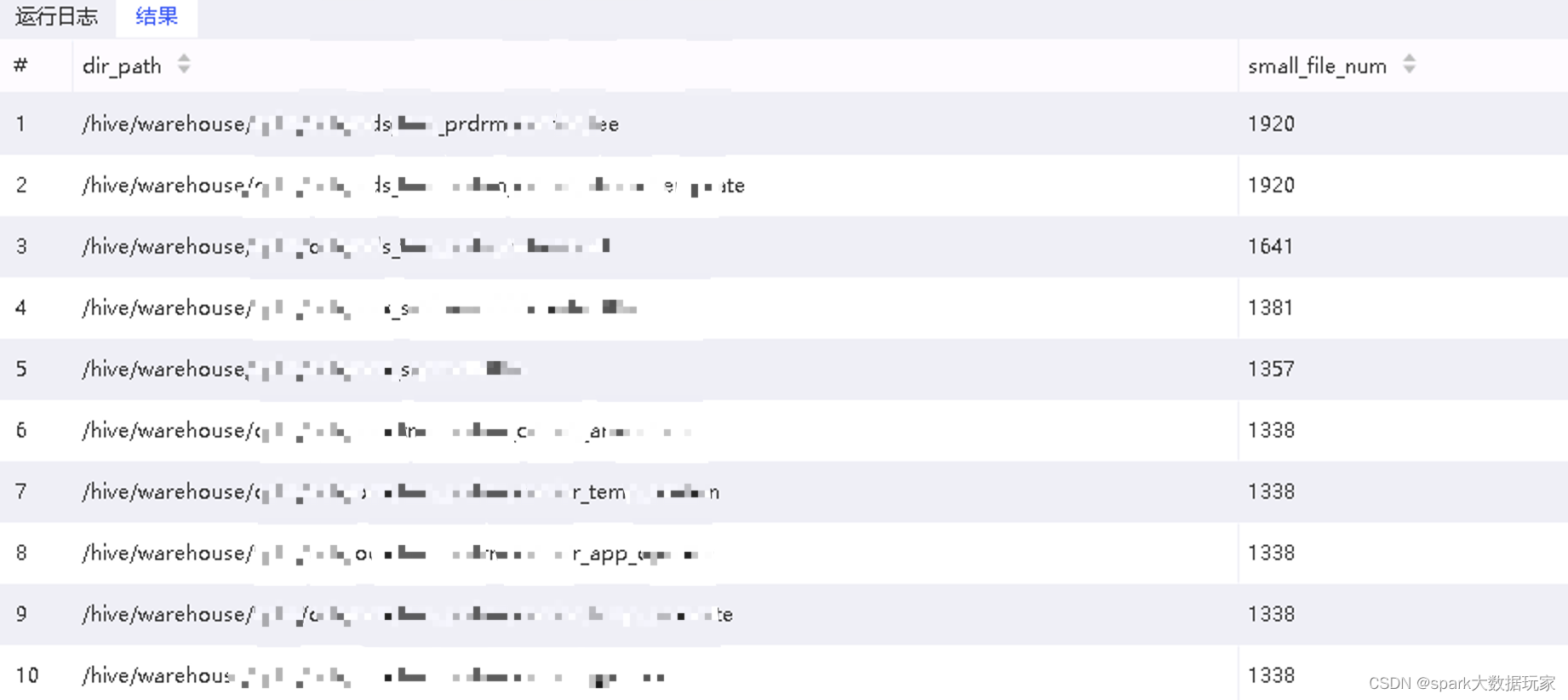
6 ) 小文件处理
- 根据涉及目录,反向找到涉及程序,尝试优化避免小文件的产生
- 及时合并归档小文件
- 及时清理历史小文件