VIT:https://blog.csdn.net/qq_37541097/article/details/118242600
Swin Transform:https://blog.csdn.net/qq_37541097/article/details/121119988
一、VIT
模型由三个模块组成:
Linear Projection of Flattened Patches(Embedding层)
Transformer Encoder(图右侧有给出更加详细的结构)
MLP Head(最终用于分类的层结构)
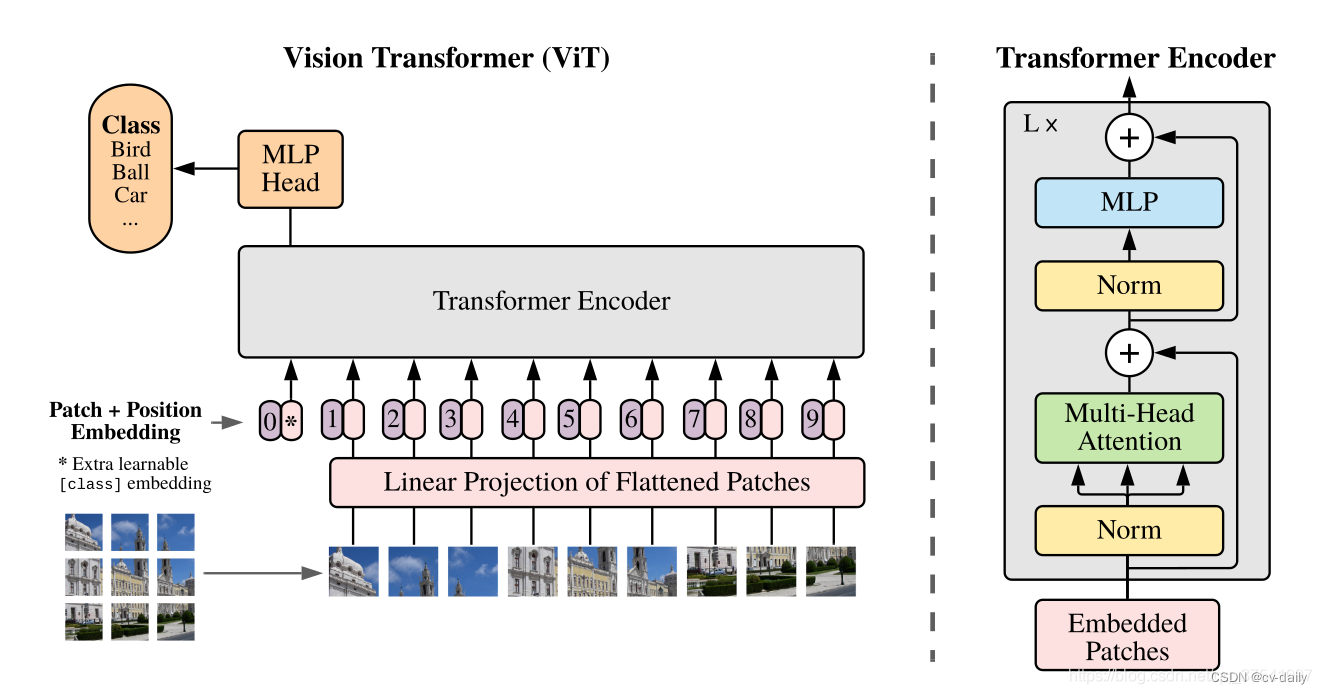
Embedding模块:
ViT-B/16为例,每个token向量长度为768。要求输入的token必须是二维的。需要把三维的图片信息转成二维。
以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
还要有一个用于分类的token,长度与其他token保持一致。与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。
Transformer Encoder模块:
vit使用
总结构
class VisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, nattr=1, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, use_checkpoint=False):
super().__init__()
self.nattr = nattr
self.use_checkpoint = use_checkpoint
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) ###第一步
num_patches = self.patch_embed.num_patches
# modify
# self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, self.nattr, embed_dim)) ##创建类别token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.nattr, embed_dim)) ##总的token
self.pos_drop = nn.Dropout(p=drop_rate) ##使用Dropout
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
# self.repr = nn.Linear(embed_dim, representation_size)
# self.repr_act = nn.Tanh()
# Classifier head
# self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.pos_embed, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1) # (bt, num_patches + nattr, embed_dim)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.norm(x)
# return x[:, :self.nattr]
return x[:, 1:]
第一步Embedding层,相当于一层卷积
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.num_x = img_size[1] // patch_size[1] # 28
self.num_y = img_size[0] // patch_size[0]
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
第二步+第三步,Transformer Encoder+MLP Head
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)]) ##创建12个Block,每个Block都是:归一化+attention+dropout+归一化+mlp(2个fc层)。
class Mlp(nn.Module): ##两个全连接层
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim) ##层归一化,LayerNorm
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop) ##注意力模块,需要设置头个数
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
最后一步,搭建分类器:
@CLASSIFIER.register("linear")
class LinearClassifier(BaseClassifier):
def __init__(self, nattr, c_in, bn=False, pool='avg', scale=1):
super().__init__()
self.pool = pool
if pool == 'avg':
self.pool = nn.AdaptiveAvgPool2d(1)
elif pool == 'max':
self.pool = nn.AdaptiveMaxPool2d(1)
self.logits = nn.Sequential(
nn.Linear(c_in, nattr),
nn.BatchNorm1d(nattr) if bn else nn.Identity()
)
def forward(self, feature, label=None):
if len(feature.shape) == 3: # for vit (bt, nattr, c)
bt, hw, c = feature.shape
# NOTE ONLY USED FOR INPUT SIZE (256, 192)
h = 16
w = 12
feature = feature.reshape(bt, h, w, c).permute(0, 3, 1, 2) ##(32,768,16,12)
feat = self.pool(feature).view(feature.size(0), -1) ##(32,768)
x = self.logits(feat) ##(32,num_class)
#return [x],feature,feat
return [x], feature
classifier = build_classifier(cfg.CLASSIFIER.NAME)(
nattr=train_set.attr_num,
c_in=c_output,
bn=cfg.CLASSIFIER.BN,
pool=cfg.CLASSIFIER.POOLING,
scale =cfg.CLASSIFIER.SCALE
)
model = FeatClassifier(backbone, classifier, bn_wd=cfg.TRAIN.BN_WD)


![读书笔记-《ON JAVA 中文版》-摘要23[第二十章 泛型-2]](https://img-blog.csdnimg.cn/c140d4cfa7aa43b083c25aae79eed135.gif)




![java八股文面试[多线程]——Synchronized的底层实现原理](https://img-blog.csdnimg.cn/ca21a0072cf44e23a5c218f32cd972c6.png)