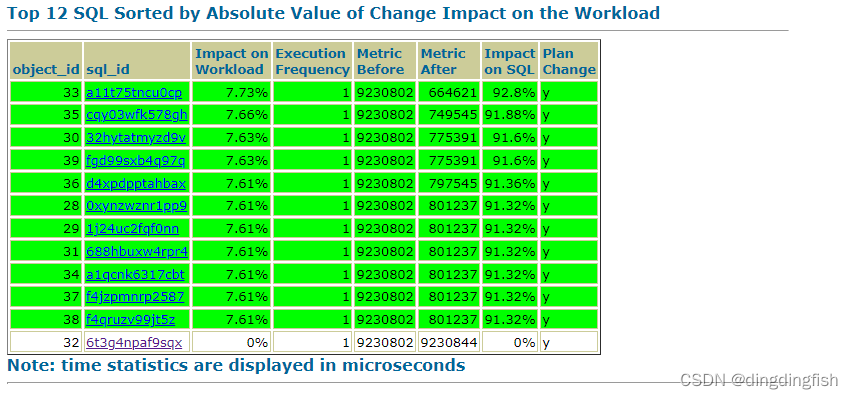
缘起
“蚂蚁呀嘿,蚂蚁呀呼,蚂蚁呀哈” 相信最近好多人的朋友圈或者抖音都被类似视频刷过屏!
类似的效果最早是在2020年初,那个时候大家应该还都记得,几乎所有的人都因为疫情原因被迫线上办公!
工作当然离不开开会了,这点歪果仁和中国很像,国内我们一般用qq或者钉钉来个在线视频会议!歪果仁也会经常开线上会议,不过他们用的最多的是zoom这个软件。经常的在线会会让人很烦躁,为什么呢?原本在家办公就不用洗头了,但是为了开在线视频会议还得去专门洗个头!
so,一个来自俄罗斯程序猿就想了一个招数恶搞一下他的同事。他基于 first-order-model 做了一个叫做Avatarify 的软件,并且放在了全世界做大的同性交友网站github上。First Order Motion Model for Image Animation 简单来说就是把一张图片变成动态的。Avatarify ,看起来很熟悉的名字,你肯定听过一部叫阿凡达的电影!之后程序猿小哥又基于Avatarify 做了一个苹果app,在网上掀起了吗咿呀嘿旋风,不过在上架appstore7天后在中国区就被下架了,原因不得而知。
来看一下 First Order Motion Model上的图片动画结果

First Order Motion Model上的swap face结果
看完以后大概能明白为什么被下架了!如果东西能被普通人随便使用,那么我们的表情甚至动作都能被别人模拟出来,只要他有一张你的照片!所以说人脸识别不是绝对安全,什么都可以被模拟!这两天的315晚会不知道大家看没有看,好多商家都在非法收集的脸部信息!
上面我们提到的库都是python的,app实现这样的功能都是把图片或者视频传输给服务器,然后服务器处理文件。
浏览器环境人脸识别
我们今天要在浏览器环境下面实现一个简单的人脸识别,我们会用到Tracking.js ,这是一个独立的JavaScript库,用于跟踪从相机或者图片实时收到的数据。跟踪的数据既可以是颜色,也可以是人,也就是说我们可以通过检测到某特定颜色,或者检测一个人体/脸的出现与移动,来触发JavaScript 事件。
trankingjs下载
我们需要先点击后面的标签下载trankingjs
trankingjs使用-识别图片
引入 tracking-min.js人脸识别库
引入face-min.js,eye-min.js,mouth-min.js 脸部,眼睛,嘴巴等模型文件
创建html文件,内容如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="./build/tracking-min.js"></script>
<script src="./build/data/face-min.js"></script>
<script src="./build/data/mouth-min.js"></script>
<script src="./build/data/eye-min.js"></script>
<style>
.rect {
border: 2px solid #a64ceb;
left: -1000px;
position: absolute;
top: -1000px;
}
.demo-container {
width: 100%;
height: 530px;
position: relative;
background: #eee;
overflow: hidden;
border-bottom-right-radius: 10px;
border-bottom-left-radius: 10px;
}
</style>
</head>
<body>
<div class="demo-container">
<img src="./imgs/2.png" alt="" id="img">
</div>
<script>
window.onload = function () {
var tracker = new tracking.ObjectTracker(['face', 'eye', 'mouth']);
tracker.setStepSize(1.7);
tracking.track('#img', tracker);
tracker.on('track', function (event) {
// 获取跟踪数据
event.data.forEach(function (rect) {
window.plot(rect.x, rect.y, rect.width, rect.height);
});
});
window.plot = function (x, y, w, h) {
var rect = document.createElement('div');
document.querySelector('.demo-container').appendChild(rect);
rect.classList.add('rect');
rect.style.width = w + 'px';
rect.style.height = h + 'px';
rect.style.left = (img.offsetLeft + x) + 'px';
rect.style.top = (img.offsetTop + y) + 'px';
};
}
</script>
</body>
</html>
html和css比较简单,这里我们主要来看js代码。
注意js代码必须一定要写在window.onload 回调函数里面,否者获取不到图片的数据,就没有办法对图片进行识别!
创建识别对象
// 创建追踪识别对象
var tracker = new tracking.ObjectTracker(['face', 'eye', 'mouth']);
// 设置 追踪识别的图片
tracking.track('#img', tracker);
// 监听追踪事件
tracker.on('track', function (event) {
// 获取追踪数据
event.data.forEach(function (rect) {
window.plot(rect.x, rect.y, rect.width, rect.height);
});
});
获取的event.data是一个数组 ,数组存放识别处理出来的脸部数据,数据结构如下
{width: 61, height: 61, x: 244, y: 125}
x和y是识别出来元素的坐标,width和height是识别出来元素的宽度
处理识别结果
接下来我们只要需要把得到的结果标记到图片的对应的位置即可,通过plot函数创建一个div,给定对应的坐标和宽高
window.plot = function (x, y, w, h) {
var img = document.querySelector('#img')
var rect = document.createElement('div');
document.querySelector('.demo-container').appendChild(rect);
rect.classList.add('rect');
rect.style.width = w + 'px';
rect.style.height = h + 'px';
rect.style.left = (img.offsetLeft + x) + 'px';
rect.style.top = (img.offsetTop + y) + 'px';
};
然后就会看到这样的结果,会识别出照片的眼睛、鼻子、嘴巴
trankingjs使用-识别摄像头数据
创建html文件,写入如下代码
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>demo</title>
<script src="./build/tracking-min.js"></script>
<script src="./build/data/face-min.js"></script>
<style>
video,
canvas {
position: absolute;
}
</style>
</head>
<body>
<div class="demo-container">
<video id="video" width="320" height="240" preload autoplay loop muted></video>
<canvas id="canvas" width="320" height="240"></canvas>
</div>
<script>
window.onload = function () {
// 视频显示
var video = document.getElementById('video');
// 绘图
var canvas = document.getElementById('canvas');
var context = canvas.getContext('2d');
var tracker = new tracking.ObjectTracker('face');
// 设置识别的放大比例
tracker.setInitialScale(4);
// 设置步长
tracker.setStepSize(2);
// 边缘密度
tracker.setEdgesDensity(0.1);
// 启动摄像头,并且识别视频内容
tracking.track('#video', tracker, {
camera: true
});
tracker.on('track', function (event) {
context.clearRect(0, 0, canvas.width, canvas.height);
// 绘制
event.data.forEach(function (rect) {
context.strokeStyle = '#a64ceb';
context.strokeRect(rect.x, rect.y, rect.width, rect.height);
});
});
};
</script>
</body>
</html>
核心js代码解释如下
创建识别对象
创建识别对象并且启用摄像头,将摄像头内容输出到video标签上
// 视频显示
var video = document.getElementById('video');
//创建识别对象
var tracker = new tracking.ObjectTracker('face');
// 设置识别的放大比例
tracker.setInitialScale(4);
// 设置步长
tracker.setStepSize(2);
// 边缘密度
tracker.setEdgesDensity(0.1);
// 启动摄像头,并且识别视频内容
tracking.track('#video', tracker, {
camera: true
});
注意:这里的识别放大比例,步长,边缘密度等值可以根据摄像头距离物体远近自己调整。
处理识别结果
// 创建canvas 用于绘图绘图
var canvas = document.getElementById('canvas');
var context = canvas.getContext('2d');
//监听识别事件
tracker.on('track', function (event) {
//清除上一次绘图结果
context.clearRect(0, 0, canvas.width, canvas.height);
// 根据识别结果绘制绘制矩形
event.data.forEach(function (rect) {
context.strokeStyle = '#a64ceb';
context.strokeRect(rect.x, rect.y, rect.width, rect.height);
});
});
然后启动起来,浏览器会提示是否允许开启摄像头!点击允许,就会看到你英俊潇洒(沉鱼落雁)的脸庞!