概述
此实验申请地址在这里。
实验帮助在这里。
此实验预估完成时间100分钟。
关于自治数据库自动分区的帮助文档,请参见这里。
这个实验设计得很好,推荐。
介绍
关于本研讨会
自治数据库中的自动分区分析您的应用程序工作负载,并自动将分区应用于您的表和索引,以提高性能或更好地管理大型表。
找到合适的分区策略需要深入了解应用程序工作负载和数据分布。 当您执行手动分区时,您必须分析您的工作负载并选择如何将分区应用于表和索引以提高应用程序的性能。 自动分区使自治数据库用户能够从分区中受益,而无需执行手动模式和工作负载分析。
自动分区使用单列分区键与单级分区相结合。 到目前为止,自动分区不支持更复杂的分区策略,例如多列分区表或复合分区。
自动分区从以下分区方法中进行选择:
- AUTOMATIC INTERVAL:此选择最适合分区键值的范围。 这是一种仅限内部的分区方法。
- LIST AUTOMATIC:此分区方法适用于不同的分区键值。
- HASH:对分区键的哈希值应用分区。
该研讨会旨在用于 19c 自治数据库 (ADB) 实例,其中表需要大于 5 GB 才能考虑进行自动分区。 在非免费 ADB 服务中,表必须至少为 64GB。这个限制是在哪个文档中说明的呢?
这个说明找到了,是在DBMS_AUTO_PARTITION PL/SQL包的说明中,而非在Using Oracle Autonomous Database on Shared Exadata Infrastructure文档里。
To be a valid candidate, the following tests must pass:
- Table passes inclusion and exclusion tests specified by AUTO_PARTITION_SCHEMA and AUTO_PARTITION_TABLE configuration parameters.
- Table exists and has up-to-date statistics.
- Table is at least 64 GB.
- Table has 5 or more queries in the SQL tuning set that scanned the table.
- …
实验步骤是:
- 创建一个名为 APART 的 5GB 非分区表,其中填充了随机数据
- 在 APART 表上运行测试工作负载
- 运行自动分区验证 API 以确认表满足自动分区要求
- 在仅报告模式下执行自动分区推荐任务。 该任务将构建表的分区副本,并比较分区前后的性能。
- 使用 apply API 实现自动分区推荐。 APART 表将被转换为 ONLINE ALTER TABLE 操作,这样生产工作负载就不会中断。
虽然不知道为什么,但只有5GB以上的表才应考虑分区。这个在2017年的OOW和2022年的OCW上都已经提到过。
工作原理
自动分区分析选定候选表的工作负载。
- 默认情况下,自动分区使用自治数据库中收集的工作负载信息进行分析。
- 根据工作负载的大小,可能会考虑查询样本。
自动分区根据工作负载分析和性能优势的量化和验证来评估分区方案:
- 具有综合统计信息的候选**无分区?**方案在内部创建并进行性能分析。没有数据吗?有的,应该译为无分区,而非空分区
- 选择具有最高估计 IO 减少的候选方案作为最佳分区策略,并在内部实现以测试和验证性能。
- 如果候选分区方案提高了超出指定性能和回归标准的性能,则建议使用自动分区。
- 推荐的自动分区方案可以在线方式自动实现。 或者,您可以在自己查看推荐的好处后选择手动调用推荐的自动分区方案的应用。
致谢
本实验的设计者为Nigel Bayliss,贡献者为Hermann Baer。
他们俩还在Oracle Blogs上发表了相关文章,推荐阅读:Automatic Partitioning with Autonomous Database
实验 1:配置自治数据库实例
自治数据库介绍
本研讨会将引导您完成开始使用 Oracle 自治数据库的步骤。 在本次研讨会中,我们将使用针对分析和仓储 (ADW) 优化的始终免费的自治数据库。 您将在几分钟内配置一个新数据库。
经过实验设计的是使用ADW,但我还是会使用ATP。因为这是自治数据库的特性,而非仅仅是自治数据仓库的特性;另外,这个对于HTAP场景非常有用
Oracle 自治数据库具有以下特点:
- 自动驾驶 自动化数据库配置、调整和扩展。
配置高可用性数据库,针对特定工作负载进行配置和调整,并在需要时扩展计算资源,所有这些都是自动完成的。 - 自我保护 自动化数据保护和安全。
使用 Oracle 自治数据库自动保护敏感和受监管的数据、修补数据库的安全漏洞并防止未经授权的访问。 - 自我修复 自动进行故障检测、故障转移和修复。
自动检测和保护系统故障和用户错误,并提供零数据丢失的备用数据库故障转移。
任务 1:创建一个新的始终免费的自治数据仓库数据库
创建一个ATP,参数如下:
- Always Free:未选中
- Name:ATPautopart
- 数据库版本:19c (默认,目前唯一支持的版本,小版本为最新,即19.17)
- 数据库Edition:DBEE
- OCPU: 1(默认)
- Storage Capacity: 1T(默认)
- Auto scaling: Off
- network access:Secure access from everywhere (默认)
由于我没有Always Free的Quota,因此只好建了一个收费的ADB,导致后续用于测试的表需要大于64G,但我怀疑有hint可以改
服务就绪时间如下,不到1分钟:
Tue, Nov 15, 2022, 13:41:48 UTC Tue, Nov 15, 2022, 13:42:23 UTC
实验 2:创建非分区表
介绍
在本实验中,我们创建了一个 5GB 的非分区表。 一个表在 Always Free Autonomous Database 环境中必须至少为 5GB 或在非免费自治数据库(事务处理或数据仓库)中至少为 64GB 才能被视为自动分区的候选表。本例我们使用了后者。
注意:要按原样运行此研讨会,您需要确保在 19c 自治数据库上运行它。
任务 1:从 Oracle OCI 调用 Cloud Shell
为方便,还是决定不用Cloud Shell,而是在同一个Region创建了一个实例,安装Oracle数据库客户端来连接ATP。
任务 2:创建和填充新表
以下脚本均用ADMIN用户执行,注意d列的数据类型,他将成为分区键:
drop table apart purge;
create table apart (
a number(10),
b number(10),
c number(10),
d date,
pad varchar2(1000));
--
-- Hints must be enabled for this particular INSERT statement
-- because we want to force a particular join order. This will
-- keep the random strings apart when written to storage, which will
-- make compression less effective. We want to make the table large
-- as quickly as possible so that it qualifies for auto partitioning.
alter session set optimizer_ignore_hints = false;
-- Table data is compressed by default, so we will insert random data
-- to make compression less effective. The aim is to create
-- a large table as quickly as possible.
--
insert /*+ APPEND */ into apart
with
r as ( select /*+ materialize */ dbms_random.string('x',500) str
from dual connect by level <= 2000 ),
d as ( select /*+ materialize */ to_date('01-JAN-2020') + mod(rownum,365) dte
from dual connect by level <= 2500 ),
m as ( select 1
from dual connect by level <= 3 )
select /*+ leading(m d r) use_nl(d r) */
rownum, rownum, rownum, dte, str
from m,d,r;
-- Commit the transaction
commit;
alter session set optimizer_ignore_hints = true;
运行结果:
15000000 rows created.
Elapsed: 00:01:32.51
我们的表需要大于64G,因此再将表放大:
-- 当前只有9G
-- 到18G,耗时01:14.94秒
insert /*+ append */ into apart select * from apart;
commit;
-- 到36G,耗时02:33.10秒
insert /*+ append */ into apart select * from apart;
commit;
-- 到72G,耗时05:30.32秒
insert /*+ append */ into apart select * from apart;
commit;
任务 3:检查新表大小
select sum(bytes)/(1024*1024) size_in_megabytes
from user_segments
where segment_name = 'APART';
运行结果,目前已超过64G的要求:
SIZE_IN_MEGABYTES
-----------------
72200
实验 3:验证表
介绍
确认所选表可以用于自动分区。
预计时间:25分钟
任务 1:验证您新创建的非分区表可用于自动分区
运行以下脚本,验证表是否可用于自动分区:
set serveroutput on
declare
ret varchar2(1000);
begin
ret := dbms_auto_partition.validate_candidate_table (table_owner=>user,table_name=>'APART');
dbms_output.put_line(' ');
dbms_output.put_line(' ');
dbms_output.put_line('Auto partitioning validation: ' || ret);
end;
/
如果表不够大:
Auto partitioning validation: INVALID: table is too small (8.8 GB actual, 64 GB required)
如果表够大,但目前还是不行,因为其上还没有工作负载:
Auto partitioning validation: INVALID: table is referenced by 1 full table scan queries in the SQL tuning set; 5 queries
required
任务 2:生成有代表性的样本工作负载 - 执行测试查询
分区可以提高应用程序的性能。 我们新建的表上还没有负载运行。 出于本实验的目的和要求,我们模拟您的应用程序,在新建表上运行一组具有代表性的示例查询。
运行以下查询,每个查询运行几秒到十几秒不等:
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-MAR-2020') and to_date('05-mar-2020');
select /* TEST_QUERY */ sum(a) from apart
where d = to_date('01-MAR-2020');
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-JAN-2020') and to_date('05-JAN-2020');
select /* TEST_QUERY */ sum(c) from apart
where d between to_date('01-APR-2020') and to_date('05-APR-2020');
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-JUN-2020') and to_date('02-JUN-2020');
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-DEC-2020') and to_date('31-DEC-2020');
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-AUG-2020') and to_date('31-AUG-2020');
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-OCT-2020') and to_date('01-OCT-2020');
select /* TEST_QUERY */ sum(c) from apart
where d between to_date('01-FEB-2020') and to_date('05-FEB-2020');
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-MAY-2020') and to_date('02-MAY-2020');
select /* TEST_QUERY */ avg(a) from apart
where d between to_date('01-JUL-2020') and to_date('02-JUL-2020');
任务 3:等待 Oracle 自治数据库自动收集您的应用程序工作负载
Oracle 自治数据库每 15 分钟自动收集一次您的工作负载信息。 Auto STS Capture Task 负责在名为 SYS_AUTO_STS 的 SQL 调优集(SQL Tuning Set)中捕获工作负载 SQL。 这是在自治数据库环境中自动维护的自动 SQL 调优集或 ASTS。
使用以下查询监控上次调度时间并等待任务再次执行:
select current_timestamp now from dual;
col task_name for a24
select task_name,
status,
enabled,
interval,
last_schedule_time,
systimestamp-last_schedule_time ago
from dba_autotask_schedule_control
where dbid = sys_context('userenv','con_dbid')
and task_name like '%STS%';
输出如下:
NOW
---------------------------------------------------------------------------
16-NOV-22 02.48.48.269256 AM +00:00
TASK_NAME STATUS ENABL INTERVAL
------------------------ ---------- ----- ----------
LAST_SCHEDULE_TIME
---------------------------------------------------------------------------
AGO
---------------------------------------------------------------------------
Auto STS Capture Task SUCCEEDED TRUE 900
16-NOV-22 02.41.31.458 AM +00:00
+000000000 00:07:17.602796
从输出可以看出,每900秒运行一次Auto STS Capture Task,下一次运行还需等待7分17秒。
反复运行查询,监控 LAST SCHEDULE TIME,并等待它改变。 或者,查看“AGO”列值并等待它显示任务在几秒钟前运行。
在生成工作负载后最多 等待15 分钟,自治数据库已收集此工作负载。 确认已在自动 SQL 调整集中捕获工作负载查询。
set pages 9999
select sql_text
from dba_sqlset_statements
where sql_text like '%TEST_QUERY%'
and sqlset_name = 'SYS_AUTO_STS';
输出如下,之前执行的11个查询全部捕获:
SQL_TEXT
--------------------------------------------------------------------------------
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-JAN-2020
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-MAR-2020'
select /* TEST_QUERY */ sum(a) from apart
where d = to_date('01-MAR-2020')
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-DEC-2020
select /* TEST_QUERY */ avg(a) from apart
where d between to_date('01-JUL-2020
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-AUG-2020
select /* TEST_QUERY */ sum(c) from apart
where d between to_date('01-APR-2020
select /* TEST_QUERY */ sum(c) from apart
where d between to_date('01-FEB-2020
select /* TEST_QUERY */ sum(b) from apart
where d between to_date('01-OCT-2020
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-JUN-2020
select /* TEST_QUERY */ sum(a) from apart
where d between to_date('01-MAY-2020
11 rows selected.
任务 4:再次确认将新创建的非分区表是否符合条件
现在已经在自动 SQL 调优集中捕获了工作负载,再次验证:
set serveroutput on
declare
ret varchar2(1000);
begin
ret := dbms_auto_partition.validate_candidate_table (table_owner=>user,table_name=>'APART');
dbms_output.put_line(' ');
dbms_output.put_line(' ');
dbms_output.put_line('Auto partitioning validation: ' || ret);
end;
/
Wow,符合条件了:
Auto partitioning validation: VALID
实验 4:执行推荐任务
预计时间:20分钟
目标:使用自动分区来推荐一种分区方法,并确认它会为我们的工作负载带来性能优势。
Recommendation_partition_method 过程将对工作负载查询和表本身进行分析。 根据这些信息,将使用表及其数据的综合统计信息来识别候选分区方案。 接下来,构建包含数据的表的分区副本,并在此副本上重新测试工作负载查询。 最后,将生成摘要报告。
完成以下过程的时间取决于表大小、索引数量和捕获的工作负载的执行时间(自动分区可能会选择使用工作负载的子集而不是整个工作负载)。
set timing on
set serveroutput on
set trimspool on
set trim on
set pages 0
set linesize 1000
set long 1000000
set longchunksize 1000000
set heading off
set feedback off
exec dbms_auto_partition.configure('AUTO_PARTITION_MODE','REPORT ONLY');
declare
r raw(100);
cursor c1 is
select partition_method, partition_key, report
from dba_auto_partition_recommendations
where recommendation_id = r;
begin
r :=
dbms_auto_partition.recommend_partition_method(
table_owner => 'ADMIN',
table_name => 'APART',
report_type => 'TEXT',
report_section => 'ALL',
report_level => 'ALL');
for c in c1
loop
dbms_output.put_line('=============================================');
dbms_output.put_line('ID: '||r);
dbms_output.put_line('Method: '||c.partition_method);
dbms_output.put_line('Key : '||c.partition_key);
dbms_output.put_line('=============================================');
end loop;
end;
/
上述过程运行了近27分钟,以下为输出:
=============================================
ID: ED8ED7C1683D93D7E0532614000A2430
Method: LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL '1' MONTH, TIMESTAMP '2020-01-01 00:00:00')) AUTOMATIC
Key : D
=============================================
Elapsed: 00:26:52.35
自动分区已为您的未分区表确定了一个最佳模式,该模式将提高性能。 分区方法不是标准的范围或间隔分区(其实就是列表分区),因为它需要考虑 NULL 分区键,并且它可避免创建大量分区,例如,如果在D 列插入/更新到未来很远的日期值。
实验 5:查看推荐
预计时间:10分钟
目标:查看自动分区报告和自动分区数据字典视图中可用的信息。
任务 1:查看推荐的基本信息
每当自动分区为候选表识别出合适的推荐时,结果就会存储在数据字典中。 DBA_AUTO_PARTITION_RECOMMENDATIONS 视图可用于查看推荐的详细信息,例如分区方法和分区键。
使用以下查询查看最新的推荐详情。
set linesize 180
column partition_method format a100
column partition_key format a13
select partition_method,partition_key
from dba_auto_partition_recommendations
where generate_timestamp =
(select max(generate_timestamp)
from dba_auto_partition_recommendations);
输出如下,分区方法是LIST,分区列是“D”。
LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL '1' MONTH, TIMESTAMP '2020-01-01 00:00:00')) AUTOMATIC D
任务 2:提取并下载自动分区报告
除了关于推荐执行和顶级发现的核心信息之外,自治数据库还存储了一份关于工作负载执行的详细报告,该报告针对为验证而构建的隐藏分区表。 您可以直接从数据字典中选择此信息,或使用专门构建的界面以用户友好的格式(例如 HTML)提取此信息。
通过执行以下命令来提取最新的自动分区报告。 该脚本会将名为 autoPartitionFinding.html 的文件假脱机到您调用 sqlcl/sqlplus 的当前目录中。
set trimspool on
set trim on
set pages 0
set linesize 1000
set long 1000000
set longchunksize 1000000
set heading off
set feedback off
spool autoPartitionFinding.html
select dbms_auto_partition.report_last_activity(type=>'HTML') from dual;
exit;
任务 3:查看自动分区报告
这个报告有点长,共4639列。我们看一下表头部分:
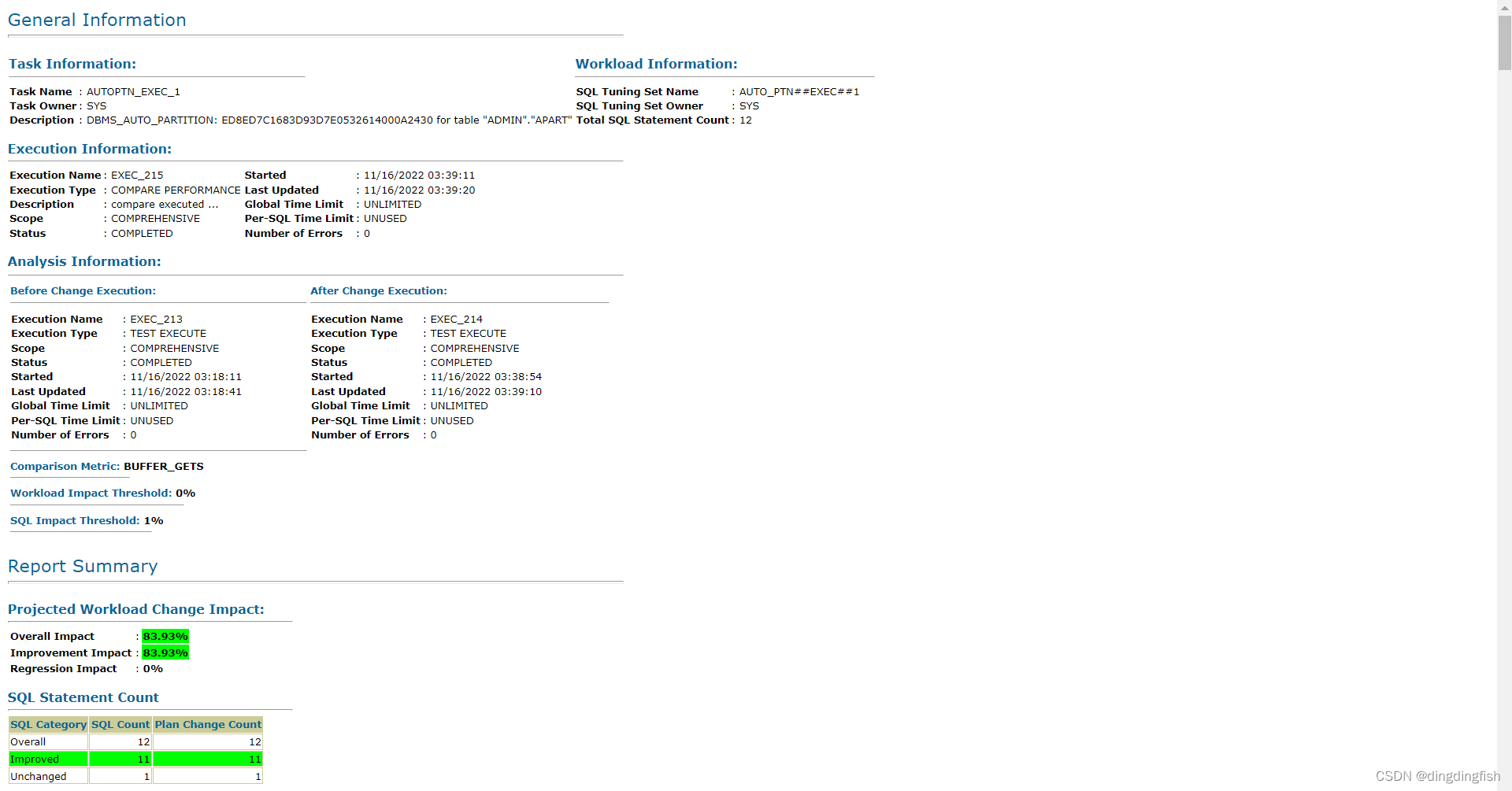
然后是提升的SQL,最后那个没有提升的SQL实际上是我运行的select count(*):
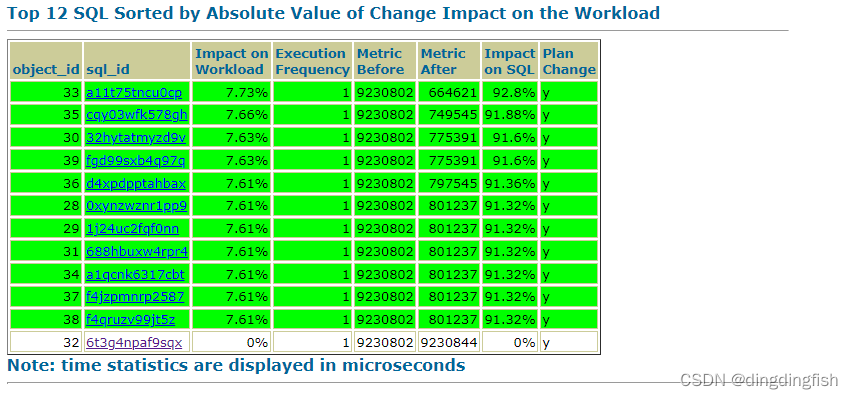
还可以看到之前之后的执行计划,每一个具体SQL的提升等。
任务 4:查看 modify-table DDL
可以在生产数据库的克隆上运行推荐任务并检索可用于对生产数据库表进行分区的 DDL 命令。 DDL 命令保存在 DBA_AUTO_PARTITION_RECOMMENDATIONS 中。
检查自动分区将用于更改候选表的 DDL 命令。 请注意,它使用 ONLINE PARALLEL 操作。 在此示例中,查询 DBA_AUTO_PARTITION_RECOMMENDATIONS 以查看最新建议。
set long 100000
set pages 9999
select modify_table_ddl
from dba_auto_partition_recommendations
where generate_timestamp =
(select max(generate_timestamp)
from dba_auto_partition_recommendations)
order by recommendation_seq;
输出如下:
MODIFY_TABLE_DDL
--------------------------------------------------------------------------------
begin
-- DBMS_AUTO_PARTITION recommendation_ID 'ED8ED7C1683D93D7E0532614000A2430'
-- for table "ADMIN"."APART"
-- generated at 11/16/2022 03:18:41
dbms_auto_partition.begin_apply(expected_number_of_partitions => 13);
execute immediate
'alter table "ADMIN"."APART"
modify partition by
LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL ''1'' MONTH, TIMESTAMP ''2020-01-0
1 00:00:00'')) AUTOMATIC (PARTITION P_NULL VALUES(NULL))
auto online parallel';
dbms_auto_partition.end_apply;
exception when others then
dbms_auto_partition.end_apply;
raise;
end;
以上DDL是一个在线的并行操作,分区策略是Auto List。
实验 6:应用建议
预计时间:10分钟
目标:接受分区建议并创建分区表。
任务 1:将建议应用于实施分区
在前面的实验中,输出中包含了建议ID,即第一列中的ID:
=============================================
ID: ED8ED7C1683D93D7E0532614000A2430
Method: LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL '1' MONTH, TIMESTAMP '2020-01-01 00:00:00')) AUTOMATIC
Key : D
=============================================
Elapsed: 00:26:52.35
使用您的建议 ID 执行以下命令以启动分区表构建:
exec dbms_auto_partition.apply_recommendation('ED8ED7C1683D93D7E0532614000A2430');
将使用 ALTER TABLE MODIFY PARTITION ONLINE 命令在线构建表的分区版本。 在整个过程中,您的原始表不会受到影响或锁定。 19c 实例中的 5GB 表大约需要 10 分钟。我们的72GB的表耗时Elapsed: 16:42.02 分钟。
任务 2:确认表已分区
成功修改分区表后,旧的非分区表不再存在。 您可以通过查询数据字典来验证修改是否成功。
检查 APART 现在是一个分区表:
set trims on
set linesize 300
column partition_name format a20
column segment_name format a15
select segment_name,
partition_name,
segment_type,
bytes/(1024*1024) mb
from user_segments
order by partition_name;
输出如下:
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE MB
--------------- -------------------- ------------------ ----------
APART P_NULL TABLE PARTITION .0625
APART SYS_P2197 TABLE PARTITION 6104
APART SYS_P2198 TABLE PARTITION 5888
APART SYS_P2199 TABLE PARTITION 6280
APART SYS_P2200 TABLE PARTITION 6272
APART SYS_P2201 TABLE PARTITION 6074
APART SYS_P2202 TABLE PARTITION 6272
APART SYS_P2203 TABLE PARTITION 6272
APART SYS_P2204 TABLE PARTITION 6272
APART SYS_P2205 TABLE PARTITION 5248
APART SYS_P2206 TABLE PARTITION 6272
APART SYS_P2207 TABLE PARTITION 6112
APART SYS_P2208 TABLE PARTITION 5376
13 rows selected.
在我们的例子中,该表总共有13个分区,除一个用于接收 NULL 分区键的分区外,每个分区大小约为 5-6 GB。 分区大小会有所不同,因为压缩因子对数据内容和数据排序非常敏感。
压缩启用了吗?并没有啊!也许ADW会压缩,但ATP没有
SELECT compression, compress_for
FROM user_tables
WHERE table_name = 'APART';
COMPRESS COMPRESS_FOR
-------- ------------------------------
SELECT compression, compress_for
FROM user_tab_partitions
WHERE table_name = 'APART';
COMPRESS COMPRESS_FOR
-------- ------------------------------
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
DISABLED
13 rows selected.
无需人工分析您的工作负载和模式,自动分区已为您的模式和应用程序确定了最佳分区方案,无需您干预即可透明地提高性能。 您的候选表越大,您在应用程序中体验到的性能优势就越大。
研讨会到此结束。