文章目录
- 0. 前言
- 1. 相关概念
- 1.1 名称介绍
- 1.2 官网特性介绍
- 2. 快速入门
- 2.1 准备工作
- 2.2.1 准备表
- 2.2.2 创建工程
- 2.2 入门测试
- 2.2.1 编写实体类
- 2.2.2 编写Mapper
- 2.2.3 编写测试类
- 3. CRUD
- 3.1 条件构造器
- 3.1.1 AbstractWrapper
- (1) 基本比较操作
- (2) allEq
- (3) 模糊查询
- (4)分组查询、排序
- (5)连接 or and
- 3.1.2 QueryWrapper
- 3.1.3 UpdateWrapper
- 3.2 Mapper CRUD 接口
- 3.2.1 Insert
- 3.2.2 Delete
- 3.2.3 Update
- 3.2.4 Select
- 3.3 Service CRUD 接口
- 3.3.1 SaveOrUpdate
- 3.3.2 Remove
- 3.3.3 Page
- 3.3.4 Count
- 3.4 ID 生成器
- 3.4.1 默认ID生成器
- 3.4.2 自定义ID生成器
- 3.5 Lambda Wrapper
- 3.5.1 LambdaQueryWrapper
- 3.5.2 LambdaUpdateWrapper
- 4. 连表查询
- 4.1 MP的连表解决方案
- 4.2 Mybatis连表
- 5. 总结
0. 前言
Mybatis Plus 个人学习笔记。
学习前提:有一定的SQL、Mybatis 基础。
学习目标:快速入门。
参考官网:MybatisPlus官网
参考资料: 稀土掘金优质文章
博客园优质文章
1. 相关概念
我们用传统的 Mybatis 进行项目的持久层开发时,常常要自己手动写很多 Mapper.xml 文件。 同时我们可以了解到,使用MybatisPlus可以节省很多SQL的编写,解放了一部分劳动力。
下面我们开始正式学习!
1.1 名称介绍
MybatisPlus,简称MP,是一个Mybatis增强工具。
1.2 官网特性介绍
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
简单总结一下上面提到的特性:
不影响传统Mybatis的开发方式,开销、损耗小,支持多种数据库、多种操作方式。
这部分刚开始的时候了解一下就好,我们的目标是会用。建议用熟练了以后再回过头来详细阅读特性。
2. 快速入门
按照官网的指示和用例来入门。
2.1 准备工作
2.2.1 准备表
在准备表之前,我们首先要准备一个数据库,名称自己定。
例如,我的库:
CREATE DATABASE mybatis_plus_learning;
USE mybatis_plus_learning;
建表:
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
插入数据:
DELETE FROM user;
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');
2.2.2 创建工程
按照官网的建议,我们创建一个SpringBoot工程,并添加相关依赖。
以下拿我自己的举例:
SpringBoot版本:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.9</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
相关依赖:
<dependencies>
<!-- SpringBoot 相关 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- MybatisPlus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<!-- Mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
application.yml配置:
#数据源
spring:
datasource:
url: jdbc:mysql://localhost:3306/mybatis_plus_learning?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
#配置日志
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
注意,官网的描述是SpringBoot 2.0+ 、MP 最新版本,我这里选择的是SpringBoot 2.5.x, MP 较新(截至至本文编辑日期)但不是最新版本。
另外,官网提供了h2数据库依赖,我这里选用的是Mysql,读者可根据自身需求参考选用。
另外,由于mybatis-plus为我们省略了很多sql,所以部分sql我们是不可见的,于是我们可以配置日志,通过日志来查看到底执行了什么样的sql语句。
2.2 入门测试
2.2.1 编写实体类
根据官网的教程我们编写实体类;
@Data
public class User implements Serializable {
/**
* 官方提供User表对对应的属性
*/
private Long id;
private String name;
private Integer age;
private String email;
}
2.2.2 编写Mapper
@Repository
public interface UserMapper extends BaseMapper<User> {
//已经实现了CRUD,此处我们不必编写抽象方法了
}
主启动类添加MapperScan:
@SpringBootApplication
@MapperScan("cn.sharry.mplearning.mapper")
public class MplearningApplication {
public static void main(String[] args) {
SpringApplication.run(MplearningApplication.class, args);
}
}
2.2.3 编写测试类
@Slf4j
@SpringBootTest
public class UserMapperTests {
@Autowired
private UserMapper userMapper;
/**
* 入门测试:测试查询用户列表
*/
@Test
public void testGetUserList(){
log.info("即将进行【Mybatis入门】测试,查询User列表:");
//queryWrapper : 条件构造器,当没有时我们用null
List<User> userList = userMapper.selectList(null);
//遍历集合
userList.forEach(System.out::println);
}
如果能正确输出用户列表,那么说明我们的入门配置与测试成功了!接下来我们来详细学习MP给我们带来的便捷的CRUD!
3. CRUD
在上面的小节中,我们进行了初步的入门配置与测试。接下来,我们稍微详细学习一下如何使用 Mybatis-Plus 进行CRUD。
3.1 条件构造器
在开始学习、练习CRUD之前,我们首先要了解一个概念:条件构造器。
在我们没有使用 Mybatis-Plus 时,我们写SQL常常要添加 where 条件判断。条件构造器则是在我们使用Mybatis-Plus,没有怎么手写where条件的情况下,就需要用条件构造器给我们生成一些条件。
在上面的入门案例中,我们使用IDEA测试时,可能会出现如下提示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TDsgjDaX-1671090850669)(E:\Working-Sida\PersonalNotes\NotesFromLearning\MybatisPlusLearning\images\wrapper-demo1.png)]
这里指的就是一个条件构造器。
通过官网以及参考资料我们了解到,在MP中,AbstractWrapper和AbstractChainWrapper是Wrapper接口的重点实现,因此接下来我们学习的重点为AbstractWrapper以及其⼦类。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gR9laJux-1671090850671)(E:\Working-Sida\PersonalNotes\NotesFromLearning\MybatisPlusLearning\images\wrapper-demo2.png)]
注:图片来源于参考资料——博客园优质文章
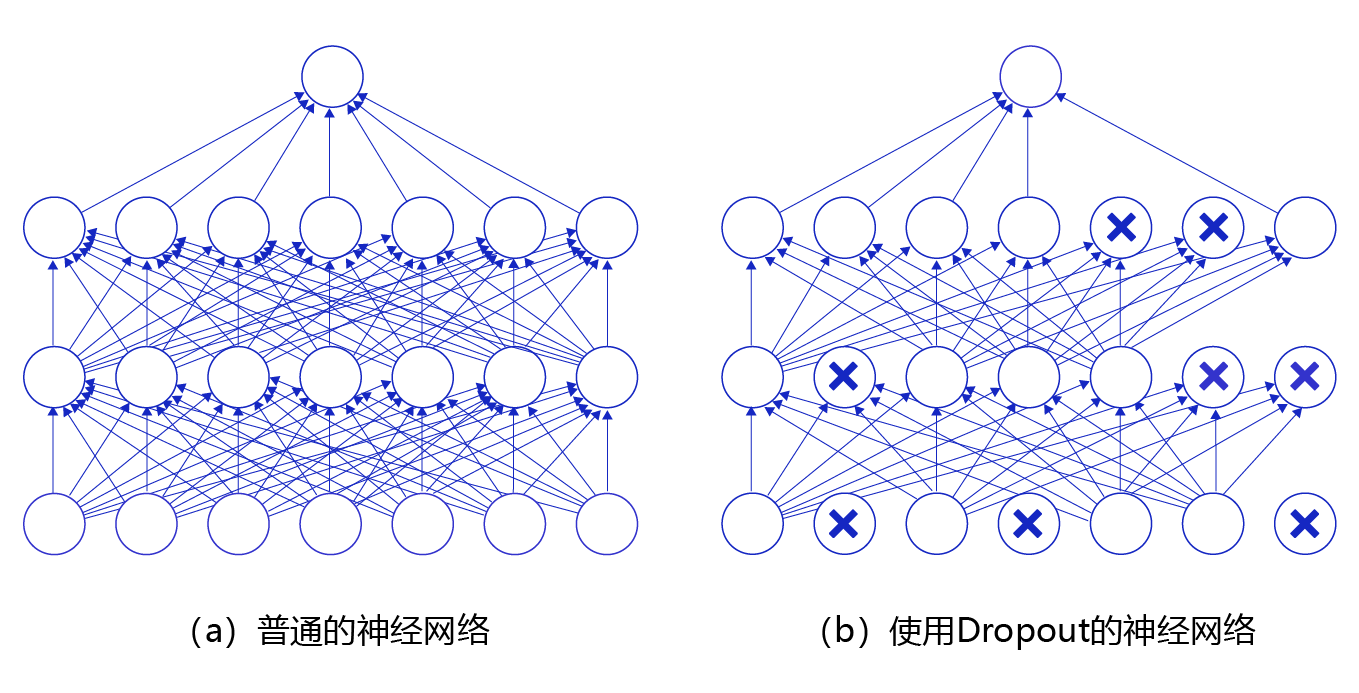
顺便附一张非常实用的图:
注:图片来源于网络,侵删。
3.1.1 AbstractWrapper
本小节列举一些 AbstractWrapper 常用的方法
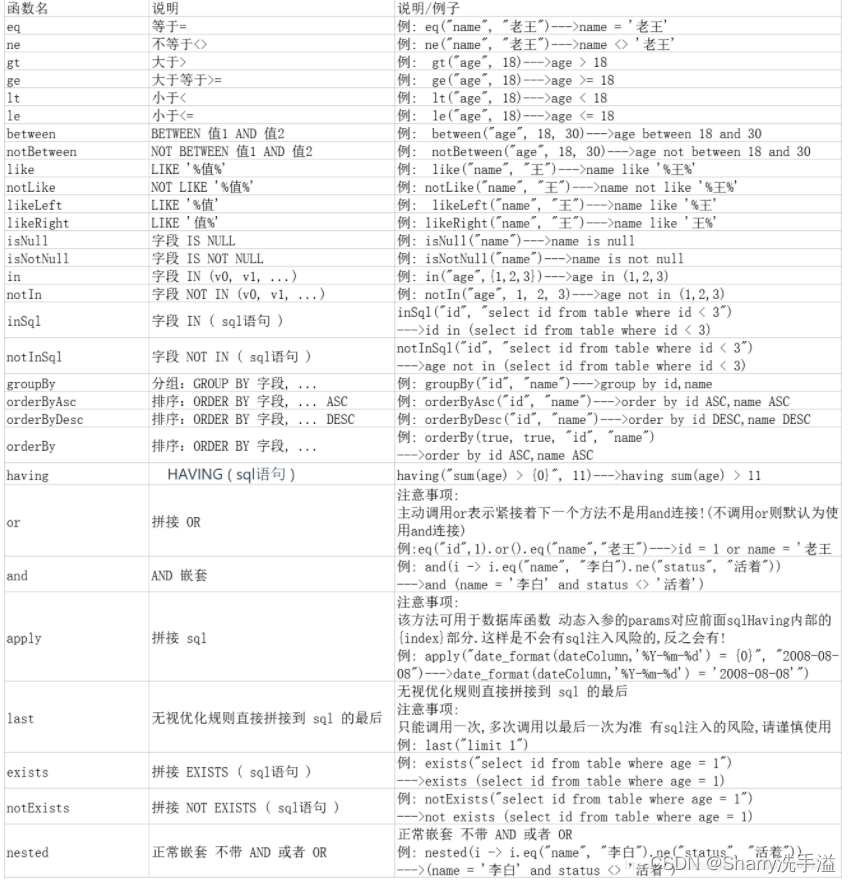
(1) 基本比较操作
基本比较操作
| 函数 | 说明 |
|---|---|
| eq | 等于 = |
| ne | 不等于 <> |
| gt | ⼤于 > |
| ge | ⼤于等于 >= |
| lt | ⼩于 < |
| le | ⼩于等于 <= |
| between | BETWEEN 值1 AND 值2 |
| notBetween | NOT BETWEEN 值1 AND 值2 |
| in | 字段 IN (value.get(0), value.get(1), …) |
| not In | 字段 NOT IN (v0, v1, …) |
代码示例
我们通过测试举例来入门 Wrapper 的一些基本实现方式
/**
* 基本比较操作,此处用2个方法举例
*/
@Test
public void testBasicCompare(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//WHERE email in(?,?,?) AND age >= 20
queryWrapper.in("email", "test1@baomidou.com","test2@baomidou.com","test3@baomidou.com")
.ge("age", 20);
List<User> userList = userMapper.selectList(queryWrapper);
for(User user : userList){
System.out.println(user);
}
(2) allEq
通过上面小节的学习,我们了解到eq代表“=”,那么 allEq 指的是全部eq(或个别isNull),以下是官网说明:
allEq(Map<R, V> params)
allEq(Map<R, V> params, boolean null2IsNull)
allEq(boolean condition, Map<R, V> params, boolean null2IsNull)
个别参数说明:
params : key为数据库字段名,value为字段值
null2IsNull : 为true则在map的value为null时调用 isNull 方法,为false时则忽略value为null的
例1: allEq({id:1,name:“老王”,age:null})—>id = 1 and name = ‘老王’ and age is null
例2: allEq({id:1,name:“老王”,age:null}, false)—>id = 1 and name = ‘老王’
代码示例
/**
* AllEq Wrapper 测试
*/
@Test
public void testAllEq(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//构建map
Map<String,Object> map = new HashMap<>();
map.put("name", "jack");
map.put("age", null);
//以下展开lambda表达式,方便初学者入门。
//queryWrapper.allEq((k,v) -> k.equals("name"),map);
BiPredicate<String,Object> filter = new BiPredicate<String, Object>() {
@Override
public boolean test(String s, Object o){
return s.equals("name");
}
};
queryWrapper.allEq(filter,map);
List<User> userList = userMapper.selectList(queryWrapper);
//遍历查看效果
for(User user : userList){
System.out.println(user);
}
}
通过上面的例子,可以看出MP Wrapper 使用 Lambda 会使语句简洁许多,我们在下面的代码示例会逐步引入一些Lambda表达式供各位复习。至于具体Wrapper+Lambda的使用方式,别急,我们在下面的章节讨论。
(3) 模糊查询
MP Wrapper 的模糊查询非常见名知意:
- like —> LIKE ‘%value%’
- not like —> NOT LIKE ‘%value%’
- likeLeft —> (百分号在左边) LIKE ‘%value’
- likeRight —> (百分号在右边) LIKE ‘value%’
代码示例
/**
* 模糊查询
*/
@Test
public void testSelectLike(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//WHERE name LIKE '%?%'
queryWrapper.likeLeft("name", "y");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
(4)分组查询、排序
分组查询和排序都是见名知意:groupBy、orderByAsc、orderByDesc;
需要稍微注意一下这几个方法都有哪些参数,官网可查。
上栗子
/**
* 排序
*/
@Test
public void testGroupAndOrder(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.orderByDesc("age");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
分组的例子,篇幅有限,请读者自行尝试。
(5)连接 or and
默认情况下,链式调用的 wrapper 是用and连接,当我们主动调用or时,表示用or连接
/**
* or 拼接
*/
@Test
public void testLink(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name","jack").or().eq("age",28).select("name");
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
}
剩余其它方法与例子,请读者自行查阅、尝试。
3.1.2 QueryWrapper
QueryWrapper 实现查询主要使用select 方法,我们直接举例子:
@Test
public void testWrappers(){
//QueryWrapper
QueryWrapper<User> qw = new QueryWrapper<>();
//SELECT id, name, age FROM user WHERE name = 'Jack';
qw.select("id","name","age").like("name","Jack" );
User userJack = userService.getOne(qw);
System.out.println("查询到的用户为"+userJack);
}
3.1.3 UpdateWrapper
UpdateWrapper 实现更新主要使用set方法,我们直接举例子:
@Test
public void testWrappers(){
//UpdateWrapper
UpdateWrapper<User> uw = new UpdateWrapper<>();
uw.set("age",35).like("name","Jack" );
//UPDATE user SET age = 35 WHERE name = 'Jack';
boolean isSuccess = userService.update(uw);
System.out.println("修改Jack的年龄是否成功:"+isSuccess);
}
基本的 Wrapper 用法大概如上。至于LambadaWrapper链式调用的方法,我们会在下文介绍。
3.2 Mapper CRUD 接口
我们学习Mapper CRUD接口的目的是了解MP 自带的CRUD 方法有哪些。至于具体调用,由于MP 是为了提高我们的效率而生,实际工作中,我们会通过 IService 调用这些已经写好的方法,而不必再像纯Mybatis的方式去注意CRUD。因此本小节的内容我们了解即可,用到再去查询。下面我们开始学习:
继承了 BaseMapper 的 Mapper 继承了基本的CRUD方法,具体我们可以通过源码以及官方文档了解,BaseMapper源码:
public interface BaseMapper<T> extends Mapper<T> {
int insert(T entity);
int deleteById(Serializable id);
int deleteByMap(@Param("cm") Map<String, Object> columnMap);
int delete(@Param("ew") Wrapper<T> queryWrapper);
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
int updateById(@Param("et") T entity);
int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
T selectById(Serializable id);
List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> idList);
List<T> selectByMap(@Param("cm") Map<String, Object> columnMap);
T selectOne(@Param("ew") Wrapper<T> queryWrapper);
Integer selectCount(@Param("ew") Wrapper<T> queryWrapper);
List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
List<Object> selectObjs(@Param("ew") Wrapper<T> queryWrapper);
<E extends IPage<T>> E selectPage(E page, @Param("ew") Wrapper<T> queryWrapper);
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param("ew") Wrapper<T> queryWrapper);
}
3.2.1 Insert
// 插入一条记录
int insert(T entity);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| T(泛型标记符Type,代表类型) | entity | 实体对象 |
代码举例
/**
* 测试新增用户
*/
@Test
public void testSaveUser(){
User user = new User();
user.setAge(19);
user.setEmail("sharrytesystem@162.com");
user.setId(6l);
user.setName("Sharry");
int insert = userMapper.insert(user);
log.debug("插入结果:影响行数{}", insert);
//遍历集合
listUser().forEach(System.out::println);
}
3.2.2 Delete
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper | wrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Serializable | id | 主键 ID |
| Map<String, Object> | columnMap | 表字段 map 对象 |
代码举例
/**
* 测试根据名字删除用户
*/
@Test
public void testDeleteUser(){
//Lambda 链式 Wrapper
int row = userMapper.delete(
Wrappers.<User>lambdaQuery()
.like(User::getName, "Sharry")
);
System.out.println(row);
}
3.2.3 Update
// 根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 (set 条件值,可为 null) |
| Wrapper | updateWrapper | 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) |
代码举例
/**
* 测试update
*/
@Test
public void testUpdate(){
User user = new User();
user.setEmail("Jack@123.com");
int isUpdated = userMapper.update(
user,
new LambdaQueryWrapper<User>().like(true, User::getName,"Jack")
);
System.out.println(isUpdated);
}
3.2.4 Select
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper | queryWrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| IPage | page | 分页查询条件(可以为 RowBounds.DEFAULT) |
代码举例
/**
* 查询数量
*/
@Test
public void testIPageMapper(){
int count = userMapper.selectCount(new LambdaQueryWrapper<User>().lt(User::getAge, 50));
System.out.println(count);
}
至此,MP 提供的Mapper接口已介绍完毕。
3.3 Service CRUD 接口
IService 源码:
public interface IService<T> {
int DEFAULT_BATCH_SIZE = 1000;
default boolean save(T entity) {
return SqlHelper.retBool(this.getBaseMapper().insert(entity));
}
@Transactional(
rollbackFor = {Exception.class}
)
default boolean saveBatch(Collection<T> entityList) {
return this.saveBatch(entityList, 1000);
}
boolean saveBatch(Collection<T> entityList, int batchSize);
@Transactional(
rollbackFor = {Exception.class}
)
default boolean saveOrUpdateBatch(Collection<T> entityList) {
return this.saveOrUpdateBatch(entityList, 1000);
}
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
default boolean removeById(Serializable id) {
return SqlHelper.retBool(this.getBaseMapper().deleteById(id));
}
default boolean removeByMap(Map<String, Object> columnMap) {
Assert.notEmpty(columnMap, "error: columnMap must not be empty", new Object[0]);
return SqlHelper.retBool(this.getBaseMapper().deleteByMap(columnMap));
}
default boolean remove(Wrapper<T> queryWrapper) {
return SqlHelper.retBool(this.getBaseMapper().delete(queryWrapper));
}
default boolean removeByIds(Collection<? extends Serializable> idList) {
return CollectionUtils.isEmpty(idList) ? false : SqlHelper.retBool(this.getBaseMapper().deleteBatchIds(idList));
}
default boolean updateById(T entity) {
return SqlHelper.retBool(this.getBaseMapper().updateById(entity));
}
default boolean update(Wrapper<T> updateWrapper) {
return this.update((Object)null, updateWrapper);
}
default boolean update(T entity, Wrapper<T> updateWrapper) {
return SqlHelper.retBool(this.getBaseMapper().update(entity, updateWrapper));
}
@Transactional(
rollbackFor = {Exception.class}
)
default boolean updateBatchById(Collection<T> entityList) {
return this.updateBatchById(entityList, 1000);
}
boolean updateBatchById(Collection<T> entityList, int batchSize);
boolean saveOrUpdate(T entity);
default T getById(Serializable id) {
return this.getBaseMapper().selectById(id);
}
default List<T> listByIds(Collection<? extends Serializable> idList) {
return this.getBaseMapper().selectBatchIds(idList);
}
default List<T> listByMap(Map<String, Object> columnMap) {
return this.getBaseMapper().selectByMap(columnMap);
}
default T getOne(Wrapper<T> queryWrapper) {
return this.getOne(queryWrapper, true);
}
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
Map<String, Object> getMap(Wrapper<T> queryWrapper);
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
default int count() {
return this.count(Wrappers.emptyWrapper());
}
default int count(Wrapper<T> queryWrapper) {
return SqlHelper.retCount(this.getBaseMapper().selectCount(queryWrapper));
}
default List<T> list(Wrapper<T> queryWrapper) {
return this.getBaseMapper().selectList(queryWrapper);
}
default List<T> list() {
return this.list(Wrappers.emptyWrapper());
}
default <E extends IPage<T>> E page(E page, Wrapper<T> queryWrapper) {
return this.getBaseMapper().selectPage(page, queryWrapper);
}
default <E extends IPage<T>> E page(E page) {
return this.page(page, Wrappers.emptyWrapper());
}
default List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper) {
return this.getBaseMapper().selectMaps(queryWrapper);
}
default List<Map<String, Object>> listMaps() {
return this.listMaps(Wrappers.emptyWrapper());
}
default List<Object> listObjs() {
return this.listObjs(Function.identity());
}
default <V> List<V> listObjs(Function<? super Object, V> mapper) {
return this.listObjs(Wrappers.emptyWrapper(), mapper);
}
default List<Object> listObjs(Wrapper<T> queryWrapper) {
return this.listObjs(queryWrapper, Function.identity());
}
default <V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper) {
return (List)this.getBaseMapper().selectObjs(queryWrapper).stream().filter(Objects::nonNull).map(mapper).collect(Collectors.toList());
}
default <E extends IPage<Map<String, Object>>> E pageMaps(E page, Wrapper<T> queryWrapper) {
return this.getBaseMapper().selectMapsPage(page, queryWrapper);
}
default <E extends IPage<Map<String, Object>>> E pageMaps(E page) {
return this.pageMaps(page, Wrappers.emptyWrapper());
}
BaseMapper<T> getBaseMapper();
Class<T> getEntityClass();
default QueryChainWrapper<T> query() {
return ChainWrappers.queryChain(this.getBaseMapper());
}
default LambdaQueryChainWrapper<T> lambdaQuery() {
return ChainWrappers.lambdaQueryChain(this.getBaseMapper());
}
default KtQueryChainWrapper<T> ktQuery() {
return ChainWrappers.ktQueryChain(this.getBaseMapper(), this.getEntityClass());
}
default KtUpdateChainWrapper<T> ktUpdate() {
return ChainWrappers.ktUpdateChain(this.getBaseMapper(), this.getEntityClass());
}
default UpdateChainWrapper<T> update() {
return ChainWrappers.updateChain(this.getBaseMapper());
}
default LambdaUpdateChainWrapper<T> lambdaUpdate() {
return ChainWrappers.lambdaUpdateChain(this.getBaseMapper());
}
default boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper) {
return this.update(entity, updateWrapper) || this.saveOrUpdate(entity);
}
}
从上面的源码我们可以得知,IService 提供了基本的CRUD方法,我们要使用这些方法,可以参考如下:
Service接口实现IService
/**
* User 服务Service接口
* @author: Sharry
* @createTime: 2022/12/13 10:00
* @version: Version-1.0
*/
public interface IUserService extends IService<User> {
}
ServiceImpl实现类继承ServiceImpl
/**
* User 服务实现类
* @author: Sharry
* @createTime: 2022/12/14 14:17
* @version: Version-1.0
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
}
接下来,我们就可以学习ServiceCRUD接口了。我们选取其中一些接口来举例、学习。
3.3.1 SaveOrUpdate
// TableId 注解存在更新记录,否插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
代码举例
/**
* saveOrUpdate
* 先判断是否已存在目标元素的主键,是:更新,否:插入
*/
@Test
public void testSaveOrUpdate(){
List<User> userList = new ArrayList<>();
//准备数据
User user1 = new User();
user1.setId(7L);
user1.setAge(55);
user1.setName("Kevin");
user1.setEmail("TestEmail@Email.com");
User user2 = userService.getOne(new LambdaQueryWrapper<User>().like(User::getName, "Jack"));
user2.setAge(33);
userList.add(user1);
userList.add(user2);
//更新或插入
boolean isSuccess = userService.saveOrUpdateBatch(userList);
System.out.println("更新或插入结果:"+isSuccess);
//查询看结果:
List<User> userList1 = userService.list();
userList1.forEach(System.out::println);
}
3.3.2 Remove
// 根据 entity 条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
代码举例
/**
* 测试移除 remove
*/
@Test
public void testRemove(){
System.out.println("是否移除成功:"+userService.removeById(7L));
List<User> userList = userService.list();
userList.forEach(System.out::println);
}
注意,实际工作中请使用逻辑删除!!! 具体逻辑删除使用方式,请参考官方文档。
3.3.3 Page
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
在使用分页之前,我们常常需要在配置类添加分页插件。这是因为,Mybatis 本身给我们提供的不是物理分页,Mybatis-Plus 通过插件给我们提供物理分页,在数据量大时,可以为我们节省开销。
代码举例
/**
* 测试MapPage分页 : 数据量少,每页2条,age>18 ,
*/
@Test
public void testMapPage(){
IPage<User> p = new Page<>(1,2);
IPage<User> userIPage = userService.page(p, new LambdaQueryWrapper<User>().gt(User::getAge, 18));
//输出信息
System.out.println("当前页"+userIPage.getCurrent());
System.out.println("当前页数据list集合:" + userIPage.getRecords());
System.out.println("每页显示记录数:" + userIPage.getSize());
System.out.println("总记录数:" + userIPage.getTotal());
System.out.println("总页数:" + userIPage.getPages());
}
3.3.4 Count
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);
代码举例
/**
* 测试统计 age>21 的 user
*/
@Test
public void testCountByAge(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 21);
System.out.println("age>21的user有:"+userService.count(queryWrapper));
}
3.4 ID 生成器
3.4.1 默认ID生成器
从MP 3.3.0 开始,默认使用雪花算法+UUID生成ID,举个例子:
/**
* 测试自带的ID生成器
*/
@Test
public void testIDGenerator(){
User user = new User();
user.setEmail("123456789@789.com");
user.setName("观察这个user的ID");
user.setAge(100);
//插入,并观察
userService.save(user);
System.out.println(
userService.getOne(
new LambdaQueryWrapper<User>().select(User::getId, User::getName)
.eq(User::getName, "观察这个user的ID")
)
);
}
雪花算法+UUID 的具体实现,篇幅有限,本文不赘述。
3.4.2 自定义ID生成器
参考官网的教程
3.5 Lambda Wrapper
LambdaQueryWrapper、LambdaUpdateWrapper 是实现了 AbstractLambdaWrapper 的两个实现类 ,结合链式Lambda表达式,大大提高开发效率。
3.5.1 LambdaQueryWrapper
源码
public class LambdaQueryWrapper<T> extends AbstractLambdaWrapper<T, LambdaQueryWrapper<T>> implements Query<LambdaQueryWrapper<T>, T, SFunction<T, ?>> {
private SharedString sqlSelect;
public LambdaQueryWrapper() {
this((Object)null);
}
public LambdaQueryWrapper(T entity) {
this.sqlSelect = new SharedString();
super.setEntity(entity);
super.initNeed();
}
public LambdaQueryWrapper(Class<T> entityClass) {
this.sqlSelect = new SharedString();
super.setEntityClass(entityClass);
super.initNeed();
}
LambdaQueryWrapper(T entity, Class<T> entityClass, SharedString sqlSelect, AtomicInteger paramNameSeq, Map<String, Object> paramNameValuePairs, MergeSegments mergeSegments, SharedString lastSql, SharedString sqlComment, SharedString sqlFirst) {
this.sqlSelect = new SharedString();
super.setEntity(entity);
super.setEntityClass(entityClass);
this.paramNameSeq = paramNameSeq;
this.paramNameValuePairs = paramNameValuePairs;
this.expression = mergeSegments;
this.sqlSelect = sqlSelect;
this.lastSql = lastSql;
this.sqlComment = sqlComment;
this.sqlFirst = sqlFirst;
}
@SafeVarargs
public final LambdaQueryWrapper<T> select(SFunction<T, ?>... columns) {
if (ArrayUtils.isNotEmpty(columns)) {
this.sqlSelect.setStringValue(this.columnsToString(false, columns));
}
return (LambdaQueryWrapper)this.typedThis;
}
public LambdaQueryWrapper<T> select(Class<T> entityClass, Predicate<TableFieldInfo> predicate) {
if (entityClass == null) {
entityClass = this.getEntityClass();
} else {
this.setEntityClass(entityClass);
}
Assert.notNull(entityClass, "entityClass can not be null", new Object[0]);
this.sqlSelect.setStringValue(TableInfoHelper.getTableInfo(entityClass).chooseSelect(predicate));
return (LambdaQueryWrapper)this.typedThis;
}
public String getSqlSelect() {
return this.sqlSelect.getStringValue();
}
protected LambdaQueryWrapper<T> instance() {
return new LambdaQueryWrapper(this.getEntity(), this.getEntityClass(), (SharedString)null, this.paramNameSeq, this.paramNameValuePairs, new MergeSegments(), SharedString.emptyString(), SharedString.emptyString(), SharedString.emptyString());
}
public void clear() {
super.clear();
this.sqlSelect.toNull();
}
}
代码举例
/**
* 测试根据 lambda 查询名字为 age < 28 的用户
*/
@Test
public void testSelectByName(){
//链式查询: SELECT id,name,phone,email FROM user WHERE age = < 28
Integer age = 28;
List<User> userList = userService.list(Wrappers.<User>lambdaQuery().lt(User::getAge,age));
//遍历结果
userList.forEach(System.out::println);
}
/**
* 测试根据 lambda 查询 名字带有J 或 S 的用户信息
*/
@Test
public void testSelectLambdaLike(){
//链式查询: SELECT id,name,phone,email FROM user WHERE name LIKE '%J%' OR name LIKE '%S%'
List<User> userList = userService.list(new LambdaQueryWrapper<User>()
.like(User::getName, "J").or().like(User::getName, "S"));
//遍历
userList.forEach(System.out::println);
}
3.5.2 LambdaUpdateWrapper
源码
public class LambdaUpdateWrapper<T> extends AbstractLambdaWrapper<T, LambdaUpdateWrapper<T>> implements Update<LambdaUpdateWrapper<T>, SFunction<T, ?>> {
private final List<String> sqlSet;
public LambdaUpdateWrapper() {
this((Object)null);
}
public LambdaUpdateWrapper(T entity) {
super.setEntity(entity);
super.initNeed();
this.sqlSet = new ArrayList();
}
public LambdaUpdateWrapper(Class<T> entityClass) {
super.setEntityClass(entityClass);
super.initNeed();
this.sqlSet = new ArrayList();
}
LambdaUpdateWrapper(T entity, Class<T> entityClass, List<String> sqlSet, AtomicInteger paramNameSeq, Map<String, Object> paramNameValuePairs, MergeSegments mergeSegments, SharedString lastSql, SharedString sqlComment, SharedString sqlFirst) {
super.setEntity(entity);
super.setEntityClass(entityClass);
this.sqlSet = sqlSet;
this.paramNameSeq = paramNameSeq;
this.paramNameValuePairs = paramNameValuePairs;
this.expression = mergeSegments;
this.lastSql = lastSql;
this.sqlComment = sqlComment;
this.sqlFirst = sqlFirst;
}
public LambdaUpdateWrapper<T> set(boolean condition, SFunction<T, ?> column, Object val) {
if (condition) {
this.sqlSet.add(String.format("%s=%s", this.columnToString(column), this.formatSql("{0}", new Object[]{val})));
}
return (LambdaUpdateWrapper)this.typedThis;
}
public LambdaUpdateWrapper<T> setSql(boolean condition, String sql) {
if (condition && StringUtils.isNotBlank(sql)) {
this.sqlSet.add(sql);
}
return (LambdaUpdateWrapper)this.typedThis;
}
public String getSqlSet() {
return CollectionUtils.isEmpty(this.sqlSet) ? null : String.join(",", this.sqlSet);
}
protected LambdaUpdateWrapper<T> instance() {
return new LambdaUpdateWrapper(this.getEntity(), this.getEntityClass(), (List)null, this.paramNameSeq, this.paramNameValuePairs, new MergeSegments(), SharedString.emptyString(), SharedString.emptyString(), SharedString.emptyString());
}
public void clear() {
super.clear();
this.sqlSet.clear();
}
}
代码举例
/**
* 测试将Jack 的邮箱修改为older@baomidou.com
*/
@Test
public void testUpdateByName(){
//目标邮箱
String name = "Jack";
String target = "Jack@baomidou.com";
// UPDATE user SET email = ? WHERE name = ?
boolean isSuccess = userService.update(Wrappers.<User>lambdaUpdate()
.eq(User::getName, name).set(!target.equals(""), User::getEmail, "older@baomidou.com")
);
System.out.println(isSuccess);
//查询Jack的信息 : SELECT * FROM user WHERE name = ?
User user = userService.getOne(new LambdaQueryWrapper<User>().eq(User::getName, name));
System.out.println(user);
}
4. 连表查询
4.1 MP的连表解决方案
参考文章连接
或百度搜索。
4.2 Mybatis连表
Mybatis-Plus 只做增强,不做改变,因此我们可以直接使用Mybatis的连表方式,也就是使用*Mapper.xml 。
接下来我们试一试:
创建测试表

然后根据个人喜好,插入一些数据,此处就不做演示。然后,我们就可以根据 Mybatis 的连表方式进行连表查询:
编辑实体类
/**
* UserScoreVO
* @author: Sharry
* @createTime: 2022/12/15 15:05
* @version: Version-1.0
*/
@Data
public class UserScoreVO implements Serializable {
/**用户名称*/
private String name;
/**用户年龄*/
private Integer age;
/**用户分数*/
private Integer score;
}
/**
* 分数实体类
*
* @author: Sharry
* @createTime: 2022/12/15 15:05
* @version: Version-1.0
*/
@Data
public class Score implements Serializable {
private Long id;
private Long userId;
private Integer score;
}
编写抽象方法
/**
* 根据用户Id查询分数
* @param userId 用户id
* @return 用户分数VO
*/
UserScoreVO selectScoreById(Long userId);
编辑Mapper.xml文件
<!-- 根据用户Id查询分数 -->
<select id="selectScoreById" resultMap="TestLinkTableRM">
SELECT u.name, u.age, s.score
FROM user u
LEFT JOIN score s on u.id = s.user_id
WHERE user_id = #{id}
</select>
<resultMap id="TestLinkTableRM" type="cn.sharry.mplearning.pojo.vo.UserScoreVO">
<result column="name" property="name"></result>
<result column="age" property="age"></result>
<result column="score" property="score"></result>
</resultMap>
编辑并执行测试方法
/**
* 测试连表查询
*/
@Test
public void testLinkTable(){
System.out.println(userMapper.selectScoreById(2L));
}
至此,我们用传统的 Mybatis 实现方式实现了最基本的连表查询。至此,Mybatis-Plus 最基本的使用方式已介绍完毕。接下来就是多加练习、运用、查找并尝试一些拓展、高级用法,让我们共同进步。
5. 总结
学习Mybatis-Plus,我们首先要有 SQL、Mybatis 基础,并借助Maven工程来练习。
在学习的过程中,我们不难发现,学习并使用 Wrapper 是 Mybatis-Plus 的一个重点,MP使用面向对象的方式让我们做持久层操作更方便。而在工作中,链式的Lambda Wrapper给我们提供了更大的便捷。
Mybatis-Plus 的优点是大大增强了开发效率。基本的CRUD不需要我们手写,因此在阅读源码时,具体执行了什么,需要借助进一步的阅读源码、阅读日志、查询文档。
本文为小编对着官方文档和参考资料学习MP,进行进一步总结的入门级 Mybatis-Plus 笔记。至于一些拓展、高级用法,请读者查询官方文档以及其它教程。
总的来说,当你某一天开始用 Mybatis-Plus 代替传统的 Mybatis.xml 进行开发时,或许会有和我一样的感受:“哎,真香!”。