今天我们学习并发编程中另一个重要的关键字volatile,虽然面试中它的占比低于synchronized,但依旧是不可忽略的内容。
关于volatile,我收集到了8个常见考点,围绕应用,特点和实现原理。
- volatile有什么作用?
- 为什么多线程环境中会出现可见性问题?
- synchronized和volatile有哪些区别?
- 详细描述volatile的实现原理(涉及内存屏障)。
- volatile有哪些特性?它是如何保证这些特性的?
- volatile保证线程间变量的可见性,是否意味着volatile变量就是并发安全的?
- 为什么方法中的变量不需要使用volatile?
- 重排序是如何产生的?
本文从volatile应用开始,接着从源码角度分析volatile的实现,通过对原理的剖析尝试解答以上问题。
volatile是什么
同synchronized一样,volatile是Java的提供的用于并发控制的关键字,不过它们之间也有比较明显的差异。
首先是使用方式:
- synchronized能够修饰方法和代码块
- volatile只能修饰成员变量
能力上volatile也更“弱”一些:
- 保证被修饰变量的可见性
- 禁止被修饰变量发生指令重排
我们稍微修改关于线程你必须知道的8个问题(上)中可见性问题的代码,使用volatile修饰变量flag:
private static volatile boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (flag) {}
System.out.println("线程:" + Thread.currentThread().getName() + ",flag状态:" + flag);
}, "block_thread").start();
TimeUnit.MICROSECONDS.sleep(500);
new Thread(() -> {
flag = false;
System.out.println("线程:" + Thread.currentThread().getName() + ",flag状态:" + flag);
}, "change_thread").start();
}不难发现,block_thread解脱了,说明对flag的修改被其它线程“看见了”,这就是volatile保证可见性的表现。
接着修改深入理解JMM和Happens-Before中指令重排带来有序性问题的代码,同样使用volatile修饰变量instance:
public class Singleton {
static volatile Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}多次实验后发现,不会再获取到未经初始化的instacne对象了,这就是volatile禁止指令重排的表现。
Tips:再次强调,Happens-Before描述的是行为结果间的关系。
volatile的实现
以下内容基于JDK 11 HotSpot虚拟机,以X86架构的实现为主,会与ARM架构的实现对比。选择这些的原因很简单,它们是各自领域的“顶流”。
volatile使用简单,功能易理解,但往往简单的背后隐藏着复杂的实现。和分析synchronized的过程一样,从字节码开始,再到JVM的实现,力求从底层串联volatile,内存屏障与硬件之间的关系。
volatile在不同架构下的实现差异较大,看个例子,X86架构的templateTable_x86__中getfield_or_static方法的实现:
void TemplateTable::getfield_or_static(int byte_no, bool is_static, RewriteControl rc) {
// 省略类型判断的代码
__ bind(Done);
// [jk] not needed currently
// volatile_barrier(Assembler::Membar_mask_bits(Assembler::LoadLoad | Assembler::LoadStore));
}ARM架构的templateTable_arm__中getfield_or_static方法的实现:
void TemplateTable::getfield_or_static(int byte_no, bool is_static, RewriteControl rc) {
// 省略类型判断的代码
__ bind(Done);
if (gen_volatile_check) {
Label notVolatile;
__ tbz(Rflagsav, ConstantPoolCacheEntry::is_volatile_shift, notVolatile);
volatile_barrier(MacroAssembler::Membar_mask_bits(MacroAssembler::LoadLoad | MacroAssembler::LoadStore), Rtemp);
__ bind(notVolatile);
}
}X86架构下不需要对volatile类型进行特殊处理,而ARM架构下,添加内存屏障保证了与X86架构一致的效果。这个例子是为了展示规范在不同CPU架构上的实现差异,另外提醒大家不要误将X86的实现当成标准,X86架构对重排序的约束更强,能“天然”实现JMM规范中的某些要求,所以JVM层面的实现看起来会非常简单。
上面一直在说模板解释器,不过后面的内容我要用字节码解释器bytecodeInterpreter了。为什么不用模板解释器?因为模板解释器离OrderAccess太“远”了,而OrderAccess中内存屏障的详细解释是理解volatile原理的关键。
不过,我们还是先花点时间了解下X86架构下内存屏障assembler_x86的实现:
enum Membar_mask_bits {
StoreStore = 1 << 3,
LoadStore = 1 << 2,
StoreLoad = 1 << 1,
LoadLoad = 1 << 0
};
void membar(Membar_mask_bits order_constraint) {
if (os::is_MP()) {
if (order_constraint & StoreLoad) {
int offset = -VM_Version::L1_line_size();
if (offset < -128) {
offset = -128;
}
lock();
addl(Address(rsp, offset), 0);
}
}
}使用位掩码定义内存屏障的枚举,分析偏向锁的时候就见到过位掩码的使用,重点在membar方法中最后两行代码:
lock();
addl(Address(rsp, offset), 0);插入了lock addl指令,它是X86架构下内存屏障实现的关键,orderAccess_linux_x86中的实现也是如此。
Tips:membar方法是Memory Barrier(内存屏障)的缩写,另外也有称为Memory Fence(内存栅栏)的,或者直接称为fence,反正屏障,栅栏什么的乱七八糟的。
从字节码开始
使用双检锁单例模式生成的字节码:
public class com.wyz.keyword.keyword_volatile.Singleton
static volatile com.wyz.keyword.keyword_volatile.Singleton instance;
flags:(0x0048) ACC_STATIC, ACC_VOLATILE
public static com.wyz.keyword.keyword_volatile.Singleton getInstance();
Code:
stack=2, locals=2, args_size=0
24: putstatic #7 // Field instance:Lcom/wyz/keyword/keyword_volatile/Singleton;
37: getstatic #7 // Field instance:Lcom/wyz/keyword/keyword_volatile/Singleton;我们看字节码中的关键部分:
- 标记volatile变量的ACC_VOLATILE;
- 写入/读取静态变量时的指令getstatic和putstatic。
Java 11虚拟机规范第4章中是这样描述ACC_VOLATILE的:
ACC_STATIC 0x0008 Declared static. ACC_VOLATILE 0x0040 Declared volatile; cannot be cached.
虚拟机规范要求被volatile修饰的变量不能被缓存。我们知道,CPU高速缓存是带来可见性问题的“罪魁祸首”,不能被缓存就意味着杜绝了可见性问题,但并不意味着不使用缓存。
Java 11虚拟机规范第6章中也描述了getstatic指令的作用:
Get static field from class.
putstatic指令的作用:
Set static field in class.
可以大致猜到JVM的实现volatile的方式,JVM中定义getstatic/putstatic指令对应的方法,并在方法中判断变量是否被标记为ACC_VOLATILE,然后进行特殊逻辑处理。
Tips:
- 0x0048是ACC_STATIC和ACC_VOLATILE结合的结果;
- 非static变量,读取和写入是getfield和putfield两条指令。
字节码解释器的实现
这部分我们只看putstatic的源码,前面模板解释器的部分也大致分析了getstatic,剩下的就留给大家自行分析了。
putstatic的实现在bytecodeInterpreter中第2026行:
CASE(_putfield):
CASE(_putstatic):
{
if ((Bytecodes::Code)opcode == Bytecodes::_putstatic) {
// static的处理方式
} else {
// 非static的处理方式
}
// ACC_VOLATILE -> JVM_ACC_VOLATILE -> is_volatile()
if (cache->is_volatile()) {
// volatile变量的处理方式
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
}else {
// 省略了超多的类型判断
}
OrderAccess::storeload();
} else {
// 非volatile变量的处理方式
}
}逻辑很简单,判断变量的类型,然后调用OrderAccess::storeload(),保证volatile变量的特性实现。
JVM的内存屏障
JVM在不同操作系统,CPU架构的基础上,构建了一套符合JMM规范的内存屏障,屏蔽了不同架构间的差异,实现了内存屏障的语义一致性。这部分重点解释JVM实现的4种主要内存屏障和介绍X86架构的实现以及硬件差异导致的不同。
来看orderAccess中对4种内存屏障的解释:
Memory Access Ordering Model
LoadLoad: Load1(s); LoadLoad; Load2
Ensures that Load1 completes (obtains the value it loads from memory) before Load2 and any subsequent load operations. Loads before Load1 may not float below Load2 and any subsequent load operations.
StoreStore: Store1(s); StoreStore; Store2
Ensures that Store1 completes (the effect on memory of Store1 is made visible to other processors) before Store2 and any subsequent store operations. Stores before Store1 may not float below Store2 and any subsequent store operations.
LoadStore: Load1(s); LoadStore; Store2
Ensures that Load1 completes before Store2 and any subsequent store operations. Loads before Load1 may not float below Store2 and any subsequent store operations.
StoreLoad: Store1(s); StoreLoad; Load2
Ensures that Store1 completes before Load2 and any subsequent load operations. Stores before Store1 may not float below Load2 and any subsequent load operations.
努力翻译下对4种主要的内存屏障的描述:
- LoadLoad,指令:Load1;LoadLoad;Load2。确保Load1在Load2及之后的读操作前完成读操作,Load1前的Load指令不能重排序到Load2及之后的读操作后;
- StoreStore,指令:Store1;StoreStore;Store2。确保Store1在Store2及之后的写操作前完成写操作,且Stroe1写操作的结果对Store2可见,Store1前的Store指令不能重排序到Store2及之后的写操作后;
- LoadStore,指令:Load1;LoadStore;Store2。确保Load1在Store2及之后的写操作前完成读操作,Load1前的Load指令不能重排序到Store2及之后的写操作后;
- StoreLoad:指令:Store1;StoreLoad;Load2。确保Store1在Load2及之后的Load指令前完成写操作,Store1前的Store指令不能重排序到Load2及之后的Load指令后。
虽然翻译过来有些拗口,但理解起来并不困难,建议小伙伴们认真阅读这部分注释(包括后面的内容)。
注释中可以看出,内存屏障保证了程序的有序性。
X86架构的内存屏障实现
Linux平台X86架构的实现orderAccess_linux_x86中对内存屏障的定义:
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }实现非常简单,只有两个核心方法compiler_barrier和fence:
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}上述代码是GCC的扩展内联汇编形式,简单解释下compiler_barrier方法中的内容:
- asm,插入汇编指令;
- volatile,禁止优化此处的汇编指令;
- meomory,汇编指令修改了内存,要重新读取内存数据。
接着是支撑storeload屏障的fence方法,和templateTable_x86的实现一样,核心是lock addl指令。lock前缀指令可以理解为CPU指令级的锁,对总线和缓存加锁,主要有两个作用:
- Lock前缀指令会引起处理器缓存回写到内存
- 处理器缓存回写到内存会导致其他处理器的缓存无效
实际上X86架构提供了内存屏障指令lfence,sfence,mfence等,但为什么不使用内存屏障指令呢?原因在fence的注释中:
mfence is sometimes expensive
即mfence指令在性能上的开销较大。好了,到这里我们已经能够得到X86架构下实现volatile特性的原理:
- JVM的角度看,内存屏障提供了可见性和有序性的保证;
- X86的角度看,voaltile指令禁止重排序,Lock指令引起缓存失效和回写。
Tips:fence方法中AMD64和X86的处理略有差异,关于它们的渊源,可以参考pansz大佬的知乎。
其他架构实现差异的原因
前面看到,X86架构和ARM架构的模板解释器中,getfield_or_static方法在使用内存屏障上产生了分歧,ARM通过内存屏障到达了“罗马”,而X86出生在“罗马”。
不难想到产生这种差异的原因,CPU架构对重排序的约束不同,导致JVM需要使用不同的处理方式达到统一的效果。关于CPU允许的重排序,我“搬运”了一张图:
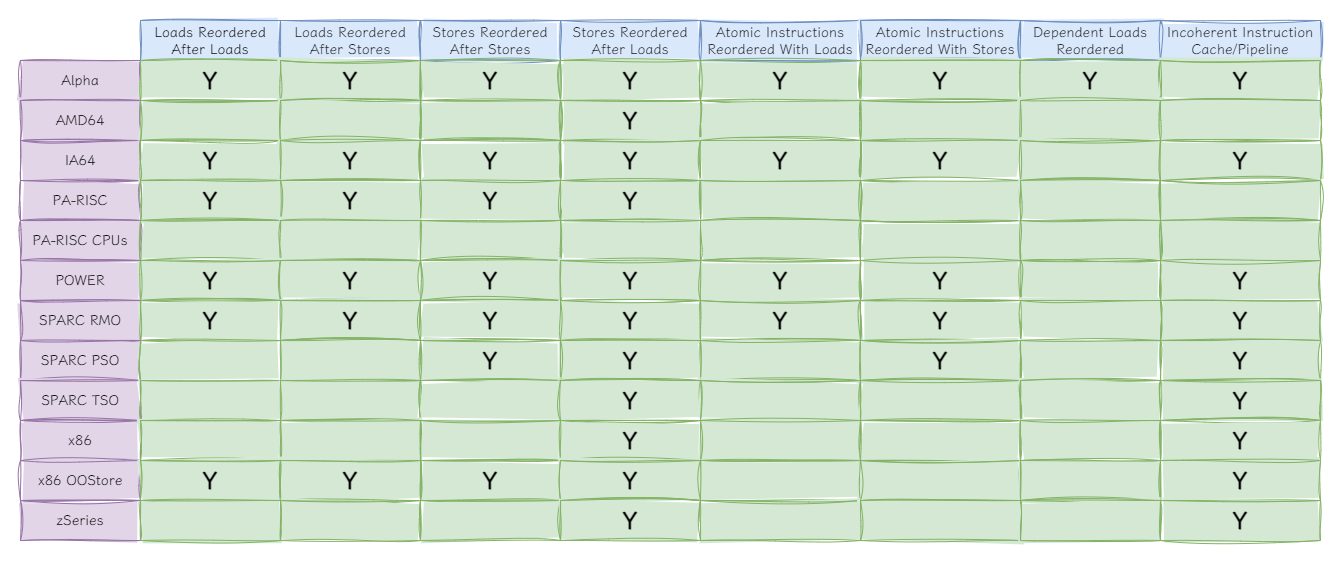
该图来自介绍CPU缓存与内存屏障的经典文章《Memory Barriers:a Hardware View for Software Hackers》,虽然年代较为“久远”,但依旧值得阅读。原图中列标题是竖向,看起来并不方便,所以进行了简单的“视觉优化”。
从图中也可以看到,X86架构只允许“Stores Reordered After Loads”重排序,因此JVM中只对storeload进行了实现,至于其它屏障的特性则是由CPU自己保证的。
结语
volatile的内容太难写了,特性不难,源码也不难,但是讲内存屏障非常难。
说少了难以理解,说多了就“越界”,就成了写硬件的文章。因此在写硬件实现差异的策略是桌面端最常用的X86架构为主,并对比移动端最常用ARM架构的实现,尽量简短的解释volatile的实现。
实际上,内存屏障的部分还有acquire和release两种单向屏障没有涉及到,大家可以自行了解。
那么,现在回到开始的题目中,相信你能够轻松的回答出前6道题目了吧?
如果本文对你有帮助的话,还请多多点赞支持。如果文章中出现任何错误,还请批评指正。最后欢迎大家关注分享硬核Java技术的金融摸鱼侠王有志,我们下次再见!