性能测试之CPU分析
- 一、回顾:性能测试分析的思路
- 二、cpu知识
- 1、影响cpu性能的物理因素:架构、主频、核
- 2、结构:主要物理结构是3个,实际是有4个
- 3、内存
- 说人话(总结)
- 4、内核&线程&架构
- 5、查看cpu信息
- 1、`top`
- 2、`lscpu`
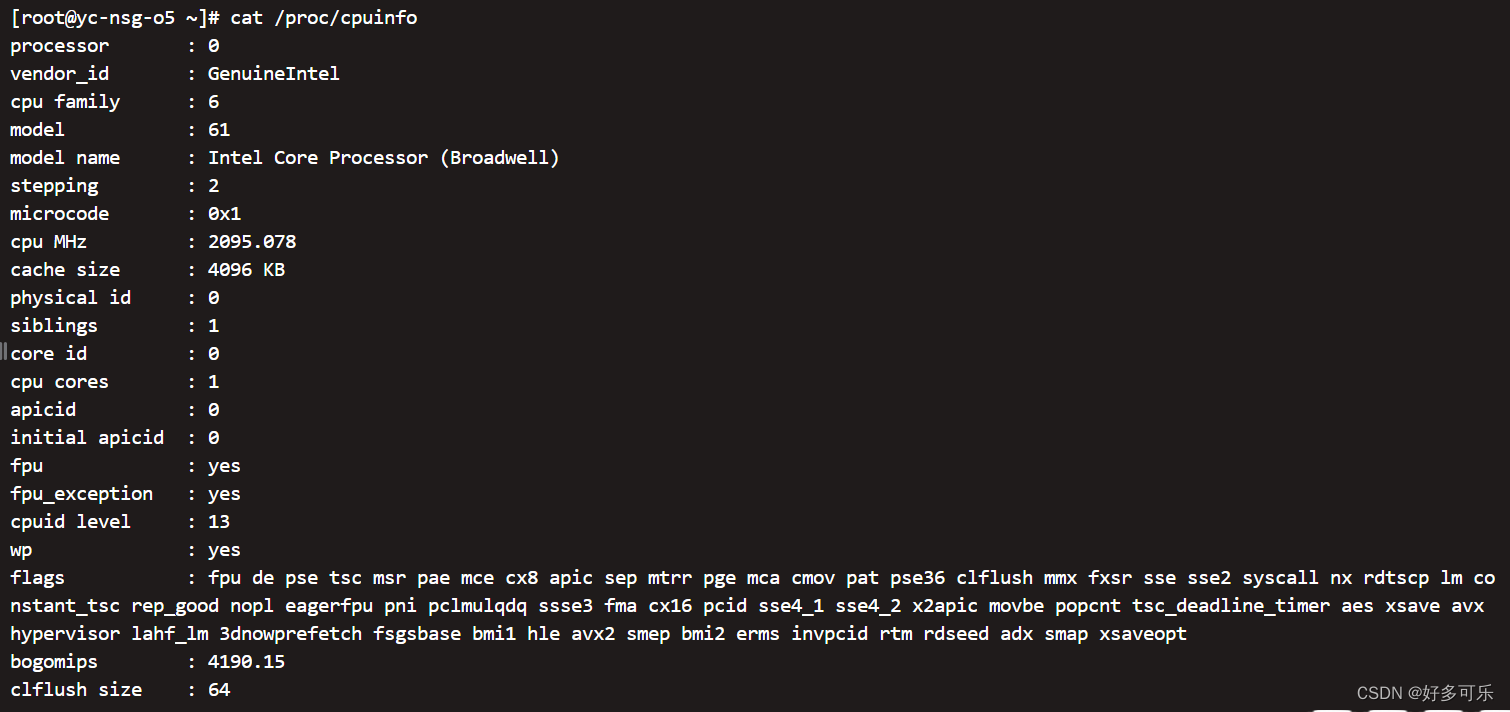
- 3、`cat /proc/cpuinfo`
- 6、监控cpu
- cpu 分析:
- load average值和cpu使用率之间的关系
- 上下文
- cpu性能分析:load高 && cpu高
- 做性能测试时候每次的结果都相差很大/不准,怎么分析?
一、回顾:性能测试分析的思路
- 性能测试分析的思路:先分析硬件 、网络、 系统配置、应用程序
- 硬件: cpu、内存、磁盘、网络、io
- 本次我们就来谈谈cpu
二、cpu知识
-
cpu:中央处理器(central processing unit)
-
1、影响cpu性能的物理因素:架构、主频、核
- 架构:intel(x86),AMD(powerPC),ARM(ARM)
- 主频:GHz(值越高每秒刷新速度越快)
- 核心数:
-
2、结构:主要物理结构是3个,实际是有4个
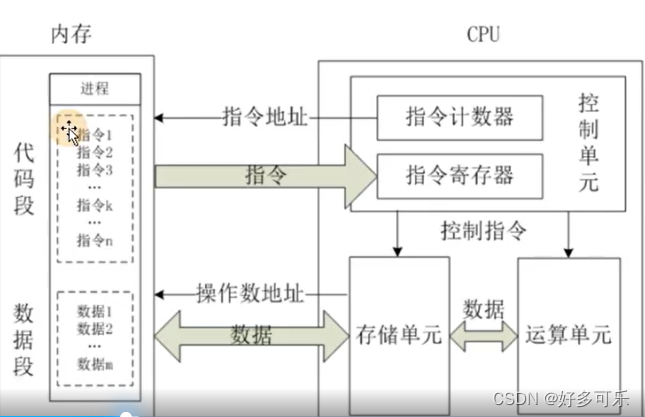
- 运算器: 真正进行计算的单元
- 控制器: leader,把内存的指令,数据读入寄存器,控制计算机
- 寄存器: 暂存指令、数据、地址
- 时钟:计时
-
3、内存
- 程序代码、网络数据,外部数据进入cpu的桥梁,内存的速度,要比cpu的速度慢
-
说人话(总结)
一段程序要被执行,先编译成机器语言,进入内存。cpu控制器再从内存中获取指令,数据,放入寄存器中。时钟控制cpu的运算器什么时候开始计算,计算多久。运算器开始计算。运算过程中,如果还需要数据,控制器就从寄存器中拿数据,拿不到就从内存中拿。如果1个时间片段计算不完,就先干其他事,之后再执行。执行完了,输出数据给寄存器,传给内存–> 切换,中断
-
4、内核&线程&架构
- 内核:医院的医生,治疗病人
- 线程:医院的护士,接待病人
- 线程是cpu调度和反派的基本单位
- 1医生对1护士:单核单线程
- 1医生对 n个护士:单核多线程,超频
- 如何配置超频?
- 需要手动改配置参数
- 一般情况下企业都不会使用超频,超频就代表超负荷运行,发热过快,功耗高的时候容易出问题
- 如何配置超频?
- 架构:医院的楼层结构和医疗基础设施
- 基础越合理,工作效率越高
-
5、查看cpu信息
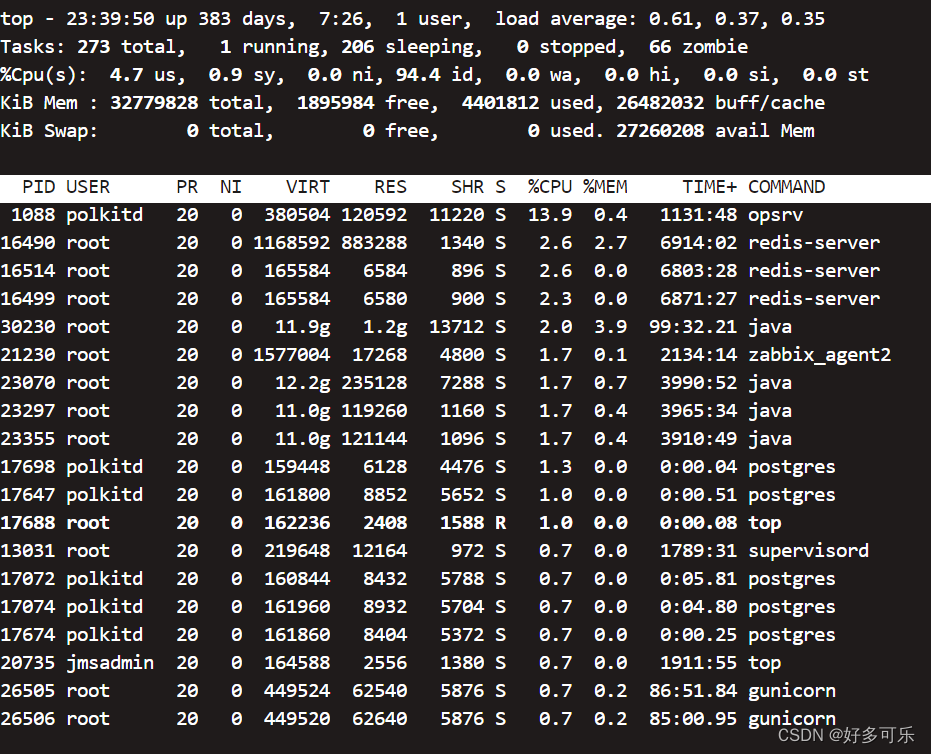
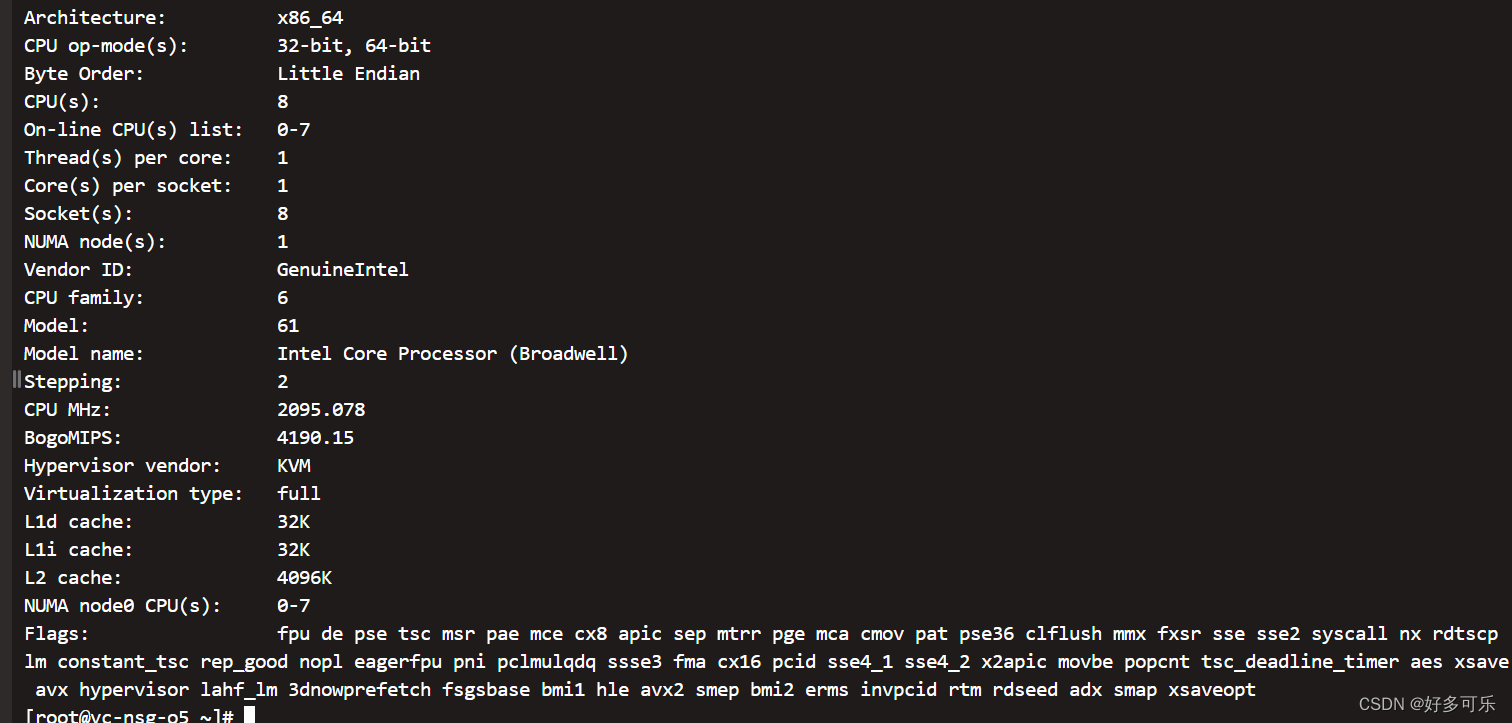
-
其他的常用命令
-
cat /proc/cpuinfo |grep "physical id" |sort |uniq |wc -l查看物理cpu数量 -
cat /proc/cpuinfo | grep "cpu cores" |uniq查看CPU的core数,即核数 -
cat /proc/cpuinfo | grep "processor" |wc -l查看逻辑CPU数量 -
load average = cpuload + ioload
-
-
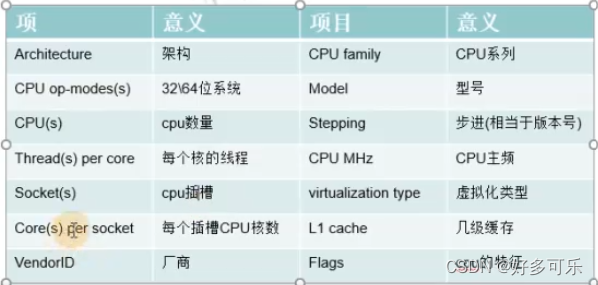
-
6、监控cpu
-
cpu 分析:
- us:用户进程空间中未改变过优先级的进程占用cpu百分比(程序在cpu进行计算的时候,没有改变过优先级,没有成为内核进行计算,在非内核计算的时间)
- 用户运行计算–>cpu密集计算 or FGC or 死循环
- cpu密集计算:代码逻辑很复杂,可能计算时候要进行密集的逻辑判断,这时候会消耗us态的时间
- FGC:
- GC:资源回收
- FGC:对老年代的资源进行回收。程序运行起来会分配内存资源,如果资源一直用的上,那就一直放在内存里,然后不用了再进行回收。这种回收消耗时间较长。资源回收就会带来中断和卡顿,卡顿也会导致程序暂时无响应(卡顿时间是毫秒级)
- YGC:(Young/Minor GC)新生代资源回收:资源用一次就不用了,把资源释放
- 死循环:一直在计算,用户态死循环就会占用很长时间
- 用户运行计算–>cpu密集计算 or FGC or 死循环
- sy:内核空间占用cpu百分比。
- 做上下文切换(自愿上下文切换,非自愿上下文切换)
- 上下文切换:寄存器里的资源进行切换
- 自愿上下文切换 --> 内存瓶颈
- 举例:比如进行计算时候,有10个程序,第一个程序有连续5个指令,但是在执行第三个指令的时候因为资源不够,要等待,那就切换其他进程处理其他指令。(资源不够,自觉切换到另外的指令)
- 非自愿上下文切换 -->cpu瓶颈
- 举例:执行第三个指令的时候,时间到了,这时候没有执行完,被迫中断/时间有,但是来了个优先级更高的,要立刻执行,强制中断。如果cpu够多,那就可以用另外的cpu去处理,所以是cpu瓶颈(有可能有优先级更高的指令,指令执行的时间已经到了,被迫中止当前的指令,去执行其他指令)
- 做上下文切换(自愿上下文切换,非自愿上下文切换)
- ni:用户进程空间内改变过优先级的进程占用cpu百分比(内核->非内核,或非内核->内核切换所用时间)
- 用户运行计算–>cpu密集计算 or FGC or 死循环
- id:空闲时间百分比
- wa:空闲&等待IO的时间百分比(很多时候是资源不够导致的等待)
- 等待资源 --> IO问题(磁盘/网络)
- hi:硬中断时间百分比(程序中断导致的切换(比如时间片到了))
- si:软中断时间百分比(自愿进行切换)
- 软中断 -->cpu竞争抢资源 or 资源不够IO问题
- st:虚拟化时被其余vm窃取时间百分比
- 抢占资源 --> 宿主机抢占资源
- us:用户进程空间中未改变过优先级的进程占用cpu百分比(程序在cpu进行计算的时候,没有改变过优先级,没有成为内核进行计算,在非内核计算的时间)
-
load average值和cpu使用率之间的关系
- 现在的linux服务器中,load average不等于cpu使用率
- load average是系统的整体负载体现
- 它包括 cpu负载+disk负载+网络负载+外设负载
- loadaverage=cpuload+ioload(disk+网络+外设负载都是io负载)
- cpu的使用:用户进程使用的时间us,系统内核运行时间sy,空闲时间idle,管理被抢占时间st
- 繁忙:us+sy+st+ni+hi+si cpu使用率的时间(除以总时间)
- 空间:idle+wa
-
上下文
-
上下文:cpu寄存器和程序计数器
- 程序计数器:存储cpu正在执行的指令位置和下一条指令的位置
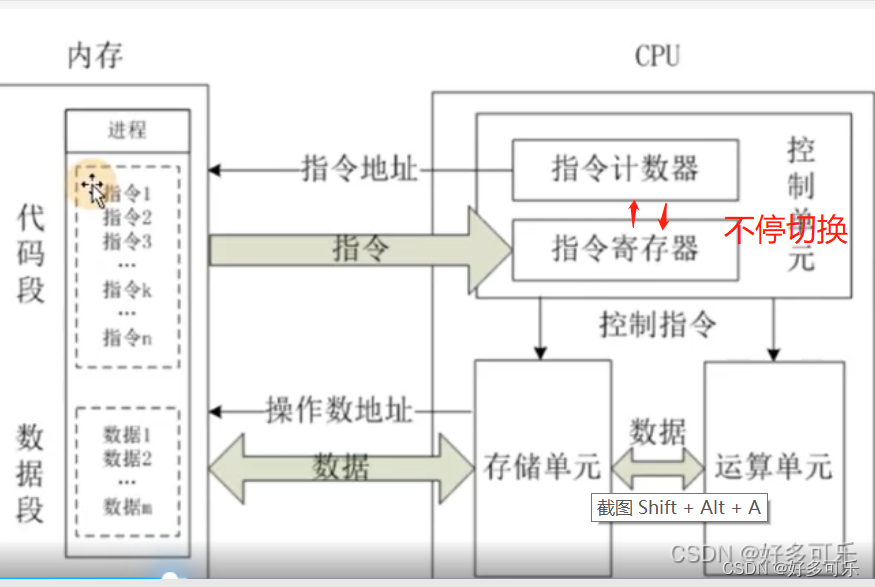
- 程序计数器:存储cpu正在执行的指令位置和下一条指令的位置
-
上下文切换:先把当前任务的cpu上下文(cpu寄存器和程序计数器)保存起来(内核中),然后加载新任务的上下文到cpu的寄存器和程序计数器中,cpu再跳转到程序计数器上执行新任务)
-
上下文切换类型:进程上下文切换,线程上下文切换,中断上下文切换
- 进程:资源的基本单位
- 线程:调度的基本单位
-
进程上下文切换
- 特权等级,跨等级时,需要系统调用:
- 同进程上下文切换:进程用户态-- 系统调用–>进程内核态–系统调用–>进程用户态
- 不同进程上下文切换:进程切换时要保存用户态资源(虚拟内存,栈等)
- 特权等级,跨等级时,需要系统调用:
-
线程上下文切换
- 线程,共享进程的资源,但是,线程也有自己的所有数据,如栈,寄存器
- 同进程中线程上下文切换:进程资源共享,切换线程私有资源
- 好比,同一个公司,不同部门之间交流;同公司不同楼层交流
-
不同进程中线程上下文切换:切换进程
-
-
cpu性能分析:load高 && cpu高
- top
- 情况1:sys系统态高 --> 需要排查cpu上下文切换
- 如果非自愿上下文切换多,说明cpu不够用,进程时间片刻,被迫切换
- 如果资源上下文切换多,说明计算用的资源不够用,可能存在IO,内存瓶颈
- 情况2:si软中断高 --> cpu抢资源,资源不够用IO问题
- sys高+si高 --> 推导出:内存 or网络IO问题 --> 解决方法:排查内存和IO
- sys高+si不高 --> 推导出:cpu瓶颈 --> 解决方法之一 :加cpu
- 情况3:us用户态高 --> 用户程序计算
- 密集型计算,内存FGC,资源等等(线程池)–>解决方法:逐个排查
- 情况1:sys系统态高 --> 需要排查cpu上下文切换
- top
-
做性能测试时候每次的结果都相差很大/不准,怎么分析?
- 如果是用无线网络测试的,可能会出现数据传输不稳定,出现延迟,导致结果会出现较大出入。我们就需要监控网络情况。有以下几种方式:
- 1,jmeter聚合报告最后两列,可以利用这两个值计算出带宽。企业可能用千兆光纤,但是企业的服务器一般只有几兆到几十兆。
- 2,也可以通过监控方式,如果有云服务器的管理台,可以看下管理台的网络流量图。
- 3,直接ping被测服务域名/ip,看看网络的延迟时间。如果时间在几毫秒~几十毫秒以内,那是可以接受的。我们可以在没有做测试前可以ping一下,正在做测试过程中也ping一下,看看有没有明显增大,如果增大非常多,甚至出现丢包,那就说明延迟已经影响性能测试,网络已经成为瓶颈。
- 如果是用无线网络测试的,可能会出现数据传输不稳定,出现延迟,导致结果会出现较大出入。我们就需要监控网络情况。有以下几种方式:
-