文章信息
论文题目:《Triplet Fingerprinting: More Practical and Portable Website Fingerprinting with N-shot Learning》
期刊(会议):Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security
级别:CCF A
文章链接:https://dl.acm.org/doi/pdf/10.1145/3319535.3354217
文章代码仓库:https://github.com/triplet-fingerprinting/tf
概述
这是一篇2019年的安全顶会论文。虽然这是一篇顶会论文,但我觉得这篇文章并没有达到我对顶会论文的期待。
这篇文章针对网站指纹攻击(Website Fingerprinting,WF)提出了一个新的方案,可以有效减少攻击目标网站时所需要收集的样本数量,并且在具有不同数据分布的数据集上和开放世界的设定下也能工作得较好。
其实作者就是引入了小样本学习(Few-shot Learning)中的三元组网络(孪生网络中的一种),通过这种网络结构训练出一个特征提取器,然后输入目标网站的加密流量得到对应的特征向量,最后用这些特征向量基于K近邻算法进行一个分类。文章中所声称的优越特性可以说都是三元组网络带来的,而这个网络结构是2015年CVPR的一篇文章《FaceNet: A Unified Embedding for Face Recognition and Clustering》提出的。所以我才会有一种失落感,安全领域的进展竟然要靠AI领域的进展来推动,安全领域的创新就是AI技术的应用?
梳理
文章总共有8个章节,前4个章节都可以看作是本文方案的一个引入。第5个章节正式提出本文的方案并介绍攻击流程。第6个章节介绍实验设定以及实验结果。最后两个章节总结实验结果并结束本文。
引入
第一章是Introduction,简要介绍了网站指纹攻击的由来,并列举了前人的一些工作及其缺陷,从而引出本文的贡献和本文方案的优点。
所谓WF攻击,就是利用每个网站的网络流量具有独特模式这一事实,这些模式可以被机器学习分类器学习到。攻击者必须通过收集他感兴趣的网站(监视网站)和其他用户可能访问的网站(非监视网站)的网络轨迹之间的大量数据来训练分类器。拥有训练有素的分类器后,攻击者会拦截受害者与第一个Tor节点之间的加密连接的流量,并使用分类器来确定她是否访问了监视站点,如果是的话,她访问了哪个站点。从而将用户与他访问的网站联系起来,破解Tor提供的匿名性。
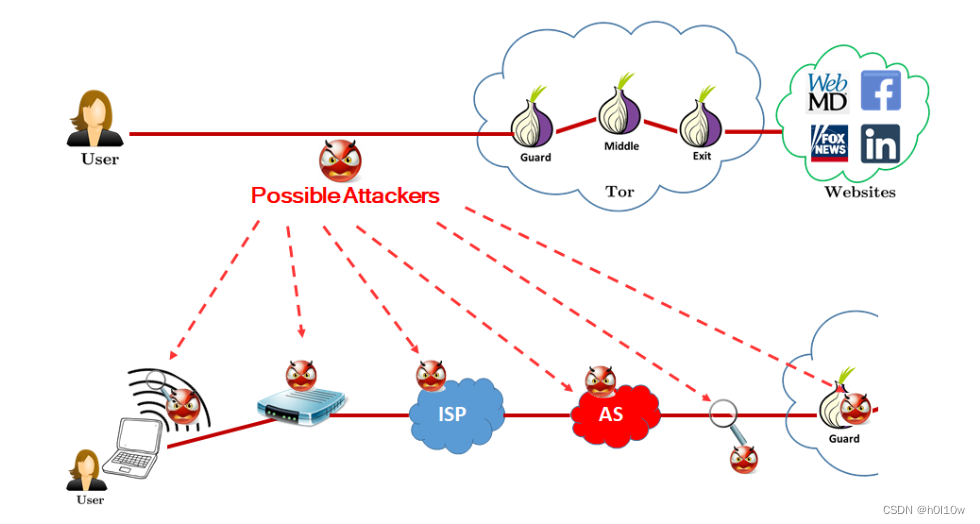
文章指出前人的工作存在一些缺陷:闭世界的设定不贴合实际,需要大量训练资料导致启动时间太长,假设训练数据和测试数据具有相同的数据分布,收集的数据是在同一网络条件下收集的……这些缺陷被本文的方案一一克服,从而形成自己的优势。
第二章介绍了一些背景和相关工作。在列举工作时作者提到了2018年的一篇论文《Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning》,这是本文重点对标的方案。同时作者也总结了一些必须考虑的假设:
- 闭世界和开放世界:闭世界假设用户只访问指定数量的被监控的网站,远小于真实世界的网站数量。开放世界除了被监控的网站外还有不被监控的网站。由此引出开放世界的两个指标:(1)开放大小,即不被监控的网站数量;(2)开放世界的评估模型,本文采用的是标准模型。
- 用户浏览行为:之前的很多工作都假定用户一次只访问一个网站,然而这不切实际,因为用户可以同时开很多标签页。
- 流量解析和背景流量:WF攻击需要假设攻击者能够从背景流量中区分监控网站的流量。这一假设已经得到处理,不是本文重点
第三章介绍了攻击目标。能运用于现实的方案需要具备如下特点:
- 普适性:之前的研究都假定攻击者能够复制受害者的网络条件、Tor浏览器版本以及一些其他设定,从而实现精准的WF攻击。一旦这些条件之一变化或想换一个人攻击,精确度都会急剧下降。
- 引导时间:之前的研究在攻击前都需要收集大量样本进行训练,训练往往需要花很多时间。另外,收集的样本过时了也会影响精度。所以好的方案需要能够快速部署,本文的方案只需要5个样本就能达到不错的效果。
- 灵活性和可迁移性:如果攻击者向受监控的网站列表添加或删除网站,以前的方案不得不重新训练。所以好的方案要具备灵活性和可迁移性,而这可以通过减少引导时间来解决。
第四章介绍了N-shot learning(NSL)技术,这是为了解决上述问题引入的技术。传统的监督学习主要侧重于训练分类器,让它学会将本地输入映射到其相应类别。相比之下,NSL模型被训练成学会区分不同的对象,而不考虑之前训练的类别。这其实就是一种Meta Learning(元学习)。这一章还介绍了Triplet Netwotrk,我之前的博客有详细记录,这里不多赘述。
攻击方案
预训练阶段:攻击者收集数据并训练Triplet Network,并使用DF模型作为子网络。DF模型就是本文对标的方案,本文作者将其中的Softmax层改成FC层以生成嵌入向量。如下图所示,预训练阶段的结果是一个特征提取器。
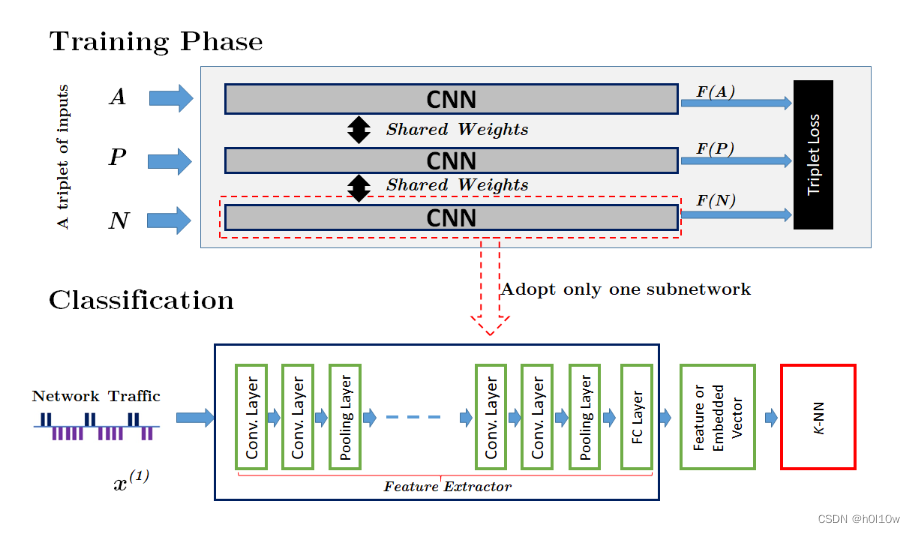
攻击阶段:本阶段又可分为两步:N训练和分类。N训练表示从三元组网络的特征提取器生成的N个嵌入向量训练WF分类器的过程。
N训练有3步,直观的过程可以看下面的图片:
- 攻击者从每个被监控的网站收集N个样本。
- 收集的流量样本送入特征提取器,获得每个网站对应的特征向量。
- 基于嵌入向量训练一个KNN分类器。
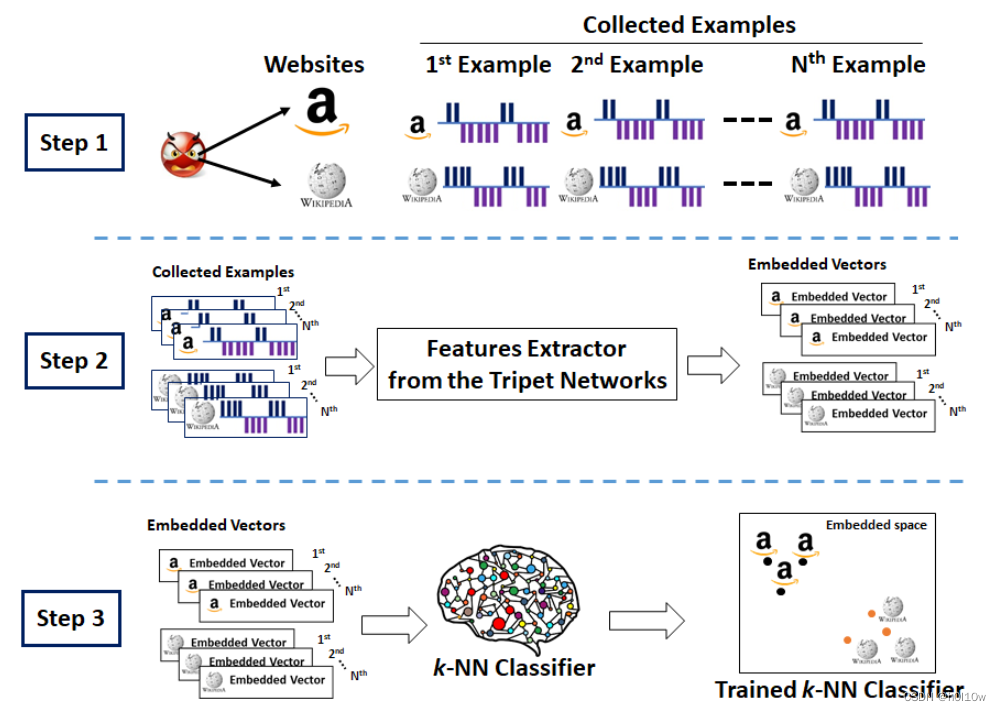
分类过程如下图所示,和上述过程类似

实验评估
不得不说这篇文章的工作量还是很大的,进行了很多实验。
作者首先评估了前人的两个方案,通过改变每类的样本数来观察精度的变化情况。

闭世界设定
接下来作者开始用自己的方案进行实验了。第一个实验作者在训练和测试时采用了两种不同的数据集。具体来说就是训练和测试用的流量样本来自不同的网站,但是具有类似的数据分布,因为他们都是在相同时间段使用相同版本的Tor浏览器收集的。
在这里作者对KNN进行了改进,在实验的时候对比效果:(1)N-ALL:就是原方案,将N个特征向量全部投入分类器(2)N-MEV:将N个特征向量求平均之后再投入分类器。

之后的实验是测试预训练阶段的攻击阶段的网站有重叠的情况,重叠比例从0%到100%。这里用的数据集也具有类似的数据分布。
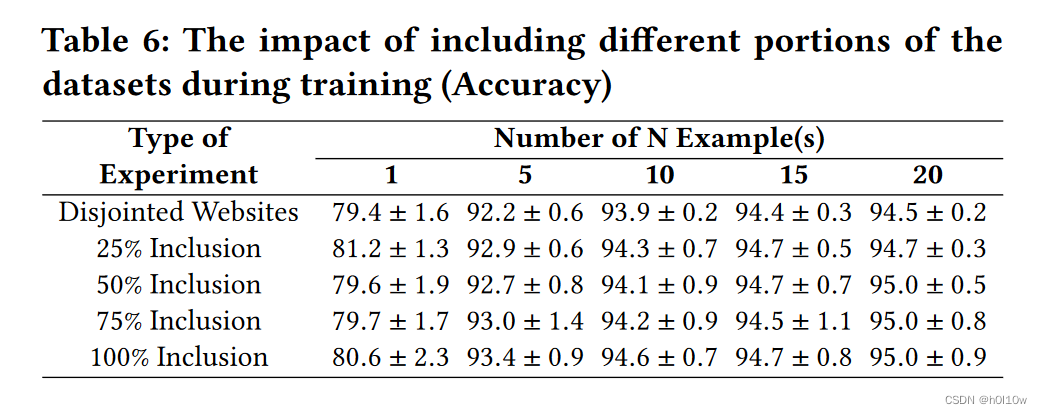
然后作者采用了不同的数据分布。这里的实验采用了前面训练出来的特征提取器,但是测试的数据集比训练集早3年,Tor浏览器版本也更老。

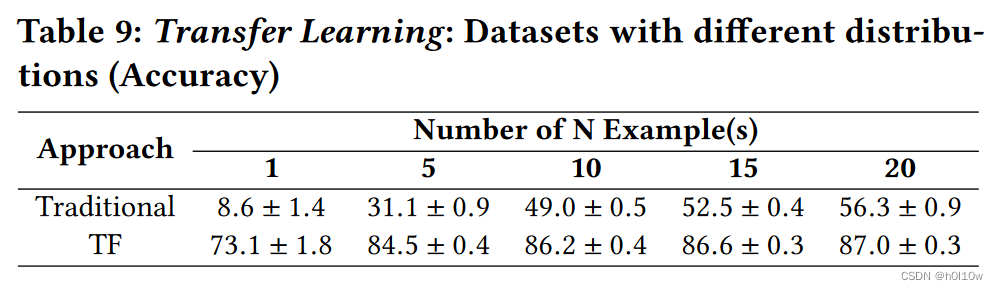
接下来作者对比了一般的迁移学习和本文的Triplet Network,这里用的是相似的数据分布。
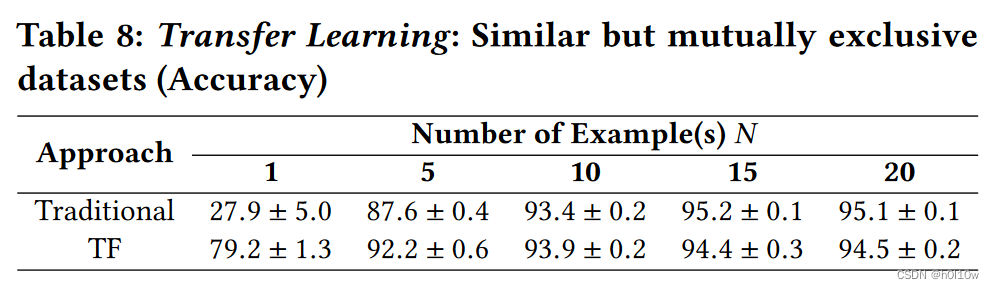
不同数据分布也测了一次。
开放世界设定
这里作者记录了针对精确度调优以及针对回报率调优的结果。

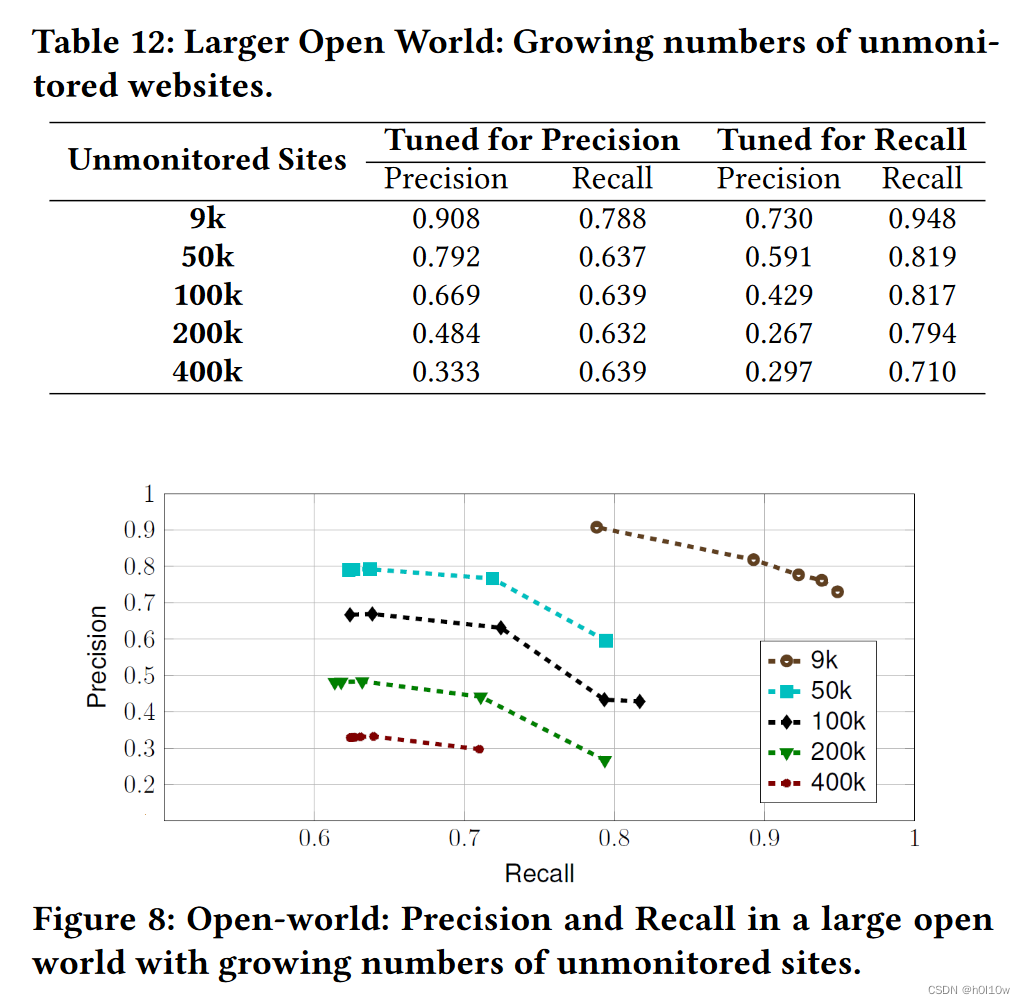
更大的开放世界
作者针对未监控的网站数量也进行了一系列实验。
WTF-PAD防御下
WTF-PAD防御就是对数据包进行自适应填充,通过在真实数据的间隙中发送假数据以掩盖用户流量的一些特征,比如长度。

总结
作者使用了N-shot Learning来改进WF攻击,在比大多数WF攻击论文中更现实和更具挑战性的情境下,提出了Triplet指纹(TF)攻击,利用Triplet Network进行N-shot Learning,允许攻击者仅对每个站点的少量样本进行训练。作者评估了TF攻击在几种具有挑战性的情境下的表现。结果表明,即使在训练和测试数据来自多年前并且收集在不同网络上的情况下,TF攻击的准确率仍然保持在85%。此外,作者还展示了TF攻击在开放世界的环境中也是有效的,并且可以胜过传统的迁移学习。这些结果表明,即使是拥有相对较低计算资源的攻击者也可以执行具有相当有效性能的WF攻击。