列式存储引擎-内核机制-Parquet格式
Parquet是一种开源的列式存储结构,广泛应用于大数据领域。
1、数据模型和schema
Parquet继承了Protocol Buffer的数据模型。每个记录由一个或多个字段组成。每个字段可以是atomic字段或者group字段。Group字段包含嵌套的字段,每层可以要么是atomic要么是group字段。每个字段定义由两部分组成:数据类型(基本的数据类型,比如int32或者byte array)、repetition类型(定义字段值出现的次数):required(1次)、optional(0或者1次)、repeated(0次或大于1次)。
看一个简单的示例:

Schema的最上层是message,里面包含3个字段。每个字段有3个属性:重复性(repetition)、类型(type)和名称(name)。其中contacts是一个group类型,即嵌套结构。
数据示例:

2、repetition和definition 级别
为了编码嵌套列,parquet 使用 dremel 通过 definition levels 和 repetition levels 来实现。
Repetition levels:用以表示在该字段路径上哪个节点进行了重复(at what repeated field in the field’s path the value has repeated)
Definition Levels:用以表示该字段路径上有多少可选的字段实际进行了定义(how many fields in p that could be undefined (because they are optional or repeated) are actually present)
1)比如:嵌套a.b.c三个3字段。字段path就是a.b.c
2)Repetition levels用来表示path中哪个部分是重复的。如果在a上重复了,那么level是1,b上重复level是2,c上重复level是3.
3)definition levels用来看下字段path中多少可选字段部分(optional和repeated)是定义的(即有值),求个和
为什么需要definition levels呢?
由于optional和repeated类型的存在,可能一条记录中某一列没有值,假设不记录这样的值,就会导致本该属于下一条记录的值被当作当前记录的一部分了,从而导致数据错误。下面的例子说明这点。
Dremel: Interactive Analysis of Web-Scale Datasets论文中的例子:
1)Schema定义:

2)两条记录

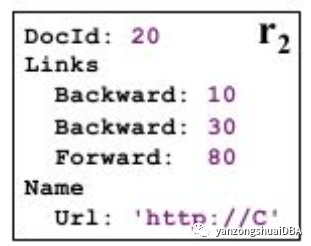
3)上述记录的RD表示
4)先以Links.Backward来说明为什么需要D
第1条记录中Links.Backward没有值,对该字段补NULL。此时Links.Backward的NULL没有一部分是重复的,所以R值为0。
第2条记录中Links.Backward有10和30两个值,10这个没有一部分是重复的,所以R值为0,30这个在Backward上重复,R值是1。
那么,不使用D的话,就将NULL,10,30都归到第1条记录了。
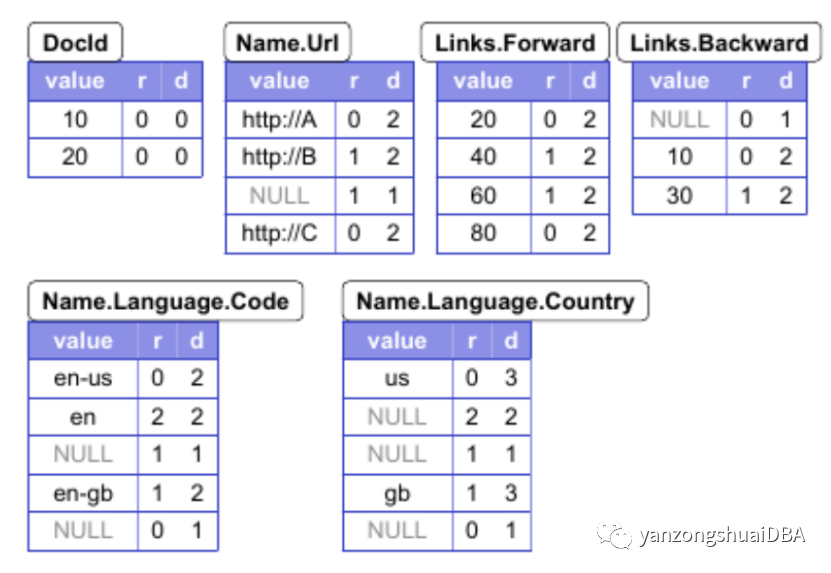
5)来看Name.Language.Code的D。Name和Language都是可选字段。
en-us的这个值出现了,即Code出现了,表示前两个也出现,所以它的值是2
NULL的这个,即表示url:http://B 这个的,仅name出现,所以该路径上可选项为1个。
注意:
1)required和optional字段不需要repetition level,只有repeated可重复的字段需要,所以这个路径的level仅算repeated的。比如Links.Backward这个路径Links是optional,仅Backward是repeated,所以Backward的repetition level是1。
2)Name.Language.Code的第一个NULL,表示url:http://B 这个的,它的R是在Name上重复,所以是1
3、编码
将给定数据转换成编码形式。根据使用的方法,编码有不同目的:确保数据正确性、缩短数据或者正确书写字符。Parquet中有:Plain、RLE/bit-packing、Delta编码。
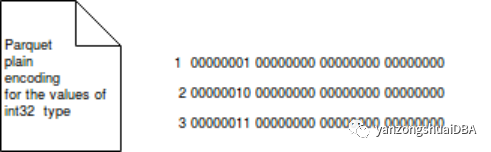
3.1 Plain编码
对数据没有压缩和其他处理。所有类型均可使用。比如int32以4个字节存储,下图显示了0到3数字如何以plain编码方式进行存储:
3.2 RLE编码
Run-Length encoding算法,针对连续重复的数据,记录重复次数及对应值:

3.3 Bit-packing
基于这么个假设:每个int32或int64的值并不总是需要全部的32位或者64位。因此,不将这些值存储在他们的全部范围中,bit-packing将多个值打包到一个空间中。从数值的最低有效位开始压缩。最低有效位的意思,就是数值从二进制表示的值是 1 的最低的位置。从右边开始。例如针对数值是从 0 到 7,7占有的位长是 3, 按照 3 的位长来进行按位操作。如下:
# bitwidth of 3
output[0] = ((input[0] & 7) | ((input[1] & 7) << 3) | ((input[2] & 7) << 6)) & 255
output[1] = (((input[2] & 7) >>> 2) | ((input[3] & 7) << 1) | ((input[4] & 7) << 4)) | ((input[5] & 7) << 7)) & 255
output[2] = (((input[5] & 7) >>> 1) | ((input[6] & 7) << 2) | ((input[7] & 7) << 5)) & 255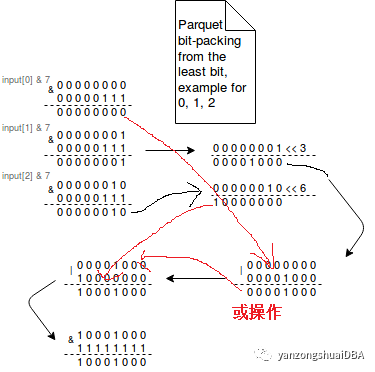
上图是0,1,2三个值打包的示例。使用三位来表示一个值。input[0]使用最低3位,input[1]使用中间三位,input[3]使用最高的2位。
3.4 Dictionary Encoding 编码
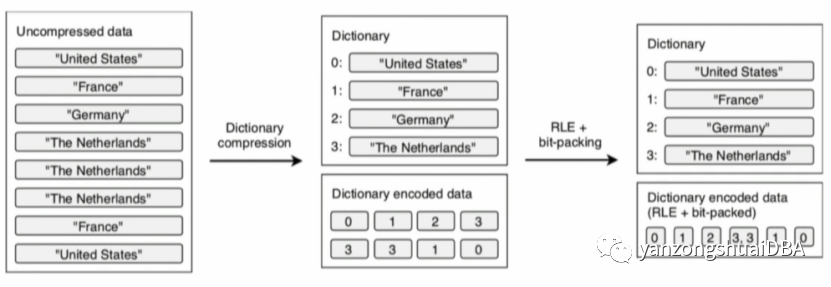
对每个未压缩的数据使用数字进行编码。当然可以和上述的RLE/bit-packing结合。
3.5 Delta
可以用在整数和字节数组。delta 编码记录一个值和它之后一个值的差异,比如:
to_encode = [1, 2, 5, 7, 9]
encoded = [1, 1, 3, 2, 2]2比前一个值大1,5比前一个值大3,依次类推。
to_encode = [abc, abcd, abcde, abcdef]
encoded = [abc, 3d, 4e, 5e, 6f]字节的话,abcd与前一个不同在于第3个值是d,依次类推。
Delta 编码又被称为 incremental 变化,增量编码。非常适合有同样前缀的有序的字符串。
4、存储格式
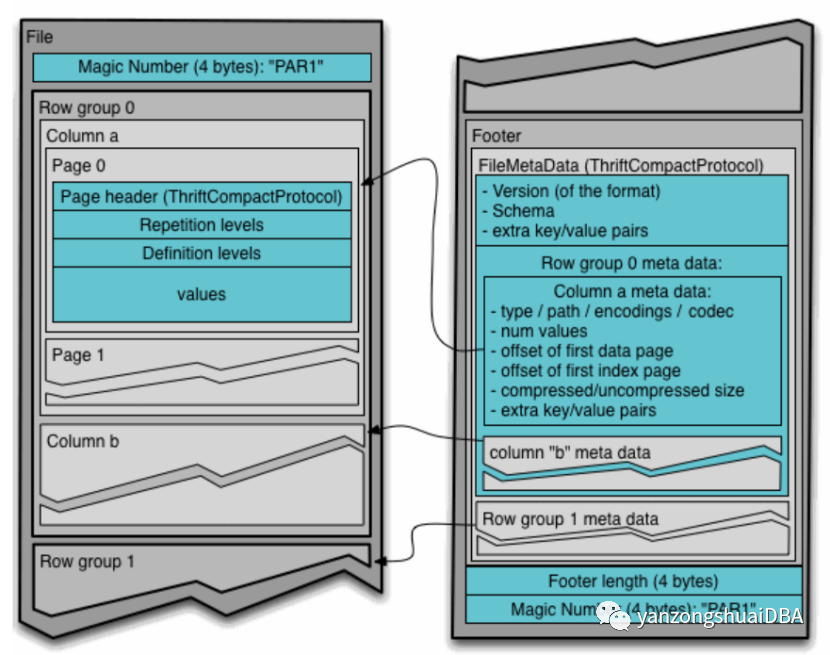
这里存储模型又可以理解为存储格式或文件格式,Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
1、行组,Row Group:Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
2、列块,Column Chunk:行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。
3、页,Page:Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
5、参考
https://www.waitingforcode.com/apache-parquet/encodings-apache-parquet/read
https://github.com/apache/parquet-format
https://github.com/apache/parquet-format/blob/master/Encodings.md