介绍与网络传输
- 0.介绍
- a.什么是rpc
- b.rpc的通信流程
- 1.网络传输
- a.零拷贝
- 1) 零拷贝的概念
- 2) Netty的零拷贝
- b.IO多路复用
- c.Netty入门
- 1) netty中的helloworld
- d.封装报文
- 1) 协议结构
- 2) 模拟封装报文
- e.序列化
- f.压缩和解压缩
0.介绍
a.什么是rpc
rpc 的全称是 Remote Procedure Call,即远程过程调用。从字面上的来看,rpc就是通过网络通信访问另一台机器的应用程序接口。但随着近几年的技术在不断发展,rpc也有了一些新的含义。
目前,我们的rpc组件的基本能力就是屏蔽网络编程细节,实现调用远程方法就跟调用本地(同一个项目中的方法)一样**。事实上一个合格的可用于生产的rpc框架还应该具备**负载均衡、优雅启停、链路追踪、灰度发布等等功能。
b.rpc的通信流程
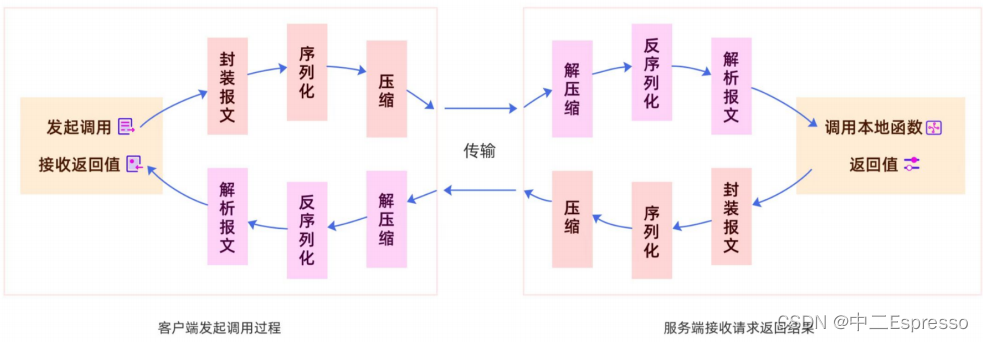
rpc能实现调用远程方法就跟调用本地(同一个项目中的方法)一样,发起调用请求的那一方叫做调用方,被调用的一方叫做服务提供方
1.网络传输
a.零拷贝
1) 零拷贝的概念
几个buffer缓冲区:
-
当某个程序或已存在的进程需要某段数据时,它只能在用户空间中属于它自己的内存中访问、修改,这段内
存暂且称之为
user buffer -
正常情况下,数据只能从磁盘(或其他外部设备)加载到内核的缓冲区,且称之为
kernel buffer -
TCP/IP协议栈维护着两个缓冲区: send buffer 和 recv buffer ,它们合称为
socket buffer
(1) DMZ操作
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。
DMA下读取磁盘数据流程如下:
- 1.用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- 2.CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令
- 3.DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程
- 4.DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程。
- 5.DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区
- 6.用户进程由内核态切换回用户态,解除阻塞状态
DMA可以脱离CPU,将一些数据从外设读取到内核缓冲区当中
(2) 传统读取数据和发送数据
程序传统IO实际上是调用系统的 read() 和 write() 实现,通过 read() 把数据从硬盘读取到内核缓冲区,再复制到用户缓冲区;然后再通过 write() 写入到socket缓冲区,最后写入网卡设备:
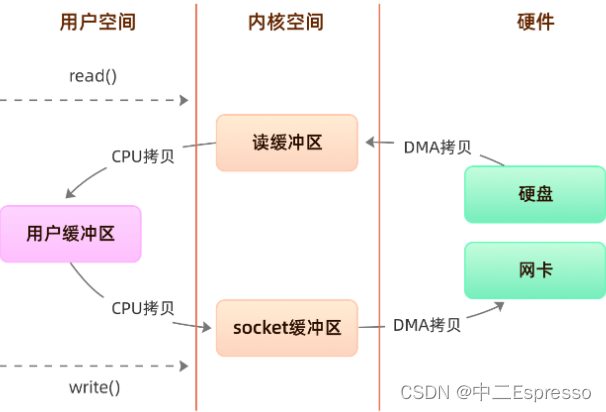
整个过程发生了四次用户态和内核态的切换还有四次IO拷贝, 具体流程是:
- 用户进程通过 read() 方法向操作系统发起调用,此时上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU把读缓冲区数据拷贝到应用缓冲区,上下文从内核态转为用户态, read() 返回
- 用户进程通过 write() 方法发起调用,上下文从用户态转为内核态
- CPU将应用缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态, write() 返回
(3) 零拷贝实现技术
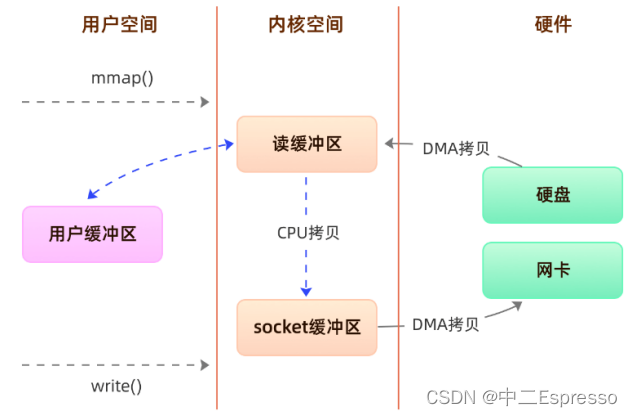
方案一、内存映射(mmap+write)
mmap 是 Linux 提供的一种内存映射文件方法,即将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地
址。
mmap 主要实现方式是将**读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,**从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝,然而内核读缓冲区(read buffer)仍需将数据拷贝到内核写缓冲区(socket buffer)。
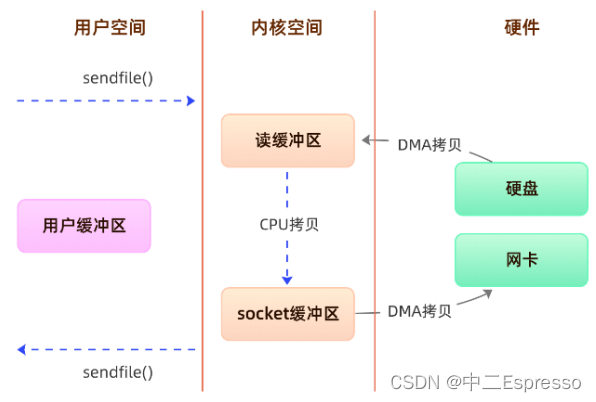
方案二、sendfile
通过使用 sendfile 函数,数据可以直接在内核空间进行传输,因此避免了用户空间和内核空间的拷贝,同时由于
使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换
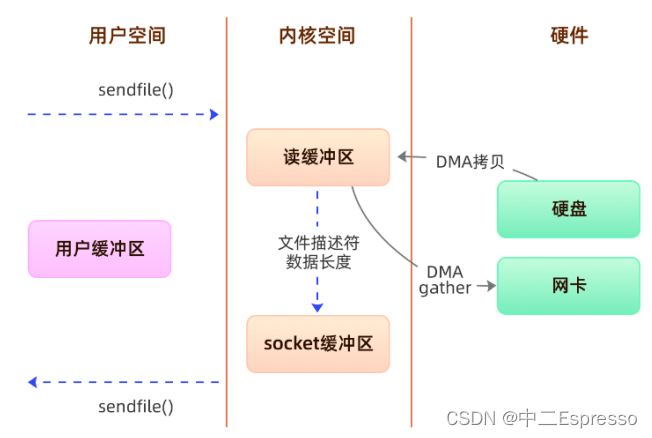
方案三、sendfile+DMA scatter/gather
将读缓冲区中的数据描述信息–内存地址和偏移量记录到socket缓冲区,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程。
总结:
-
由于CPU和IO速度的差异问题,产生了DMA技术,通过DMA搬运来减少CPU的等待时间。
-
传统的 IO read/write 方式会产生2次DMA拷贝+2次CPU拷贝,同时有4次上下文切换。
-
而通过 mmap+write 方式则产生2次DMA拷贝+1次CPU拷贝,4次上下文切换,通过内存映射减少了一次CPU拷贝,可以减少内存使用,适合大文件的传输。
-
sendfile 方式是新增的一个系统调用函数,产生2次DMA拷贝+1次CPU拷贝,但是只有2次上下文切换。因为只有一次调用,减少了上下文的切换,但是用户空间对IO数据不可见,适用于静态文件服务器。
-
sendfile+DMA gather 方式产生2次DMA拷贝,没有CPU拷贝,而且也只有2次上下文切换。虽然极大地提升了性能,但是需要依赖新的硬件设备支持。
2) Netty的零拷贝
操作系统层面的零拷贝主要避免在用户态(User-space)和内核态(Kernel-space)之间来回拷贝数据。
Netty中的zero-copy不同于操作系统,它完全是在用户态(java 层面),更多的偏向于优化数据操作这样的概念,体现在:
(1) ByteBuf
ByteBuf是Netty进行数据读写交互的单位,结构如下:
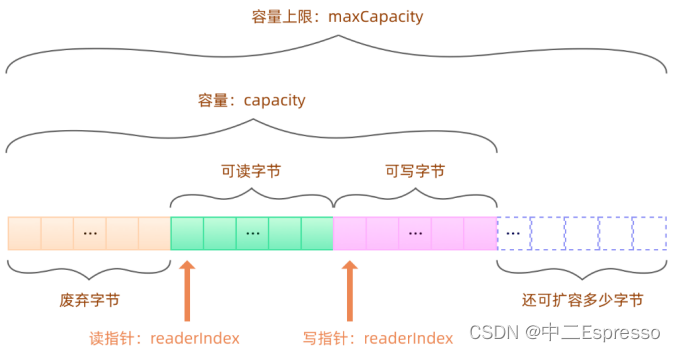
- 1.ByteBuf 是一个字节容器,容器里面的的数据分为三个部分,第一个部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。最后一部分虚线表示的是该ByteBuf 最多还能扩容多少容量
- 2.以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(readerIndex)、写指针(writerIndex),然后还有一个变量 capacity,表示 ByteBuf 底层内存的总容量
- 3.从 ByteBuf 中每读取一个字节,readerIndex 自增1,ByteBuf 里面总共有
writerIndex-readerIndex个字节可读,当 readerIndex 与 writerIndex 相等的时候,ByteBuf 不可读 - 4.写数据是从 writerIndex 指向的部分开始写,每写一个字节,writerIndex 自增1,直到增到 capacity,这个时候,表示 ByteBuf 已经不可写了
- 5.ByteBuf 里面其实还有一个参数 maxCapacity,当向 ByteBuf 写数据的时候,如果容量不足,那么这个时候可以进行扩容,直到 capacity 扩容到 maxCapacity,超过 maxCapacity 就会报错
@Test
public void testByteBuf() {
ByteBuf header = Unpooled.buffer();
ByteBuf body = Unpooled.buffer();
// 通过逻辑组装而不是物理拷贝,实现jvm中零拷贝
CompositeByteBuf byteBuf = Unpooled.compositeBuffer();
byteBuf.addComponents(header, body);
}
(2) CompositeByteBuf 零拷贝
Composite buffer 实现了透明的零拷贝, 将物理上的多个 Buffer 组合成了一个逻辑上完整 CompositeByteBuf
比如在网络编程中, 一个完整的 http 请求常常会被分散到多个 Buffer 中。用 CompositeByteBuf 很容易将多个分散的Buffer组装到一起,而无需额外的复制
@Test
public void testWrapper() {
byte[] buf = new byte[1024];
byte[] buf2 = new byte[1024];
// 共享byte数组的内容而不是拷贝,也是零拷贝
ByteBuf byteBuf = Unpooled.wrappedBuffer(buf, buf2);
}
b.IO多路复用
常见的网络 IO 模型分为四种:
-
同步阻塞 IO(BIO)
-
同步非阻塞 IO(NIO)
-
IO 多路复用
-
异步非阻塞 IO(AIO)
在这四种 IO 模型中,只有 AIO 为异步 IO,其他都是同步 IO。
下图是应用程序发起一次网络IO的流程:
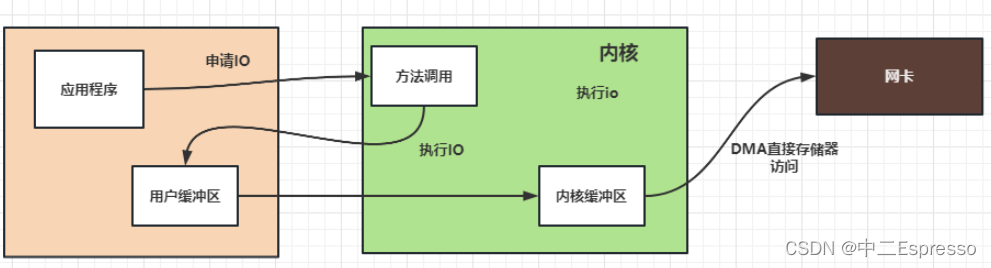
那么什么是 IO 多路复用呢?通过字面上的理解,多路就是指多个通道,也就是多个网络连接的 IO,而复用就是指多个通道复用在一个selector上。
多个网络连接的 IO 可以注册到一个selector上,当用户进程调用了 select,那么整个进程会被阻塞。同时,内核会“监视”所有 selector 负责的 socket,当任何一个 socket 中的数据准备好了,select 就会返回。这个时候用户进程再调用 read 操作,将数据从内核中拷贝到用户进程。
当用户进程发起了 select 调用,进程会被阻塞,当发现该 select 负责的 socket 有准备好的数据时才返回,之后才发起一次 read,整个流程要比阻塞 IO 要复杂,似乎也更浪费性能。但它最大的优势在于,用户可以在一个线程内同时处理多个 socket 的 IO 请求。用户可以注册多个 socket,然后不断地调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
同样好比我们去餐厅吃饭,这次我们是几个人一起去的,我们专门留了一个人在餐厅排号等位,其他人就去逛街了,等排号的朋友通知我们可以吃饭了,我们就直接去享用了。
c.Netty入门
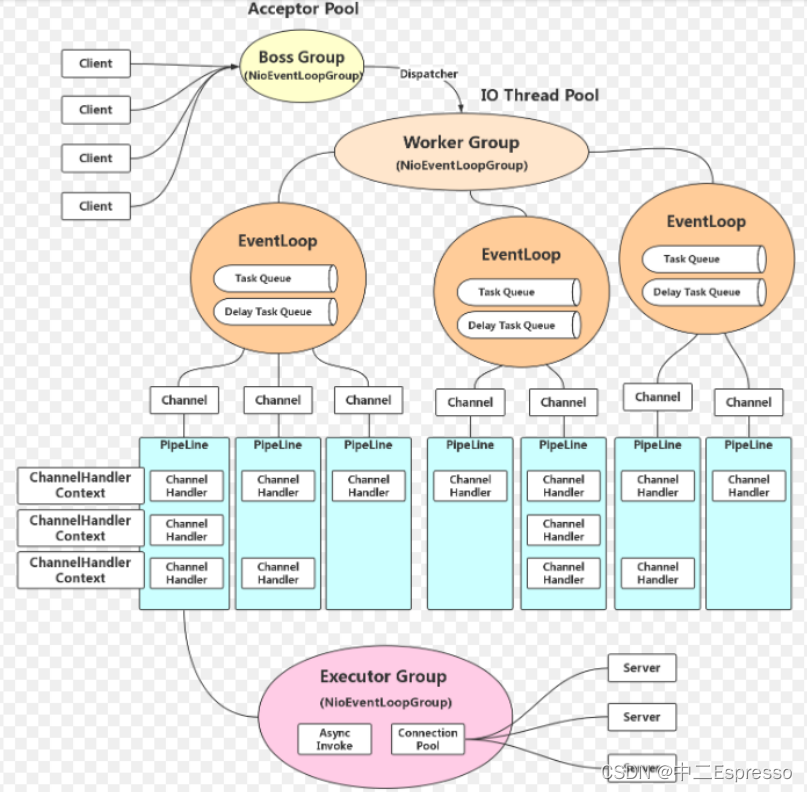
netty的基本工作流程
在netty中存在以下的核心组件:
-
ServerBootstrap:服务器端启动辅助对象;
-
Bootstrap:客户端启动辅助对象;
-
Channel:通道,代表一个连接,每个Client请对会对应到具体的一个Channel;
-
ChannelPipeline:责任链,每个Channel都有且仅有一个ChannelPipeline与之对应,里面是各种各样的Handler;
-
handler:用于处理出入站消息及相应的事件,实现我们自己要的业务逻辑;
-
EventLoopGroup:I/O线程池,负责处理Channel对应的I/O事件;
-
ChannelInitializer:Channel初始化器;
-
ChannelFuture:代表I/O操作的执行结果,通过事件机制,获取执行结果,通过添加监听器,执行我们想要的操作;
-
ByteBuf:字节序列,通过ByteBuf操作基础的字节数组和缓冲区。
1) netty中的helloworld
创建客户端Client
客户端启动类根据服务器端的IP和端口,建立连接,连接建立后,实现消息的双向传输
public class AppClient {
public void run() {
// 1.定义线程池 EventLoopGroup
NioEventLoopGroup group = new NioEventLoopGroup();
try {
// 2.启动一个客户端需要一个辅助类 bootstrap
Bootstrap bootstrap = new Bootstrap();
bootstrap = bootstrap.group(group)
.remoteAddress(new InetSocketAddress(8080))
// 选择初始化一个什么样的channel
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
socketChannel.pipeline().addLast(new ClientChannelHandler());
}
});
// 3.连接到远程节点;等待连接完成
ChannelFuture channelFuture = bootstrap.connect().sync();
// 4.获取channel并且写数据,发送消息到服务器端
channelFuture.channel().writeAndFlush(Unpooled.copiedBuffer("hello netty".getBytes(StandardCharsets.UTF_8)));
// 5.阻塞程序,等待接收消息
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
try {
group.shutdownGracefully().sync();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new AppClient().run();
}
}
定义客户端Client的处理器
public class ClientChannelHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf byteBuf = (ByteBuf) msg;
System.out.println("客户端已经收到了消息:--> " + byteBuf.toString(StandardCharsets.UTF_8));
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
}
}
创建服务器Server
public class AppServer {
private int port;
private AppServer(int port) {
this.port = port;
}
public void start() {
// 1.创建EventLoopGroup,老板只负责处理请求,之后会将请求分发给worker,1比2的比例
NioEventLoopGroup boss = new NioEventLoopGroup(2);
NioEventLoopGroup worker = new NioEventLoopGroup(10);
try{
// 2.服务器端启动辅助对象
ServerBootstrap serverBootstrap = new ServerBootstrap();
// 3.配置服务器
serverBootstrap = serverBootstrap.group(boss, worker)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
socketChannel.pipeline().addLast(new ServerChannelHandler());
}
});
// 4.绑定端口
ChannelFuture channelFuture = serverBootstrap.bind(port).sync();
// 5.阻塞操作
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
try {
boss.shutdownGracefully().sync();
worker.shutdownGracefully().sync();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new AppServer(8080).start();
}
}
创建服务器Server处理器
public class ServerChannelHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf byteBuf = (ByteBuf) msg;
System.out.println("服务端已经收到了消息:--> " + byteBuf.toString(StandardCharsets.UTF_8));
// 可以通过ctx获取channel
ctx.channel().writeAndFlush(Unpooled.copiedBuffer("hello client".getBytes(StandardCharsets.UTF_8)));
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
}
}
d.封装报文
在设计一个 rpc远程调用框架时,需要考虑如何对请求和响应数据进行封装、以及编码、解码,以及如何表示调用的方法和参数。我们必须要设计一个私有且通用的私有协议,协议是一种公平对话的模式,有了标准协议调用方和服务提供方就可以互相按照标准进行协商。
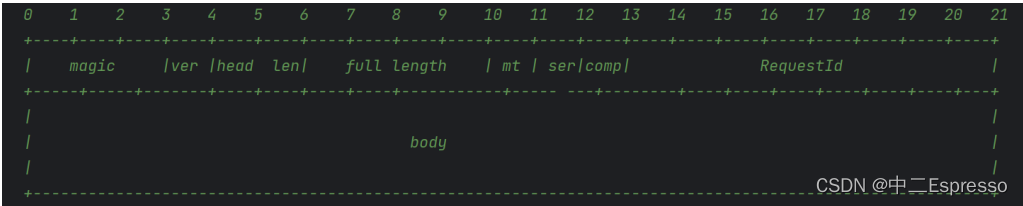
1) 协议结构
项目设计的协议分为 Header(头部)和 Body(主体)两部分。Header 包含协议的元数据,例如消息类型、序列化类型、请求ID 等。Body 包含实际的 rpc 请求或响应数据。
+-----------------------------------------------+
| Header |
+-----------------------------------------------+
| Body |
+-----------------------------------------------+
Header 结构
Header 可以包含以下字段:
- Magic Number(4 字节):魔数,用于识别该协议,例如:0xCAFEBABE。
- Version(1 字节):协议版本号。
- MessageType(1 字节):消息类型,例如:0x01 表示请求,0x02 表示响应。
- Serialization Type(1 字节):序列化类型,例如:0x01 表示 JSON,0x02 表示 Protobuf 等。
- Request ID(8 字节):请求ID,用于标识请求和响应的匹配。
- Body Length(4 字节):Body 部分的长度。
- head length (4 字节) :请求长度
Body 结构
Body 的结构取决于具体的 yrpc 请求或响应数据
对于 yrpc 请求,Body 可以包含以下字段:
- Service Name:被调用的服务名称。
- Method Name:被调用的方法名称。
- Method Arguments:被调用方法的参数列表。
- Method Argument Types:被调用方法参数的类型列表。
对于 yrpc 响应,Body 可以包含以下字段:
- Status Code:响应状态码,例如:0x00 表示成功,0x01 表示失败。
- Error Message:错误信息,当 Status Code 为失败时,包含具体的错误信息。
- Return Value:方法返回值,当 Status Code 为成功时,包含方法调用的返回值。
2) 模拟封装报文
/**
* 模拟封装报文
*/
@Test
public void testMessage() throws IOException {
ByteBuf message = Unpooled.buffer();
message.writeBytes("rpc".getBytes(StandardCharsets.UTF_8)); // magic number
message.writeByte(1); // version
message.writeShort(125); // head length
message.writeInt(256); //full length
message.writeByte(1); // Message Type
message.writeByte(0); // Serialization Type
message.writeByte(2); // comp
message.writeLong(251455L); // Request ID
// 对象流转换为字节数组
AppClient appClient = new AppClient();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(outputStream);
oos.writeObject(appClient);
byte[] bytes = outputStream.toByteArray();
message.writeBytes(bytes);
printAsBinary(message);
}
e.序列化
网络传输中,我们不能直接将堆内存的对象实例直接进行传输,而是需要将其序列化成一组二进制数据,这样的二进制数据可以是字符序列,最简单的莫过于我们熟悉的json字符序列
- jdk的ObjectInputStream
- Hession
- Json
- protobuf等
f.压缩和解压缩
如果我们觉得序列化后的二进制内容体积任然比较大,任然不能支持当前的业务容量,我们可以选择对序列化的结果进行压缩,但是开启压缩一定要注意,这个操作本是就是一个cpu资源换取存储和带宽资源的操作,要判断当前的业务是更需要cpu资源还是内存资源。
模拟压缩与解压代码:
/**
* 模拟压缩
*/
@Test
public void testCompress() throws IOException {
byte[] buf = new byte[]{12, 26, 26, 26, 25, 12, 26, 26, 26, 25, 12, 26, 26, 26, 25, 12, 26, 26, 26, 25, 23, 25, 14, 25, 23, 25, 14, 25, 23, 25, 14, 25, 23, 25, 14, 26, 25, 23, 25, 14, 26, 25, 23, 25, 14};
// 将buf作为输入,将结果输出到另一个字节数组当中
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
GZIPOutputStream gzipOutputStream = new GZIPOutputStream(byteArrayOutputStream);
gzipOutputStream.write(buf);
gzipOutputStream.finish();
byte[] bytes = byteArrayOutputStream.toByteArray();
System.out.println(Arrays.toString(bytes));
System.out.println("压缩前:" + buf.length);
System.out.println("压缩后:" + bytes.length);
}
/**
* 模拟解压缩
*/
@Test
public void testDeCompress() throws IOException {
byte[] buf = new byte[]{31, -117, 8, 0, 0, 0, 0, 0, 0, -1, -29, -111, -110, -110, -110, -28, 65, 37, -60, 37, -7, -112, -79, 20, -100, 0, 0, -90, -21, -43, 46, 45, 0, 0, 0};
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPInputStream gzipInputStream = new GZIPInputStream(new ByteArrayInputStream(buf));
byte[] bytes = gzipInputStream.readAllBytes();
System.out.println(Arrays.toString(bytes));
System.out.println("解压前:" + buf.length);
System.out.println("解压后:" + bytes.length);
}