现象
生产服务中,存在部分服务在 JVM 参数、POD 规格、物理机规格 一致,负载流量差异不大的情况下,出现在内存使用上差异较大的情况。下面是一些基本信息的收集和整理。
JVM 参数
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=2 -
XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -XX:MaxRAMFraction=1 -
XX:-OmitStackTraceInFastThrow -Dnetworkaddress.cache.ttl=60 -Dsun.net.inetaddr.ttl=60 -
XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseGCLogFileRotation -
XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20m
流量情况
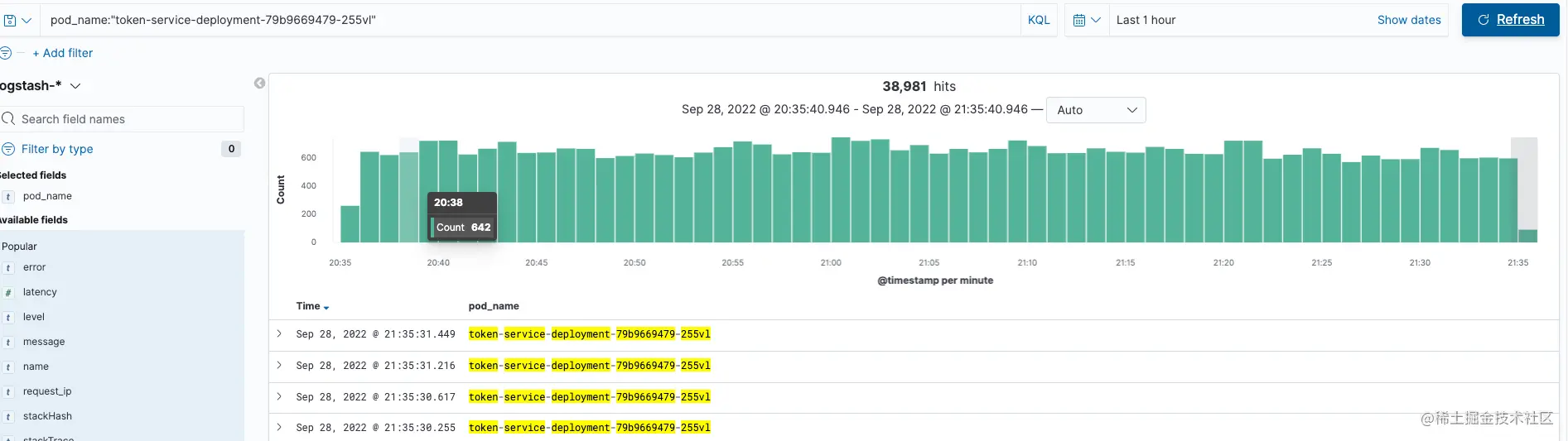
pod-zdvgm 流量情况

pod-255vl 流量情况
堆和 GC 分析
堆
通过 jmap -heap 查看堆使用情况
- 配置
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 6442450944 (6144.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 3865051136 (3686.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
复制代码
- 使用情况

结论:
- 1、在堆配置一致的情况下,两个实例的在 Young Generation 和 G1 Old Generation 的运行时情况差异非常大。这些使用情况也直接反馈在 GC 上,下面是 GC 情况。
- 2、heap region size 为 1M 【MaxHeapSize(6144M)/Heap regions(6144)】
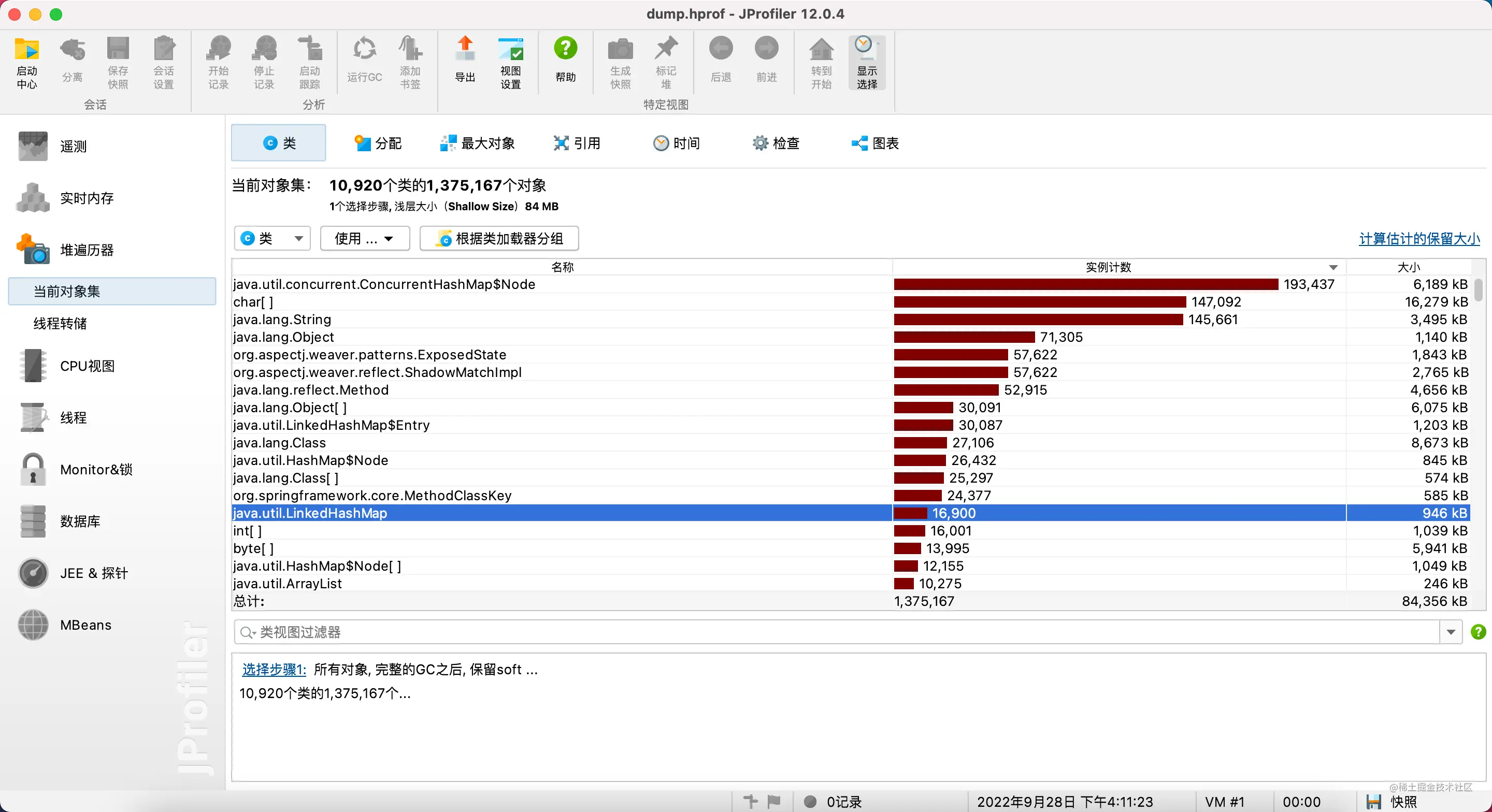
- 3、通过 heap dump 分析,token-service-deployment-79b9669479-255vl dump 下的文件是 2.31G,token-service-deployment-79b9669479-zdvgm 是464M。通过 jprofile 分析,在删除弱引用和无效引用的情况下,heap 使用情况基本一致,都没有大对象情况,也就是说,内存占用多的 pod 如果 GC 频次起来之后,相应的内存肯定是会降来下的,因为堆中存在大量未引用和无效引用的情况对象没有被回收。
下面是对两个 POD 进行 heap dump 的分析截图:
-
大小差异很大

-
clean 无效对象之后的分析结果
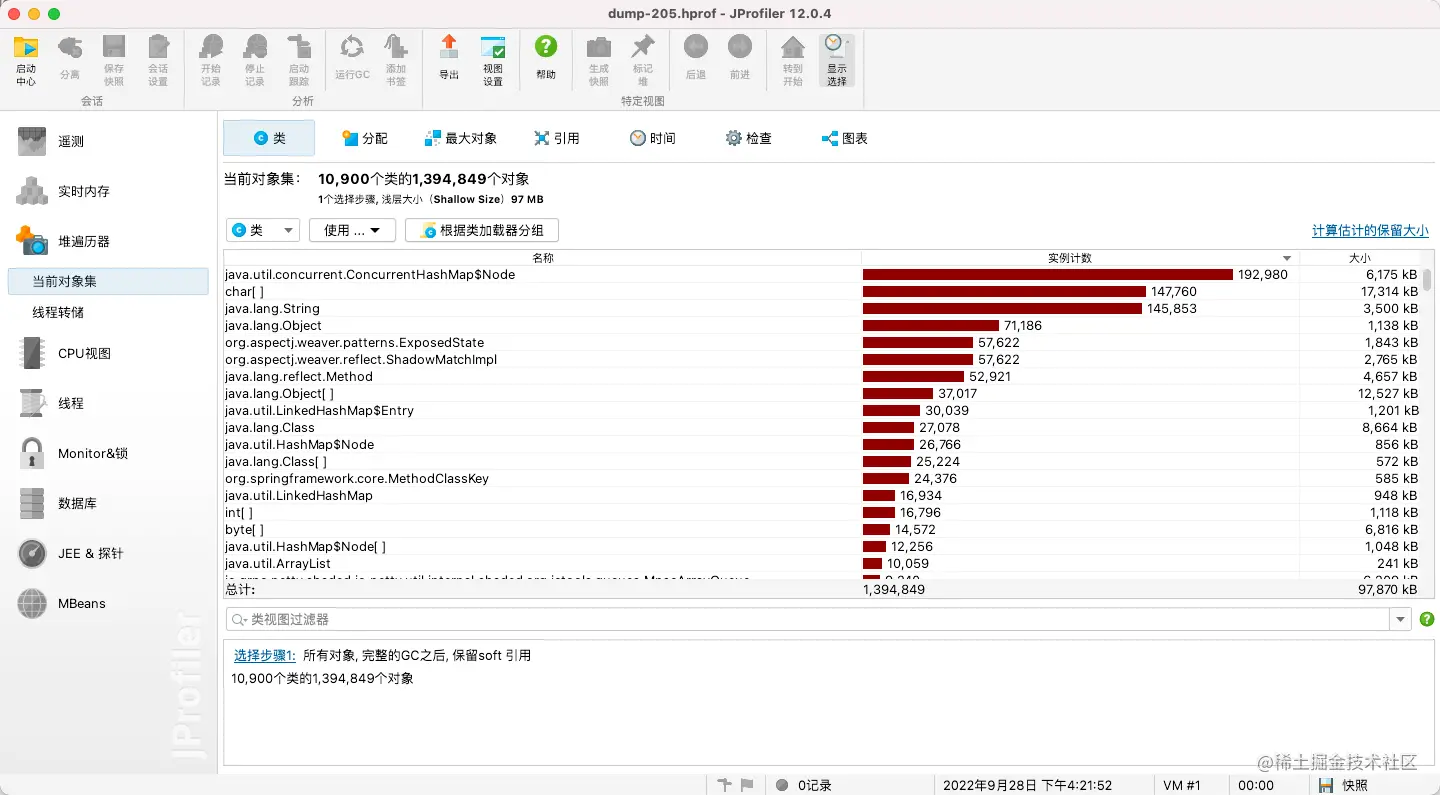
-
clean 无效对象之后的分析结果
GC
随机抓取到的 gc 日志 pod-zdvgm,
[Eden: 214.0M(214.0M)->0.0B(212.0M) Survivors: 1024.0K->2048.0K Heap: 343.2M(384.0M)->129.4M(384.0M)]
复制代码
pod-255vl,
[Eden: 1915.0M(1915.0M)->0.0B(1914.0M) Survivors: 2048.0K->3072.0K Heap: 2706.3M(3196.0M)->791.8M(3196.0M)]
复制代码
pod-zdvgm 的 GC 频次是 pod-255vl 的 5-10 倍。eden 区的大小也相差接近 10 倍。
关于 G1
- 1、为什么在同等条件下,内存使用差距会这么大?eden 区的分配和 region 的个数是由什么决定的?
- 2、G1 GC 频次有哪些影响因素
Eden 区大小和 Region 个数影响因素
JVM 默认堆大小
官方文档对于默认堆大小的计算说明:docs.oracle.com/javase/8/do…。简单说就是:在物理内存达到 192MB 之前, JVM 最大堆大小为物理内存的一半;在物理内存大于 192MB, 在到达 1GB 之前, JVM 最大堆大小为物理内存的 1/4(大于 1GB 的物理内存也按 1GB 计算)。
可以使用标志 -Xms(初始堆大小)和 -Xmx(最大堆大小)指定初始和最大堆大小。
Eden 区大小
计算逻辑说明:
- 如果设置新生代最大值(MaxNewSize)和最小值(NewSize),可以根据这些值计算新生代包含的最大的分区和最小的分区;注意 Xmn 等价于设置了 MaxNewSize 和 NewSize,且NewSize=MaxNewSize。
- 如果既设置了最大值或者最小值,又设置了NewRatio,则忽略NewRatio。
- 如果没有设置新生代最大值和最小值,但是设置了NewRatio,则新生代的最大值和最小值是相同的,都是整个堆空间/(NewRatio+1)。
- 如果没有设置新生代最大值和最小值,或者只设置了最大值和最小值中的一个,那么 G1 将根据参数G1MaxNewSizePercent(默认值为60)和 G1NewSizePercent(默认值为5)占整个堆空间的比例来计算最大值和最小值。
MaxHeapSize = 6442450944 (6144.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 3865051136 (3686.0MB)
复制代码
MaxNewSize (3686) = MaxHeapSize (6144)* 60%
-
1、NewSize 的计算不是根据 MaxHeapSize*5% 计算得到,这个值算是一个默认值(比如在这个 case中,heap 是 24G,但是 NewSize 也是 1363144)
-
2、如果 G1 推断出最大值和最小值相等,则说明新生代不会动态变化。不会动态变化意味着 G1 在后续对新生代垃圾回收的时候可能不能满足期望停顿的时间
Region 个数
前面 Heap Configuration 中 MaxHeapSize = 6144M, regions 为 6144,所以 HeapRegionSize 在我们的场景下就是 1M。
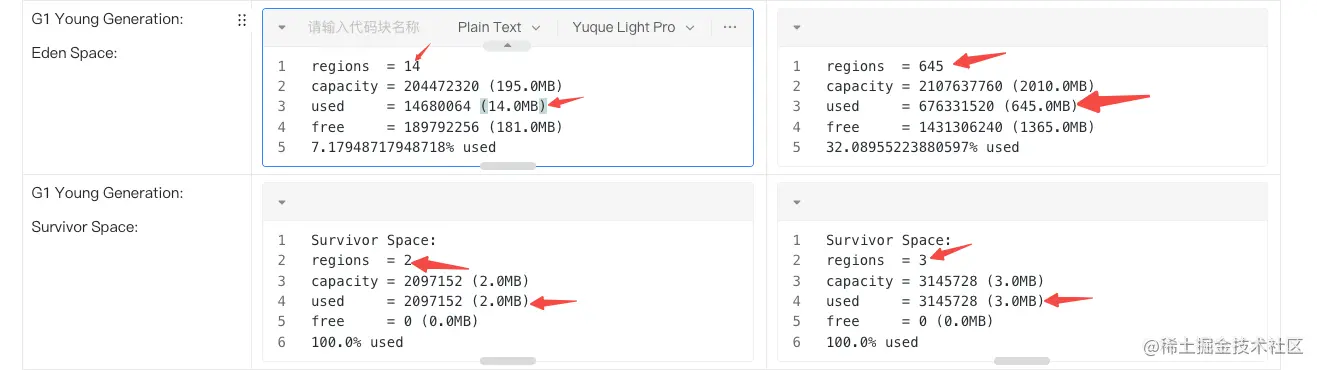
MaxHeapSize 是根据物理机内存决定的(未指定 -Xmx时),所以默认情况下整堆的 region 是固定的;eden 区在 G1 场景下是动态计算的,所以 region 的个数也是有波动的。
基本情况:
- 所有 Heap Region 的大小都是一样的。
- Heap Region 的大小只能为 1MB、2MB、4MB、8MB、16MB 和 32MB ,默认情况下,整个堆空间分为2048 个 Heap Region(该值可以自动根据最小的堆分区大小计算得出)
如何控制 Eden 区的大小 和 region个数
前面介绍了 Eden 区的大小 和 region个数 的默认计算方式,JVM 中对于控制这两个数值对应的参数是
-
Heap Region Size 大小可由以下方式确定:
- 可以通过参数 G1HeapRegionSize 来指定大小,这个参数的默认值为 0。
- 启发式推断,即在不指定 Heap Region 大小的时候,由 G1 启发式地推断 Heap Region 大小
-
控制新生代大小的 JVM 参数:
- MaxNewSize
- NewSize
- G1MaxNewSizePercent
- G1NewSizePercent
关于 Heap Region
如果在启动时设置了最大和最小新生代的大小,若最大值和最小值相等,即固定了新生代的空间,这种情况下预测时间对新生代无效。也就是说,YGC不受预测时间的控制。在这种情况下,要满足预测时间,只能调整新生代的最大值和最小值。
如果没有设置固定的新生代空间,即新生代空间可以自动调整,G1如何满足预测时间?答案是在初始化或者每次YGC结束后,会重新设置新生代分区的数量。这个数量是根据预测时间来设置的。逻辑如下:·首先计算最小分区的数目,其值为Survivor的长度+1,即每次除了 Survivor 外只有一个Eden分区用于数据分配;
如果最小分区数目的收集都不能满足预测时间,则使用最小的分区数目。
计算最大分区的数目,其值为新生代最大分区数目或者除去保留空间的最大自由空间数目的较小值,然后在这个最大值和最小值之间选择一个满足预测时间的合适的值作为新生代分区的数目。
解法
回到 JVM 参数
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=2 -
XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -XX:MaxRAMFraction=1 -
XX:-OmitStackTraceInFastThrow -Dnetworkaddress.cache.ttl=60 -Dsun.net.inetaddr.ttl=60 -
XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseGCLogFileRotation -
XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20m
复制代码
参数解释:
-
-XX:MaxGCPauseMillis=200 可以移除,这个是默认的;
-
-Dnetworkaddress.cache.ttl=60 -Dsun.net.inetaddr.ttl=60 两个是控制JVM DNS 缓存的,不需要关注
-
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20m 和 GC 日志相关,不需要关注
-
-XX:ParallelGCThreads=8 -XX:ConcGCThreads=2 和 GC 线程设置有关,POD 是一样的,影响理论上不构成差异。(G1 GC 下 ConcGCThreads=ParallelGCThreads/4 四舍五入,所以 XX:ConcGCThreads 可以省略 )
-
-XX:+UnlockExperimentalVMOptions : 解锁实验参数,允许使用实验性参数,JVM中有些参数不能通过-XX直接赋值,需要先解锁,比如要使用某些参数的时候,可能不会生效,需要设置这个参数来解锁,这里是用来开启 UseCGroupMemoryLimitForHeap 的
-
-XX:UseCGroupMemoryLimitForHeap -XX:MaxRAMFraction=1 stackoverflow.com/questions/5…
解决思路
初步是先通过调整新生代大小来观察各 POD 的堆使用情况是否能够限制在一个比较合理的范围之后:
- 1、从现象看,eden 区的大小差异比较大,所以第一点是控制下 eden 区的大小,然后进行观察下 runtime 时 GC ,heap 的使用情况。
- 2、eden 区小的 pod gc 频次较高,可以提高 HeapRegionSize 到 2M 进行观察
调整 HeapRegionSize=2M -XX:NewSize=256M -XX:MaxNewSize=512M 后,新生代的整体 heap 占用差距大的问题没有了。
效果跟踪
在调整 HeapRegionSize=2M -XX:NewSize=256M -XX:MaxNewSize=512M 后,新生代的整体 heap 占用差距大的问题没有了。
一些疑问(倔友们可以针对这个给些思路和建议)
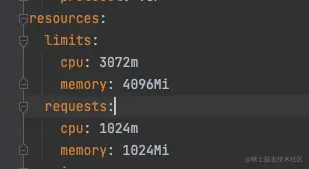
- 1、POD 设置的 resources limit 是 4G,但是实际从监控看, HEAP 的 max 是 5个多 G
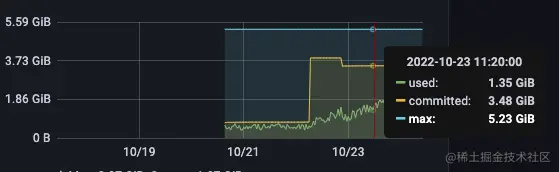
- 2、committed mem 突增,从 200M 直接干到 3G+

- 3、G1 从找到的资料看,已经 committed 的 heap mem 是不会归还给 OS 的(JAVA 12 G1 才支持 openjdk.org/jeps/346,但是从监控数据看,committed 值有回落
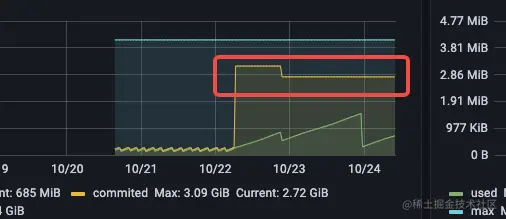
PS: 监控数据是准确的