目录
主流深度学习框架及神经网络模型汇总
一、人工智能的研究领域和分支
二、主流深度学习框架编辑
1.TensorFlow
2.PyTorch
3.PaddlePaddle
4.Keras
5.Caffe/Caffe2
6.MXNet
7.Theano
8.Torch
9.CNTK
10.ONNX
三、深度学习移动端推理框架
1.TensorRT
2.TF-Lite
3.OpenVINO
4.CoreML
5.NCNN
6.MNN
7.Tenigne
8.NNIE
9.RKNN
四、卷积神经网络 – CNN
1.目标检测模型
2.图像分类模型
3.语义分割模型
主流深度学习框架及神经网络模型汇总
一、人工智能的研究领域和分支

二、主流深度学习框架
如果走学术路线,果断PyTorch,如果想走部署,TensorFLow+PaddlePaddle+Caffe。
1.TensorFlow
TensorFlow是Google开发的一款开源软件库,专为深度学习或人工神经网络而设计。TensorFlow允许你可以使用流程图创建神经网络和计算模型。它是可用于深度学习的最好维护和最为流行的开源库之一。TensorFlow框架可以使用C++也可以使用Python。你可以使用TensorBoard进行简单的可视化并查看计算流水线。其灵活的架构允许你轻松部署在不同类型的设备上。不利的一面是,TensorFlow没有符号循环,不支持分布式学习。此外,它还不支持Windows。
- 出生地:Google
- 特点:计算图、分布式训练效果强、底层C构建速度快,生态强大
- 主要调包语言:Python、C/C++、JS
- 评价:对标PyTorch、学术界没市场了、部署更加的方便
- 入门推荐:建议做工程的小伙伴入门,学术界真的马上被PyTorch垄断
2.PyTorch
PyTorch是脸书的框架,前身是Torch,支持动态图,而且提供了Python接口。是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。Python是现在学术界的霸主,对于想要做学术的同学绝对首推(重点)。
- 出生地:FaceBook
- 特点:生态强大、入门爽歪歪、代码量少(重点)
- 主要调包语言:Python、C/C++
- 评价:入门很快、速度有点慢、部署很垃圾、学术界的霸主
- 入门推荐:想要做学术的童鞋绝对首选,几乎现在顶会论文的代码都是这个框架写的,不过想要做部署的还是看看TensorFLow或者PaddlePaddle吧。
3.PaddlePaddle
百度推出的深度学习框架,算是国人最火的深度学习框架了。跟新了2.0的高级API与动态图后,Paddle更加的强大。百度有很多PaddlePaddle的教程,对于初学者来说还是相当不错的。PaddlePaddle有很多便捷的工具,比如detection、cv、nlp、GAN的工具包,也有专门的可视化工具(远离tensorboard的支配)。
- 出生地:百度
- 特点:计算图动态图都支持、有高级API、速度快、部署方便、有专门的平台
- 主要调包语言:Python、C/C++、JS
- 入门推荐:如果没有卡那就非常适合,如果算力不缺,建议先看看PyTorch,当然也可以PaddlePaddle。
4.Keras
Keras可以当成一种高级API,它的后端可以是Theano和tensorFlow(可以想成把TF的很多打包了)。由于是高级API非常的方便,非常适合科研人员上手。
- 作者:Google AI 研究人员 Francois Chollet
- 特点:生态强大、入门爽歪歪、代码量少(重点)
- 主要调包语言:Python、C/C++、JS
- 评价:太适合入门了、速度有点慢、版本得匹配后端框架的版本
- 入门推荐:强推入门首选,但是后续一定要看看算法的底层是怎样工作的。
5.Caffe/Caffe2
Caffe是顶级高校UCB的贾扬清博士开发的,主要是适用于深度学习在计算机视觉的应用。使用Caffe做算法代码量很少,经常就是修修改改就能用,神经网络模型的管理非常的方便,而且算是比较早的部署在各种落地场景中。Caffe2可以理解为一个新版本的Caffe,但是有很多不同,Caffe2后来并入了PyTorch。该工具支持Ubuntu,Mac OS X和Windows等操作系统。
- 作者:UCB 贾扬清博士
- 特点:计算图、部署方便、训练方便、cuDnn与MKL均支持
- 主要调包语言:Python、Matlab脚本、C++
- 评价:卷积人的大爱、环境不好配置、感觉偏底层、Caffe2还是PyTorch
- 入门推荐:不是很建议,真的想了解可以先入门PyTorch
6.MXNet
MXNet 是一个社区维护起来的深度学习框架,后来被亚马逊看上了。有类似于 Theano 和 TensorFlow 的计算图,也有灵活的动态图,摒弃有高级接口方便调用。MXNet的底层为C构建,优化的很好,很多推理框架都能直接转换,非常方便。
- 出生地:社区
- 特点:计算图动态图都支持、有高级API、速度快、部署方便
- 主要调包语言:Python、C/C++、JS(js用的相对少)
- 评价:一定意义上是国人的框架、小团体整的社区维护、文档少生态不行
- 入门推荐:一般。
7.Theano
Theano是07年左右开发的一个多维数组的计算库,支持GPU计算,当时很多人当成“支持GPU的Numpy”,底层优化的非常好,支持导出C的脚本。
- 出生地:蒙特利尔大学
- 特点:计算图、Python+Numpy、源于学术界
- 主要调包语言:Python
- 评价:很臃肿、不支持分布式、被后面的TensorFlow打击的很大
- 入门推荐:绝对不建议,真的要用的话,先学习别的框架再看Github就行了
8.Torch
Torch是一款针对ML算法且又简单易用的开源计算框架。该工具提供了高效的GPU支持,N维数组,数值优化例程,线性代数例程以及用于索引、切片和置换的例程。基于Lua的脚本语言,该工具带有大量预先训练好的模型。这款灵活高效的ML研究工具支持诸如Linux,Android,Mac OS X,iOS和Windows等主流平台。
9.CNTK
Microsoft Cognitive Toolkit是具有C#/C++/Python接口支持的最快的深度学习框架之一。此款开源框架带有强大的C++ API,比TensorFlow更快、更准确。该工具还支持内置数据读取器的分布式学习。它支持诸如前馈,CNN,RNN,LSTM和序列到序列等算法。该工具支持Windows和Linux。
- 出生地:微软
- 特点:非常严谨、语音上有一些优势、难度有点高
- 调包语言:C++、Python
- 评价:语音上不错呀、微软推不下去了、感觉不如TensorFlow、有点复古
- 入门推荐:不建议,看看就好。
10.ONNX
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。用大白话说就是是一个中间件,比如你PyTorch的模型想转换别的,就得通过ONNX,现在有的框架可以直接转,但是在没有专门支持的时候,ONNX就非常重要了,万物先转ONNX,ONNX再转万物。ONNX本身也有自己的模型库以及很多开源的算子,所以用起来门槛不是那么高。
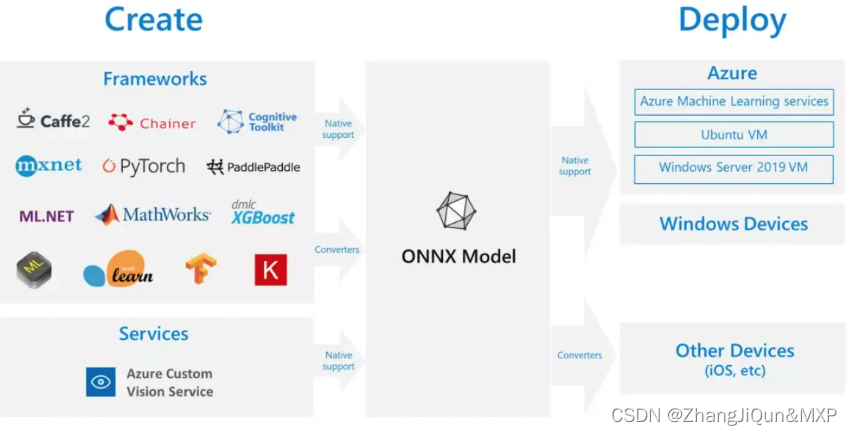

- 出生地:有点多,很多大厂一起整的
- 特点:万能转换
- 主要调包语言:Python、C/C++
- 入门推荐:感觉不用刻意去学习,用到了再看就可以的
三、深度学习移动端推理框架
一些框架是面向算力有限的设备上做模型部署的,比如嵌入式设备、机器人或者移动设备上。
1.TensorRT
TensorRT是NVIDIA公司推出的面向GPU算力的推理框架,在服务端和嵌入式设备上都有非常好的效果,但是底层不开源。TensorRT的合作方非常的多,主流的框架都支持。如果有GPU的话,传统的算子可以用CUDA,深度学习搞成TensorRT。
- 出生地:NVIDIA
- 特点:自产自销NVIDIA不多解释,框架支持很多,生态很棒,稳定性高
- 主要调包语言:Python、C/C++
- 推荐平台:NVIDIA Jetson系列的嵌入式、NVIDIA的GPU(一条龙)
- 支持模型:TensorFlow1.x、TensorFlow2.x、PyTorch、ONNX、PaddlePaddle、MXNet、Caffe、Theano,Torch,Lasagne,Blocks。
- 入门推荐:非常适合入门,毕竟直接在自己的GPU上做测试就行。
2.TF-Lite
TF-Lite是谷歌针对移动端的推理框架,非常的强大。强大的原因在于Keras、TensorFlow的模型都能使用,而且有专门的TPU和安卓平台,这种一条龙的服务让TensorFlow在部署方面还在称霸。TF-Lite如果用Keras、TensorFlow的模型去转换一般来说都是脚本直接开搞,自己重构的部分相对少很多。
- 出生地:Google
- 特点:一条龙的服务专属平台
- 主要调包语言:Python、C/C++、Java
- 支持模型:Keras、TensorFlow、ONNX
- 推荐平台:几乎所有的ARM处理器和微控制器(树莓派,甚至单片机)、TPU专享
- 入门推荐:TFboys(TensorFlow使用者)的必备,毕竟一条龙,还有机会了解TPU,非常贴心。
3.OpenVINO
OpenVINO是Intel的推理框架,一个超级强的推理部署工具。工具包中提供了很多便利的工具,例如OpenVINO提供了深度学习推理套件(DLDT),该套件可以将各种开源框架训练好的模型进行线上部署,除此之外,还包含了图片处理工具包OpenCV,视频处理工具包Media SDK。如果是针对Intel的加速棒或者工控机上部署真的是非常不错的。
- 出生地:Intel
- 特点:面向Intel设备的加速,便捷使用,安装和SDK很方便
- 主要调包语言:C/C++、Python
- 支持模型:TensorFlow、PyTorch、ONNX、MXNet、PaddlePaddle
- 推荐平台:自己的电脑、Intel神经网络加速棒、Intel的FPGA
- 入门推荐:作为入门的不啊还是不错的,只是落地场景有点少,毕竟现在是边缘设备的时代
因为工业上工控机多但是深度学习模型用的还是少,很多都是传统的算法,很多落地场景中上Intel的处理器并不占优势。
4.CoreML
CoreML是苹果公司推出针对ios以及macOS系统部署的机器学习平台,底层不开源。在苹果设备上,CoreML的速度是最快的,但是也只能用于苹果的设备上。现在开发apple app主要是Swift,受到Swift出的特性,真的是各种语言各种粘,很好入门。
- 出生地:Apple
- 特点:面向苹果设备,专业设备上速度第一,稳定、入门简单
- 主要调包语言:C/C++、Python、Obj-C、Swift
- 支持模型:TensorFlow、ONNX、PyTorch、ONNX、MXNet、Caffe
- 推荐平台:iMac、MacBook、iPhone、iPad、AppleWatch
- 入门推荐:针对Apple的开发者,业余选手得买个MBP
5.NCNN
NCNN是腾讯推出的推理框架,一定意义上是之前使用非常广的一个推理框架,社区做的也非常棒。NCNN的速度是超过TFLite的,但是有点麻烦的是之前得经常自己用C去复现一些算子(框架起步都这样),现在因为使用的人数很多,因此算子很多。NCNN对于X86、GPU均有支持,在嵌入式、手机上的表现非常好。
- 出生地:腾讯优图实验室
- 特点:面向移动端的加速、手机处理器的加速单元支持很棒
- 主要调包语言:C/C++、Python
- 支持模型:TensorFlow、ONNX、PyTorch、ONNX、MXNet、DarkNet、Caffe
- 推荐平台:安卓/苹果手机、ARM处理器设备
- 入门推荐:对于嵌入式或者APP开发有经验的同学绝对首推的
6.MNN
MNN是阿里巴巴推出的移动端框架,现在也支持模型训练,支持OpenCL,OpenGL,Vulkan和Metal等。同样的设备,MNN的部署速度是非常快的,树莓派3B上cpu的加速是NCNN速度的3被以上,而且文档非常的全,代码整洁清晰,非常适合开发者使用。
- 出生地:阿里巴巴多部门合作
- 特点:面向移动端的加速、应该是现在速度之最
- 主要调包语言:C/C++、Python
- 支持模型:TensorFlow、ONNX、PyTorch、MXNet、NCNN、Caffe、TF-Lite
- 推荐平台:安卓/苹果手机、ARM处理器设备
- 入门推荐:首推的部署推理框架,绝对的好用,在苹果设备上的速度也很棒。MNN框架感觉比NCNN稳定一些,而且源码非常整洁,研究底层也是非常方便。
7.Tenigne
Tenigne-Lite是OpenAILab推出的边缘端推理部署框架,OpenCV官方在嵌入式上的部署首推Tenigne-Lite。现在对于RISC-V、CUDA、TensorRT、NPU的支持非常不错。Tengine是现在来说感觉安装环境中bug最少的框架,几乎安按照文档走不会出问题的。
- 出生地:OpenAILab
- 特点:面向移动端的加速、速度和MNN不相上下、对于嵌入式的支持非常好
- 主要调包语言:C/C++、Python
- 支持模型:TensorFlow、ONNX、DarkNet、MXNet、NCNN、Caffe、TF-Lite、NCNN
- 推荐平台:安卓手机、ARM处理器设备、RISC-V
- 入门推荐:嵌入式开发的小伙伴还等什么,干就完了
Tengine-Lite是个朝气蓬勃的框架,虽然出的时间并没有其他框架早,但是框架性能、易用性还是非常适合嵌入式玩家的。
8.NNIE
NNIE 即 Neural Network Inference Engine,是海思 SVP 开发框架中的处理单元之一,主要针对深度学习卷积神经网络加速处理的硬件单元,可用于图片分类、目标检测等 AI 应用场景。


支持现有大部分公开的卷积神经网络模型,如 AlexNet、VGG16、ResNet18、ResNet50、GoogLeNet 等分类网络,Faster R-CNN、YOLO、SSD、RFCN 等检测目标网络,以及 FCN 、SegNet 等分割场景网络。目前 NNIE 配套软件及工具链仅支持以 Caffe 框架,使用其他框架的网络模型需要转化为 Caffe 框架下的模型。
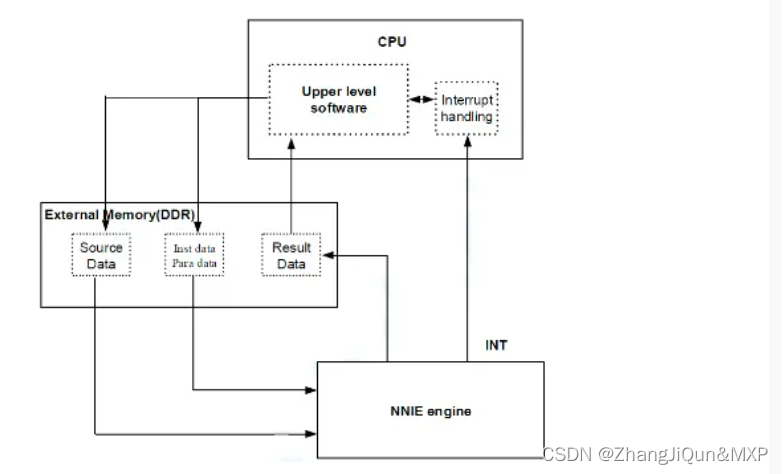

华为海思NNIE非常强大,之前移动端真的快霸主,但是现在受制约芯片停产。
9.RKNN
Rockchip提供RKNN-Toolkit开发套件进行模型转换、推理运行和性能评估。
-
模型转换:支持 Caffe、Tensorflow、TensorFlow Lite、ONNX、Darknet 模型,支持RKNN 模型导入导出,后续能够在硬件平台上加载使用。
-
模型推理:能够在 PC 上模拟运行模型并获取推理结果,也可以在指定硬件平台RK3399Pro Linux上运行模型并获取推理结果。
-
性能评估:能够在 PC 上模拟运行并获取模型总耗时及每一层的耗时信息,也可以通过联机调试的方式在指定硬件平台 RK3399Pro Linux上运行模型,并获取模型在硬件上运行时的总时间和每一层的耗时信息。
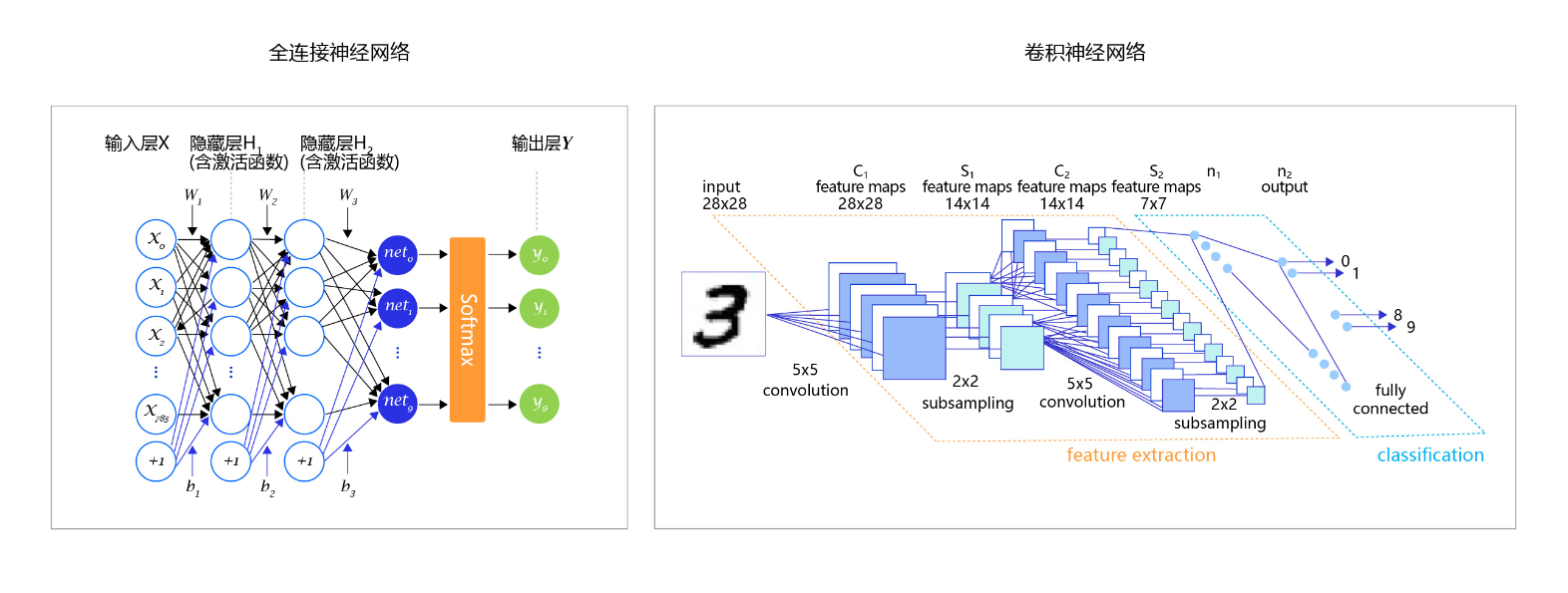
四、卷积神经网络 – CNN
https://easyai.tech/ai-definition/cnn/#zuoyong
CNN 的基本原理:
- 卷积层 – 主要作用是保留图片的特征
- 池化层 – 主要作用是把数据降维,可以有效的避免过拟合
- 全连接层 – 根据不同任务输出我们想要的结果
CNN 的实际应用:
- 图像分类、检索
- 目标检测
- 目标分割(语义分割、实例分割、全景分割)
- 人脸识别
- 骨骼识别
Object detection: speed and accuracy comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3)
1.目标检测模型
判断是图片里面有什么,分别在哪里。
https://github.com/hoya012/deep_learning_object_detection

image
模型性能对比表
| Detector | VOC07 (mAP@IoU=0.5) | VOC12 (mAP@IoU=0.5) | COCO (mAP@IoU=0.5:0.95) | Published In |
|---|---|---|---|---|
| R-CNN | 58.5 | - | - | CVPR'14 |
| SPP-Net | 59.2 | - | - | ECCV'14 |
| MR-CNN | 78.2 (07+12) | 73.9 (07+12) | - | ICCV'15 |
| Fast R-CNN | 70.0 (07+12) | 68.4 (07++12) | 19.7 | ICCV'15 |
| Faster R-CNN | 73.2 (07+12) | 70.4 (07++12) | 21.9 | NIPS'15 |
| YOLO v1 | 66.4 (07+12) | 57.9 (07++12) | - | CVPR'16 |
| G-CNN | 66.8 | 66.4 (07+12) | - | CVPR'16 |
| AZNet | 70.4 | - | 22.3 | CVPR'16 |
| ION | 80.1 | 77.9 | 33.1 | CVPR'16 |
| HyperNet | 76.3 (07+12) | 71.4 (07++12) | - | CVPR'16 |
| OHEM | 78.9 (07+12) | 76.3 (07++12) | 22.4 | CVPR'16 |
| MPN | - | - | 33.2 | BMVC'16 |
| SSD | 76.8 (07+12) | 74.9 (07++12) | 31.2 | ECCV'16 |
| GBDNet | 77.2 (07+12) | - | 27.0 | ECCV'16 |
| CPF | 76.4 (07+12) | 72.6 (07++12) | - | ECCV'16 |
| R-FCN | 79.5 (07+12) | 77.6 (07++12) | 29.9 | NIPS'16 |
| DeepID-Net | 69.0 | - | - | PAMI'16 |
| NoC | 71.6 (07+12) | 68.8 (07+12) | 27.2 | TPAMI'16 |
| DSSD | 81.5 (07+12) | 80.0 (07++12) | 33.2 | arXiv'17 |
| TDM | - | - | 37.3 | CVPR'17 |
| FPN | - | - | 36.2 | CVPR'17 |
| YOLO v2 | 78.6 (07+12) | 73.4 (07++12) | - | CVPR'17 |
| RON | 77.6 (07+12) | 75.4 (07++12) | 27.4 | CVPR'17 |
| DeNet | 77.1 (07+12) | 73.9 (07++12) | 33.8 | ICCV'17 |
| CoupleNet | 82.7 (07+12) | 80.4 (07++12) | 34.4 | ICCV'17 |
| RetinaNet | - | - | 39.1 | ICCV'17 |
| DSOD | 77.7 (07+12) | 76.3 (07++12) | - | ICCV'17 |
| SMN | 70.0 | - | - | ICCV'17 |
| Light-Head R-CNN | - | - | 41.5 | arXiv'17 |
| YOLO v3 | - | - | 33.0 | arXiv'18 |
| SIN | 76.0 (07+12) | 73.1 (07++12) | 23.2 | CVPR'18 |
| STDN | 80.9 (07+12) | - | - | CVPR'18 |
| RefineDet | 83.8 (07+12) | 83.5 (07++12) | 41.8 | CVPR'18 |
| SNIP | - | - | 45.7 | CVPR'18 |
| Relation-Network | - | - | 32.5 | CVPR'18 |
| Cascade R-CNN | - | - | 42.8 | CVPR'18 |
| MLKP | 80.6 (07+12) | 77.2 (07++12) | 28.6 | CVPR'18 |
| Fitness-NMS | - | - | 41.8 | CVPR'18 |
| RFBNet | 82.2 (07+12) | - | - | ECCV'18 |
| CornerNet | - | - | 42.1 | ECCV'18 |
| PFPNet | 84.1 (07+12) | 83.7 (07++12) | 39.4 | ECCV'18 |
| Pelee | 70.9 (07+12) | - | - | NIPS'18 |
| HKRM | 78.8 (07+12) | - | 37.8 | NIPS'18 |
| M2Det | - | - | 44.2 | AAAI'19 |
| R-DAD | 81.2 (07++12) | 82.0 (07++12) | 43.1 | AAAI'19 |
| ScratchDet | 84.1 (07++12) | 83.6 (07++12) | 39.1 | CVPR'19 |
| Libra R-CNN | - | - | 43.0 | CVPR'19 |
| Reasoning-RCNN | 82.5 (07++12) | - | 43.2 | CVPR'19 |
| FSAF | - | - | 44.6 | CVPR'19 |
| AmoebaNet + NAS-FPN | - | - | 47.0 | CVPR'19 |
| Cascade-RetinaNet | - | - | 41.1 | CVPR'19 |
| HTC | - | - | 47.2 | CVPR'19 |
| TridentNet | - | - | 48.4 | ICCV'19 |
| DAFS | 85.3 (07+12) | 83.1 (07++12) | 40.5 | ICCV'19 |
| Auto-FPN | 81.8 (07++12) | - | 40.5 | ICCV'19 |
| FCOS | - | - | 44.7 | ICCV'19 |
| FreeAnchor | - | - | 44.8 | NeurIPS'19 |
| DetNAS | 81.5 (07++12) | - | 42.0 | NeurIPS'19 |
| NATS | - | - | 42.0 | NeurIPS'19 |
| AmoebaNet + NAS-FPN + AA | - | - | 50.7 | arXiv'19 |
| SpineNet | - | - | 52.1 | arXiv'19 |
| CBNet | - | - | 53.3 | AAAI'20 |
| EfficientDet | - | - | 52.6 | CVPR'20 |
| DetectoRS | - | - | 54.7 | arXiv'20 |
2.图像分类模型
图像分类是对图像判断出所属的分类,比如在学习分类中数据集有人(person)、羊(sheep)、狗(dog)和猫(cat)四种。
https://github.com/weiaicunzai/awesome-image-classification
| ConvNet | ImageNet top1 acc | ImageNet top5 acc | Published In |
|---|---|---|---|
| Vgg | 76.3 | 93.2 | ICLR2015 |
| GoogleNet | - | 93.33 | CVPR2015 |
| PReLU-nets | - | 95.06 | ICCV2015 |
| ResNet | - | 96.43 | CVPR2015 |
| PreActResNet | 79.9 | 95.2 | CVPR2016 |
| Inceptionv3 | 82.8 | 96.42 | CVPR2016 |
| Inceptionv4 | 82.3 | 96.2 | AAAI2016 |
| Inception-ResNet-v2 | 82.4 | 96.3 | AAAI2016 |
| Inceptionv4 + Inception-ResNet-v2 | 83.5 | 96.92 | AAAI2016 |
| RiR | - | - | ICLR Workshop2016 |
| Stochastic Depth ResNet | 78.02 | - | ECCV2016 |
| WRN | 78.1 | 94.21 | BMVC2016 |
| SqueezeNet | 60.4 | 82.5 | arXiv2017(rejected by ICLR2017) |
| GeNet | 72.13 | 90.26 | ICCV2017 |
| MetaQNN | - | - | ICLR2017 |
| PyramidNet | 80.8 | 95.3 | CVPR2017 |
| DenseNet | 79.2 | 94.71 | ECCV2017 |
| FractalNet | 75.8 | 92.61 | ICLR2017 |
| ResNext | - | 96.97 | CVPR2017 |
| IGCV1 | 73.05 | 91.08 | ICCV2017 |
| Residual Attention Network | 80.5 | 95.2 | CVPR2017 |
| Xception | 79 | 94.5 | CVPR2017 |
| MobileNet | 70.6 | - | arXiv2017 |
| PolyNet | 82.64 | 96.55 | CVPR2017 |
| DPN | 79 | 94.5 | NIPS2017 |
| Block-QNN | 77.4 | 93.54 | CVPR2018 |
| CRU-Net | 79.7 | 94.7 | IJCAI2018 |
| ShuffleNet | 75.3 | - | CVPR2018 |
| CondenseNet | 73.8 | 91.7 | CVPR2018 |
| NasNet | 82.7 | 96.2 | CVPR2018 |
| MobileNetV2 | 74.7 | - | CVPR2018 |
| IGCV2 | 70.07 | - | CVPR2018 |
| hier | 79.7 | 94.8 | ICLR2018 |
| PNasNet | 82.9 | 96.2 | ECCV2018 |
| AmoebaNet | 83.9 | 96.6 | arXiv2018 |
| SENet | - | 97.749 | CVPR2018 |
| ShuffleNetV2 | 81.44 | - | ECCV2018 |
| IGCV3 | 72.2 | - | BMVC2018 |
| MnasNet | 76.13 | 92.85 | CVPR2018 |
| SKNet | 80.60 | - | CVPR2019 |
| DARTS | 73.3 | 91.3 | ICLR2019 |
| ProxylessNAS | 75.1 | 92.5 | ICLR2019 |
| MobileNetV3 | 75.2 | - | arXiv2019 |
| Res2Net | 79.2 | 94.37 | arXiv2019 |
| EfficientNet | 84.3 | 97.0 | ICML2019 |
3.语义分割模型
语义分割(semantic segmentation)就是需要区分到图中每一点像素点,而不仅仅是矩形框框住了。但是同一物体的不同实例不需要单独分割出来。对下图左,标注为人,羊,狗,草地。而不需要羊1,羊2,羊3,羊4,羊5等。

- FCN
- SegNet
- U-Net
- Dilated Convolutions
- DeepLab (v1 & v2)
- RefineNet
- PSPNet
- Large Kernel Matters
- DeepLab v3
主流深度学习框架及神经网络模型汇总 - 简书





![10万字智慧政务大数据平台项目建设方案222页[Word]](https://img-blog.csdnimg.cn/img_convert/2dc2c6ade877991a5dc7888403cfbc68.jpeg)