仅供个人复习,
C语言IO占位符表
| %d | 十进制整数(int) |
|---|---|
| %ld | long |
| %lld | long long |
| %u | unsigned int |
| %o | 八进制整型 |
| %x | 十六进制整数/字符串地址 |
| %c | 单个字符 |
| %s | 字符串 |
| %f | float,默认保留6位 |
| %lf | double |
| %e | 科学计数法 |
| %g | 根据大小自动选取f或e格式,去掉无效0 |
转义符表
转义符可以取消关键字符的特殊性,下面是常见的转义符使搭配
printf("\b");//退格符
printf("\n");//换行
printf("\a");//响铃,电脑真的响一下,不可思议
printf("\t");//水平制表符
printf("\v");//垂直制表符
printf("\130");//输出char对应130的字符
printf("%% %d",12);//%的转义使用%,而不是\
C/C++ 语言数据类型大小
ANSI/ISO规范
sizeof(short int)<=sizeof(int)
sizeof(int)<=sizeof(long int) short
int至少应为16位(2字节)
long int至少应为32位。
16位编译器
| 数据类型 | 字节数 |
|---|---|
| char | 1 |
| short | 2 |
| int | 2 |
| long | 4 |
| float | 4 |
| double | 8 |
| bool | 1 |
| 指针 | 2 |
32位编译器
| 数据类型 | 字节数 |
|---|---|
| char | 1 |
| short | 2 |
| int | 4 |
| long | 4 |
| long long | 8 |
| float | 4 |
| double | 8 |
| bool | 1 |
| long double | 12 |
| 指针 | 4 |
64位编译器
| 数据类型 | 字节数 |
|---|---|
| char | 1 |
| short | 2 |
| int | 4 |
| long | 8 |
| long long | 8 |
| float | 4 |
| double | 8 |
| bool | 1 |
| long double | 16 |
| 指针 | 8 |
宏函数和内联函数的区别
宏函数(Macro Functions):
-
替换规则:在编译预处理阶段的简单文本替换
-
参数展开:没有参数类型检查
-
适用场景:简单的、短小的代码片段,例如进行简单的数学计算、位操作等。
内联函数(Inline Functions):
-
替换规则:编译阶段处理。编译器会尝试将函数调用处直接替换为函数体。
-
参数类型检查:参数和返回值检查与正常函数无异
-
适用场景:内联函数适用于较短小的函数,包含一些简单的代码逻辑,且频繁调用的情况。
-
推荐用法:一般来说,内联函数应该是在类的定义中实现的,以便于对其进行封装和管理,或者在头文件中避免函数重定义问题。inline关键字只能建议编译器进行内联,是否采纳取决于编译器
内联函数可以优化函数进入和离开的开销,但内联可能会导致编译后的代码体积增大,宏函数的使用更需要小心,因为它在文本替换阶段可能会引发一些意想不到的问题。
差异案例
#include <iostream>
#define SQUARE_MACRO(x) x * x
inline int square_inline(int x) {
return x * x;
}
int main() {
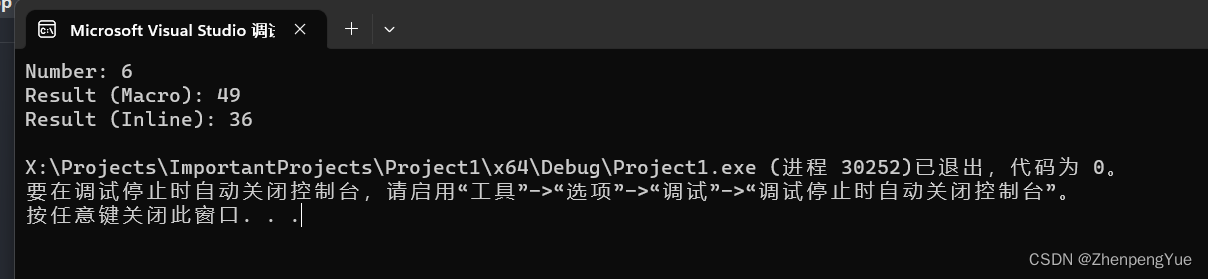
int num = 5;
// result = (++num) * (++num) 直接把参数替换进函数
int result_macro = SQUARE_MACRO(++num); // 使用宏函数
num = 5;
//先自增再传入
int result_inline = square_inline(++num); // 使用内联函数
std::cout << "Number: " << num << std::endl;
std::cout << "Result (Macro): " << result_macro << std::endl;
std::cout << "Result (Inline): " << result_inline << std::endl;
return 0;
}
STL标准库
vector
优点:
- 内存是连续分配的,访问元素的速度较快。
- 在末尾插入和删除元素的时间复杂度为常数。
缺点:
- 在中间插入或删除元素的时间复杂度较高,需要移动后续元素。
- 在内存不足时,可能会导致重新分配内存和复制元素。
#include <vector>
std::vector<int> v;
v.push_back(10); // 在末尾插入元素
v.pop_back(); // 删除末尾的元素
v.size(); // 返回容器中的元素数量
v.empty(); // 检查容器是否为空
v.clear(); // 清空容器中的所有元素
v.at(index); // 访问指定索引的元素
v.front(); // 访问首元素
v.back(); // 访问末尾元素
v.begin(); // 返回指向容器第一个元素的迭代器
v.end(); // 返回指向容器最后一个元素之后的迭代器
list
优点:
- 支持在任意位置快速插入和删除元素。
- 在中间插入和删除元素的时间复杂度为常数。
缺点:
- 元素在内存中不连续存储,访问元素的速度慢。
- 占用更多内存,每个节点需要存储额外的指针。
#include <list>
std::list<int> lst;
lst.push_back(10); // 在末尾插入元素
lst.push_front(20); // 在开头插入元素
lst.pop_back(); // 删除末尾的元素
lst.pop_front(); // 删除开头的元素
lst.size(); // 返回容器中的元素数量
lst.empty(); // 检查容器是否为空
lst.clear(); // 清空容器中的所有元素
lst.front(); // 访问首元素
lst.back(); // 访问末尾元素
lst.begin(); // 返回指向容器第一个元素的迭代器
lst.end(); // 返回指向容器最后一个元素之后的迭代器
forawrd_list
与list类似,仅支持单向访问,效率更佳一些
#include <forward_list>
std::forward_list<T> fl;
fl.push_front(const value_type& value); // 在头部插入元素
fl.pop_front(); // 从头部删除元素
fl.insert_after(pos, const value_type& value); // 在指定位置后插入元素
fl.erase_after(pos); // 在指定位置后删除元素
fl.front(); // 访问第一个元素
fl.begin(); // 返回指向第一个元素的迭代器
fl.end(); // 返回指向最后一个元素之后的迭代器
deque
优点:
- 支持在两端快速插入和删除元素。
- 内存是分块分配的,访问元素的速度较快。
缺点:
- 难以在中间插入或删除元素
- 存储多个分块,占用较多内存
#include <deque>
std::deque<int> dq;
dq.push_back(10); // 在末尾插入元素
dq.push_front(20); // 在开头插入元素
dq.pop_back(); // 删除末尾的元素
dq.pop_front(); // 删除开头的元素
dq.size(); // 返回容器中的元素数量
dq.empty(); // 检查容器是否为空
dq.clear(); // 清空容器中的所有元素
dq.front(); // 访问首元素
dq.back(); // 访问末尾元素
dq.begin(); // 返回指向容器第一个元素的迭代器
dq.end(); // 返回指向容器最后一个元素之后的迭代器
map
优点:
- 存储键值对,支持按键进行高效的查找和插入。
- 根据键的顺序遍历元素。
缺点:
- 内存使用较多,每个键值对都需要额外的内存存储键。
- 没有连续存储,访问元素的速度相对较慢。
#include <map>
std::map<std::string, int> m;
m["one"] = 1; // 插入键值对
m["two"] = 2;
m.find(const key_type& k); // 查找键的位置
m.count(const key_type& k); // 计算具有特定键的元素数量
m.size(); // 返回容器中的键值对数量
m.empty(); // 检查容器是否为空
m.clear(); // 清空容器中的所有键值对
m.begin(); // 返回指向容器第一个键值对的迭代器
m.end(); // 返回指向容器最后一个键值对之后的迭代器
set
优点:
- 存储唯一的元素,支持按值进行高效的查找和插入。
缺点:
- 内存使用较多,每个元素都需要额外的内存存储。
- 不连续存储,访问元素的速度相对较慢。
#include <set>
std::set<int> s;
s.insert(const value_type& val); // 插入元素
s.find(const key_type& k); // 查找元素
s.size(); // 返回容器中的元素数量
s.empty(); // 检查容器是否为空
s.clear(); // 清空容器中的所有元素
s.begin(); // 返回指向容器第一个元素的迭代器
s.end(); // 返回指向容器最后一个元素之后的迭代器
unordered_map (C++11)
优点:
- 使用哈希表实现,支持快速的查找和插入操作,平均时间复杂度为常数。
- 对于大数据集,查找效率高于std::map。
缺点:
- 内存占用较高,需要存储哈希表和键值对。
- 不保证元素的顺序。
#include <unordered_map>
std::unordered_map<std::string, int> um;
um["one"] = 1; // 插入键值对
um["two"] = 2;
um.find(const key_type& k); // 查找键的位置
um.count(const key_type& k); // 计算具有特定键的元素数量
um.size(); // 返回容器中的键值对数量
um.empty(); // 检查容器是否为空
um.clear(); // 清空容器中的所有键值对
um.begin(); // 返回指向容器第一个键值对的迭代器
um.end(); // 返回指向容器最后一个键值对之后的迭代器
unordered_set (C++11)
优点:
- 使用哈希表进行实现,支持快速的查找和插入操作,平均时间复杂度为常数。
- 对于大数据集,查找效率高于std::set。
缺点:
- 内存占用较高,因为需要存储哈希表和元素。
- 不保证元素的顺序。
#include <unordered_set>
std::unordered_set<int> us;
us.insert(const value_type& val); // 插入元素
us.find(const key_type& k); // 查找元素
us.size(); // 返回容器中的元素数量
us.empty(); // 检查容器是否为空
us.clear(); // 清空容器中的所有元素
us.begin(); // 返回指向容器第一个元素的迭代器
us.end(); // 返回指向容器最后一个元素之后的迭代器
stack
#include <stack>
std::stack<T> s;
s.push(const value_type& value); // 将元素压入堆栈顶部
s.pop(); // 弹出堆栈顶部的元素
s.top(); // 访问堆栈顶部的元素
s.empty(); // 检查堆栈是否为空
s.size(); // 返回堆栈中元素的数量
queue
#include <queue>
std::queue<T> q;
q.push(const value_type& value); // 将元素推入队列尾部
q.pop(); // 从队列头部弹出元素
q.front(); // 访问队列头部元素
q.back(); // 访问队列尾部元素
q.empty(); // 检查队列是否为空
q.size(); // 返回队列中元素的数量
priority_queue
#include <queue>
std::priority_queue<T> pq;
pq.push(const value_type& value); // 将元素推入优先队列
pq.pop(); // 从优先队列中弹出元素
pq.top(); // 访问优先队列中优先级最高的元素
pq.empty(); // 检查优先队列是否为空
pq.size(); // 返回优先队列中元素的数量
#include <iostream>
#include <queue>
#include <vector>
struct MyStruct {
int value;
// 比较操作符,根据 value 来比较 ,越大优先级越高
bool operator<(const MyStruct& other) const {
return value < other.value;
}
};
int main() {
std::priority_queue<MyStruct> pq;
pq.push({5});
pq.push({2});
pq.push({8});
pq.push({1});
// 遍历优先队列按优先级输出
while (!pq.empty()) {
std::cout << pq.top().value << " ";
pq.pop();
}
return 0;
}
// 8 5 2 1
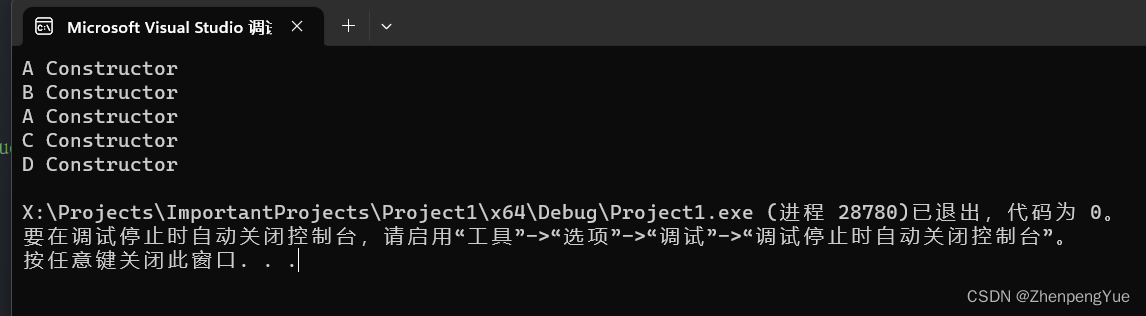
构造函数执行顺序
- 先成员的构造,再当前类型的构造
- 父类构造优先于子类构造
- 成员初始化按书写顺序,低于构造顺序
- 虚基类只构造一次,非虚构造两次
例题:问输出结果是多少
#include <iostream>
class A {
public:
A() {
std::cout << "A Constructor" << std::endl;
}
};
class B : public A {
public:
B() {
std::cout << "B Constructor" << std::endl;
}
};
class C : public A {
public:
C() {
std::cout << "C Constructor" << std::endl;
}
};
class D : public B, public C {
public:
D() {
std::cout << "D Constructor" << std::endl;
}
};
int main() {
D d;
return 0;
}
智能指针
- std::shared_ptr:允许多个智能指针共享同一个对象,通过引用计数来管理对象的生命周期。当最后一个引用被释放时,对象会被销毁。
auto sp = std::make_shared<int>(); // 分配堆空间,创建智能指针
auto sp2 = sp; // 创建另一个智能指针
-
std::unique_ptr:用于独占地拥有一个对象,不能被多个智能指针共享。它提供了更轻量级的智能指针,适用于不需要共享所有权的情况。
-
std::weak_ptr:用于解决std::shared_ptr的循环引用问题。它可以与std::shared_ptr一起使用,但不会增加对象的引用计数。
今天到这里,改日再更






![【java】【项目实战】[外卖六]套餐管理业务开发](https://img-blog.csdnimg.cn/0249b1eec7fd447394a4a742c7b409f6.png)