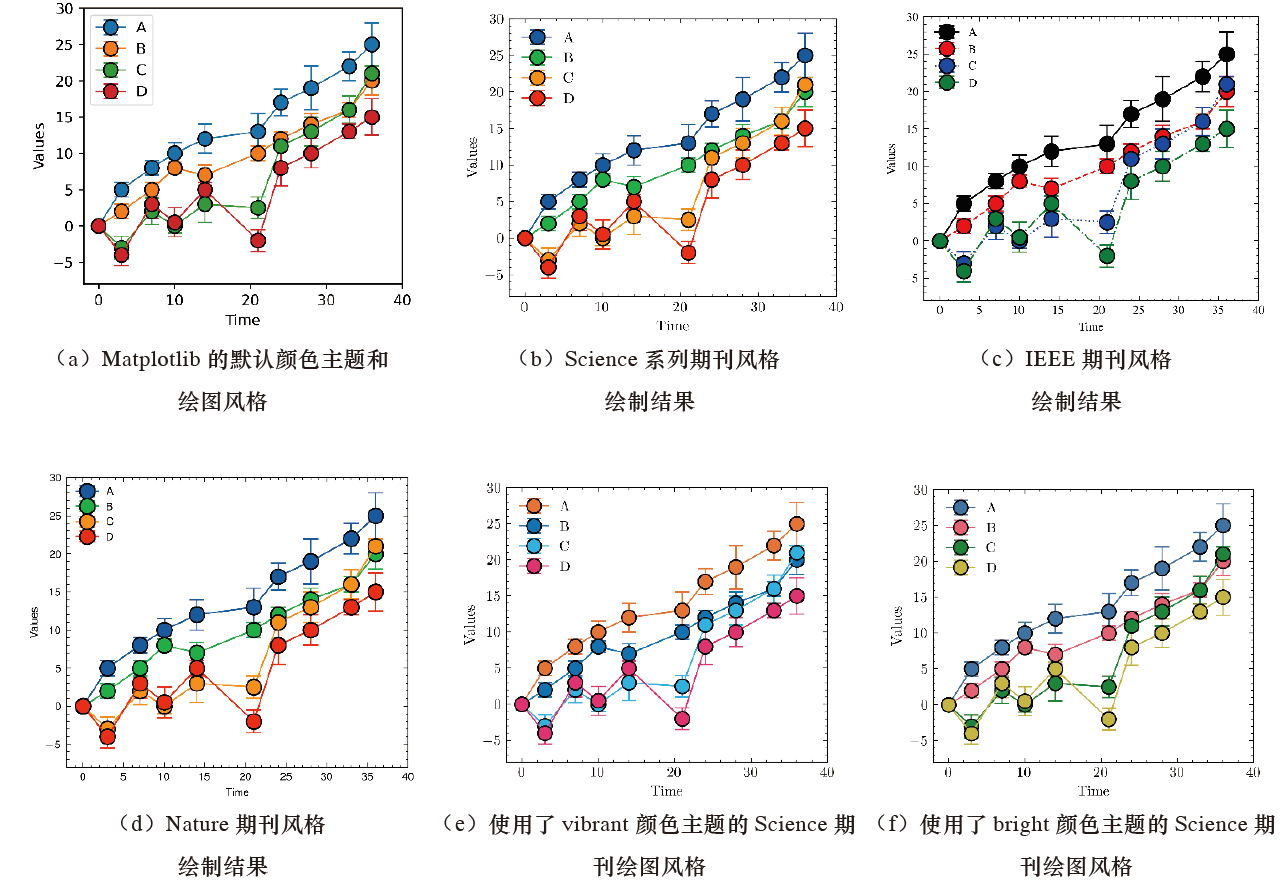
文章目录
- 前言
- 论文阅读
- 摘要
- 介绍
- 模型
- 算法
- 总结
前言
本周学习了GAN论文《Generative Adversarial Nets》,了解GAN主要由两部分组成:生成器和判别器,知道生成器G和判别器D的作用及原理,相比于其他的生成模型,了解GAN的优势和不足分别是什么。
This week, I study the paper about GAN and learn that GAN are mainly composed of two parts: generator and discriminator. I also learn about the functions and principles of generator and discriminator, and explore the advantages and disadvantages of GAN compared to other Generative models.
论文阅读
机器学习有两大类模型:
• 分辨模型,判断数据类别或预测一个实数值
• 生成模型,怎样生成数据本身
标题 Generative Adversarial Nets (GAN)
作者 Ian J. Goodfellow∗ , Jean Pouget-Abadie† , Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair‡ , Aaron Courville, Yoshua Bengio§
摘要
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptions, the entire system can be trained with backpropagation.There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
我们提出了一个通过对抗过程来估计生成模型的新框架,其中我们同时训练两个模型:捕获整个数据分布的生成模型G(对整个数据的分布进行建模,使得你能够生成各种分布)和估计样本来自训练数据而不是G的概率的判别模型D。G的训练过程是尽量的想让你的辨别模型犯错。这个框架对应于一个极大极小的二人博弈。在任意函数G和D的空间中,存在一个唯一解,这个解是代表既能够把你整个训练数据的真实分布给找出来。D是辨别模型,因为已经把真实数据给挖掘出来了,辨别模型基本做不了什么事情。如果G、D是MLP的话,整个系统就可以通过一个误差反传来整个进行训练。这里我们不需要使用任何的马尔科夫链或者说对一个近似的推理过程展开,实验效果非常好。
介绍
深度学习在生成模式上进展不多,我们要去近似分布来计算似然函数,这篇文章不用近似的似然函数的方法,使用别的方法得到一个计算更好的模型。
GAN介绍:框架里面有两类模型,生成模型(类似于造假的人产生假币)和判别模型(任务是找出假币和真币区分开来),通过不断的学习,造假者提高造假的能力,警察提高判别真假币的能力,最后希望造假者能赢,造的钱币和真的一样,警察没有能力分辨真币和假币,这时我们就可以来生成跟真实一样的数据。
框架里的生成模型是一个MLP,它的输入是一个随机噪声,MLP能够把产生随机噪音的分布(通常是一个高斯分布)可以映射到任何一个我们想去拟合的分布。同样,如果判别模型也是MLP,因为两个模型都是基于MLP的,在训练的时候可以直接通过误差的反向传递,从而不需要通过向使用马尔科夫链一样的算法来对一个分布进行复杂的采样,从而导致在计算上有优势。
相关工作
之前的方法是想去构造这个分布函数,把函数提供一些参数让他学习,这些参数通过最大化它的对数似然函数来做。这些方法计算困难,但这篇论文没有构造分布,通过学习模型来近似结果,弊端就是不知道最后的分布是什么。
模型
这个框架最简单的应用是当生成器和辨别器都是MLP的时候,生成器要去在数据X上学一个Pg的分布,GAN主要用在图片的生成上(图片生成的例子:假如在玩游戏,显示器是4K 的分辨率,每秒输出60张图片,要学一个生成器,也能够生成和游戏一样的图片,上面说的X就是在显示器里的4K分辨率(800万像素)图片,每个像素是一个随机变量,X是一个长为800万维度的多维随机变量,每个像素的值都是由后面的分布Pg来控制)。那么生成模型怎样来输出X?我们定义一个先验在一个输入的噪音变量pz(z)上,Z是噪音变量(可以认为100维的向量,每一个元素是一个均值为0,方差为1的搞高斯噪音),分布是PZ,生成模型就是把Z映射成X,生成模型是一个MLP,它有个可学习的参数为θ_g,假设想要生成游戏的图片,可以反汇编游戏的代码,伶出代码,就知道游戏真正是怎样生成的,这种方式代表前面说的我们去构造一个分布,在计算上比较难,但GAN不是这样的,学习一个MLP映射,因为理论上MLP理论上可以拟合任何的一个函数,构造一个差不多大小的向量,MLP强行把Z映射成要的那些X,使得两者长得很相似,好处是计算简单,坏处是MLP并不了解背后的原理。辨别器也有自己学习的参数θ_d “它的作用是把之前的数据,也就是800万像素的” 图片 放进来D(x;θd)然后输出一个标量,判断X到底是来自于真实采样数据(真实数据标号)还是生成出来的图片,采样数据,训练一个两类的分类器。在训练D的同时也会训练G,G用来最小化log(1-D(G(z))),Z是随机噪音,G(Z)生成图片,如果辨别器正确D(G(z))为0,最小化这一项也就是训练一个G使得辨别器尽量犯错,无法区分出数据到底是真实还是生成。
目标函数:

有两项,第一项是一个期望,X是采样真实分布,X放入辨别器,再加LOG,假设辨别器在完美的情况下,D(X)为1,log 之后为0,第二项是采样噪音的分布,噪音放进生成器,生成X,放入D中,理想情况下D为0,如果不理想,有误分类,这两项因为有log都会变成负数值。想要辨别器完美分类要最大化V(D,G),G是让辨别器尽量犯错,要最小化log(1-D(G(z)))。min和max在相互对抗,D尽量使数据分开,G尽量使得生成数据使D分不开,达到均衡叫做纳什均衡。
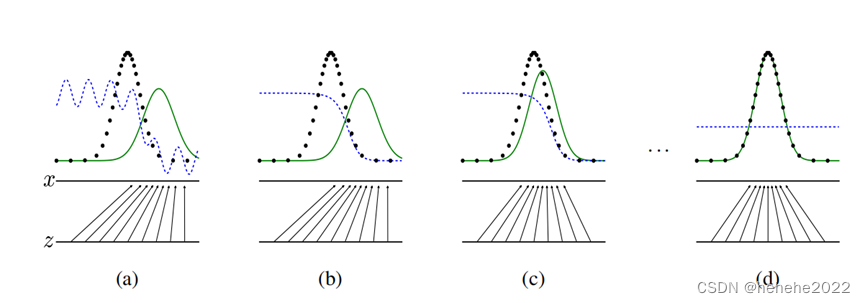
这四张图表示GAN在前面三步和最后一步干了什么?
(a)随机噪音Z、X是一个一维的标量,噪音是均匀分布采样而来,真实去拟合X在图中黑圆点处,基本是一个高斯分布,辨别器是蓝色的线,生成器把均值分布映射为绿线。下一步辨别器尽量把这两个东西分开,
(b)更新生成器
(c)生成模型可以把来自均匀分布的随机噪声Z映射为一个几乎和真实分布差不多的高斯分布。
算法

首先是FOR循环,每个循环中做一次迭代,迭代的第一部分是循环K布,每一步中先采样m个噪音样本,再采样m个来自于真实数据的样本,组成2m大小的一个小批量,放进辨别器,放进之后对辨别器的参数求梯度来更新辨别器,做K布之后,再采样m个噪音样本,放进第二项,把它的梯度对于生成器的模型算出来,对生成器进行更新,完成一次迭代。K为超参数。GAN的收敛不稳定。
实验+结论:目标函数有一个全局最优解,当且仅当生成器学习到的分布和真实数据的分布是相等的。
目标函数是正确的?
当生成器G是固定的,辨别器D的计算方式:(*是最优解的意思)
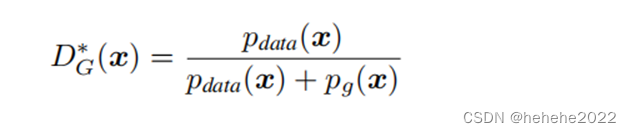
Pdatda(x):把X放进去之后,在真实的产生数据的分布里面,它的概率是多少。
Pg(x):生成器所拟合的那个分布把我的X放进去后它等于多少。最优的情况下DG(x)为1/2。
期望公式:E_(x~p) f(x)=∫_x▒P(x)f(x)ⅆx
总结
论文主要阐述了以下三点内容:
- 提出了生成对抗型网络
- 分别叙述了生成器G,鉴别器D的作用及原理。
- 网络在训练过程中的优势。
G、D叙述:生成模型G捕获数据分布,判别模型D估计样本来自于训练数据而不是G的概率。
优点:
- 不需要马尔可夫链。
- 函数变化多样性,无需推理学习过程。
- 由于其独特的更新方式,意味着输入源数据不会直接复制到生成器的参数中。
- GAN可以表示非常尖锐、甚至退化的分布,而基于马尔可夫链的方法要求分布有点模糊,以便链能够在模式之间混合。
缺点:
- pg(x)没有显式表示。
- 训练时D必须与G保持良好的同步(要避免不平衡更新),像玻尔兹曼机器的负链必须在学习步骤之间保持最新。
展望:
GAN可用作半监督学习:当有限制的标记数据可用时,鉴别器的特征可以提高分类器的性能。
效率提高: 通过划分更好的方法来协调G和D,或者在训练过程中确定更好的样本z的分布,可以大大加速训练。
![【java】【项目实战】[外卖六]套餐管理业务开发](https://img-blog.csdnimg.cn/0249b1eec7fd447394a4a742c7b409f6.png)








![[Android]JNI的基础知识](https://img-blog.csdnimg.cn/b28cf04001844f7f9d9dc824076d0b2c.png)