1.list的介绍
- list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
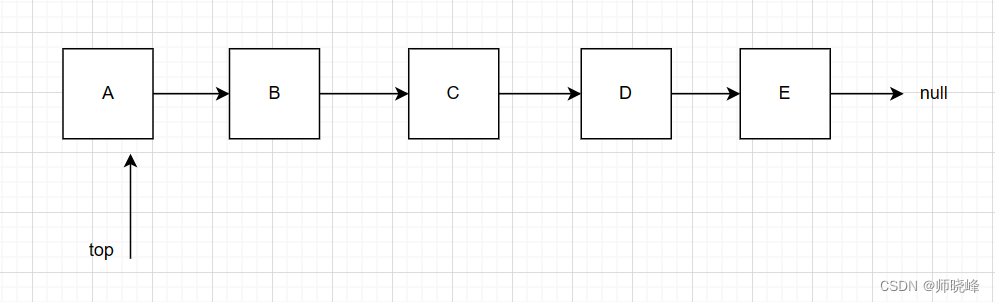
- list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向 其前一个元素和后一个元素。
- list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高效。
- 与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率更好。
- 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间开销;list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这可能是一个重要的因素)
2.list的使用
在学过vector接口后,list接口的使用也就非常容易了。大同小异!
构造函数
一、默认构造函数:
std::list<int> myList; // 创建一个空的整数链表
二、带有初始元素的构造函数:
std::list<int> myList = {1, 2, 3, 4, 5}; // 创建一个包含初始元素的整数链表
三、拷贝构造函数:
std::list<int> originalList = {1, 2, 3};
std::list<int> copiedList(originalList); // 通过拷贝构造函数创建一个与原链表相同的新链表
四、范围构造函数:
std::vector<int> vec = {1, 2, 3, 4, 5};
std::list<int> myList(vec.begin(), vec.end()); // 从一个范围内的元素创建链表
五、构造函数指定元素个数和值:
std::list<int> myList(5, 42); // 创建一个包含5个值为42的元素的链表
六、使用自定义分配器的构造函数:
std::allocator<int> myAllocator;
std::list<int, std::allocator<int>> myList(myAllocator); // 创建一个使用自定义分配器的链表
operator=
list& operator= (const list& x);
#include <iostream>
#include <list>
int main() {
std::list<int> sourceList = {1, 2, 3, 4, 5};
std::list<int> targetList;
// 使用赋值运算符将源链表赋值给目标链表
targetList = sourceList;
// 输出目标链表的内容
for (const auto& value : targetList) {
std::cout << value << " ";
}
return 0;
}
迭代器
- 获取迭代器:
begin(): 返回指向链表第一个元素的迭代器。end(): 返回指向链表尾部后一个元素的迭代器(并不指向有效元素)。
- 反向迭代器:
rbegin(): 返回指向链表最后一个元素的反向迭代器。rend(): 返回指向链表头部前一个元素的反向迭代器(并不指向有效元素)。
- 迭代器移动操作:
++iterator: 将迭代器移动到下一个元素。--iterator: 将迭代器移动到前一个元素。
- 解引用迭代器:
*iterator: 获取迭代器指向的元素的值。->: 如果链表元素是对象,可以使用箭头运算符访问对象的成员。
正向迭代器遍历链表:
#include <iostream>
#include <list>
int main() {
std::list<int> myList = {1, 2, 3, 4, 5};
// 使用迭代器遍历链表并输出元素
for (std::list<int>::iterator it = myList.begin(); it != myList.end(); ++it) {
std::cout << *it << " ";
}
// 使用 C++11 范围循环进行遍历(更简洁的方式)
for (const int& value : myList) {
std::cout << value << " ";
}
return 0;
}
反向迭代器遍历链表:
#include <iostream>
#include <list>
int main() {
std::list<int> myList = {1, 2, 3, 4, 5};
// 使用反向迭代器遍历链表并输出元素
for (std::list<int>::reverse_iterator rit = myList.rbegin(); rit != myList.rend(); ++rit) {
std::cout << *rit << " ";
}
return 0;
}
注意: 由于 list 是双向链表,迭代器支持前进和后退操作,但不支持随机访问。
- begin与end为正向迭代器,对迭代器执行++操作,迭代器向后移动
- rbegin(end)与rend(begin)为反向迭代器,对迭代器执行++操作,迭代器向前移动
capacity
size():返回链表中的元素数量。
std::list<int> myList = {1, 2, 3, 4, 5};
std::cout << "Size of the list: " << myList.size() << std::endl;
empty():检查链表是否为空。
if (myList.empty()) {
std::cout << "The list is empty." << std::endl;
} else {
std::cout << "The list is not empty." << std::endl;
}
max_size():返回std::list可以容纳的最大元素数量,考虑到系统的限制。
std::cout << "Maximum size of the list: " << myList.max_size() << std::endl;
resize(size_type n)和resize(size_type n, const T& value):改变链表的大小。第一个版本使用默认构造函数添加或移除元素,第二个版本将指定的值用作添加的元素值。
myList.resize(10); // 默认构造函数添加元素
myList.resize(8, 42); // 使用值 42 添加元素
resize的两种情况:
- 当所给值大于当前的size时,将size扩大到该值,扩大的数据为第二个所给值,若未给出,则默认为容器所存储类型的默认构造函数所构造出来的值。
- 当所给值小于当前的size时,将size缩小到该值。
element access
front():返回链表的第一个元素的引用。
std::list<int> myList = {1, 2, 3, 4, 5};
int firstElement = myList.front(); // 获取第一个元素的值
back():返回链表的最后一个元素的引用。
std::list<int> myList = {1, 2, 3, 4, 5};
int lastElement = myList.back(); // 获取最后一个元素的值
Modifiers
assign(): 用新的元素替换链表中的元素。
std::list<int> myList;
myList.assign({1, 2, 3, 4, 5}); // 用新元素替换现有元素
push_back(): 在链表末尾添加一个元素。
std::list<int> myList = {1, 2, 3};
myList.push_back(4); // 在末尾添加元素4
pop_back(): 移除链表末尾的元素。
std::list<int> myList = {1, 2, 3, 4};
myList.pop_back(); // 移除最后一个元素
push_front(): 在链表开头添加一个元素。
std::list<int> myList = {2, 3, 4};
myList.push_front(1); // 在开头添加元素1
pop_front(): 移除链表开头的元素。
std::list<int> myList = {1, 2, 3, 4};
myList.pop_front(); // 移除第一个元素
insert(): 在指定位置插入一个或多个元素。
std::list<int> myList = {1, 2, 5};
std::list<int>::iterator it = std::next(myList.begin()); // 获取第二个元素的迭代器
myList.insert(it, 3); // 在第二个位置插入元素3
erase(): 移除指定位置的一个或多个元素。
std::list<int> myList = {1, 2, 3, 4, 5};
std::list<int>::iterator it = std::next(myList.begin(), 2); // 获取第三个元素的迭代器
myList.erase(it); // 移除第三个元素
clear(): 移除所有链表中的元素,使其变为空链表。
std::list<int> myList = {1, 2, 3, 4, 5};
myList.clear(); // 清空链表中的所有元素
swap():用于交换两个链表的内容
std::list<int> list1 = {1, 2, 3};
std::list<int> list2 = {4, 5, 6};
list1.swap(list2); // 交换两个链表的内容
Operations
remove(): 移除链表中等于指定值的所有元素。
std::list<int> myList = {1, 2, 2, 3, 4, 2, 5};
myList.remove(2); // 移除所有值为2的元素
sort(): 对链表中的元素进行排序。
std::list<int> myList = {3, 1, 4, 1, 5, 9, 2, 6};
myList.sort(); // 对元素进行升序排序
reverse(): 反转链表中的元素顺序。
std::list<int> myList = {1, 2, 3, 4, 5};
myList.reverse(); // 反转元素的顺序,变为 {5, 4, 3, 2, 1}
merge(): 合并两个已排序的链表。合并后的list容器仍然有序
std::list<int> list1 = {1, 3, 5};
std::list<int> list2 = {2, 4, 6};
list1.merge(list2); // 合并两个已排序的链表
unique(): 移除链表中的重复元素(连续重复的元素只保留一个)。
std::list<int> myList = {1, 2, 2, 3, 3, 3, 4, 5, 5};
myList.unique(); // 移除连续重复的元素,变为 {1, 2, 3, 4, 5}
splice
splice函数用于两个list容器之间的拼接,其有三种拼接方式:
- 将整个容器拼接到另一个容器的指定迭代器位置。
- 将容器当中的某一个数据拼接到另一个容器的指定迭代器位置。
- 将容器指定迭代器区间的数据拼接到另一个容器的指定迭代器位置。
#include <iostream>
#include <list>
using namespace std;
int main() {
list<int> lt1(4, 2);
list<int> lt2(4, 6);
lt1.splice(lt1.begin(), lt2);//将容器lt2拼接到容器lt1的开头
for (auto e: lt1) {
cout << e << " ";
}
cout << endl;//6 6 6 6 2 2 2 2
list<int> lt3(4, 2);
list<int> lt4(4, 6);
lt3.splice(lt3.begin(), lt4, lt4.begin());//将容器lt4的第一个数据拼接到容器lt3的开头
for (auto e: lt3) {
cout << e << " ";
}
cout << endl;//6 2 2 2 2
list<int> lt5(4, 2);
list<int> lt6(4, 6);
lt5.splice(lt5.begin(), lt6, lt6.begin(), lt6.end());//将容器lt6的指定迭代器区间内的数据拼接到容器lt5的开头
for (auto e: lt5) {
cout << e << " ";
}
cout << endl;//6 6 6 6 2 2 2 2
return 0;
}
注意: 容器当中被拼接到另一个容器的数据在原容器当中就不存在了。(实际上就是将链表当中的指定结点拼接到了另一个容器当中)
remove_if
remove_if函数用于删除容器当中满足条件的元素。
#include <iostream>
#include <list>
using namespace std;
bool single_digit(const int &val) {
return val < 10;
}
int main() {
list<int> lt;
lt.push_back(10);
lt.push_back(4);
lt.push_back(7);
lt.push_back(18);
lt.push_back(2);
lt.push_back(5);
lt.push_back(9);
for (auto e: lt) {
cout << e << " ";
}
cout << endl; //10 4 7 18 2 5 9
lt.remove_if(single_digit);//删除容器当中值小于10的元素
for (auto e: lt) {
cout << e << " ";
}
cout << endl;//10 18
return 0;
}
3.list迭代器失效问题
此处可将迭代器暂时理解成类似于指针,迭代器失效即迭代器所指向的节点的无效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭代器,其他迭代器不会受到影响。
void TestListIterator1() {
int array[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
list<int> l(array, array + sizeof(array) / sizeof(array[0]));
auto it = l.begin();
while (it != l.end()) {
l.erase(it);
++it;
}
}
erase()函数执行后,it所指向的节点已被删除,因此it无效,在下一次使用it时,必须先给其赋值
改正:
void TestListIterator() {
int array[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
list<int> l(array, array + sizeof(array) / sizeof(array[0]));
auto it = l.begin();
while (it != l.end()) {
l.erase(it++);// 或者it = l.erase(it);
}
}
4.list模拟实现

要模拟实现list,必须要熟悉list的底层结构以及其接口的含义,通过上面的学习,这些内容已基本掌握,现 我们来模拟实现list。
代码如下:
#pragma once
#include "iterator.h"
#include <algorithm>
#include <assert.h>
#include <iostream>
#include <stdlib.h>
using namespace std;
// list - 底层是一个双向带头循环链表
template<class T>
struct list_node {
list_node *next;
list_node *prev;
T data;// 模板T类型,适用任何类型
// 构造函数初始化列表
// T()被用来初始化list_node类的data成员变量,以确保每个新创建的list_node对象都有一个合适的T类型的默认值。
list_node(const T &x = T())// T()用来给自定义类型调用默认构造函数来初始化x
: next(nullptr), prev(nullptr), data(x) {
}
};
// list类
template<class T>
class list {
public:
typedef list_node<T> node; // 链表
typedef list_iterator<T, T &, T *> iterator;// 迭代器
// const迭代器 通过const T& 传给Ref ,const T* 传给Ptr
typedef list_iterator<T, const T &, const T *> const_iterator;// const迭代器 - 通过const迭代器访问的数据无法被修改
typedef STL_reverse_iterator<iterator, T &, T *> reverse_iterator;
// 节点初始化
void empty_init() {
head = new node;
head->next = head;
head->prev = head;
}
// list默认构造函数
list() {
empty_init();
}
// 利用迭代器构造函数
template<class iterator>
list(iterator first, iterator last) {
empty_init();
while (first != last) {
push_back(*first);
++first;
}
}
//拷贝构造 lt2(lt1) 老方法
/*
list(const list<T>& lt)
{
empty_init();
for (auto e : lt)
{
push_back(e); //将lt的元素复制到现在的list中
}
}
*/
void swap(list<T> &tmp) {
std::swap(head, tmp.head);//交换头指针
}
// 拷贝构造-现代方法
list(const list<T> <) {
empty_init(); // 必须有,不然)_head就是空指针
list<T> tmp(lt.begin(), lt.end());//由lt的迭代器,构造出一个tmp
swap(tmp); //交换tmp和this->head的指针
}
// 赋值 lt1 = lt3 这里lt就是lt3的拷贝,lt1是this
list<T> &operator=(list<T> lt) {
swap(lt); // 交换 lt和this交换
return *this;// 返回自己就是返回lt,赋值给别的对象
}
// 迭代器通常建议将迭代器作为值传递,而不是作为引用传递。引用会导致迭代器失效
iterator begin() {
return iterator(head->next);// 调用默认构造函数给node初始化
}
const_iterator begin() const// const修饰的函数,无法改变成员变量
{
return const_iterator(head->next);// 指针不能改变,但可以赋值给别人
}
reverse_iterator rbegin() {
return reverse_iterator(head->prev);//rbegin 是最后一个数
}
reverse_iterator rend() {
return reverse_iterator(head);//rend是头指针
}
iterator end() {
// 双向带头循环判尾是头节点head
return iterator(head);
}
const_iterator end() const {
return const_iterator(head);
}
// pos迭代器不会失效,插入后,pos位置永远不会变,地址不变
void insert(iterator pos, const T &x) {
// pos是一个类
node *cur = pos._node; // 先取pos位置的节点地址
node *prevnode = cur->prev;// 记录pos位置的前节点
node *newnode = new node(x);
prevnode->next = newnode;
newnode->prev = prevnode;
newnode->next = cur;
cur->prev = newnode;
}
iterator erase(iterator pos) {
if (pos != end()) {
// 先记录前节点 后节点
node *prevnode = pos._node->prev;
node *nextnode = pos._node->next;
prevnode->next = nextnode;
nextnode->prev = prevnode;
delete pos._node;
// 返回下一个地址
return iterator(nextnode);
} else {
perror("erase fail");
exit(-1);
}
}
void push_back(const T &x) {
insert(end(), x);// 复用
}
void pop_back() {
erase(end()--);// end()是头指针,头指针的prev是尾节点
}
void push_front(const T &x) {
insert(begin(), x);
}
void pop_front() {
erase(begin());
}
void clear() {
// 清理内存 - 不清理头节点
iterator it = begin();
while (it != end()) {
erase(it);
it++;
}
}
~list() {
clear();
delete head;
head = nullptr;
}
private:
node *head;// 头节点 - list只有一个数据成员,头节点
};
list的反向迭代器
通过前面例子知道,反向迭代器的++就是正向迭代器的–,反向迭代器的–就是正向迭代器的++,因此反向迭代器的实现可以借助正向迭代器,即:反向迭代器内部可以包含一个正向迭代器,对正向迭代器的接口进行 包装即可。
iterator.h:
#pragma once
template<class T>
struct list_node;//声明外部类,
// list迭代器
template<class T, class Ref, class Ptr>
struct list_iterator {
typedef list_node<T> node; // 链表
typedef list_iterator<T, Ref, Ptr> iterator;// 迭代器
node *_node; // 迭代器里唯一的成员变量:链表指针
// 迭代器默认构造函数,传的是迭代器链表指针
list_iterator(node *n)
: _node(n) {
}
// 解引用 - 返回的是链表的值 Ref通过传参,T和const T 用来控制const类型和非const类型
Ref operator*() {
return _node->data;
}
//-> 返回的是链表data的地址 Ptr通过传参,T和const T 用来控制const类型和非const类型
Ptr operator->() {
return &_node->data;
}
// 前置++ 先++,在返回自己
iterator &operator++() {
_node = _node->next;
return *this;
}
// 后置++ 先返回 在++
iterator operator++(int) {
iterator tmp = *this;// 注意:临时变量,不能引用返回
_node = _node->next;
return tmp;// tmp是一个类,不是引用返回,返回的时候会创建一个临时类
}
// 前置-- 先--,在返回自己
iterator &operator--() {
_node = _node->prev;
return *this;
}
// 后-- 在返回,在--
iterator operator--(int) {
iterator tmp = *this;
_node = _node->prev;
return tmp;
}
// pos地址++
iterator &operator+(int x) {
while (x--) {
//*this表示迭代器里的指针,++复用前面的重载,表示指针++
*this = ++*this;
}
return *this;
}
iterator &operator-(int x) {
while (x--) {
*this = --*this;
}
return *this;
}
// this->_node 不等于参数_node
bool operator!=(const iterator &it) {
return _node != it._node;
}
};
//反向迭代器
template<class iterator, class Ref, class Ptr>
struct STL_reverse_iterator {
iterator cur;//正向迭代器
typedef STL_reverse_iterator<iterator, Ref, Ptr> reverse_iterator;
STL_reverse_iterator(iterator it)
: cur(it) {}
Ref operator*() {
return *cur;//对正向迭代器解引用,就是返回node->data
}
reverse_iterator operator++() {
--cur;
return *this;
}
reverse_iterator operator--() {
++cur;
return *this;
}
bool operator!=(const reverse_iterator &s) {
return cur != s.cur;
}
};
5.list和vector对比
vector与list都是STL中非常重要的序列式容器,由于两个容器的底层结构不同,导致其特性以及应用场景不 同,其主要不同如下:
| vector | list | |
|---|---|---|
| 底层结构 | 动态顺序表,一段连续空间 | 带头结点的双向循环链表 |
| 随机访问 | 支持随机访问,访问某个元素效率O(1) | 不支持随机访问,访问某个元素 效率O(N) |
| 插入和删除 | 任意位置插入和删除效率低,需要搬移元素,时间复杂度为O(N),插入时有可能需要增容,增容:开辟新空间,拷贝元素,释放旧空间,导致效率更低 | 任意位置插入和删除效率高,不需要搬移元素,时间复杂度为 O(1) |
| 空间利 用率 | 底层为连续空间,不容易造成内存碎片,空间利用率高,缓存利用率高 | 底层节点动态开辟,小节点容易造成内存碎片,空间利用率低, 缓存利用率低 |
| 迭代器 | 原生态指针 | 对原生态指针(节点指针)进行封装 |
| 迭代器失效 | 在插入元素时,要给所有的迭代器重新赋值,因为插入元素有可能会导致重新扩容,致使原来迭代器失效,删除时,当前迭代器需要重新赋值否则会失效 | 插入元素不会导致迭代器失效, 删除元素时,只会导致当前迭代器失效,其他迭代器不受影响 |
| 使用场景 | 需要高效存储,支持随机访问,不关心插入删除效率 | 大量插入和删除操作,不关心随机访问 |