接上篇《32、bs4的基本使用》
上一篇我们介绍了BeautifulSoup的基本概念,以及bs4的基本使用,本篇我们来使用bs4来解析星巴克网站,获取其产品信息。
一、星巴克网站介绍

星巴克官网是星巴克公司的官方网站,用于提供关于星巴克咖啡店的信息和服务。在星巴克官网上,可以找到各种有关咖啡、茶饮、糕点和其他食品的详细描述和营养信息。此外,官网还提供星巴克的最新消息、特别活动、促销优惠和公司资讯。
二、产品界面分析

星巴克官网中国地区地址:https://www.starbucks.com.cn/
我们本次要抓取的是星巴克的产品界面,我们点击首页左上角的“菜单”按钮,在右侧就可以看到星巴克所有的产品: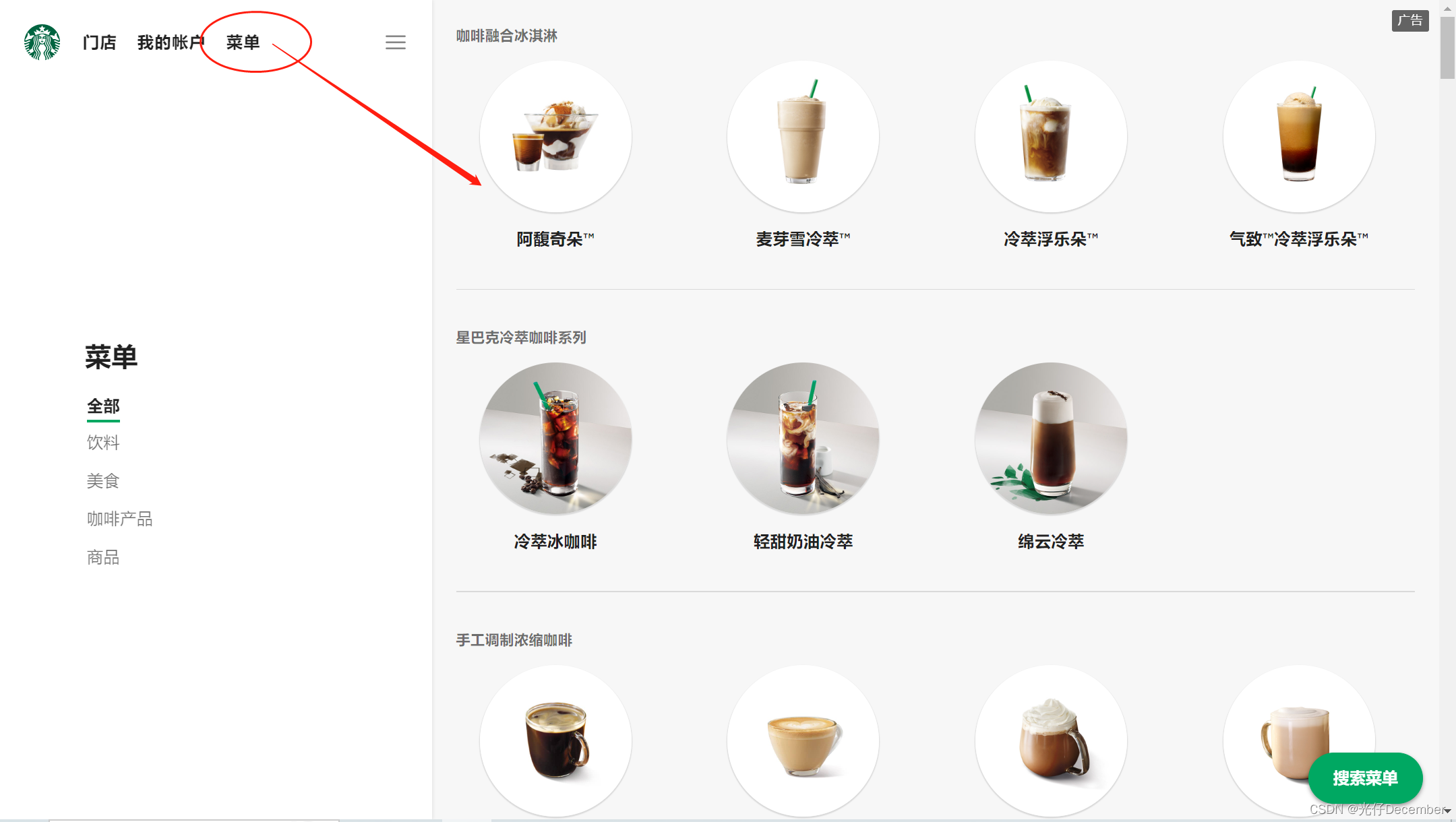
此时我们按F12打开浏览器的开发者模式,清除NetWork区域,重新点击菜单按钮或刷新菜单界面,可以看到其中获取菜单界面的后台服务地址: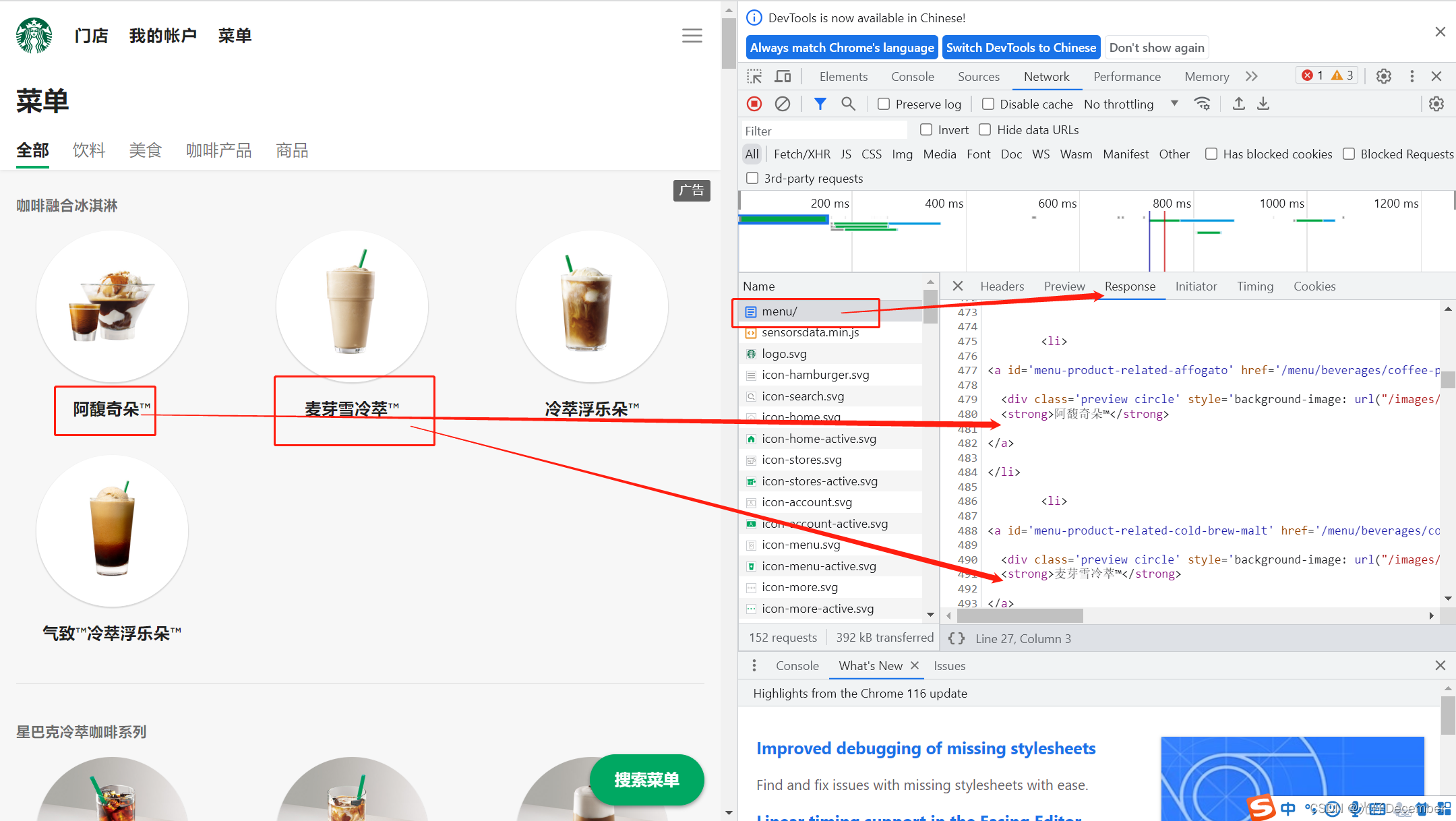
其实就是菜单地址:https://www.starbucks.com.cn/menu/,它不是一个异步的服务,而是直接返回一个渲染好的html
我们仔细阅读一下获取到的HTML代码,将有关产品的部分单独拉出来,分析其结构(这里选择了“咖啡融合冰淇淋”这一部分的html代码):
<div class='wrapper fluid margin page-menu-list'>
<ul class='grid padded-3 product'>
<li>
<a id='menu-product-related-affogato' href='/menu/beverages/coffee-plus-ice-cream/'
class='thumbnail'>
<div class='preview circle'
style='background-image: url("/images/products/affogato.jpg")'></div>
<strong>阿馥奇朵™</strong>
</a>
</li>
<li>
<a id='menu-product-related-cold-brew-malt' href='/menu/beverages/coffee-plus-ice-cream/'
class='thumbnail'>
<div class='preview circle'
style='background-image: url("/images/products/cold-brew-malt.jpg")'></div>
<strong>麦芽雪冷萃™</strong>
</a>
</li>
<li>
<a id='menu-product-related-cold-brew-float' href='/menu/beverages/coffee-plus-ice-cream/'
class='thumbnail'>
<div class='preview circle'
style='background-image: url("/images/products/cold-brew-float.jpg")'></div>
<strong>冷萃浮乐朵™</strong>
</a>
</li>
<li>
<a id='menu-product-related-nitro-cold-brew-float' href='/menu/beverages/coffee-plus-ice-cream/'
class='thumbnail'>
<div class='preview circle'
style='background-image: url("/images/products/instore-nitro-cold-brew-float.jpg")'></div>
<strong>气致™冷萃浮乐朵™</strong>
</a>
</li>
<h3 class='caption'>咖啡融合冰淇淋</h3>
</ul>
<hr/>
<!-- 后面的代码比较长,这里先省略...... -->我们可以看到,整个产品区域是由一个div包裹的,这个div包含一个名为“page-menu-list”的css样式,然后其中的产品全部是由<ul><li></li></ul>包裹,ul的id为“grid padded-3 product”。其中的具体的产品在里面用<a>标签包裹,而a标签的id包含“menu-product-”的字样,里面的<strong>标签包裹的就是我们需要获取的产品名称。而class为“caption”的h3标签,包裹的是该种产品的分类。
综上所述,我们分析出来的结果信息为:
1、所有产品在包含“page-menu-list”的css样式的div下;
2、每种产品大类包裹在id为“grid padded-3 product”的ul下;
3、每种产品大类的名称被包裹在class为“caption”的h3标签内;
4、每种产品具体的名称包裹在包含“menu-product-”的字样的a标签内的<strong>标签中。
分析了这些,足以让我们思考如何试用bs4来进行星巴克所有产品的信息抓取了。
三、抓取产品数据
我们需要抓取的结果,就是星巴克产品有多少大类,每个大类下有多少个具体的产品。
1、引入bs4库
编写代码前,首先要确保已经引入了bs4的库(如果没有,需要通过“pip install bs4”来安装)。
然后引入bs4库:
from bs4 import BeautifulSoup2、获取星巴克产品页面
我们通过urllib来获取星巴克产品页面的html代码:
import urllib.request
# 下面模拟浏览器向服务器发送请求
# 发送HTTP GET请求
response = urllib.request.urlopen('https://www.starbucks.com.cn/menu/')
html_content = response.read().decode()
print(html_content)打印出来就可以看到产品界面的html代码: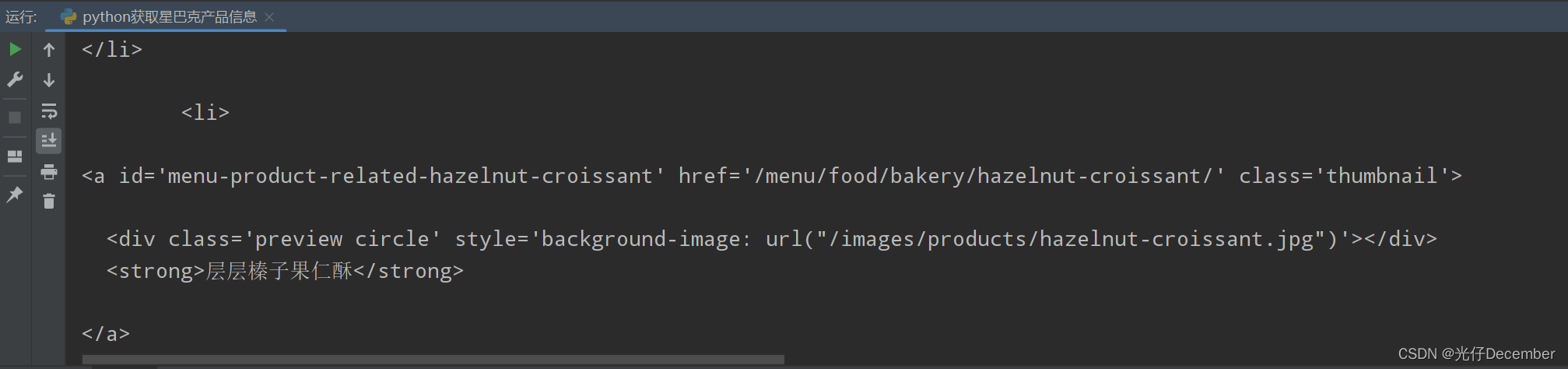
3、创建BS对象,并制定解析器
这里使用默认的html.parser解析器,用来解析html代码:
# 创建BeautifulSoup对象,并制定解析器(此处使用默认的html.parser)
soup = BeautifulSoup(html_content, 'html.parser')4、获取商品大类
首先我们先获取商品大类,根据上面的分析,我们只需要获取class为“caption”的h3标签内的字符,就获取到所有的大类了:
# 1、获取所有的产品大类
captions = soup.find_all('h3', class_="caption")
print("星巴克产品大类:")
for cap in captions:
print(cap.text)结果: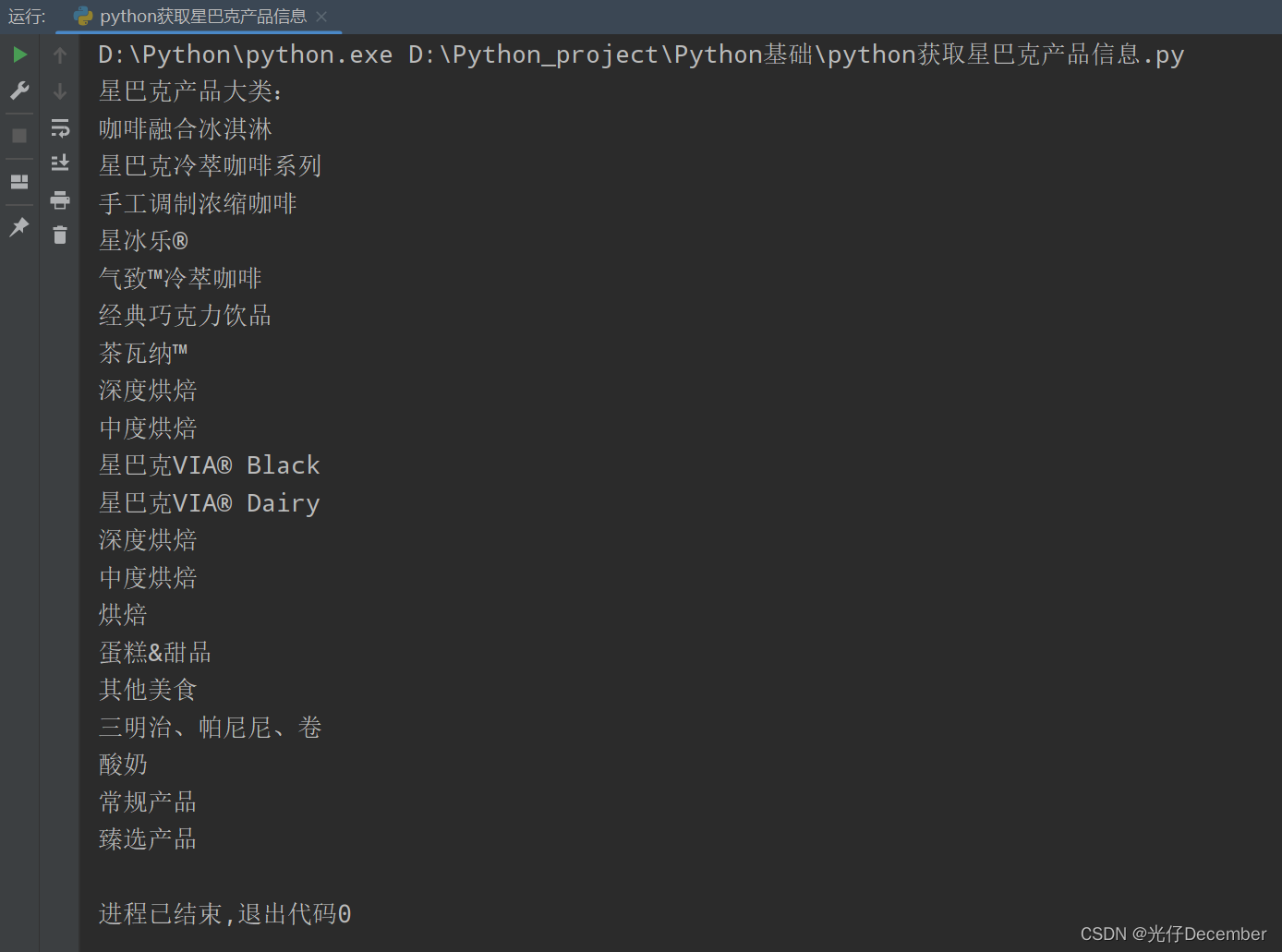
可以看到星巴克商品的所有大类已经获取到。
5、获取所有产品名称
根据第二章的分析,每种产品大类包裹在id为“grid padded-3 product”的ul下,具体的名称包裹在包含“menu-product-”的字样的a标签内的<strong>标签中,我们按照这个思路编写bs4代码:
# 2、获取所有产品信息
# 获取所有class为grid padded-3 product的ul节点
menus_uls = soup.find_all('ul', class_="grid padded-3 product")
print("【星巴克产品细则】:")
for menus_ul in menus_uls:
# 获取ul下的所有li节点
menus_lis = menus_ul.find_all('li')
# 网页上有空节点,要判定一下才能获取下一步数据
if len(menus_lis) > 0:
# 获取ul节点下唯一一个h3的文字,就是产品大类
print("----[" + menus_ul.h3.text + "]----")
for menus_li in menus_lis:
# 获取每一个li里面的a标签内的strong标签的文字,就是具体产品名
print(" ", menus_li.a.strong.text)结果:
【星巴克产品细则】:
----[咖啡融合冰淇淋]----
阿馥奇朵™
麦芽雪冷萃™
冷萃浮乐朵™
气致™冷萃浮乐朵™
----[星巴克冷萃咖啡系列]----
冷萃冰咖啡
轻甜奶油冷萃
绵云冷萃
----[手工调制浓缩咖啡]----
美式咖啡(热/冷)
拿铁(热/冷)
摩卡(热/冷)
卡布奇诺(热/冷)
焦糖玛奇朵(热/冷)
浓缩咖啡
馥芮白™
榛果风味拿铁(热/冷)
香草风味拿铁(热/冷)
----[星冰乐®]----
焦糖浓缩咖啡星冰乐
抹茶星冰乐
芒果西番莲果茶星冰乐
摩卡星冰乐
摩卡可可碎片星冰乐
香草风味星冰乐
----[气致™冷萃咖啡]----
气致™冷萃咖啡
----[经典巧克力饮品]----
经典巧克力饮品(热/冷)
----[茶瓦纳™]----
红茶拿铁(热/冷)
抹茶拿铁(热/冷)
茶瓦纳™ 冰摇柚柚蜂蜜红茶
冰摇红莓黑加仑茶
冰摇芒果花草茶
茶瓦纳™冰摇桃桃乌龙茶
----[深度烘焙]----
星巴克ORIGAMI™便携式滴滤咖啡(研磨咖啡粉)星巴克®佛罗娜烘焙咖啡系列
----[中度烘焙]----
星巴克ORIGAMI™便携式滴滤咖啡(研磨咖啡粉)星巴克®派克市场烘焙咖啡系列
----[星巴克VIA® Black]----
星巴克VIA®哥伦比亚免煮咖啡
星巴克VIA®意式烘焙免煮咖啡
----[星巴克VIA® Dairy]----
星巴克VIA®摩卡风味免煮咖啡固体饮料
星巴克VIA®焦糖拿铁风味免煮咖啡固体饮料
星巴克VIA®香草拿铁风味免煮咖啡固体饮料
----[深度烘焙]----
星巴克®佛罗娜咖啡豆
星巴克®浓缩烘焙咖啡豆
星巴克®意式烘焙咖啡豆
星巴克®低因祥龙综合咖啡豆
星巴克®苏门答腊咖啡豆
----[中度烘焙]----
星巴克®早餐综合咖啡豆
星巴克®哥伦比亚咖啡豆
星巴克®埃塞俄比亚咖啡豆
星巴克®危地马拉安提瓜咖啡豆
星巴克®首选咖啡豆
星巴克®肯亚咖啡豆
星巴克®派克市场烘焙咖啡豆
星巴克®凤舞祥云综合咖啡豆
----[烘焙]----
美式松饼
蓝莓麦芬
香浓巧克力麦芬
旋风玉桂酥
法式香酥可颂
法式焦糖酥
层层榛子果仁酥
蜂蜜提子司康
燕麦焦糖布丁面包
香浓巧克力可颂
提子干松饼
核桃提子软法面包
红豆燕麦松饼
全麦核桃麦芬
----[蛋糕&甜品]----
蓝莓曲奇风轻乳酪蛋糕
经典瑞士卷
浓醇三重黑巧克力蛋糕
法式闪电泡芙
星巴克咖啡提拉米苏蛋糕
法式马卡龙
纽约风浓郁重芝士蛋糕
----[其他美食]----
腰果
英伦风味黄油饼干
混合果仁果脯
水果沙拉
棒棒糖
咖啡味蛋卷
薄荷味口香糖(无糖)
薄荷味硬糖(无糖)
----[三明治、帕尼尼、卷]----
牛油果鸡肉焙果
培根蛋可颂堡
蜜汁培根蛋卷
层层牛肉法棍
牛肉芝士可颂
凯撒鸡肉卷
鸡肉芝香帕尼尼
炒蛋菌菇虾仁卷
火腿芝士可颂
双重芝士火腿吐司
高达芝士火腿星明治
帕斯雀牛肉三明治
烤法式火腿鸡蛋三明治
慢烤火腿芝士恰巴特
金枪鱼帕尼尼
火鸡培根英式麦芬
----[酸奶]----
谷物组合希腊式风味酸奶(混合莓果)
谷物组合希腊式风味酸奶(黄桃)
----[常规产品]----
12oz 烫金品牌黑色马克杯
银色/白色亮面品牌桌面杯
12oz 彰显本色黑色/深灰不锈钢桌面杯
12oz 纯白磨砂玻璃杯
12oz 烫金品牌白色马克杯
16oz 烫金品牌黑色马克杯
16oz 原木黑色拎绳不锈钢保温杯
16oz 彰显本色黑色/深灰不锈钢随行杯
16oz 烫金品牌白色马克杯
3oz 烫金品牌黑色试尝杯
3oz 烫金品牌白色试尝杯
500ml 黑色Logo水瓶
500ml 白色Logo水瓶
----[臻选产品]----
12oz 纯黑/古铜亮面品牌桌面杯
16oz 香槟金品牌不锈钢桌面杯
500ml 金色Logo水瓶
9oz 臻选玻璃杯可以看到将所有具体产品全部获取,并且按照大类进行了分割。
6、使用lxml获取所有商品名
如果不使用html解析器,使用lxml解析器,那么其代码实现很简单,但是公式编写需要我们进一步思考,代码如下:
# 3、使用lxml获取所有产品
soup2 = BeautifulSoup(html_content, 'lxml')
name_list = soup2.select('ul[class="grid padded-3 product"] strong')
print("【星巴克产品细则】:")
for name in name_list:
print(name.get_text())小伙伴们可以思考一下为什么这么写,并且区别lxml解析器和html解析器在那些场景下哪个比较好用。
以上实验实例的完整代码:
# _*_ coding : utf-8
# @Time : 2023-08-27 10:32
# @Author :光仔December
# @File : python获取星巴克产品信息
# @Project :Python基础
from bs4 import BeautifulSoup
import urllib.request
# 下面模拟浏览器向服务器发送请求
# 发送HTTP GET请求
response = urllib.request.urlopen('https://www.starbucks.com.cn/menu/')
html_content = response.read().decode()
# print(html_content)
# 创建BeautifulSoup对象,并制定解析器(此处使用默认的html.parser)
soup = BeautifulSoup(html_content, 'html.parser')
# 1、获取所有的产品大类
captions = soup.find_all('h3', class_="caption")
print("星巴克产品大类:")
for cap in captions:
print(cap.text)
# 2、获取所有产品信息
# 获取所有class为grid padded-3 product的ul节点
menus_uls = soup.find_all('ul', class_="grid padded-3 product")
print("【星巴克产品细则】:")
for menus_ul in menus_uls:
# 获取ul下的所有li节点
menus_lis = menus_ul.find_all('li')
# 网页上有空节点,要判定一下才能获取下一步数据
if len(menus_lis) > 0:
# 获取ul节点下唯一一个h3的文字,就是产品大类
print("----[" + menus_ul.h3.text + "]----")
for menus_li in menus_lis:
# 获取每一个li里面的a标签内的strong标签的文字,就是具体产品名
print(" ", menus_li.a.strong.text)
# 3、使用lxml获取所有产品
soup2 = BeautifulSoup(html_content, 'lxml')
name_list = soup2.select('ul[class="grid padded-3 product"] strong')
print("【星巴克产品细则】:")
for name in name_list:
print(name.get_text())以上就是使用bs4对星巴克产品信息进行抓取的实现过程。至此我们对bs4的讲解全部结束,下一篇我们将开始学习selenium技术。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://guangzai.blog.csdn.net/article/details/132521673










![这可能是你看过最详细的 [八大排序算法]](https://img-blog.csdnimg.cn/5f6d99ae9e634e32ba92a2a7c1313209.gif)