1、这货怎么没怎么听过
经常使用Quartz或者Spring Task的小伙伴们,或多或少都会遇到几个痛点,比如:
1、不敢轻易跟着应用服务多节点部署,可能会重复多次执行而引发系统逻辑的错误;
2、Quartz的集群仅仅只是用来HA,节点数量的增加并不能给我们的每次执行效率带来提升,即不能实现水平扩展;
在当当的ddframe框架中,需要一个任务调度系统。实现的话有两种思路,一个是修改开源产品,一种是基于开源产品搭建,也就是封装。当当选择了后者,最开始这个调度系统叫做dd-job。它是一个无中心化的分布式调度框架。因为数据库缺少分布式协调功能(比如选主),替换为Zookeeper后,增加了弹性扩容和数据分片的功能。Elastic-Job是ddframe中的dd-job作业模块分离出来的作业框架,基于Quartz和Curator开发,在2015年开源。
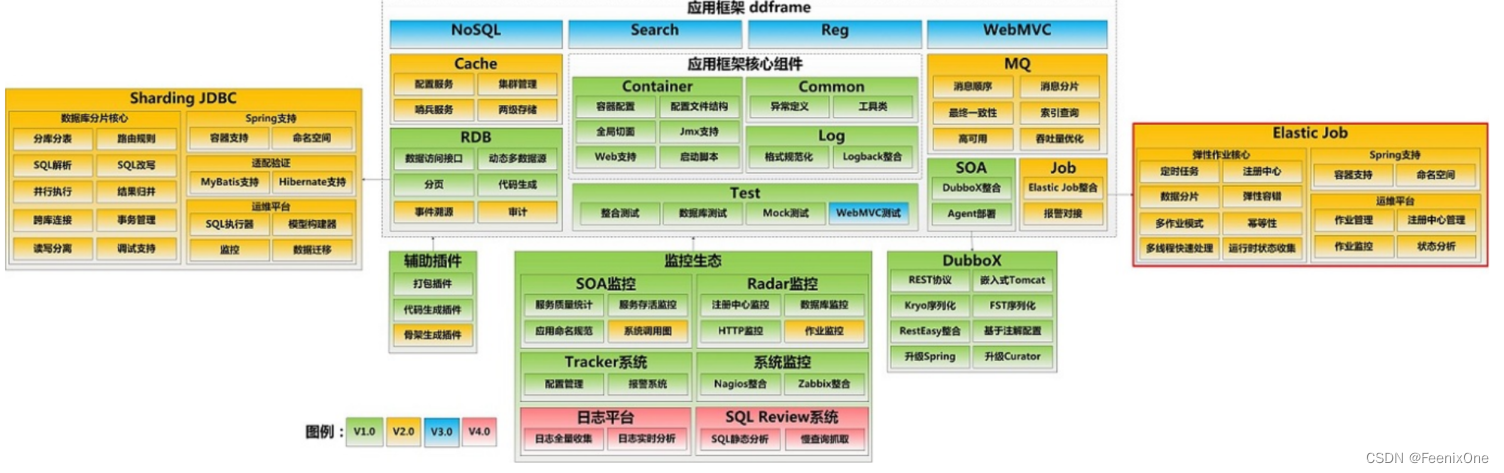
Elastic-Job是当当网架构师张亮、曹昊和江树建基于Zookepper和Quartz开发并开源的一个Java分布式定时任务(跟大名鼎鼎的ElasticSearch没有半毛钱关系),解决了Quartz不支持分布式的弊端。Elastic-Job主要的功能有支持弹性扩容,通过Zookepper集中管理和监控job,支持失效转移等。最开始只有一个elastic-job-core的项目,在2.X版本以后主要分为Elastic-Job-Lite和Elastic-Job-Cloud两个子项目。其中,Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。而Elastic-Job-Cloud使用Mesos + Docker的解决方案,额外提供资源治理、应用分发以及进程隔离等服务(跟Lite的区别只是部署方式不同,使用相同的API,只要开发一次)。
之所以感觉这货没什么人用,是因为这个项目在2020年捐给了Apache之后,将原生的编程方式基本删光了,现在在网上很难再找到原生的编程方式。更离谱的是,官网给出的Demo还漏了很多,也就是说你跟着官网一步一步写下来,结果还构建不起来.....
那为啥我还要写这么一篇文章出来,按道理说一个连官网都放弃的东西,费这些精力干啥。因为Elastic-Job中有一个很关键的概念:分片,也就是任务分片策略,这也正是它和Quartz之间最大的区别所在。而现在的Elastic-Job已经成为了一个二级子项目了,它的注册中心依赖于Zookeeper,所以如果要使用Elastic-Job的话,前提得先安装Zookeeper服务。
2、Quartz遗留的问题
① 假设在一个Quartz集群中有多个正在运行的节点,要如何决定哪些任务在哪些节点上运行呢?Quartz的处理方法非常简单粗暴,就是随机的。通过数据库中存储的信息,去抢占下一个即将触发的触发器所绑定的任务权限,并不支持对任务的执行节点进行协调;
② 当处理一个非常复杂的任务的时候,某一个节点的性能始终是有限的。如果可以将一个复杂的任务拆分成多个子任务,分别交由不同的节点协同处理,效率上必定事半功倍;
③ Quartz本身并不支持图形化管理页面,对于任务的管理非常的不方便;
3、初试Elastic-Job
以上的这些问题,Elastic-Job统统都可以解决,在弥补Quartz不足的这方面,Elastic-Job是认真的,但必须承认的是,它真的也没有特别好用。很遗憾,现在去Elastic-Job的官网已经访问不了了,这个官网早些年前被买给了快橙(一个VPN工具),现在它的官网已经沦落为shardingsphere下的一个二级网站:https://shardingsphere.apache.org/elasticjob/index_zh.html
启动Zookeeper服务
因为Elastic-Job是依赖于Zookeeper,所以先确保相关的Zookeeper服务启动成功。这里方便演示,我就不再专门弄个虚拟机搭一个Zookeeper服务,直接在本地启动Zookeeper服务。有几个点需要注意一下:
1、Zookeeper的压缩包解压缩之后,进入目录总,新建data目录存放数据,新建logs目录存放日志;
2、 进入conf目录中,复制zoo_sample.cfg一份,并从命名为zoo.cfg作为Zookeeper的配置文件,需要进行一些基础的修改;
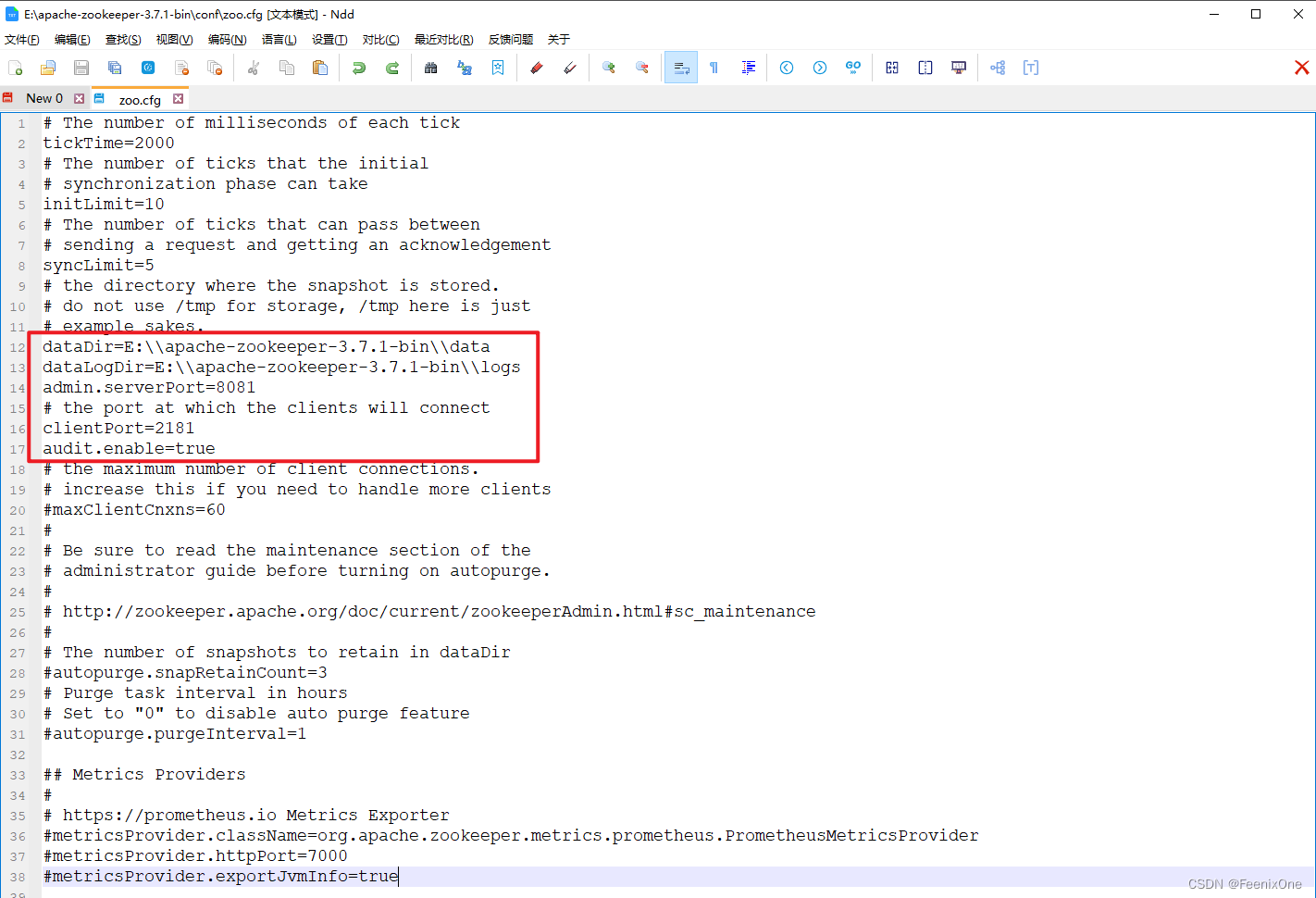
3、进入Zookeeper中的bin目录下,执行:zkServer.cmd
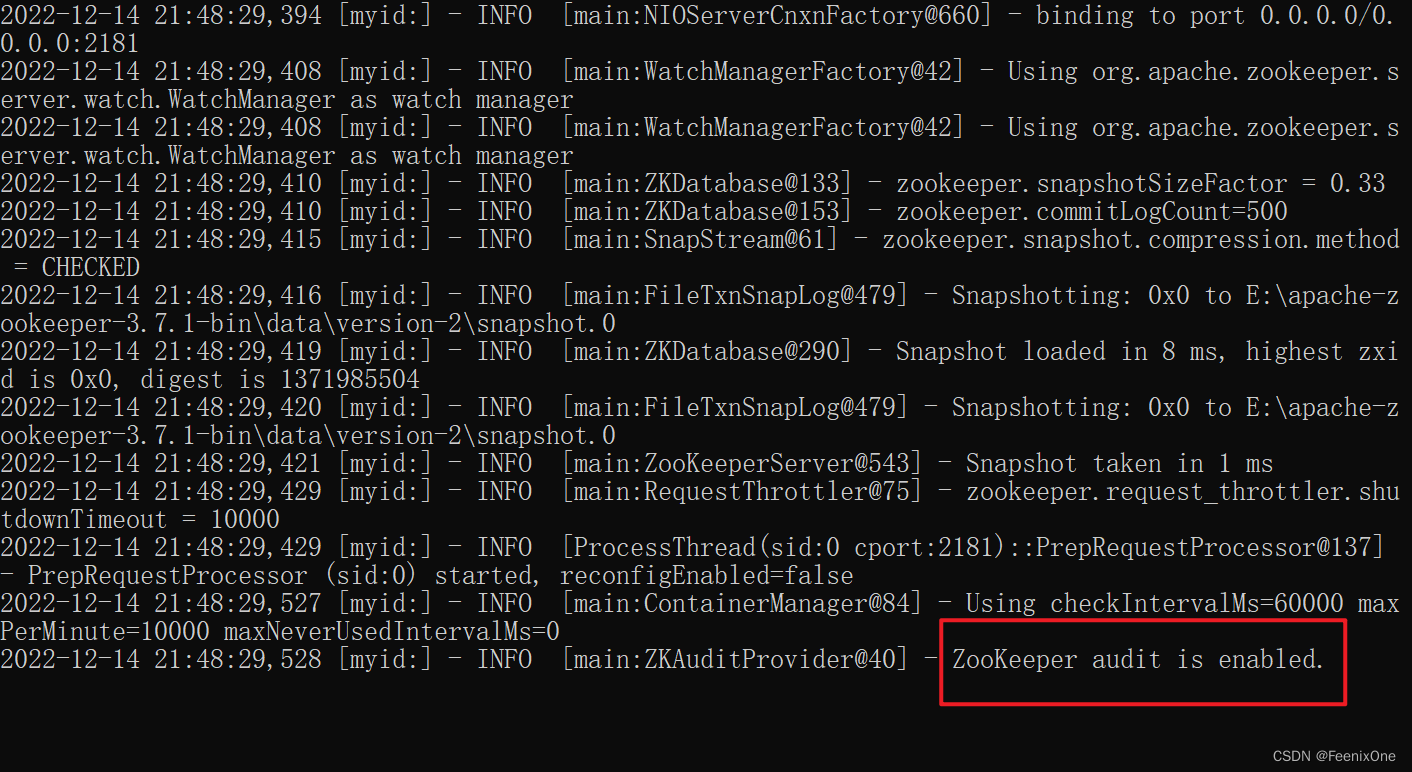
看到日志输出 ZooKeeper audit is enabled. 则说明Zookeeper服务启动成功。
引入Elastic-Job相关依赖
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-core</artifactId>
<version>3.0.1</version>
</dependency>目前Maven中央仓库最新的版本是3.0.2,更新于22年10月23日,而3.0.1是目前使用最多的版本,更新于21年10月11日。好家伙,一年一更,看这个维护的频率就知道这玩意儿没什么人用。
SimpleJob
自定义需执行的任务,实现SimpleJob接口
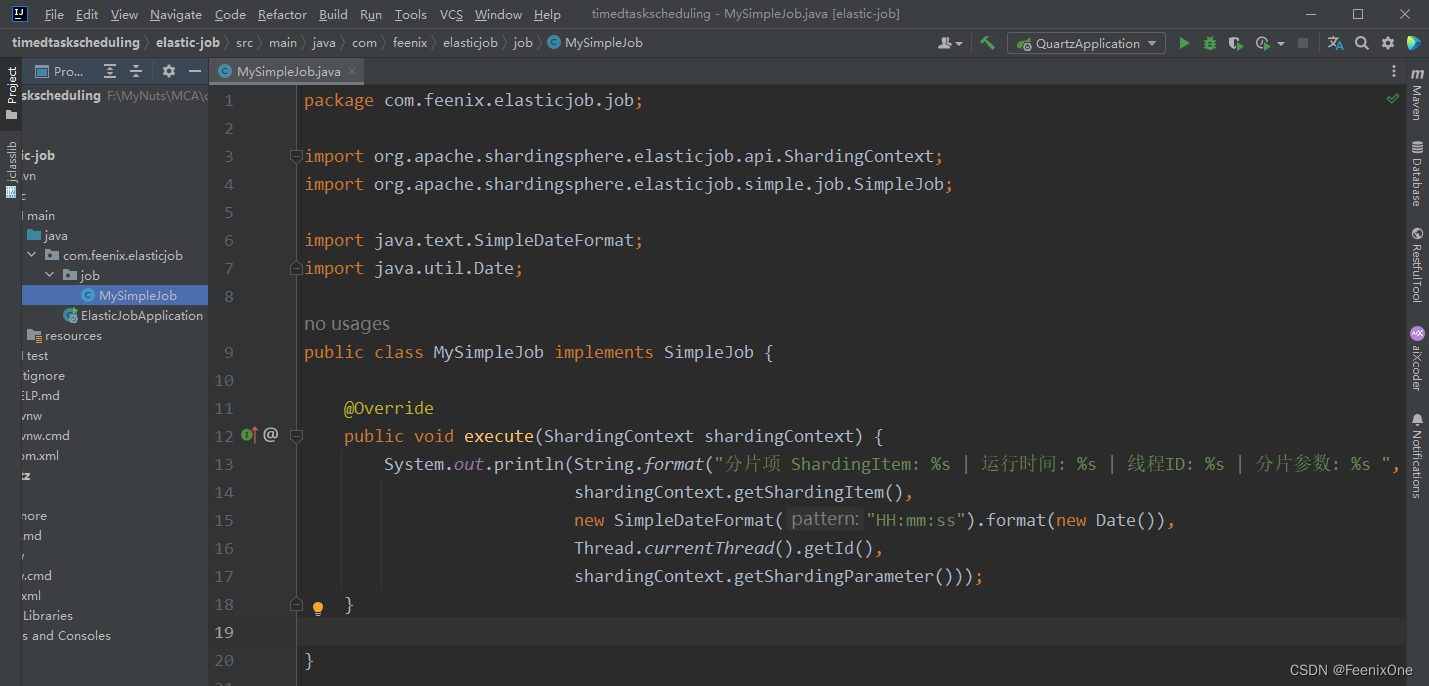
构建注册中心, 配置任务作业
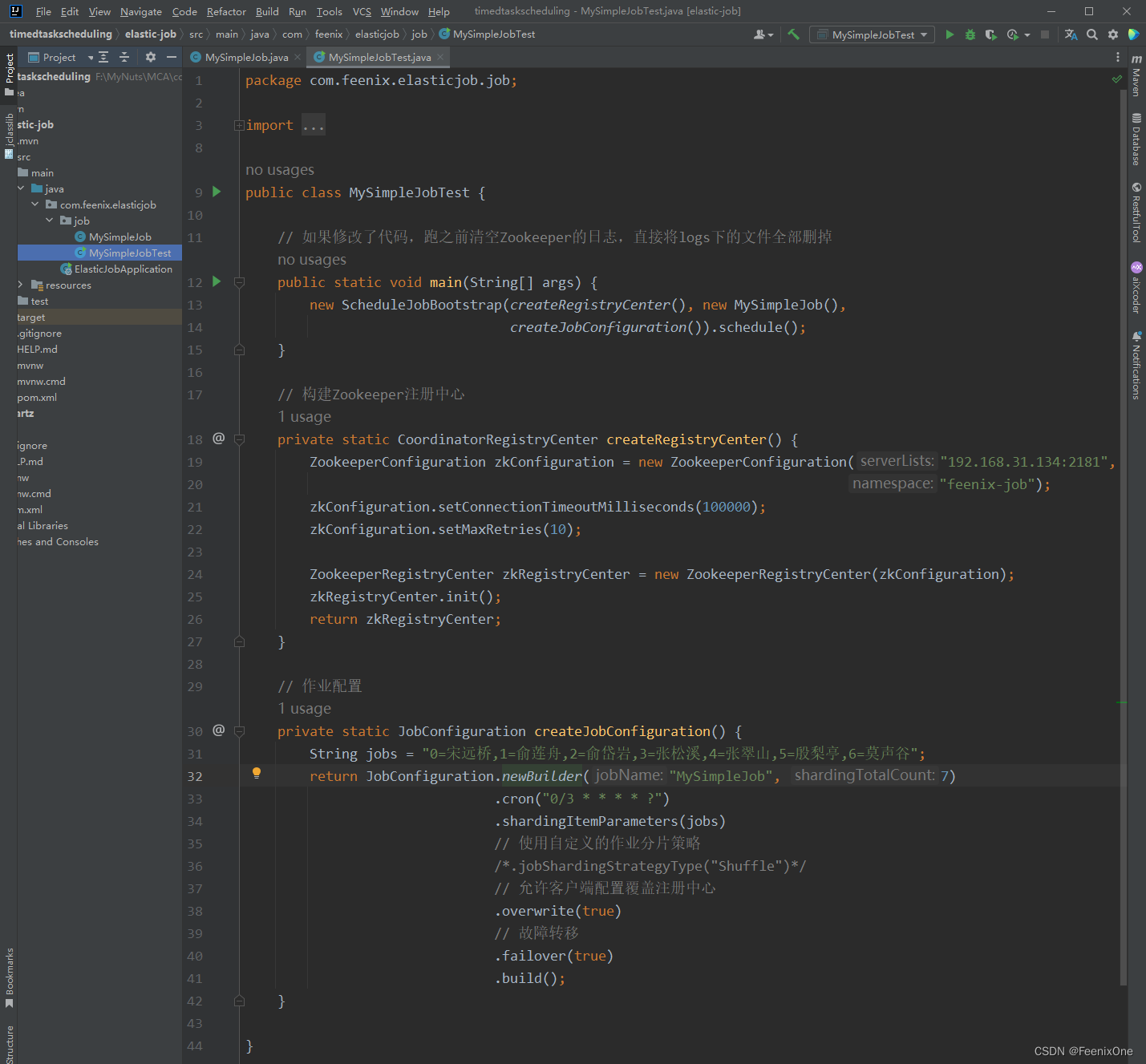
启动Elastic-Job服务
可以看到,指定的7个分片进行任务的执行。这里只是简单的打印一句话,在实际的业务中,可以通过代码判断,控制不同的分片执行不同的任务,就可以进行任务的拆分执行。
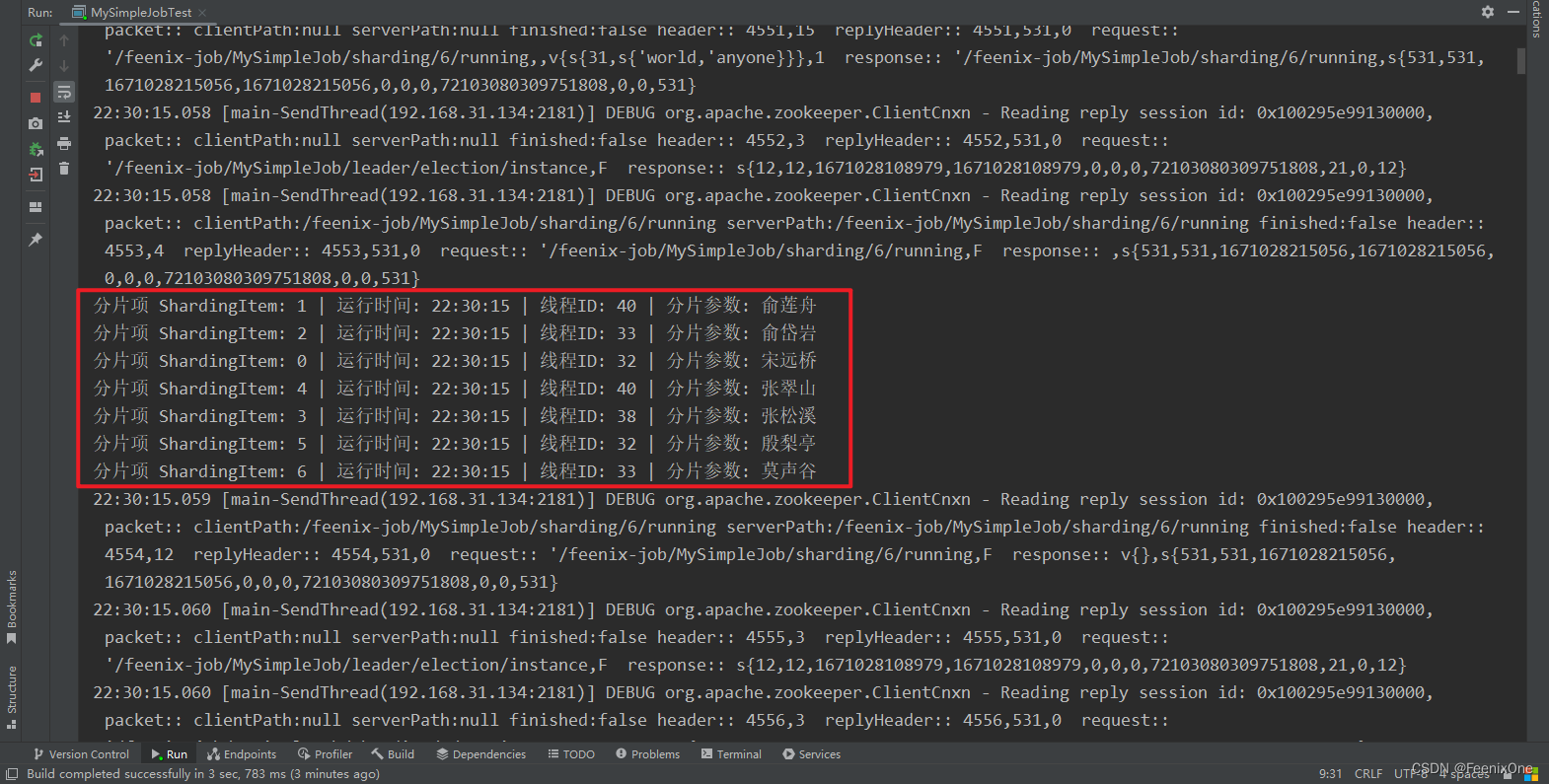
官网的教程甚至都没有给出如何构建作业配置.....

DataFlowJob
上面演示的是最简单的任务模式,Elastic-Job还提供了另外一种数据流模式:DataFlowJob,用于处理数据流。必须实现fetchData()和processData()的方法,一个用来获取数据,一个用来处理获取到的数据,其它跟SimpleJob没有区别。
实现DataFlowJob接口
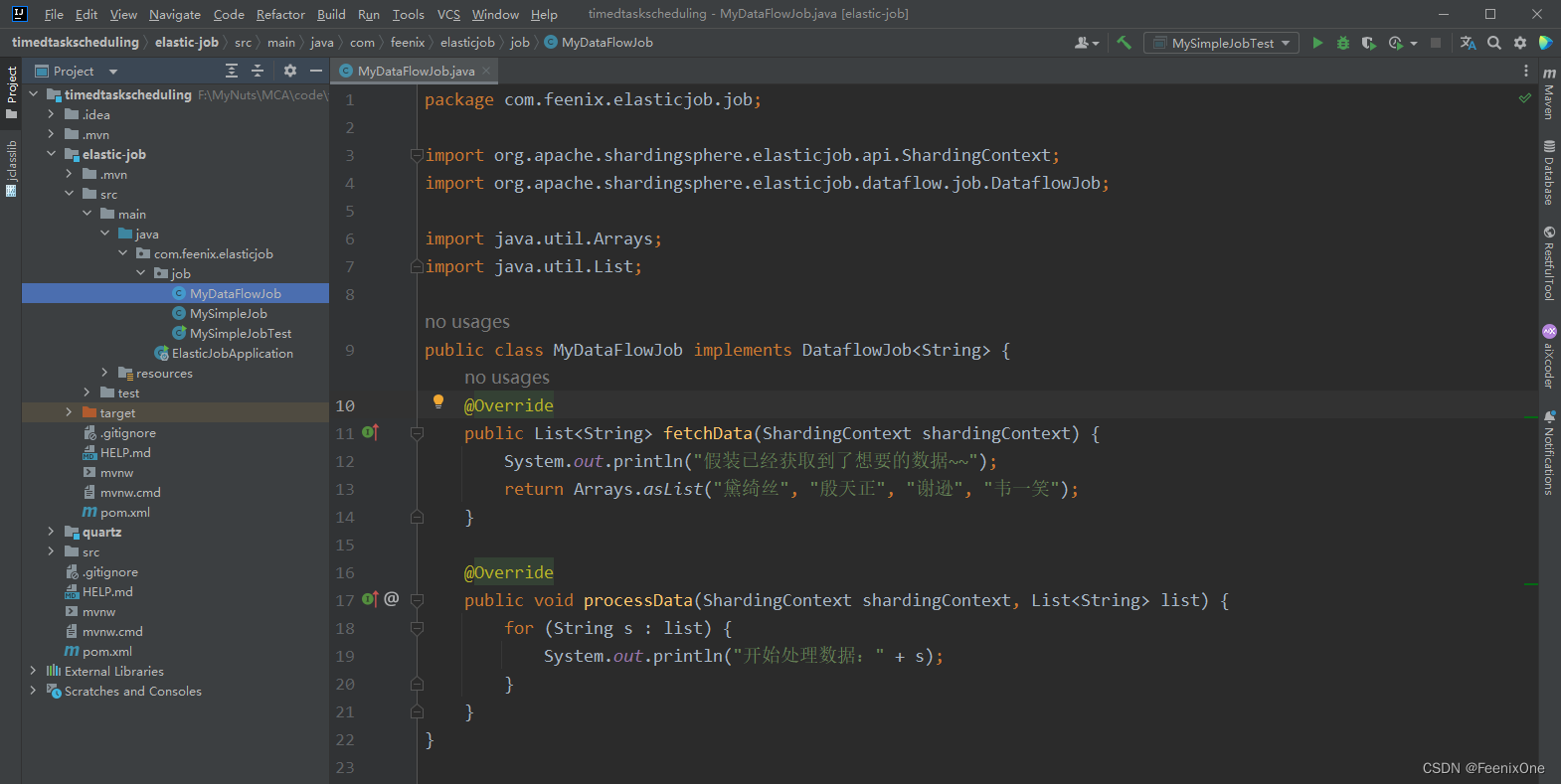
构建注册中心, 配置任务作业
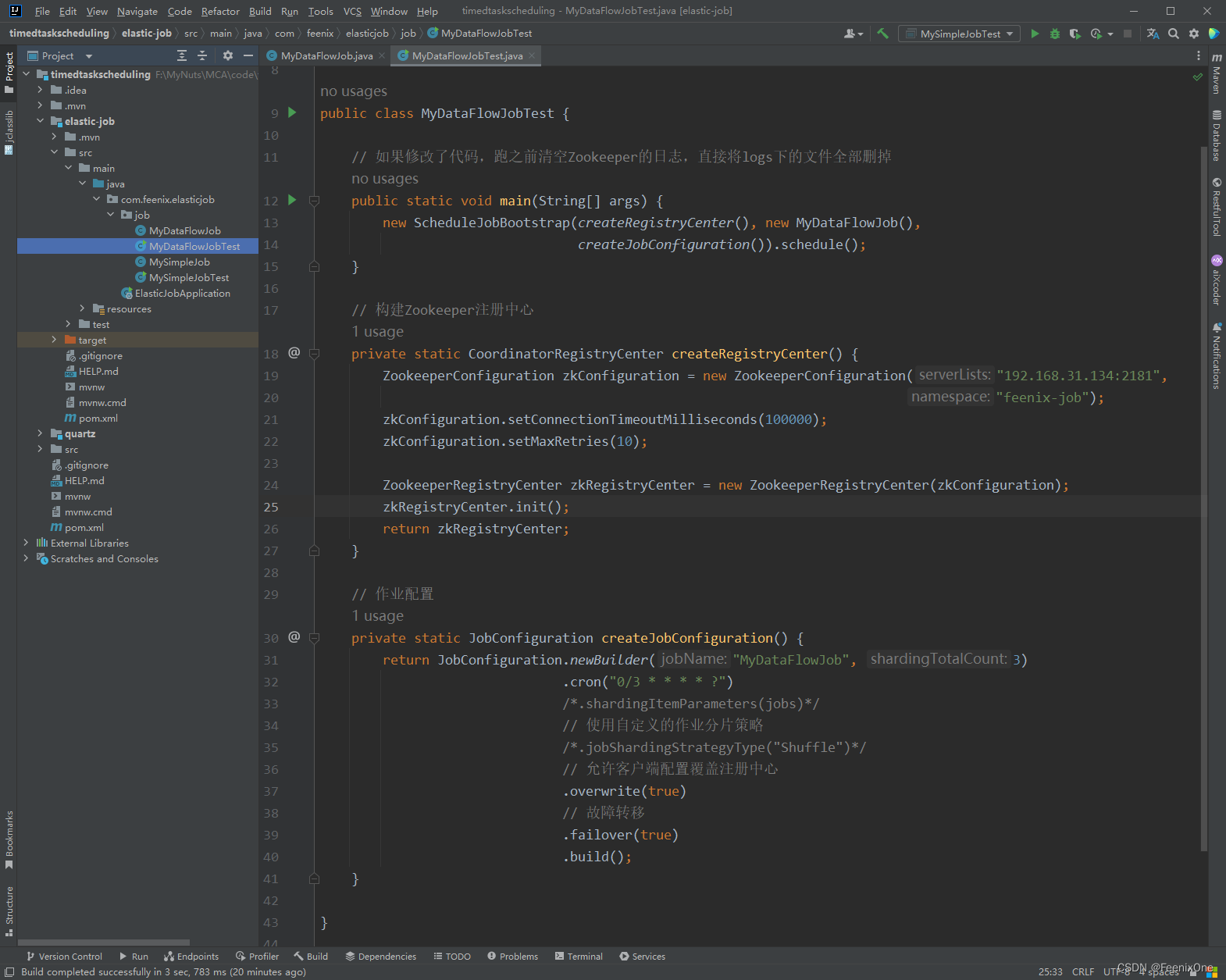
启动Elastic-Job服务
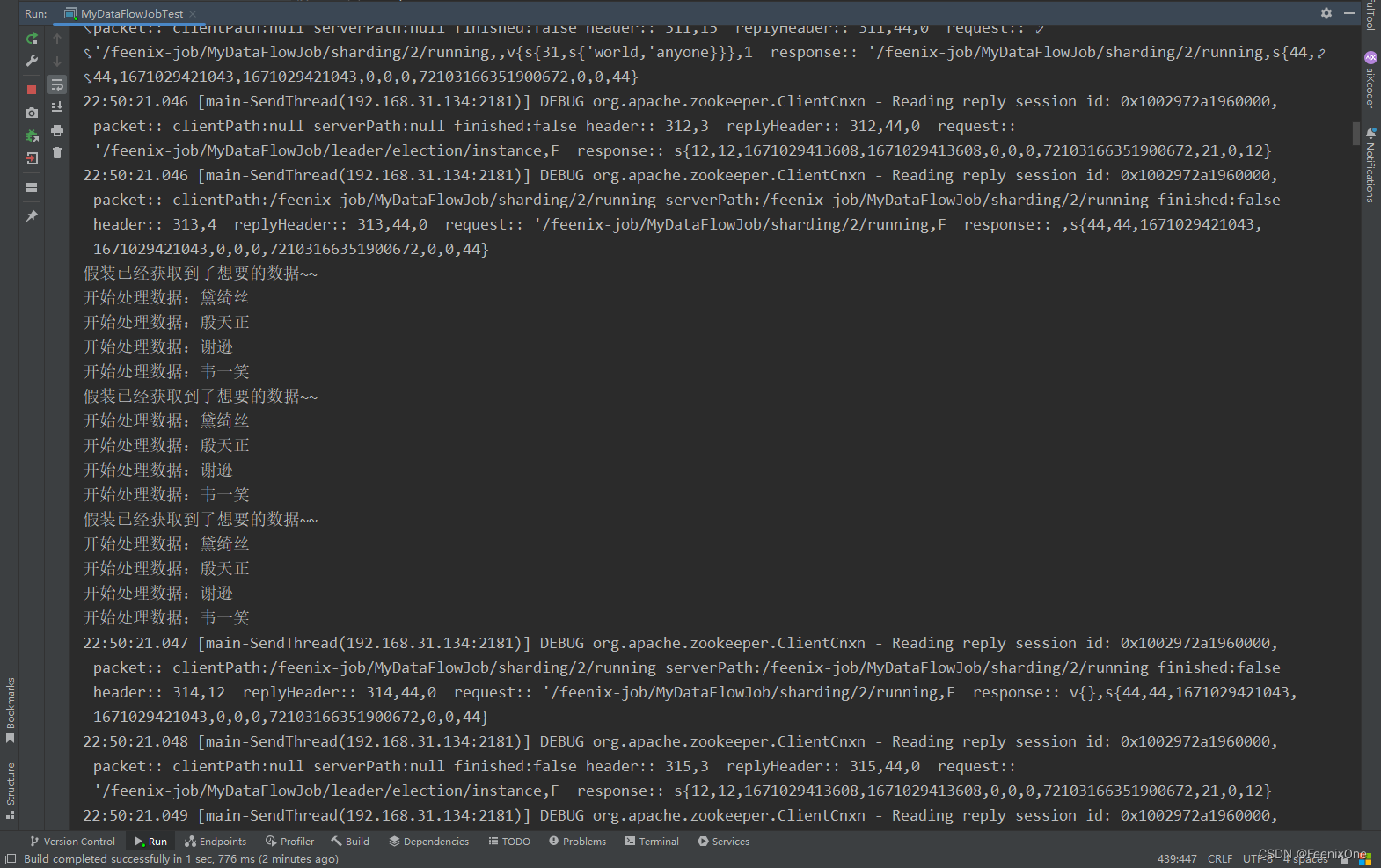
可以看到,定义的3个分片进行任务执行
ScriptJob
Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。说白了,这种类型的Job就是定时去执行脚本文件。把需要执行的脚本文件写好,告诉它在哪里,什么名字,到点了它自动去给你跑了就算完事儿。
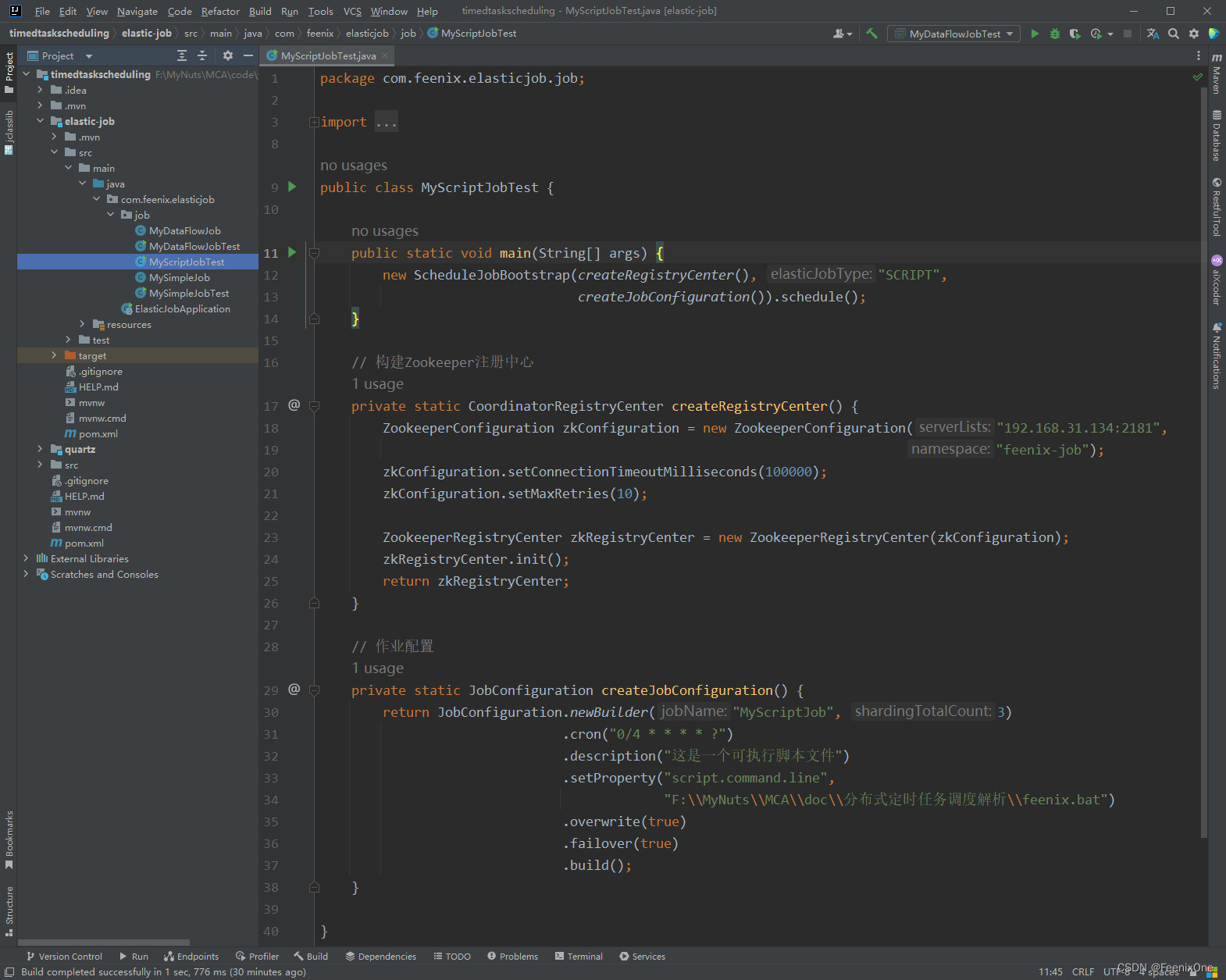
使用ScriptJob这种类型的时候,有几个点需要注意一下:
1、在构建调度器Scheduler时,参数elasticJobType固定写死就是"SCRIPT";
2、在构建作业配置时,.setProperty方法的第一个参数也是固定写死"script.command.line",第二个参数是脚本文件的绝对路径;
脚本内容就是很简单的一句话:@echo ------【脚本任务】Sharding Context: %*
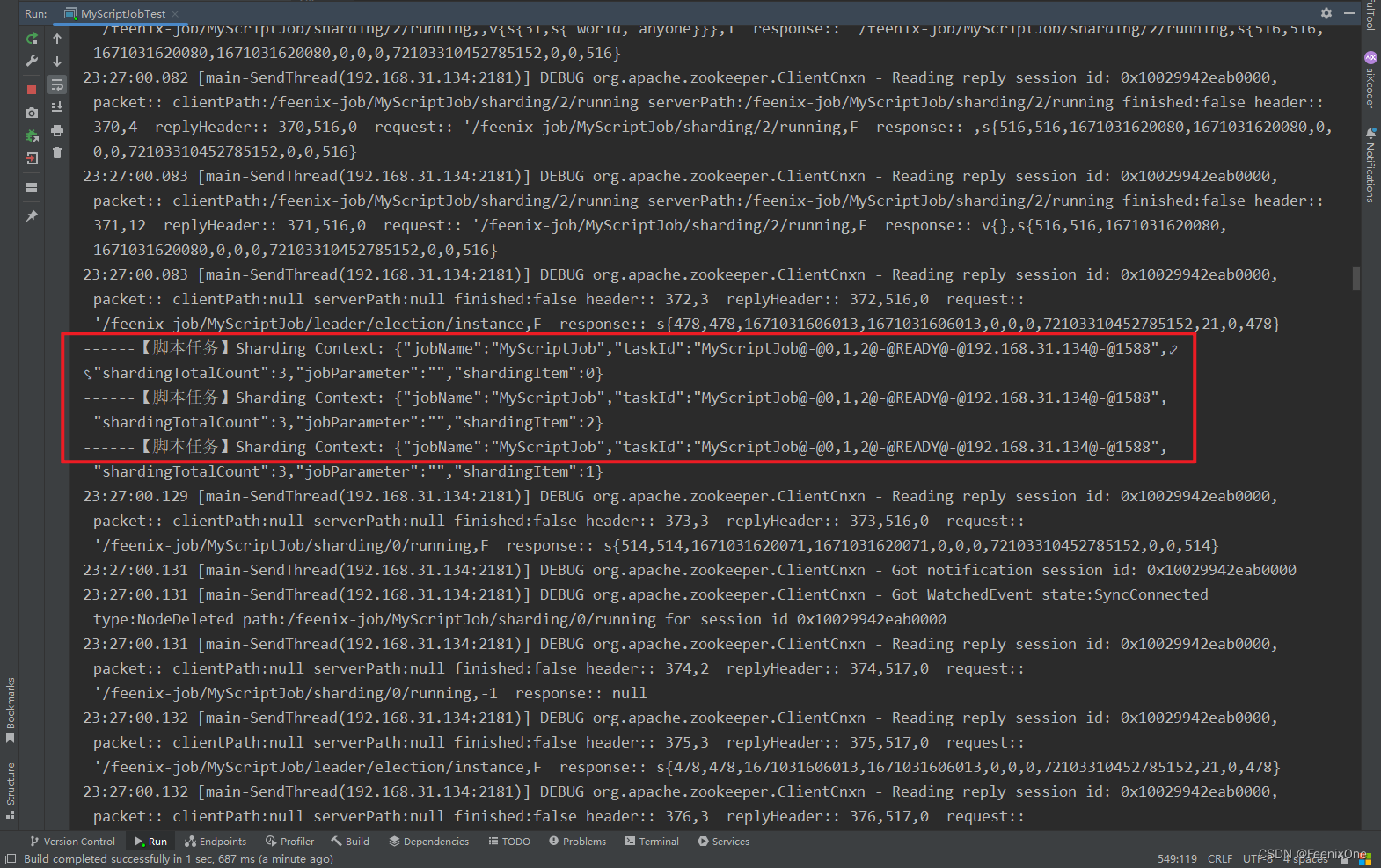
4、通过SPI的方式实现自定义作业类型
自定义任务接口,继承ElasticJob接口
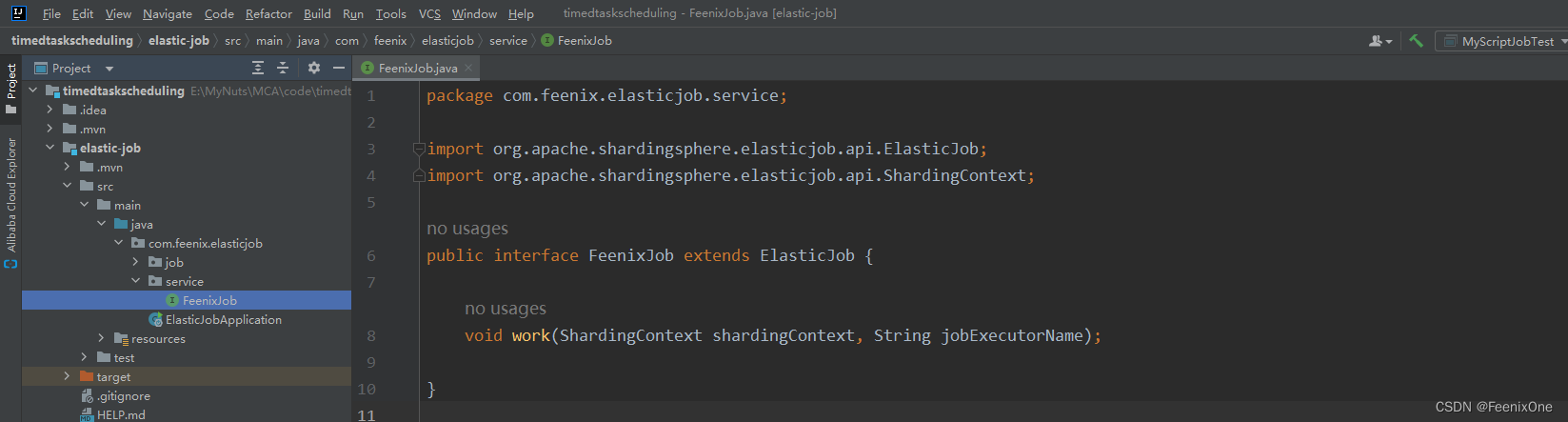
实现自定义的任务接口
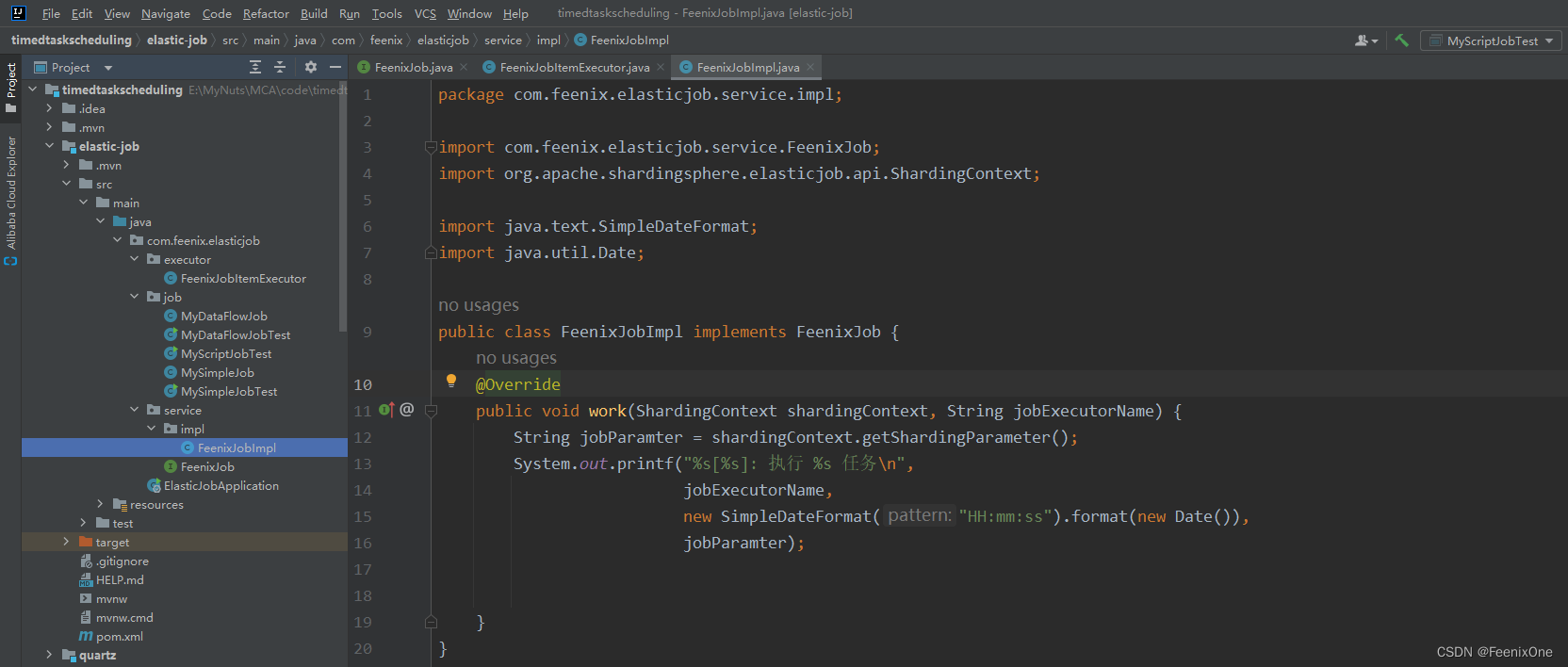
自定义任务执行器接口,继承ClassedJobItemExecutor接口
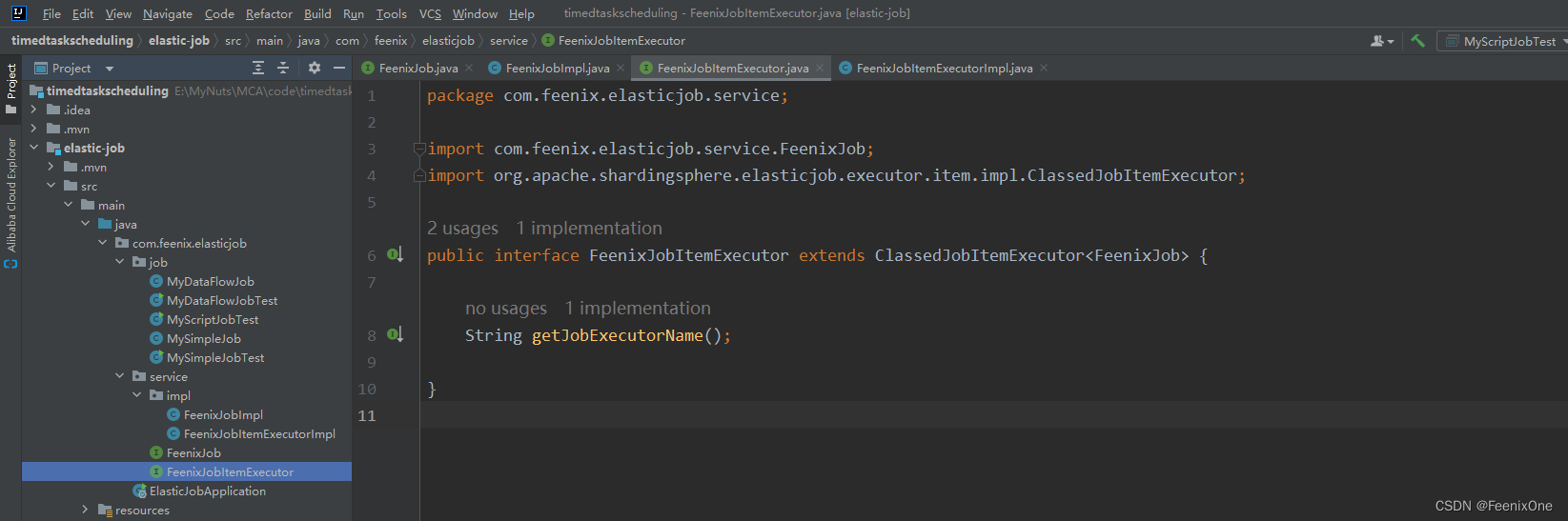
实现自定义的任务执行器接口
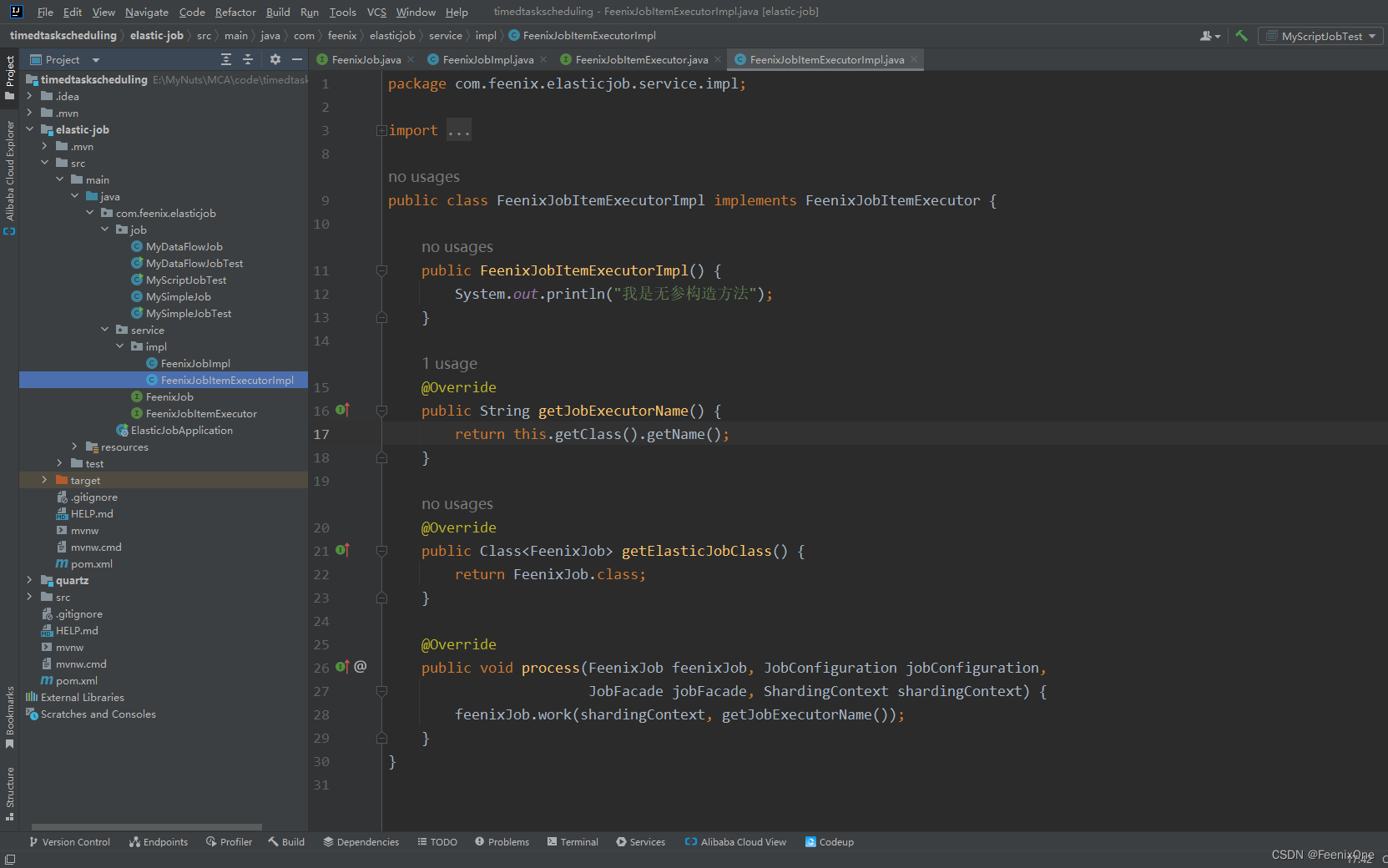
创建配置文件
在 resources.META-INF.services 目录下,以任务执行器接口的全路径名称创建一个配置文件,内容就是自定义的任务执行器实现类的全路径名
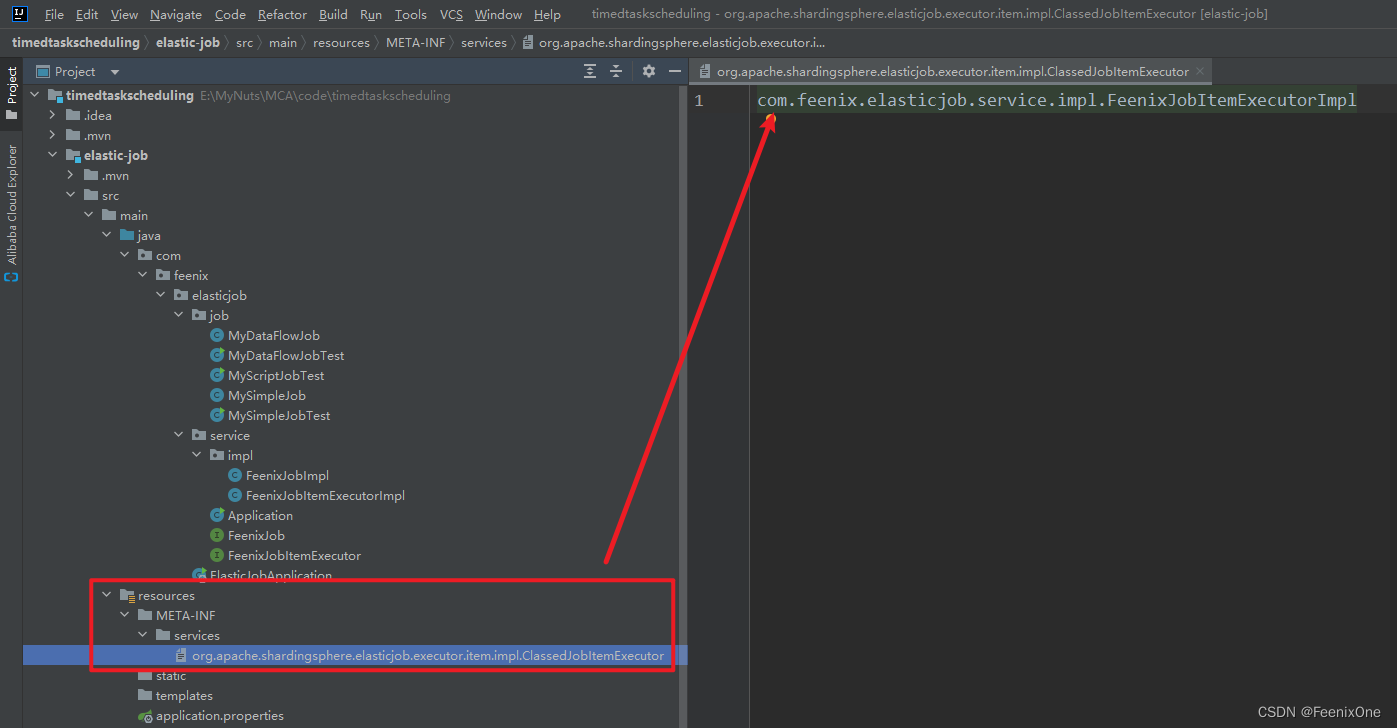
执行自定义的作业
package com.feenix.elasticjob.service;
import com.feenix.elasticjob.service.impl.FeenixJobImpl;
import org.apache.shardingsphere.elasticjob.api.JobConfiguration;
import org.apache.shardingsphere.elasticjob.lite.api.bootstrap.impl.ScheduleJobBootstrap;
import org.apache.shardingsphere.elasticjob.reg.base.CoordinatorRegistryCenter;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperConfiguration;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperRegistryCenter;
public class Application {
public static void main(String[] args) {
new ScheduleJobBootstrap(createRegistryCenter(),
new FeenixJobImpl(),
createJobConfiguration())
.schedule();
}
// 构建Zookeeper注册中心
private static CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zkConfiguration = new ZookeeperConfiguration("192.168.0.31:2181",
"feenix-job");
zkConfiguration.setConnectionTimeoutMilliseconds(100000);
zkConfiguration.setMaxRetries(10);
ZookeeperRegistryCenter zkRegistryCenter = new ZookeeperRegistryCenter(zkConfiguration);
zkRegistryCenter.init();
return zkRegistryCenter;
}
// 作业配置
private static JobConfiguration createJobConfiguration() {
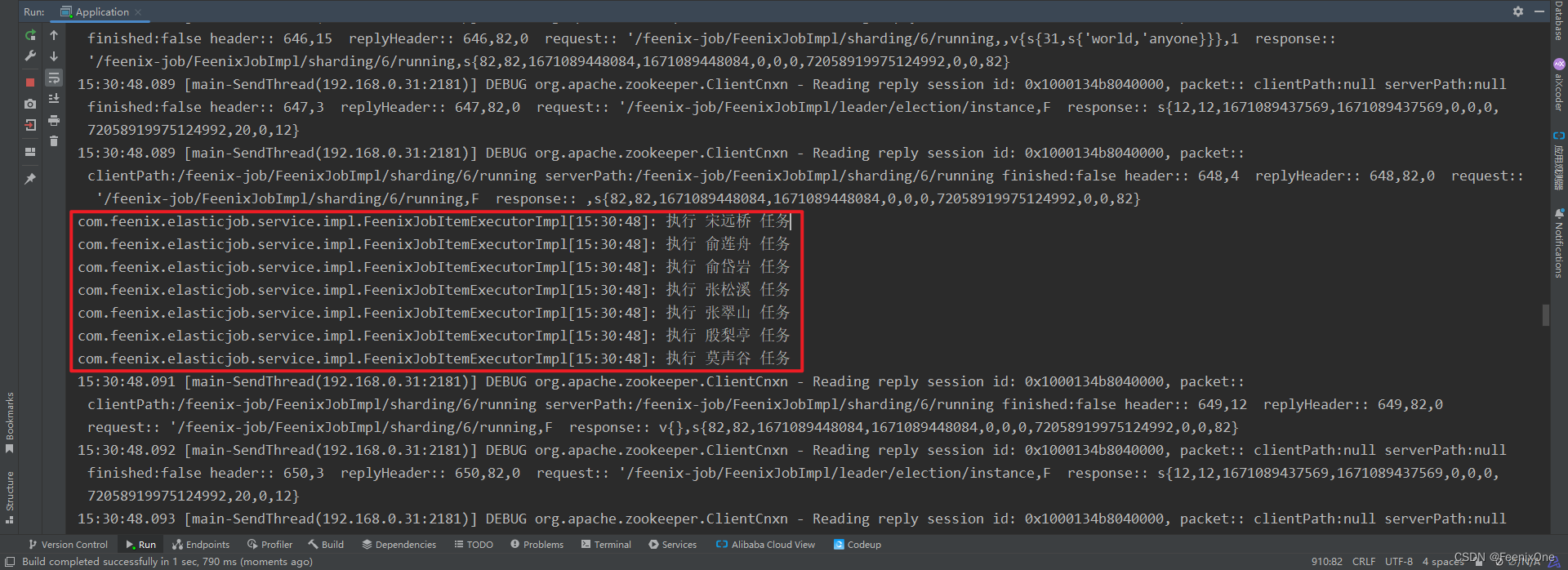
String jobs = "0=宋远桥,1=俞莲舟,2=俞岱岩,3=张松溪,4=张翠山,5=殷梨亭,6=莫声谷";
return JobConfiguration.newBuilder("FeenixJobImpl", 7)
.cron("0/3 * * * * ?")
.shardingItemParameters(jobs)
// 使用自定义的作业分片策略
/*.jobSharding StrategyType("Shuffle")*/
// 允许客户端配置覆盖注册中心
.overwrite(true)
// 故障转移
.failover(true)
.build();
}
}
5、分片
Elastic-Job中任务分片的概念,使得任务可以在分布式环境下运行,每台任务服务器只运行分配给该服务器的分片。随着服务器的增加或宕机,Elastic-Job会近乎实时的感知服务器的数量变更,从而重新为分布式服务器分配更合理的任务分片项,是的任务可以随着资源的增加而提升效率。
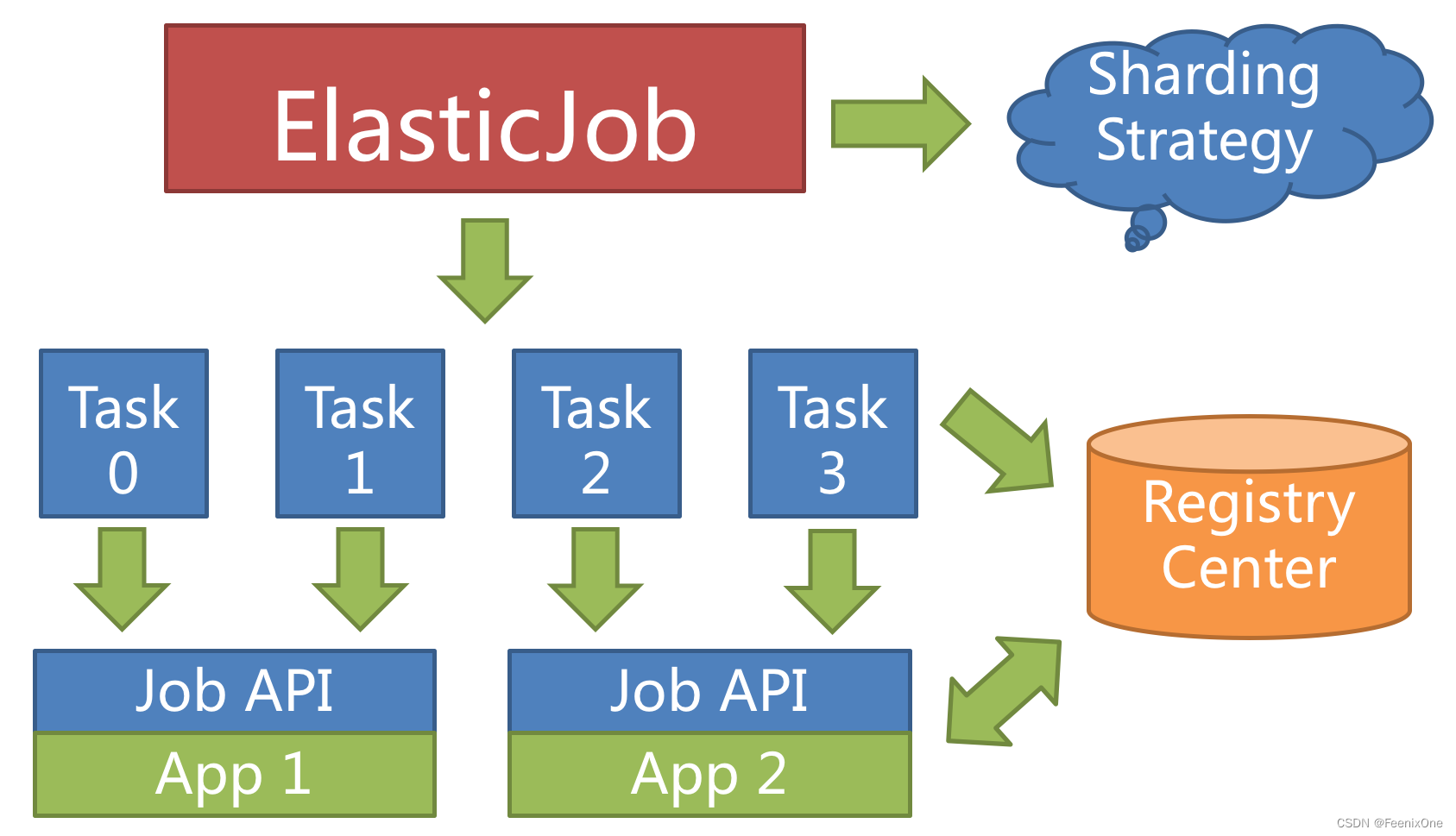
不过在上文中有提到过,Elastic-Job并不直接提供数据处理的功能,而是将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与业务的对应关系。分片项为数字,从0开始。例如:按照地区水平拆分数据库,数据库 A 是北京的数据;数据库 B 是上海的数据;数据库 C 是广州的数据。 如果仅按照分片项配置,开发者需要了解 0 表示北京;1 表示上海;2 表示广州。 合理使用个性化参数可以让代码更可读,如果配置为 0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
AverageAllocationJobShardingStrategy
基于平均分配算法的分片策略,也是默认的分片策略。如果分片不能整除,则余下的分片依次追加到顺序序号的服务器:
1、3台服务器,分成9片。第1台为[0,1,2]、第2台为[3,4,5]、第3台为[6,7,8];
2、3台服务器,分成8片。第1台为[0,1,6]、第2台为[2,3,7]、第3台为[4,5];
3、3台服务器,分成10片。第1台为[0,1,2,9]、第2台为[3,4,5]、第3台为[6,7,8];
OdevitySortByNameJobShardingStrategy
根据作业名哈希值的奇偶数决定IP升降序算法的分片策略。奇数则IP升序,偶数则IP降序,用于不同的作业平均分配负载至不同的服务器。
自定义分片策略
实现JobShardingStrategy接口
package com.feenix.elasticjob.strategy;
import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobInstance;
import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobShardingStrategy;
import java.util.*;
public class CustomJobShardingStrategy implements JobShardingStrategy {
@Override
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount) {
// 作业分片加入容器
ArrayList<Integer> customShardingList = new ArrayList<>();
for (int i = 0; i < shardingTotalCount; i++) {
customShardingList.add(i);
}
// 将容器中的作业分片项顺序打乱
Collections.shuffle(customShardingList);
// 模拟AverageAllocationJobShardingStrategy算法
Map<JobInstance, List<Integer>> result = shardingCustom(jobInstances, shardingTotalCount, customShardingList);
addCustom(jobInstances, shardingTotalCount, result, customShardingList);
return result;
}
private Map<JobInstance, List<Integer>> shardingCustom(final List<JobInstance> shardingUnits,
final int shardingTotalCount,
final ArrayList<Integer> customShardingList) {
Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingUnits.size(), 1);
int itemCountPerSharding = shardingTotalCount / shardingUnits.size();
int count = 0;
for (JobInstance each : shardingUnits) {
// 每个作业服务器申请的作业分片项列表,容量是itemCountPersharding+1,为每个作业最大的分片项
List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1);
for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) {
shardingItems.add(customShardingList.get(i));
}
result.put(each, shardingItems);
count++;
}
return result;
}
private void addCustom(final List<JobInstance> shardingUnits,
final int shardingTotalCount,
final Map<JobInstance, List<Integer>> shardingResults,
final ArrayList<Integer> customShardingList) {
int aliquant = shardingTotalCount % shardingUnits.size();
int count = 0;
for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) {
if (count < aliquant) {
entry.getValue().add(customShardingList.get(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count));
}
count++;
}
}
@Override
public String getType() {
return "CUSTOM";
}
}
创建配置文件
在 resources.META-INF.services 目录下,以自定义策略实现类的接口的全路径名称创建一个文件,内容就是自定义策略实现类的全路径
使用IDEA开启两个不同的服务实例
package com.feenix.elasticjob.service;
import com.feenix.elasticjob.service.impl.FeenixJobImpl;
import org.apache.shardingsphere.elasticjob.api.JobConfiguration;
import org.apache.shardingsphere.elasticjob.lite.api.bootstrap.impl.ScheduleJobBootstrap;
import org.apache.shardingsphere.elasticjob.reg.base.CoordinatorRegistryCenter;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperConfiguration;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperRegistryCenter;
public class Application {
public static void main(String[] args) {
new ScheduleJobBootstrap(createRegistryCenter(), new FeenixJobImpl(), createJobConfiguration()).schedule();
}
// 构建Zookeeper注册中心
private static CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zkConfiguration = new ZookeeperConfiguration("192.168.0.31:2181",
"feenix-job");
zkConfiguration.setConnectionTimeoutMilliseconds(100000);
zkConfiguration.setMaxRetries(10);
ZookeeperRegistryCenter zkRegistryCenter = new ZookeeperRegistryCenter(zkConfiguration);
zkRegistryCenter.init();
return zkRegistryCenter;
}
// 作业配置
private static JobConfiguration createJobConfiguration() {
String jobs = "0=宋远桥,1=俞莲舟,2=俞岱岩,3=张松溪,4=张翠山,5=殷梨亭,6=莫声谷";
return JobConfiguration.newBuilder("FeenixJobImpl", 7)
.cron("0/3 * * * * ?")
.shardingItemParameters(jobs)
// 使用自定义的作业分片策略
.jobShardingStrategyType("CUSTOM")
// 允许客户端配置覆盖注册中心
.overwrite(true)
// 故障转移
.failover(true)
.build();
}
}
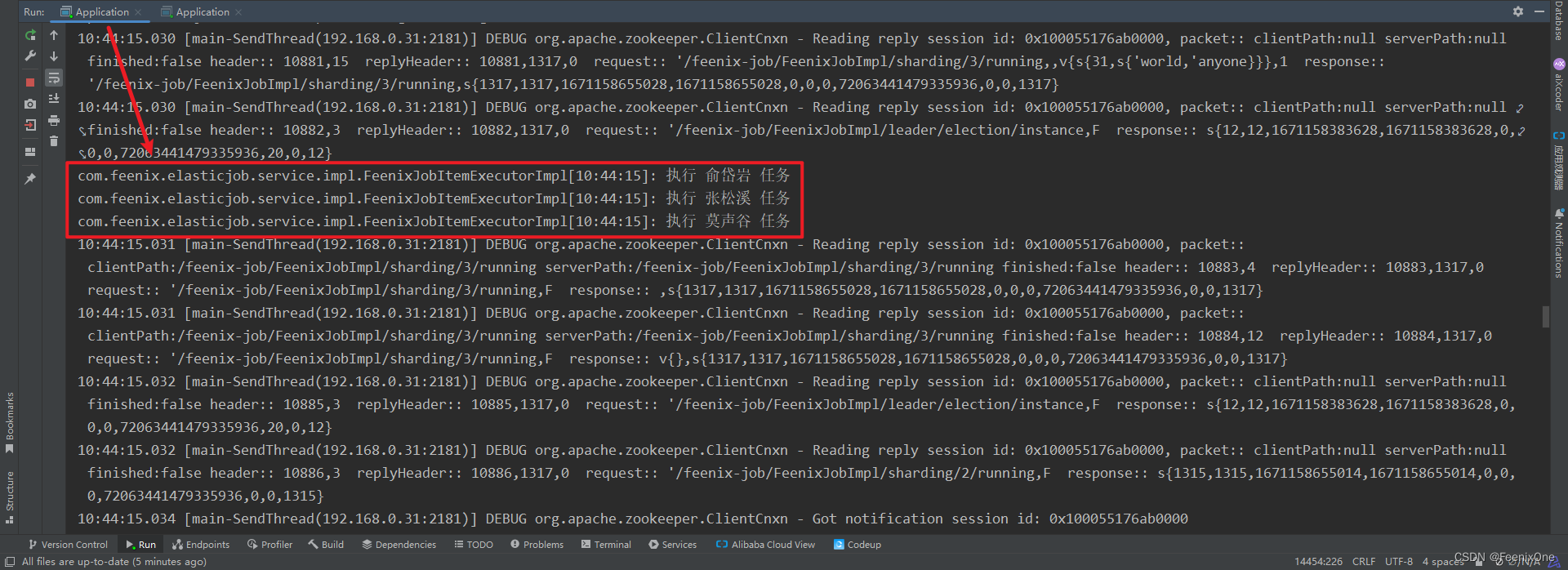
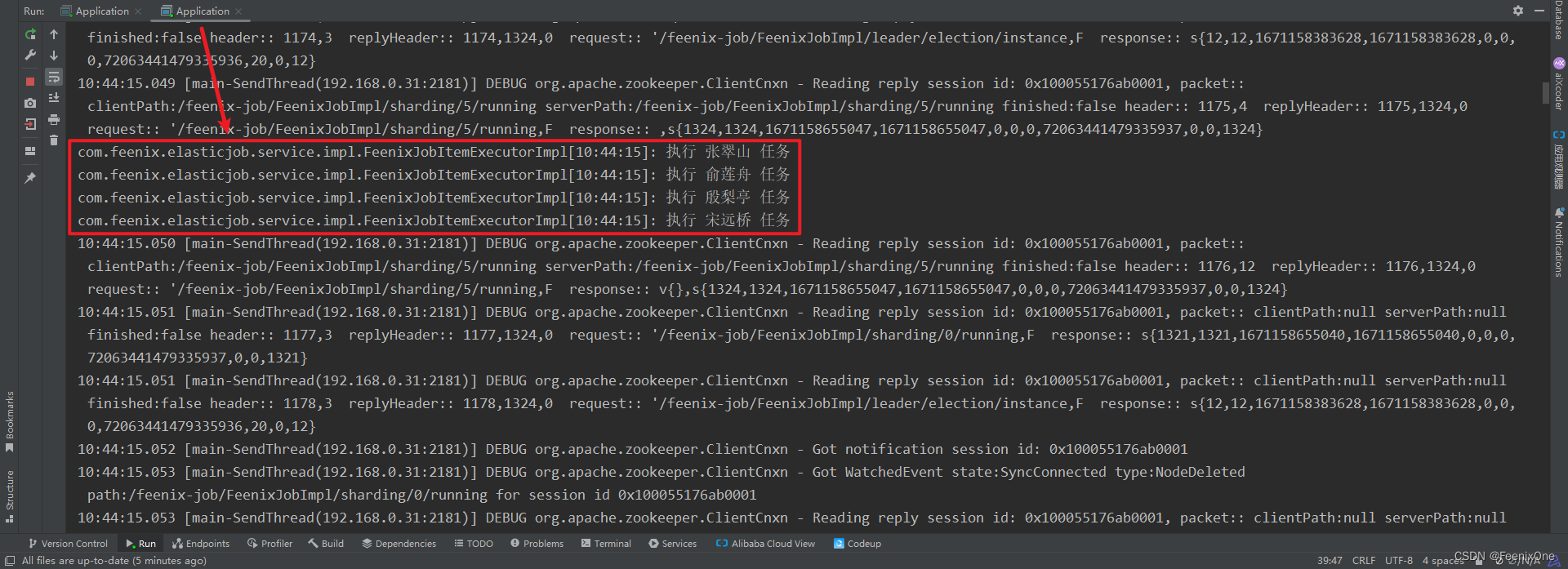
jobShardingStrategyType的值要设为"CUSTOM",因为在自定义分片策略的时候,已经将自定义的策略类型写死为"CUSTOM"。
可以看到,在同时开启两个实例的情况下,根据自定义的策略作业被分配到两个不同的实例上执行


![[附源码]Node.js计算机毕业设计高校学科竞赛管理系统Express](https://img-blog.csdnimg.cn/3e1497c5467e4b9d9bc096dcf2991741.png)