文章目录
- 文章引入
- IO模型及概念梳理
- BIO
- 简单介绍
- 代码样例
- 压测结果
- NIO(单线程模型)
- 简单介绍
- 与BIO的比较
- 代码样例
- 压测结果
- 多路复用器
- 问题引入
文章引入
如果你对BIO、NIO、多路复用器有些许疑惑, 那么这篇文章就是肯定需要看的, 本文将主要从概念, 代码实现、发展历程的角度去突出并解决各个IO模型问题, 并用实际代码样例进行演示, 使你更加直观.
本文在介绍各个IO模型后, 都将给出样例代码接收处理5000个连接, 打印出各自处理需要的时间, 各自效率一览便知.
IO模型及概念梳理
Java中的IO模型主要有三种BIO和NIO.AIO.其实主要是同步阻塞,同步不阻塞,异步不阻塞的区别。
这里的同步,异步,阻塞,非阻塞解释如下:
- 同步:当触发读写请求后,你的程序自己去读写数据, 即自己写代码去做读写这个动作,那么就是同步的.
简单来说就是应用发送完指令要参与这个过程,直到返回数据. - 异步:当触发读写请求后(这里不是去缓冲区读写,仅仅告诉内核我想去读取数据),直接返回,内核帮助你完成整个操作后,帮你将数据从内核复制到应用空间,再通知你.
简单来说就是应用发送完指令不再参与整个过程,直接返回等待通知. - 阻塞:试图对缓冲区进行读写时,当前不可读或者不可写(内核数据没有准备好的情况下),程序进行等待,直到可以操作。
- 非阻塞:试图对缓冲区进行读写时,当前不可读或者不可写,读取函数马上返回
看到这里你可能还是对这些概念似懂非懂, 没关系, 当你看到实际演示代码时就自然懂了
当然, 需要提一下, 本篇文章主要讨论同步阻塞和同步非阻塞, 异步非阻塞还没有实际运用起来, 比如Netty,Tomcat现在还依然是NIO. 所以AIO暂不在本文讨论范围内.
BIO
简单介绍
BIO, 即BLOCKING IO, 同步阻塞IO, 那它可能阻塞在哪里呢? 主要是以下两个步骤
- accept()
当服务端准备好入等待客户端连接时, 也就是执行accept方法时, 会发生阻塞, 一直等到有客户端连接进来 - read()
当创建好一个连接后, 这个socket对象去读取数据的时候, 会发生阻塞, 一直等到对方发送过来数据, 并且能够读取返回
代码样例
服务端代码 :
public class ServerSocketTest {
public static void main(String[] args) {
ServerSocket server = null;
try {
server = new ServerSocket();
server.bind(new InetSocketAddress(9090));
System.out.println("server up use 9090");
long startTime = System.currentTimeMillis();
int count = 0;
while(true){
try {
//真正开启监听
Socket client = server.accept();
System.out.println("client port: "+client.getPort());
new Thread(() -> {
while(true){
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
char[] data = new char[1024];
int num = reader.read(data);
if(num>0){
System.out.println("client read some data :"+new String(data));
}else if(num==0){
System.out.println("client read data nothing......");
}else{
System.out.println("client read data error......");
client.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
if(++count >= 5000){
System.out.println("处理5000个连接用时:"+(System.currentTimeMillis()-startTime)/1000+"s");
break;
}
} catch (IOException e) {
e.printStackTrace();
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
server.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.exit(0);
}
}
简单介绍:
上述代码每次拿到一个新的连接后, 会新new一个线程去进行真正的数据读取发送, 主线程就干一件事情, 监听建立新连接.
为什么要这样做呢?
因为如果都在一个线程里, 那么一个服务端只能处理一个客户端请求, 因为读请求也是阻塞的, 会影响到主线程监听建立新连接, 根本没法玩, 玩不动.
客户端代码:
public class C10K {
public static void main(String[] args) throws InterruptedException {
InetSocketAddress serverAddr = new InetSocketAddress("192.168.68.2", 9090);
//线性发起10000个连接
byte[] bytes = "hello".getBytes();
ByteBuffer buffer = ByteBuffer.allocate(1024);
for (int i = 10000; i < 15000; i++) {
try {
//建立连接
SocketChannel client = SocketChannel.open();
client.bind(new InetSocketAddress("192.168.68.248",i));
client.connect(serverAddr);
//发送数据,这里每次发送固定的,且只是单一的发送固定数据, 就共用一个buffer
//正常复杂读写为每个连接单独维护buffer更安全可靠
buffer.put(bytes);
buffer.flip();
client.write(buffer);
buffer.clear();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("连接都处理完毕,未避免程序停止关闭连接,这里直接等待......");
Thread.sleep(50000);
}
}
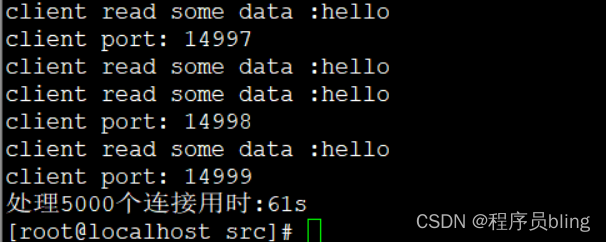
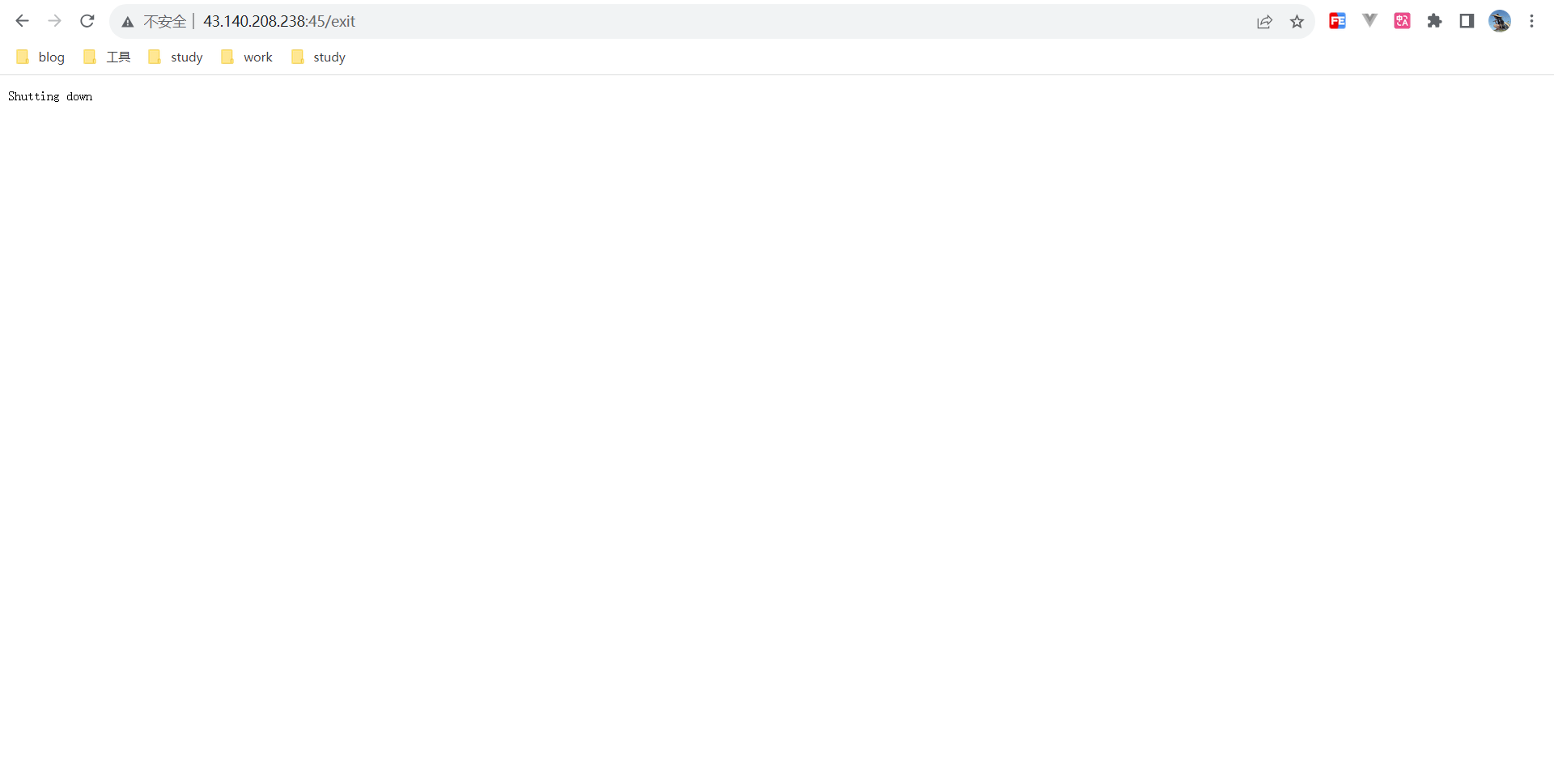
压测结果
直接用上述的客户端代码, 不断想服务端发起连接请求, 测试结果如下:
NIO(单线程模型)
简单介绍
NIO, 这个N有两层含义
对于JDK而言: 是New IO, jdk nio包的类既支持阻塞模型,也支持非阻塞模型
对于操作系统: 是 NO BLOCKING
我们这里讲的主要是操作系统层面的,即非阻塞IO, BIO会在accept()和read()方法阻塞, 而NIO则均不会阻塞, 会直接返回,
比如accept()方法, 如果有新连接, 就返回连接对象, 如果没有, 则立即返回null.这一点可以在后序的样例代码中体会到.
与BIO的比较
传统BIO的劣势: 每新来一个连接就要new一个线程, 非常非常耗费资源,支持不了数量庞大的连接.
NIO的优势 : 可以通过一个或几个线程来解决N个IO连接的处理.比如以下的样例, 处理5000个连接只用了一个线程.
代码样例
服务端代码:
public class SocketNIO {
public static void main(String[] args) throws Exception {
ArrayList<SocketChannel> clients = new ArrayList<>();
//通道, 可读可写, 是JDK new io 中的工具类
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(9090));
//设置为非阻塞, 即no blocking, 当设置了这一步进行accept时便不会阻塞,会直接返回
//如果设置为true, 就相当于BIO
serverSocketChannel.configureBlocking(false);
//ByteBuffer同时支持读写,有指针控制
//写切换成读需要调用flip方法,就是将指针移动至未读的位置
//读切换成写需要调用compact方法, 把读取过的字节往前覆盖掉,指针移动至还未写入数据的位置
//这里可以采用堆内或者堆外的方式分配内存, Direct就是堆外的方式
ByteBuffer buffer = ByteBuffer.allocate(1024);
//ByteBuffer allocate = ByteBuffer.allocateDirect(4096);
long startTime = System.currentTimeMillis();
while (true) {
//这里如果没有接收到客户端, jdk api便会返回null
//如果有, 便会返回相应对象
SocketChannel client = serverSocketChannel.accept();
if(client==null){
continue;
}
//这里设置的是read不进行阻塞
client.configureBlocking(false);
int port = client.socket().getPort();
System.out.println("add client port:"+port);
clients.add(client);
for (int i = 0; i < clients.size(); i++) {
SocketChannel curClient = clients.get(i);
//这里不阻塞,直接返回
//没有数据的话直接返回-1
int read = curClient.read(buffer);
if(read<=0){
continue;
}
//对于buffer,刚刚是写,现在进行读操作,调用flip
buffer.flip();
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
String str = new String(bytes);
System.out.println(curClient.socket().getRemoteSocketAddress()+" -->" +str);
//一次循环之后又需要进行写入,这里直接clear清0,就无需调用compact方法
buffer.clear();
}
if(clients.size() >= 5000){
System.out.println("处理5000个连接用时:"+(System.currentTimeMillis()-startTime)/1000+"s");
break;
}
}
serverSocketChannel.close();
}
}
测试使用的客户端代码还是和上面的一样, 这里不再放了.
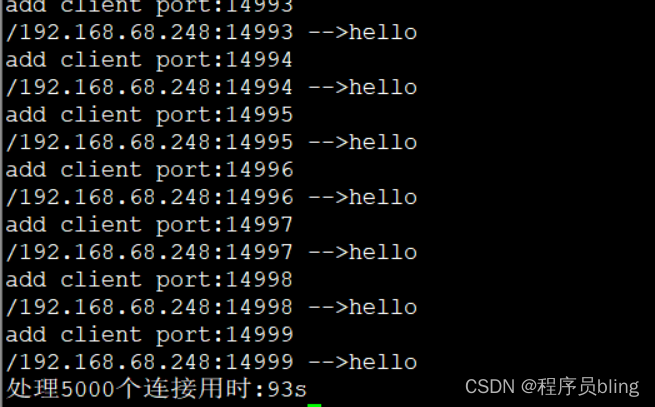
压测结果
还是用和BIO相同的客户端代码, 压测结果如下:
可能会比较惊讶, 竟然比BIO用时还多? 那这个NIO究竟慢在哪里呢?
继续往下看就知道了, 这也是为什么会有多路复用器.
多路复用器
问题引入
-
从上面两个比较结果看, 同样处理5000个请求, 直接使用NIO竟然比BIO用时还久, 这个一方面是因为上述NIO代码只用了一个线程, 如果分摊到几个线程, 比如5个, 每个线程负责1000个连接, 那速度会快一些
-
第二个最主要的点是传统NIO每次都是主动调用,主动去查看有没有新连接, 对于每一个连接有没有新数据,
每次循环的时间复杂度是0(n) n代表连接数, 也就是假如有10000个链接, 每次都要挨个循环一遍, 看看其缓冲区有没有准备好的数据, 并且这个操作(read)需要系统调用,调用内核级别的方法,涉及到用户态内核态切换,相当于10000次的系统调用, 成本很高
但是可能10000个连接里面可能某一个时刻,只有100个连接是有数据的, 这样循环就会造成浪费
这里引入了多路复用器, 但是多路复用器原理是什么, 怎么使用, 真实效率到底怎么样?
可直接点击链接观看BIO到NIO、多路复用器, 从理论到实践, 结合实际案例对比各自效率与特点(下)
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.








![java八股文面试[多线程]——sleep wait join yield](https://img-blog.csdnimg.cn/img_convert/7e288643040b63449dde9aa59802b8d6.webp?x-oss-process=image/format,png)