目录
背景
信息是什么
信息度量
小白鼠实验
哈夫曼编码
密码学
其它应用
背景
克劳德·艾尔伍德·香农(Claude Elwood Shannon)出生于 1916 年 美国密歇根州。1936 年毕业于密歇根大学,获得数学和电子工程学士学位。之后,他在麻省理工学院(MIT)获得数学博士学位和电子工程硕士学位。1941 年,他加入贝尔实验室, 一直从事研究和教学工作。
香农是一位全才型科学家,他在通信技术、信息工程、计算机技术、密码学等方面都作出了巨大的贡献。
香农的主要贡献包括以下几个方面:
1)信息论:香农在1948年发表了关于信息论的经典论文《通信的数学原理》,这个理论奠定了现代通信和信息处理的基础。他提出了信息的度量方式,用比特(bit)来表示信息的量,并提出了信道容量的概念,即信道能够传输的最大信息量。
2)香农编码:为了有效地传输和存储信息,香农提出了多种编码方法,其中最著名的是香农-费诺编码和香农-哈夫曼编码。这些编码方法可以使信息的传输更加高效和可靠。
3)随机密码系统:在第二次世界大战期间,香农在贝尔实验室从事密码学研究,并设计了一种基于随机数生成器的密码系统,被认为是现代密码学的奠基之作。
信息是什么
信息是一段文字、一张图片、一段声音、一种气息等?
香农对信息的定义是:信息是用来减少随机不确定性的东西。
【例子】我们玩一场猜数字游戏,数字在1~8范围内,我选择其中一个数字,让你来猜我选中的是什么数字。
游戏过程中,你可以问我这个数字是否大于、小于或等于某个数字,我的回答只有 “是” 或 “否“。
猜测的次数越少,得分越高。你会用什么策略来提问?
策略1:从数字1开始逐个提问(是否等于1,是否等于2,......,是否等于8),
第一次提问的不确定性是1/8,第二次是1/7,......,第八次是1,也就是每提问一次,
根据我反馈的信息 “是” 或 “否” 来减少猜测的范围,所以不确定性就逐渐减少。
该策略的效率非常低下,最坏的情况是结果数字是8,这样就要提问7次才能确定正确数字。
策略2:每次从中间的数字提问,第一次提问是否大于4,如果回答是,
第二次提问是否小于7,如果回答否,最后提问是否小于8,如果回答是,那么可以确定答案是数字7。
该策略只需要提问3次,每次提问后都能把数字范围减少一半,就可以很好地减少不确定性。
上面例子通过问答方式来获得信息,从而消除猜测数字过程中存在的 “不确定性”,
所谓的 “不确定性” 表示某事物的发生具有一定的概率,所以,香农信息属于 “概率信息”。
知道的信息越多,随机事件的不确定性就越小。
信息度量
香农厉害的地方是,使用统计的方式来量化信息,也就是对信息进行度量,用来计算某个事件发生的信息量有多少, 并用比特(bit)来表示。
香农把信息定义为是消除不确定性的东西,根据人们的一般经验可知:
- 事件发生的概率越小,不确定性就越大(信息量越大)
- 事件发生的概率越大,不确定性就越小(信息量越小)
概率为 1 的事件的信息量为 0(概率为 1 也就是必然事件,就像有人告诉你 “今天太阳从东边升起”,你一点都不会怀疑)。
概率为 0 的事件的信息量为无穷大(概率为 0 也就是不可能事件,就像有人告诉你 “今天太阳从西边升起”,你会感到不可思议)。
信息量 用来衡量一条消息所包含的信息量大小。它的概念是基于事件发生的概率来定义的,即当一个事件发生的概率较低时,它所包含的信息量较大,反之亦然。香农信息量的公式如下:
![]()
其中 I 表示信息量,P 表示事件发生的概率。这个公式表示,事件发生的概率越低,信息量就越大。
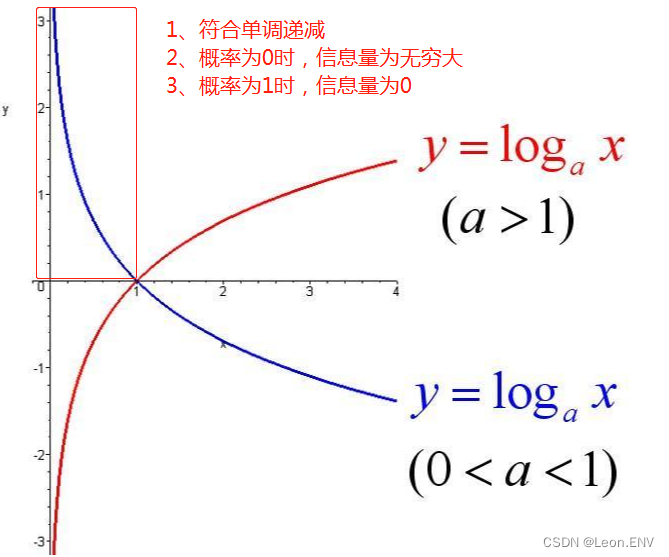
该事件发生的信息量应是该事件发生的概率的单调递减函数
如上面猜字游戏的信息量是 -log(1/8) = 3 bit,也就是说需要 3bit 的信息才能确定正确的数字。
信息熵 是衡量一组消息的平均不确定性的度量。它是对所有可能消息的信息量进行加权平均得到的值,其中权重是各个消息发生的概率。香农信息熵的公式如下:
![]()
其中H表示信息熵,Pi 表示第 i 个消息发生的概率,n 表示消息的总数。
信息量 表示一个事件或消息所包含的 “不确定性”,概率越低,信息量越大;
信息熵 表示一组消息的 “平均不确定性”,概率分布越均匀,信息熵越大。
比如抛硬币:
1)如果正反面概率都是 1/2:
I(正)= -log(1/2) = 1 bit
I(反)= -log(1/2) = 1 bit
H(熵)= 0.5 * 1 + 0.5 * 1 = 1 bit
2)如果正面概率是 9/10,反面概率是 1/10:
I(正)= -log(0.9) = 0.15 bit
I(反)= -log(0.1) = 3.32 bit
H(熵)= 0.9 * 0.15 + 0.1 * 3.32=0.78 bit
有些时候,在战争中 1 比特的信息能抵过千军万马。 在第二次世界大战中,当纳粹德国兵临前苏联莫斯科城下时,斯大林在欧洲已经无兵可派,而他们在西伯利亚的边界却有60万大军不敢使用,因为苏联不知道德国的轴心国盟友日本当时的军事策略是北上进攻苏联,还是南下和美国开战。如果是南下,苏联就可以放心大胆从亚洲撤回60万大军增援莫斯科会战。事实上日本选择了南下,其直接行动就是后来的偷袭珍珠港。但是当时苏联并不知晓,斯大林也不能乱猜,最后是传奇间谍佐尔格向莫斯科发去了信息量仅 1 比特却价值无限的情报:日本将南下。
小白鼠实验
假如实验室里有 1000 只瓶子,其中 999 瓶装了普通的水,有1瓶装了毒药,这瓶毒药无法根据气味或外观分辨出来。如果给小白鼠喝了毒药,一天后它就会死亡。假如你只有一天时间,请问至少需要几只小白鼠,你才能检验出毒药的瓶子?
如果我们有1000只小白鼠,给每只老鼠喝不同瓶中的水,则自然能检测出哪瓶是毒药,但这么做的效率不高。
让我们来换一种思路,看看用信息编码的方式,应该如何考虑这个问题。
让小白鼠喝瓶子中的水,结果只会呈现出2种状态,要么活着、要么死亡。一只小白鼠可以提供的信息量为:
-log(1/2) = 1 bit
要从1000个瓶子中选出一瓶毒药,相当于需要的信息量为:
-log(1/1000) ≈ 9.97 bit
也就是说,我们如果有10只小白鼠,提供 10 bit 的信息,就能找到那瓶毒药。
检测1000个瓶子居然只要10只小白鼠就够了,这不免让人感到惊讶。
具体的操作是这样:
我们先把1000个瓶子用1到1000编号,这个号码是二进制数,也就是说,每个瓶子要用10个0或1的数字表示:
1号瓶是 0000000001
2号瓶是 0000000010
1000号瓶就是 1111101000
再把小白鼠用1到10来编号。现在我们取出一瓶水,查看上面的二进制编号,编号上对应位数是1的,就给相应编号的小白鼠喝下这瓶水。
从第1瓶开始,重复这一动作,直到第1000瓶,如下:
1号瓶的二进制编号是0000000001,只有最后一位是1,就给10号小白鼠喝下瓶中的水。
2号瓶的二进制编号是0000000010,就给9号小白鼠喝水。
1000号瓶的二进制编号是1111101000,就要给1、2、3、4、5、7号小白鼠喝下瓶里的水。
一天以后,我们根据小白鼠的状态获得一个二进制数,0代表生存,1代表死亡。
假设1、5、8、9号小白鼠死了,这个二进制数就是1000100110,换算成十进制是550。
也就是说,第550号瓶中装的是毒药。因此, 10只小白鼠相当于一组编码,它能检测出哪瓶是毒药。
哈夫曼编码
哈夫曼编码是一种用于数据压缩的编码方式:它通过将出现频率较高的字符用较短的编码表示,
而将出现频率较低的字符用较长的编码表示,从而实现对数据进行高效压缩的目的。
如果一本书重复的内容很多,它的信息量就小,冗余度就大,压缩率就高。
假如我们将字符串(15位长度)BCAADDDCCACACAC 通过转换成ASCII码二进制编码进行传输,
那么一个字符传输的二进制位数为 8 bit,那么总共需要 120 个二进制位;
而如果使用哈夫曼编码,该串字符可压缩至 28 位。
具体编码步骤如下:

1)统计字符串中每个字符的频率:

2) 按照字符出现的频率进行排序,组成一个队列:
出现频率最低的在前面,出现频率高的在后面

3)把这些字符作为叶子节点开始构建一颗哈夫曼树:
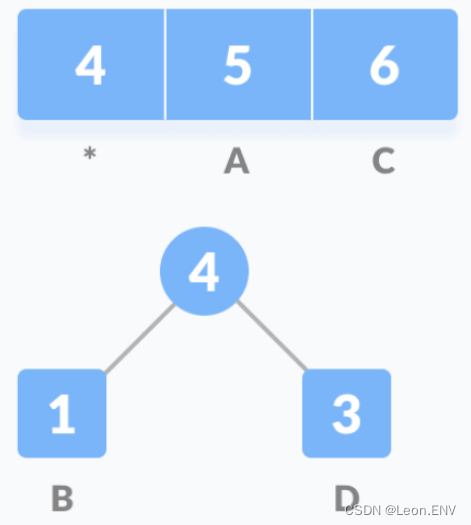
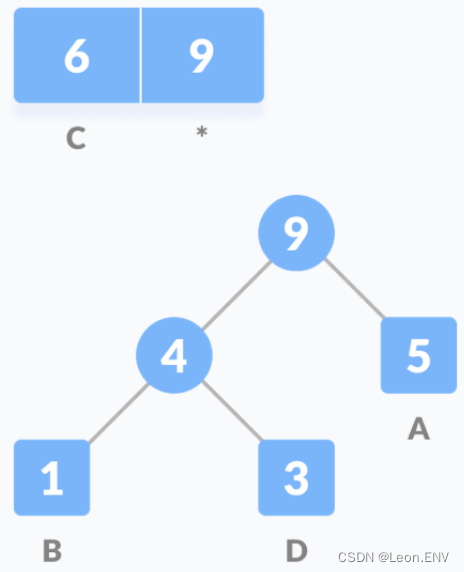
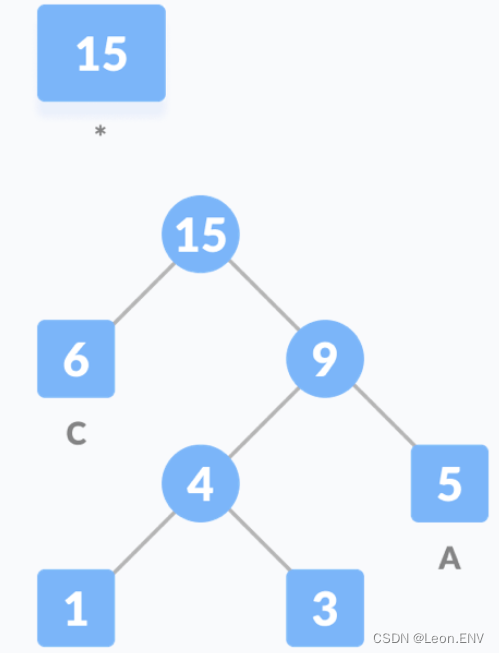
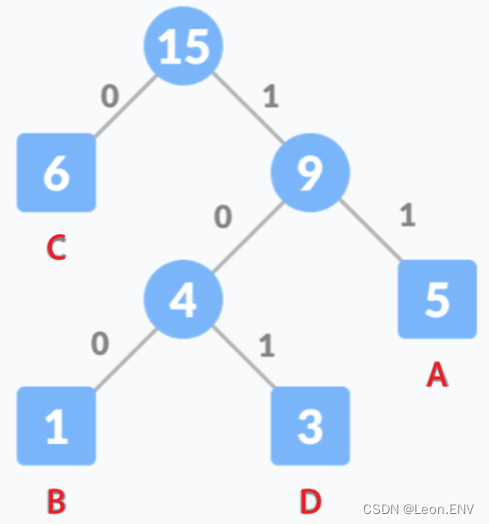
因此各个字母的编码分别为:

在没有经过哈夫曼编码之前,字符串 "BCAADDDCCACACAC" 的二进制为( 也就是占了 120 bit):
10000100100001101000001010000010100010001000100010001000100001101000011010000010100001101000001010000110100000101000011
编码之后为( 占了 28 bit):
1000111110110110100110110110
密码学
在二战中,日本军方的密码设计就有问题,美军破获了日本很多密码。在中途岛海战前,美军截获的日军密电经常出现 AF 这样的一个地名,应该是太平洋的某个岛屿,但是美军无从知道是哪个。于是,美军就逐个发布与自己控制的岛屿有关的假新闻。当发出 “中途岛供水系统坏了” 这条假新闻后,美军从截获的日军情报中又看到含有 AF 的电文(日军情报内容是 AF 供水出了问题),于是断定中途岛就是 AF。事实证明判断是正确的,美军在那里成功地伏击了日本联合舰队。
香农密码学原理是基于信息不确定性和信息熵的理论,用于设计安全的密码系统。
香农密码学原理:
- 信息的不确定性:在密码学中,我们关注的是如何通过加密方法来保护信息的安全性。香农提出了一个重要的概念,即信息的不确定性。不确定性是指在一系列可能性中,我们不知道具体是哪一种情况。例如,如果一个人告诉你他有一辆车,但没有提供任何其他信息,你无法确定他具体拥有哪种类型的车。
- 信息熵:香农引入了信息熵的概念,用来度量信息的不确定性。信息熵越高,表示信息的不确定性越大。例如,一个硬币正反面各有50%的概率,那么猜测硬币正反面的结果就是非常不确定的,信息熵也很高。
- 密码学中的应用:根据香农密码学原理,我们可以利用信息熵来设计安全的密码系统。一个好的密码系统应该具有高的信息熵,即使攻击者知道密码的某些信息,也无法推断出完整的密码。这是因为密码系统中的密钥和算法会增加信息的不确定性,使得攻击者无法轻易猜测出原始信息。
- 密钥长度和安全性:根据香农的理论,密钥的长度与信息的不确定性直接相关。密钥越长,信息熵越高,系统的安全性也就越高。因此,在设计密码系统时,需要选择足够长的密钥长度来保证信息的安全性。
RSA加密
RSA是由三位数学家Rivest、Shamir 和 Adleman 发明的非对称加密算法,这种算法非常可靠,秘钥越长,就越难破解。
目前被破解的最长RSA秘钥是768个二进制位,长度超过768位的秘钥还无法破解,但随着计算能力的增强,以后被破解到多少位还是未知数。就目前而言,1024位的秘钥属于基本安全,2048位的秘钥属于极其安全。一种加密方法只要保证50年内计算机破解不了就算非常安全可靠了。
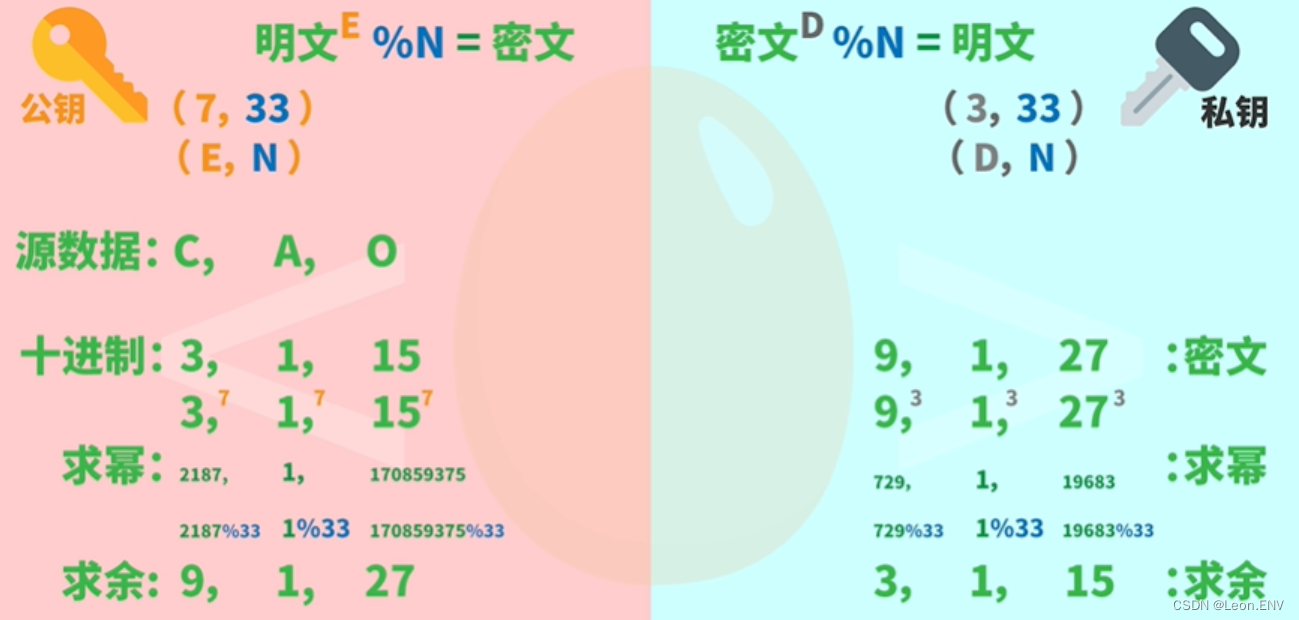
RSA是一种非对称加密算法,加密和解密使用的不是同一把秘钥:公钥加密-私钥解密、私钥加密-公钥解密。
1.公私钥计算逻辑
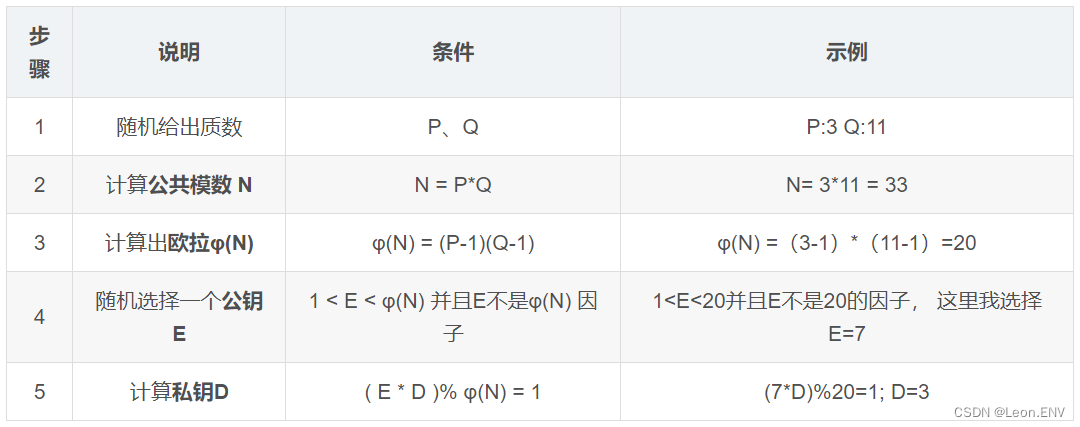
最后得出:
公钥=(E, N) = (7, 33)
私钥=(D, N) = (3, 33)
其中公钥E是对外的,如果要反推私钥D,那就必须要算出欧拉φ(N),
而算出欧拉φ(N)就必须知道P、Q,而如果P、Q设置的比较大,
计算出来的欧拉φ(N)和公共模数 N 都会非常巨大,所以即使公开N也会很难找到P、Q这个两个质数。
RSA主要依赖于两个大质数的乘积难以分解的特性,质数只能被 1 和 自己整除,所以它不能分解为质因子,其它所有整数都可以分解为质因子。质因子分解的过程就是在消除不确定性,这个特性在密码学中很有用,这是因为对非常巨大的数来做质因子分解是非常困难的,用电脑来计算也要用很长的时间。
2.加解密过程
其它应用
决策树: 通过计算每个特征的信息增益,可以确定最能有效地划分数据集的特征,从而生成更准确的决策树模型。
聚类分析:可以使用互信息来评估不同特征或样本之间的相关性,从而更好地组织和理解数据。
很多应用有意或无意中遵循信息论:搜索引擎的提问、chatgpt的提示词 都是在消除不确定性。
参考:
1、《数学之美》、《计算之魂》
2、哈夫曼编码(Huffman Coding)原理详解_chenyfan_的博客-CSDN博客