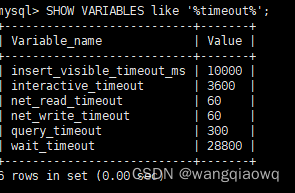
「Python」机器学习之线性判别分析(代码,不调包)
- 前言
- 1 线性判别分析(LDA)
- 2 实现
- 2.1 LDA实现
- 2.2 数据集示例
- 3 最后
前言
- 语言:python
- 库:numpy, matplotlib
- 教材参考:《机器学习》——周志华2016版(“西瓜书”)
- 平台版本:Linux 6.4.7-arch1-3,python10
在学习了机器学习的相关内容后,决定自己尝试实现,并记录下来,便于以后重温和回顾。
由于 python 在数学计算上的优势,所以使用 python以简化相关的数学运算操作,并尽量不采用现有的机器学习库,专注于算法实现。
1 线性判别分析(LDA)
注:内容来自周志华《机器学习》2016版第3章第4节
机器学习(Machine Learning)的任务主要有 拟合和分类 两种,线性判别分析(Linear Discriminant Analysis, LDA)是其中一种比较老的分类算法,示意图如下:
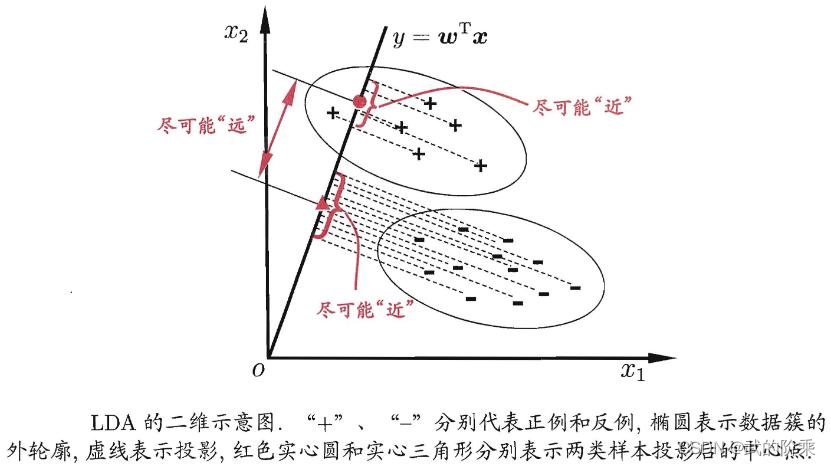
假设,数据集的样本可分为两类,分别用“+”和“-”表示,一个样本的类别由参数
x
1
x_1
x1和
x
2
x_2
x2决定。要将此数据集进行分类,采用LDA算法:
- 在 x 1 x 2 x_1x_2 x1x2平面上画一条直线 ω \omega ω;
- 将数据点投影到直线 ω \omega ω上;
- 找到一条直线 ω \omega ω,令两类数据的投影点中心尽可能远,同类数据的投影点离投影中心尽可能近。
用数学语言描述:
数据集 D = { ( x i , y i ) } i m D = \{(x_i,y_i)\}_i^m D={(xi,yi)}im, y i ∈ { 0 , 1 } y_i \in \{0,1\} yi∈{0,1}, 令 X i , μ i , Σ i X_i, \mu_i, \Sigma_i Xi,μi,Σi分别表示第 i ∈ { 0 , 1 } i \in \{0,1\} i∈{0,1}类示例的集合、均值矩阵、协方差矩阵。
- 将数据集投影到直线 ω \omega ω上;
- 两类样本的中心在直线 ω \omega ω上的投影分别是 ω T μ 0 , ω T μ 1 \omega^T\mu_0, \omega^T\mu_1 ωTμ0,ωTμ1;
- 两类样本的投影协方差分别为 ω T Σ 0 ω , ω T Σ 1 ω \omega^T\Sigma_0\omega, \omega^T\Sigma_1\omega ωTΣ0ω,ωTΣ1ω;
- 要找到直线 ω \omega ω,使得两类的投影中心相距尽可能远 ( ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ||\omega^T\mu_0-\omega^T\mu_1||^2_2 ∣∣ωTμ0−ωTμ1∣∣22 尽可能大),类内的投影点离投影中心尽可能近 ( ω T Σ 0 ω + ω T Σ 1 ω \omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega ωTΣ0ω+ωTΣ1ω 尽可能小)。
- 于是得到欲最大化目标函数: J = ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ω T Σ 0 ω + ω T Σ 1 ω = ω T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T ω ω T ( Σ 0 + Σ 1 ) ω J=\frac{||\omega^T\mu_0-\omega^T\mu_1||^2_2}{\omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega}=\frac{\omega^T(\mu_0-\mu_1)(\mu_0-\mu_1)^T\omega}{\omega^T(\Sigma_0+\Sigma_1)\omega} J=ωTΣ0ω+ωTΣ1ω∣∣ωTμ0−ωTμ1∣∣22=ωT(Σ0+Σ1)ωωT(μ0−μ1)(μ0−μ1)Tω
- 定义“类内散度” S ω = Σ 0 + Σ 1 S_\omega=\Sigma_0+\Sigma_1 Sω=Σ0+Σ1,定义“类间散度” S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b=(\mu_0-\mu_1)(\mu0-\mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T
- 于是得到: J = ω T S b ω ω T S ω ω J=\frac{\omega^TS_b\omega}{\omega^TS_\omega\omega} J=ωTSωωωTSbω
- 由此可采用梯度下降方法训练得出直线斜率 ω \omega ω,除此之外,由于此式有解,可以直接公式求解(拉格朗日乘子法): ω = S ω − 1 ( μ 1 − μ 1 ) \omega=S_\omega^{-1}(\mu_1-\mu_1) ω=Sω−1(μ1−μ1)。
2 实现
能力有限,可能存在错误,谨慎参考。
2.1 LDA实现
# -*- encoding: utf-8 -*-
"""
@File : 机器学习之线性判别分析.py
@Description: 实验线性判别分析,LDA模型
@Author : Daiwu Shen
@Date : 2023-07-10 20:24:22
"""
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
class LinerDiscriminantAnalysis:
def __init__(self, data: np.ndarray, label: np.ndarray) -> None:
self.data = data # 数据
self.label = label # 数据标签(类别)
self.class_num = np.unique(self.label).size # 类型数
self.omega = np.ones((self.data.shape[1])) # 斜率
self.classify_data = [] # 不同类别的数据
self.dataClassify()# 进行数据分类
self.project_means = np.zeros(self.class_num) # 各类别的数据均值
self.means = np.array([[np.mean(self.classify_data[j][:, i]) for i in range(self.classify_data[j].shape[1])] for j in range(len(self.classify_data))]) #
self.cov = np.array([np.cov(self.classify_data[i], rowvar=False) for i in range(len(self.classify_data))])
self.Sw = self.cov[0]
for i in range(1, self.cov.shape[0]):
self.Sw += self.cov[i]
self.Sb = np.zeros((self.means.shape[1], self.means.shape[1]))
for i in range(self.means.shape[0]):
for j in range(self.means.shape[0]):
delta = np.array([self.means[i]-self.means[j]])
self.Sb += np.dot(delta.T, delta)
self.j = [np.dot(np.dot(self.omega, self.Sb), self.omega.T) / np.dot(np.dot(self.omega, self.Sw), self.omega.T)]
def dataClassify(self):
""" 对数据分为两类 """
for _ in range(self.class_num):
self.classify_data.append(np.empty((0, self.data.shape[1])))
for index in range(self.label.size):
self.classify_data[self.label[index][0]] = np.append(self.classify_data[self.label[index][0]], [self.data[index]], axis=0)
def train(self, alpha: float = 0.01, num_iterator: int = 500):
""" 开始训练 """
for i in range(num_iterator):
self.omega += self.objectiveFunc(alpha=alpha)
if i % 100 == 0:
print(self.J(), self.omega)
for i in range(len(self.project_means)):
self.project_means[i] = np.mean(self.omega.dot(self.classify_data[i].T))
def objectiveFunc(self, alpha: float):
""" 更新目标函数 """
gredient = np.zeros(self.data.shape[1])
for i in range(self.data.shape[1]):
# 先算一边没有增加的损失函数
j1 = self.J()
# 然后增加omega
self.omega[i] += alpha
# 通过增加后的omega计算一边损失函数
j2 = self.J()
# 给omega还原
self.omega[i] -= alpha
# 如果omega增加后损失函数变大则增大(通过alpha改变增大的幅度)
gredient[i] = (j2-j1)/alpha
return gredient
def J(self):
"""损失函数"""
molecular = self.omega.dot(self.Sb).dot(self.omega.T)
denominator = self.omega.dot(self.Sw).dot(self.omega.T)
j = molecular/denominator
self.j.append(j)
return j
def predict(self, x: np.ndarray):
""" 预测 """
result = []
flag = True
print(self.project_means)
for i in range(len(x)):
project = self.omega.dot(x[i])
for j in range(1, len(self.project_means)):
if project < (self.project_means[j-1]+self.project_means[j])/2:
result.append(j-1)
flag = False
break
if flag:
result.append(self.project_means.size-1)
flag = True
return result
def correctRate(self, label1: np.ndarray, label2: np.ndarray):
""" 准确率 """
count = 0
for i in range(len(label1)):
if label1[i] == label2[i]:
count += 1
return count/len(label1)
def Lagrange(self):
""" 拉格朗日乘子法,可直接求解omega """
""" 奇异值分解法求逆矩阵(优点:稳定) """
u, sigma, v = np.linalg.svd(self.Sw, full_matrices=False)
sw_I = np.matmul(v.T/sigma, u.T)
""" 直接求逆矩阵 """
# sw_I = np.linalg.inv(self.Sw)
""" 拉格朗日乘子法:w=Sw_I (mean[0]-mean[1]) """
""" 求均值的两两差值 """
means = np.zeros(self.means.shape[1])
for i in range(self.means.shape[0]):
means += self.means[i]-self.means[0]
self.omega = sw_I.dot(means)
for i in range(len(self.project_means)):
self.project_means[i] = np.mean(self.omega.dot(self.classify_data[i].T))
2.2 数据集示例
由于 Iris 数据集的标签是 Iris 的种类名称,为方便计算机训练,需要将字符串的种类名称数值化:
def Classify2Number(data: np.ndarray, className: list = []):
""" 将数据集的标签进行数值化(如用0表示A类数据,1表示B类数据) """
result = np.empty((0, 1), int)
for item in data:
for i in range(len(className)):
if item[0] in className[i]:
result = np.append(result, [[i]], axis=0)
return result
根据LDA的原理,可以知道LDA是可以直接实现简单的多分类的,但是当数据变复杂后效果较差。由于 Iris 数据集有3个种类,数据简单,可以实现三分类。
if __name__ == "__main__":
data = pd.read_csv("数据集文件路径", header=None) # 读取数据集,无表头则header=None,有标头省略
data.columns = ["sepal-l", "sepal-w", "petal-l", "petal-w", "class"] # 这里的Iris数据集文件无表头,在这里添加表头
test = data.sample(frac=0.2) # 分出测试集和训练集
train = data.drop(test.index)
# 初始化LDA对象
LDA = LinerDiscriminantAnalysis(
train[["sepal-l", "sepal-w", "petal-l", "petal-w"]].values,
Classify2Number(train[["class"]].values, ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]))
# 二分类改为如下(将setosa作为一类,将versicolor和virginica共同作为一类)
# LDA = LinerDiscriminantAnalysis(
# train[["sepal-l", "sepal-w", "petal-l", "petal-w"]].values,
# Classify2Number(train[["class"]].values, ["Iris-setosa", ["Iris-versicolor", "Iris-virginica"]]))
""" 梯度下降训练 """
LDA.train(alpha=0.001)
""" 拉格朗日乘子法直接求解 """
# LDA.Lagrange()
print(LDA.omega)
""" 绘制损失函数 """
plt.plot(range(len(LDA.j)), LDA.j)
plt.show()
""" 测试,并打印准确率 """
print(LDA.correctRate(
LDA.predict(test[["sepal-l", "sepal-w", "petal-l", "petal-w"]].values),
Classify2Number(test[["class"]].values, ["Iris-setosa", "Iris-versicolor", "Iris-virginica"])[:, 0]))
3 最后
- 在训练前应对数据进行应有的初始化处理,如归一化、标准化等,由于 Iris 数据集数据量小,且数据规范,这里没有对数据进行处理。
- 在进行二分类时,将setosa作为一类,将versicolor和virginica共同作为一类。这也是做普遍多分类的一种方法:一对其余(OvR),对N个类的数据集,每次将一个类的样例作为正例、所有其他类的样例作为反例来训练 N 个分类器,在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果。见周志华《机器学习》2016版第3章第5节