数据工厂
一、背景
在开发自测、测试迭代测试、产品验收的过程中,都需要各种各样的前置数据,大致分为如下几类:
账号(实名、权益等级、注册等)
货源(优货、急走、相似、一手、普通货源等)
订单(各种状态订单)
查询类操作(验证码等)
UI自动化、接口自动化的过程中也需要上述数据,例如车的UI测试依赖货源信息,需要解耦。
二、目标
整体目标
总体目标:
为了更好的支撑公司实现业务目标,满足需求高质量快速迭代上线,逐步将搭建数据工厂体系。
阶段性目标
第一阶段:技术选型。
第二阶段:框架搭建。
第三阶段:实现账号、货源、订单、查询类操作等高优先级功能,并推广至测试团队。
第四阶段:不断收集需求,完善新功能,并改善原有框架趋于成熟,推广至产研及产品团队,继续迭代。
三、方案对比
由于数据工厂的高度定制化要求,与业务强关联,市面上开源的数据工厂很少,而收费的往往是“数字工厂(数据挖掘与清洗)”而非数据工厂,可供对比样本非常少。
| 方案 | 接口验签 | 参数自定义方式 | 调用方式 | 购买成本 | 灵活度 | 二次开发 | 二次开发成本 | 框架搭建成本 | 技术栈 | 社区 |
|---|---|---|---|---|---|---|---|---|---|---|
| 自研数据工厂 | 支持 | 下拉框及输入框 | 前端or接口 | 免费 | 高 | 支持 | 低 | 高 | java+vue | 无 |
| 开源项目FunLine | 不支持 | json(不直观、使用学习成本高) | 前端or接口(接口有验签,不方便赋能Metersphere及UI自动化) | 免费 | 低 | 支持 | 中等 | 低 | python+vue | 无 |
四、半年收益推演
以下数据均来自数据库(test、release、dev)中近半年数据,截至日为2023.08.09 15:00,查询SQL如下
select count(*) from *** where create_time> '2023-02-09 00:00:00';
select count(*) from *** where ctime > '2023-02-09 00:00:00' ;
select count(*) from *** where ctime > '2023-02-09 00:00:00';
select count(*) from *** where create_time > '2023-02-09 00:00:00';
select count(*) from *** where ctime > '2023-02-09 00:00:00';
select count(*) from *** where create_time > '2023-02-09 00:00:00' ;
| 业务项 | 近半年频次 | 手动平均每次耗时 | 数据工厂平均每次耗时 | 单次节省时间 | 半年总共节省时间 |
|---|---|---|---|---|---|
| 发布货源 | 8336 | 30s | 5s | 25s | 58h |
| 订单 | 2880 | 90s | 5s | 85s | 68h |
| 短信查询 | 3884 | 30s | 5s | 25s | 27h |
| 新建账户 | 691 | 60s | 5s | 55s | 11h |
| xxx | 352 | 60s | 5s | 55s | 5h |
| 实名认证 | 338 | 60s | 5s | 55s | 5h |
| 总计 | 174h |
五、年度时间明细
| 年度 | 节省时间 | 代码编写工时 | 节省 |
|---|---|---|---|
| 第一年 | 348h(174h*2) | 240h | 108h |
| 第二年 | 348h(174h*2) | 80h | 268h |
| 第三年 | 348h(174h*2) | 80h | 268h |
六、结论
相对于开源框架,自研灵活度更高,更契合公司业务;所在,以自研为基础搭建数据工厂框架,后续再填充业务功能,对比其他方案是我们目前的最佳方案
七、框架结构

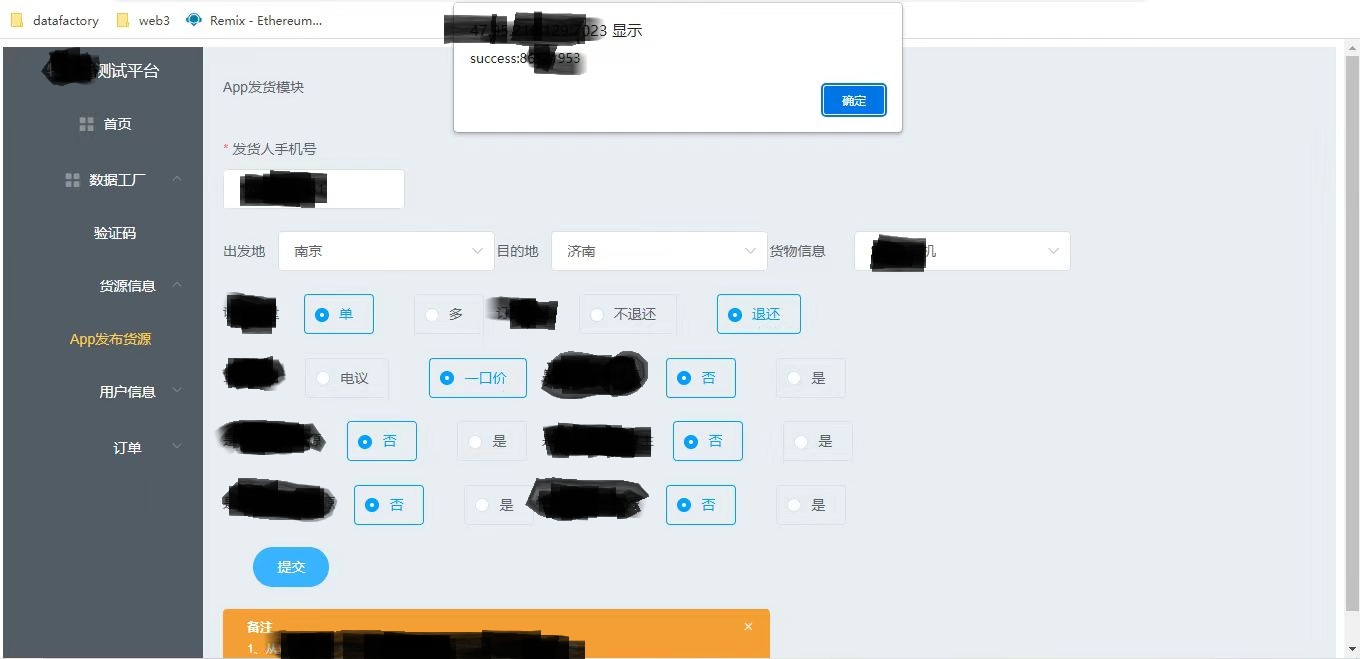
结果展示










![[数据库]MYSQL之授予/查验binlog权限](https://img-blog.csdnimg.cn/img_convert/879a8f61c15562010bc10390fc560b0d.png)