简介:
Transcribe and translate audio offline on your personal computer. Powered by OpenAI’s Whisper.
转录和翻译音频离线在您的个人计算机。由OpenAI的Whisper提供动力。
可以简单理解为QT的前端界面,python语言构建服务端,使用Whisper语言模型进行计算语音转文字的软件。
痛点在于离线,缺点也很明显,模型较大,高质量模型运算依赖于硬件和算法优化
应用场景
学习,歌曲提取歌词,视频提取字幕,多媒体信息前置数据提取
软件下载
从github上进行下载,下载地址https://github.com/chidiwilliams/buzz
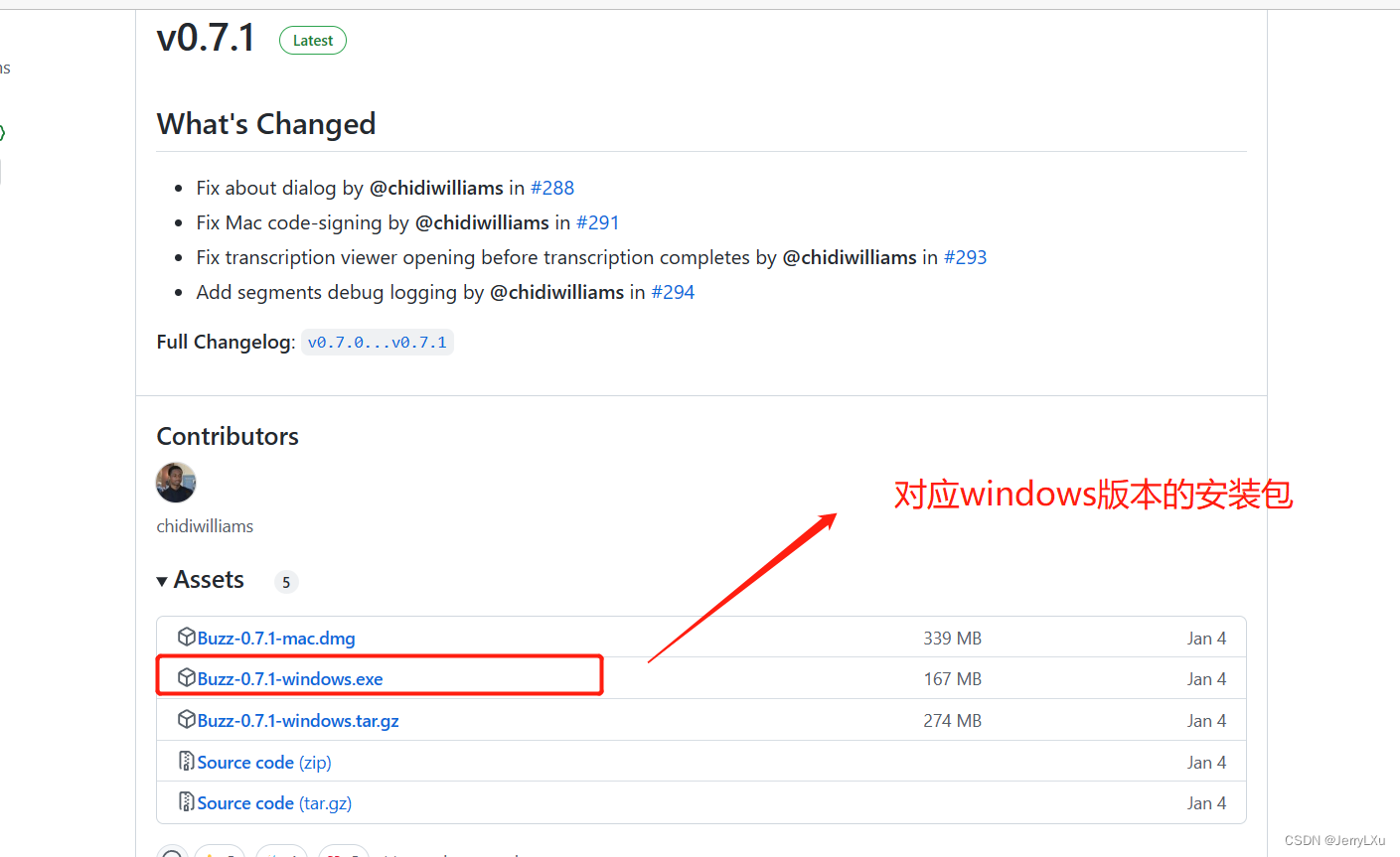
百度云盘离线下载 https://pan.baidu.com/s/1O8VxDW8Fx1yTB000u5WqJA?pwd=b67d
软件安装
windows软件安装的常规流程,双击exe,选择安装路径,进行安装
软件使用
首先双击Buzz.exe,然后打开音频文件
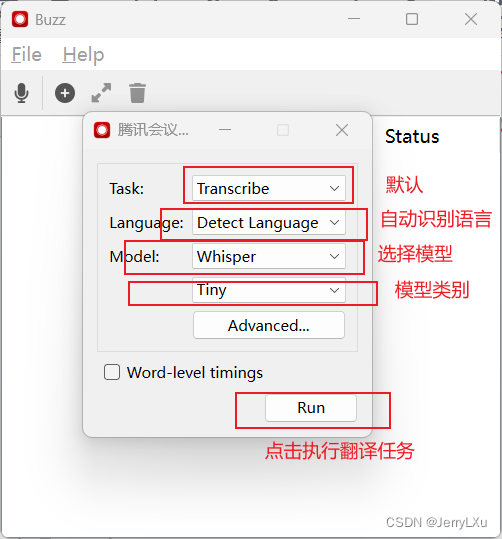
第一执行翻译任务会在用户安装目录下载模型,如果是下载时间过长,Windows版本下载路径为:C:\Users<username>\AppData\Local\Buzz\Buzz\Cache ,表示用户目录,大概率会失败报错,这里可以使用离线的模型包
模型离线下载
百度云盘离线下载 https://pan.baidu.com/s/1O8VxDW8Fx1yTB000u5WqJA?pwd=b67d
下载完成后有五个类别的模型,大小和名字一样,越大效果越强,当然也取决于硬件,运算量越大,耗时越长
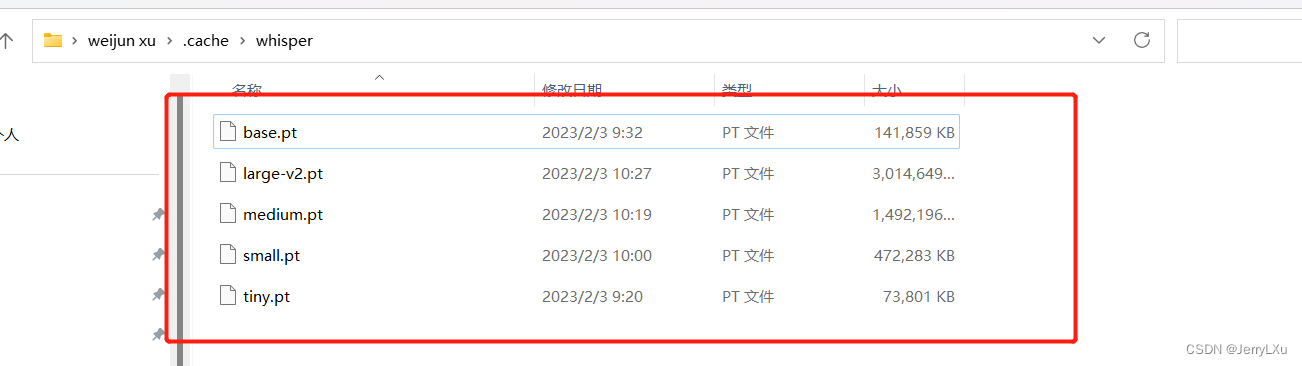
复制解压出来的模型,复制和替换C:\Users<username>\AppData\Local\Buzz\Buzz\Cache 下的模型
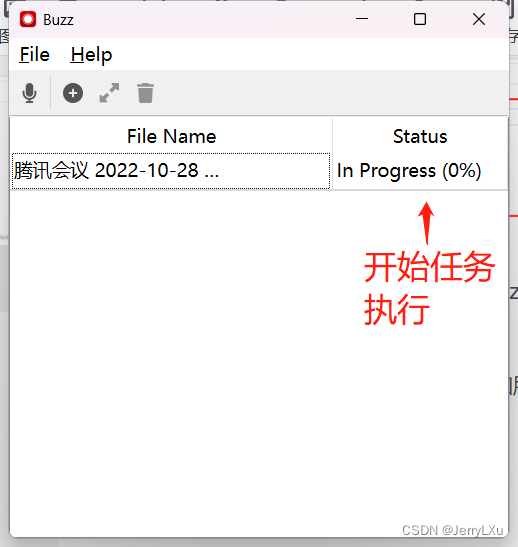
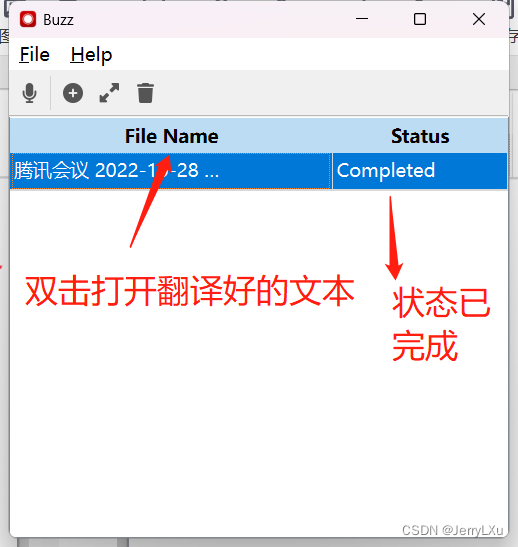
开始进行任务翻译任务处理
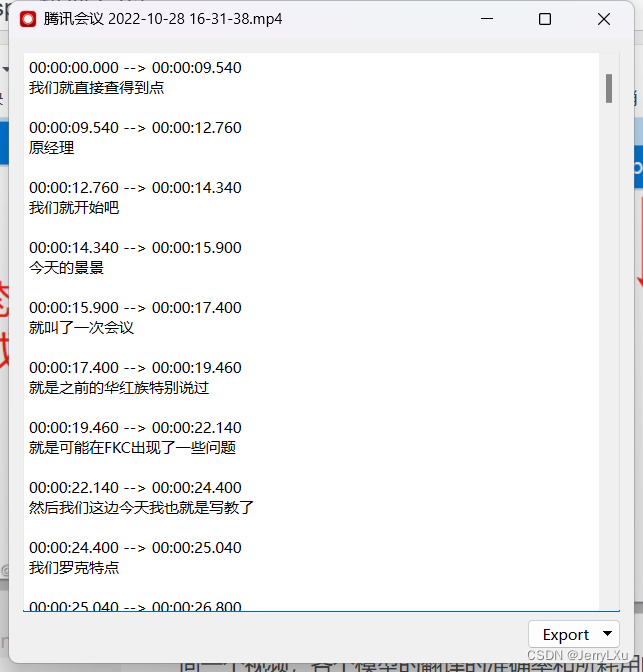
准确率和效率
上面视频用的Tiny模型,这个模型很小,所以翻译效果一般,但是用时也很短
实测使用Large(体积最大)模型翻译最准确,但是对硬件的图形运算能力要求很高,花费时间也最长
日志和耗时信息
Tiny 模型耗时
whisper process completed with code = 0, time taken = 0:01:24.168368, number of segments = 155
Large 模型耗时
whisper process completed with code = 0, time taken = 0:20:40.773737, number of segments = 214

![[论文分享]Pedestrian attribute recognition based on attribute correlation](https://img-blog.csdnimg.cn/66748dba526c4dd0aefd7ce8f1c090bd.png)