SparkSQL 定义UDF函数

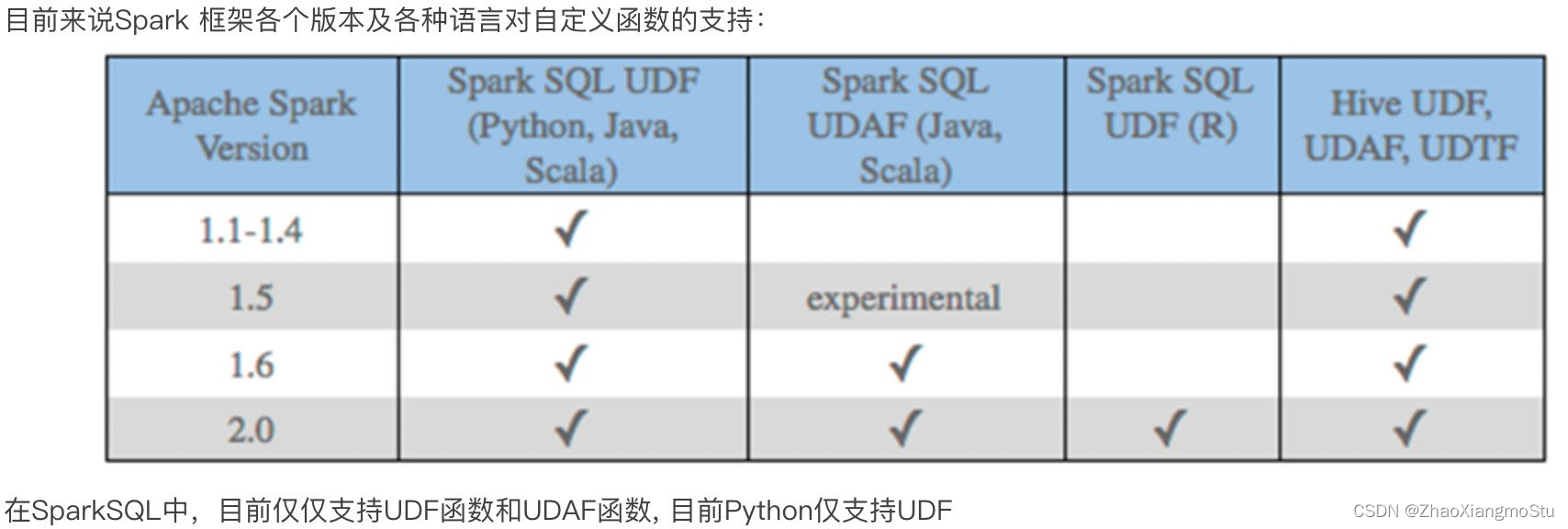
方式1语法:
udf对象 = sparksession.udf.register(参数1,参数2,参数3)
参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
方式2语法:
udf对象 = F.udf(参数1, 参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
其中F是:
from pyspark.sql import functions as F
其中,被注册成UDF的方法名是指具体的计算方法,如:
def add(x, y): x + y
add就是将要被注册成UDF的方法名

# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
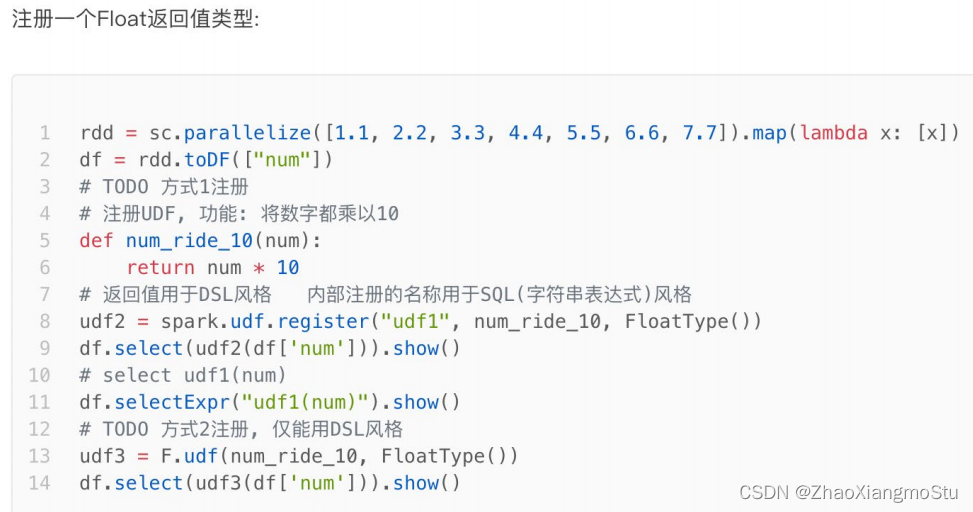
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x:[x])
df = rdd.toDF(["num"])
# TODO 1: 方式1 sparksession.udf.register(), DSL和SQL风格均可以使用
# UDF的处理函数
def num_ride_10(num):
return num * 10
# 参数1: 注册的UDF的名称, 这个udf名称, 仅可以用于 SQL风格
# 参数2: UDF的处理逻辑, 是一个单独的方法
# 参数3: 声明UDF的返回值类型, 注意: UDF注册时候, 必须声明返回值类型, 并且UDF的真实返回值一定要和声明的返回值一致
# 返回值对象: 这是一个UDF对象, 仅可以用于 DSL 语法
# 当前这种方式定义的UDF, 可以通过参数1的名称用于SQL风格, 通过返回值对象用户DSL风格
udf2 = spark.udf.register("udf1", num_ride_10, IntegerType())
# SQL风格中使用
# selectExpr 以SELECT的表达式执行, 表达式 SQL风格的表达式(字符串)
# select方法, 接受普通的字符串字段名, 或者返回值是Column对象的计算
df.selectExpr("udf1(num)").show()
# DSL 风格中使用
# 返回值UDF对象 如果作为方法使用, 传入的参数 一定是Column对象
df.select(udf2(df['num'])).show()
# TODO 2: 方式2注册, 仅能用于DSL风格
udf3 = F.udf(num_ride_10, IntegerType())
df.select(udf3(df['num'])).show()
df.selectExpr("udf3(num)").show()

# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([["hadoop spark flink"], ["hadoop flink java"]])
df = rdd.toDF(["line"])
# 注册UDF, UDF的执行函数定义
def split_line(data):
return data.split(" ") # 返回值是一个Array对象
# TODO1 方式1 构建UDF
udf2 = spark.udf.register("udf1", split_line, ArrayType(StringType()))
# DLS风格
df.select(udf2(df['line'])).show()
# SQL风格
df.createTempView("lines")
spark.sql("SELECT udf1(line) FROM lines").show(truncate=False)
# TODO 2 方式2的形式构建UDF
udf3 = F.udf(split_line, ArrayType(StringType()))
df.select(udf3(df['line'])).show(truncate=False)


# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 假设 有三个数字 1 2 3 我们传入数字 ,返回数字所在序号对应的 字母 然后和数字结合形成dict返回
# 比如传入1 我们返回 {"num":1, "letters": "a"}
rdd = sc.parallelize([[1], [2], [3]])
df = rdd.toDF(["num"])
# 注册UDF
def process(data):
return {"num": data, "letters": string.ascii_letters[data]}
"""
UDF的返回值是字典的话, 需要用StructType来接收
"""
udf1 = spark.udf.register("udf1", process, StructType().add("num", IntegerType(), nullable=True).\
add("letters", StringType(), nullable=True))
df.selectExpr("udf1(num)").show(truncate=False)
df.select(udf1(df['num'])).show(truncate=False)


SparkSQL 使用窗口函数


# coding:utf8
# 演示sparksql 窗口函数(开窗函数)
import string
from pyspark.sql import SparkSession
# 导入StructType对象
from pyspark.sql.types import ArrayType, StringType, StructType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder. \
appName("create df"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", "2"). \
getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([
('张三', 'class_1', 99),
('王五', 'class_2', 35),
('王三', 'class_3', 57),
('王久', 'class_4', 12),
('王丽', 'class_5', 99),
('王娟', 'class_1', 90),
('王军', 'class_2', 91),
('王俊', 'class_3', 33),
('王君', 'class_4', 55),
('王珺', 'class_5', 66),
('郑颖', 'class_1', 11),
('郑辉', 'class_2', 33),
('张丽', 'class_3', 36),
('张张', 'class_4', 79),
('黄凯', 'class_5', 90),
('黄开', 'class_1', 90),
('黄恺', 'class_2', 90),
('王凯', 'class_3', 11),
('王凯杰', 'class_1', 11),
('王开杰', 'class_2', 3),
('王景亮', 'class_3', 99)
])
schema = StructType().add("name", StringType()). \
add("class", StringType()). \
add("score", IntegerType())
df = rdd.toDF(schema)
# 窗口函数只用于SQL风格, 所以注册表先
df.createTempView("stu")
# TODO 聚合窗口
spark.sql("""
SELECT *, AVG(score) OVER() AS avg_score FROM stu
""").show()
# SELECT *, AVG(score) OVER() AS avg_score FROM stu 等同于
# SELECT * FROM stu
# SELECT AVG(score) FROM stu
# 两个SQL的结果集进行整合而来
spark.sql("""
SELECT *, AVG(score) OVER(PARTITION BY class) AS avg_score FROM stu
""").show()
# SELECT *, AVG(score) OVER(PARTITION BY class) AS avg_score FROM stu 等同于
# SELECT * FROM stu
# SELECT AVG(score) FROM stu GROUP BY class
# 两个SQL的结果集进行整合而来
# TODO 排序窗口
spark.sql("""
SELECT *, ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,
RANK() OVER(ORDER BY score) AS rank
FROM stu
""").show()
# TODO NTILE
spark.sql("""
SELECT *, NTILE(6) OVER(ORDER BY score DESC) FROM stu
""").show()SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
UDF定义支持2种方式, 1:使用SparkSession对象构建. 2: 使用functions包中提供的UDF API构建. 要注意, 方式1可用DSL和SQL风格, 方式2 仅可用于DSL风格
SparkSQL支持窗口函数使用, 常用SQL中的窗口函数均支持, 如聚合窗口\排序窗口\NTILE分组窗口等