流程简介
- 主要包含模型预训练和指令微调两个阶段
- 模型预训练:搜集海量的文本数据,无监督的训练自回归decoder;
O T = P ( O t < T ) O_T=P(O_{t<T}) OT=P(Ot<T),损失函数CE loss - 指令微调:在输入文本中加入任务提示,
- 输入 “翻译文本为英文:无监督训练。译文:”,让模型输出 “Non-supervised”
- 也是一个自回归训练的过程,损失函数和预训练一样,但是输入数据是有范式的。
- 模型预训练:搜集海量的文本数据,无监督的训练自回归decoder;
指令微调
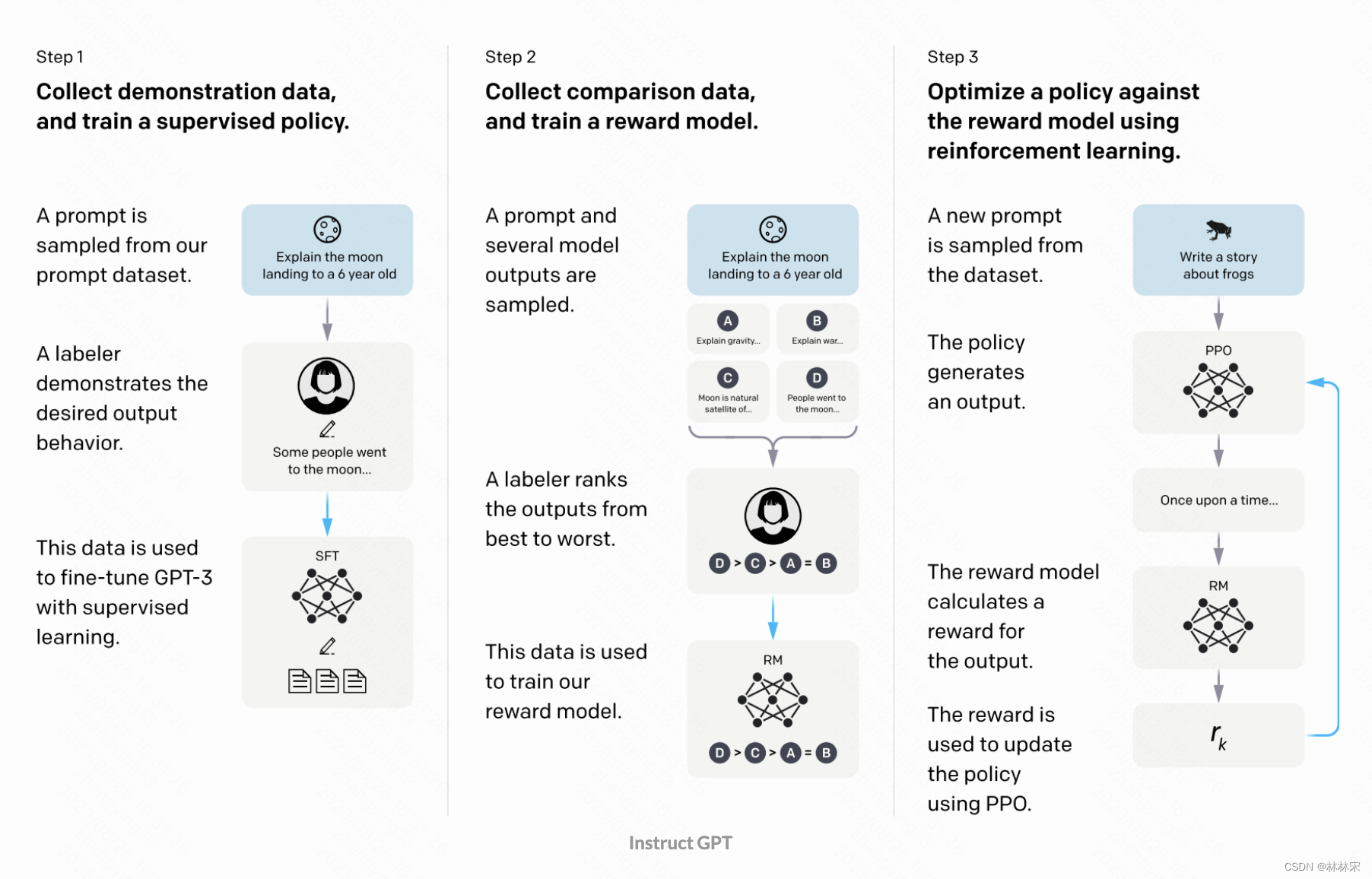
- 指令微调一般分成三个阶段
- 从用户那里收集到大量的问题,邀请专业的人士给出高质量的答案 ,然后用这些数据fine-tune生成模型;
- 让训练过的生成模型基于用户问题给出多次答案,并邀请真人对答案的质量进行打分,这些打分的数据用户训练reward model;
- 生成模型+reward model串起来,就可以自己生成答案,自己评价结果的好坏,不断进行优化。
参考博客
brightliao-ChatGPT 的模型训练