1. ArrayList源码剖析
1.1 ArrayList底层原理
- 利用空参创建的集合,在底层创建一个默认长度为0的数组名字为elementData,且还有一个底层变量size,用来记录元素的个数。
- 添加第一个元素时,底层会创建一个新的长度为10的数组,默认初始化值为空。所以我们一般会认为ArrayList的底层的数组默认长度是10。
- 底层的size这个变量有两层含义,第一层含义表示的是现在元素的个数,也就是集合的长度,第二个表示下次存入位置,每次存入数据时size都会加加。
- 当集合原始数组存满,并且还要继续添加时,数组会自动扩容1.5倍,此时size为15。如果又满了还会继续扩容为当前长度的1.5倍。
- 如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
1.2 ArrayList源码剖析
当用空参构造创建ArrayList集合的时候,ArrayList在底层创建了一个长度为零的数组
/**
* 当用空参构造创建ArrayList集合的时候,ArrayList在底层创建了一个长度为零的数组
*/
List<String> list = new ArrayList<>();
例如下面源码分析,在ArrayList中粘贴出来了一些易于自己明白的源码
transient Object[] elementData;//集合底层的数组名
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
//ArrayList空参构造
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
//这个就相当于,Object[] elementData = {};也是相当于创建了一个长度为零的数组的意思
}
当调用list.add()添加第一个元素的时候,ArrayList在底层创建了一个新的,长度为十的数组
里面默认初始化值都是null
/**
* 当用空参构造创建ArrayList集合的时候,ArrayList在底层创建了一个长度为零的数组
*/
List<String> list = new ArrayList<>();
//当调用list.add()添加第一个元素的时候,ArrayList在底层创建了一个新的,长度为十的数组
list.add("nnn");
下面源码步骤分析
transient Object[] elementData;//集合底层的数组名
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private int size;//集合中元素个数,集合长度
private static final int DEFAULT_CAPACITY = 10;//默认初始容量
protected transient int modCount = 0;//记录的是list集合被修改的次数,例如每调用一次add方法,就会加一
public ArrayList() {//ArrayList空参构造
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
//这个就相当于,Object[] elementData = {};创建了一个长度为零的数组
}
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {//minCapacity为1
//这个minCapacity就是上面传下来的size,为1
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// Object[] elementData ={};
// private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//private static final int DEFAULT_CAPACITY = 10; int minCapacity = 1;
return Math.max(DEFAULT_CAPACITY, minCapacity);//俩者之间取最大值,返回10
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {//int minCapacity = 10;
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {//minCapacity=10
// overflow-conscious code
int oldCapacity = elementData.length;//旧容量,0;
int newCapacity = oldCapacity + (oldCapacity >> 1);//这个>>相当于oldCapacity *1.5
if (newCapacity - minCapacity < 0){
newCapacity = minCapacity;
}
if (newCapacity - MAX_ARRAY_SIZE > 0){
newCapacity = hugeCapacity(minCapacity);
}
// minCapacity is usually close to size, so this is a win:
//创建一个新的长度为10的数组,把原来的元素拷贝进去
elementData = Arrays.copyOf(elementData, newCapacity);{},10
}
1.3 ArrayList扩容机制
扩容规则
-
ArrayList()会使用长度为零的数组 -
ArrayList(int initialCapacity)会使用指定容量的数组 -
public ArrayList(Collection<? extends E> c)会使用 c 的大小作为数组容量 -
add(Object o)首次扩容为 10,再次扩容为上次容量的 1.5 倍 -
addAll(Collection c)没有元素时,扩容为 Math.max(10, 实际元素个数),有元素时为 Math.max(原容量 1.5 倍, 实际元素个数)
2. LinkedList源码剖析
2.1 LinkedList简介
LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当作链表来操作外,它还可以当作栈,队列和双端队列来使用。
LinkedList同样是非线程安全的,只在单线程下适合使用。
LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
2.2 LinkedList源码剖析
LinkedList的源码如下(加入了比较详细的注释)
package java.util;
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 链表的表头,表头不包含任何数据。Entry是个链表类数据结构。
private transient Entry<E> header = new Entry<E>(null, null, null);
// LinkedList中元素个数
private transient int size = 0;
// 默认构造函数:创建一个空的链表
public LinkedList() {
header.next = header.previous = header;
}
// 包含“集合”的构造函数:创建一个包含“集合”的LinkedList
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
// 获取LinkedList的第一个元素
public E getFirst() {
if (size==0)
throw new NoSuchElementException();
// 链表的表头header中不包含数据。
// 这里返回header所指下一个节点所包含的数据。
return header.next.element;
}
// 获取LinkedList的最后一个元素
public E getLast() {
if (size==0)
throw new NoSuchElementException();
// 由于LinkedList是双向链表;而表头header不包含数据。
// 因而,这里返回表头header的前一个节点所包含的数据。
return header.previous.element;
}
// 删除LinkedList的第一个元素
public E removeFirst() {
return remove(header.next);
}
// 删除LinkedList的最后一个元素
public E removeLast() {
return remove(header.previous);
}
// 将元素添加到LinkedList的起始位置
public void addFirst(E e) {
addBefore(e, header.next);
}
// 将元素添加到LinkedList的结束位置
public void addLast(E e) {
addBefore(e, header);
}
// 判断LinkedList是否包含元素(o)
public boolean contains(Object o) {
return indexOf(o) != -1;
}
// 返回LinkedList的大小
public int size() {
return size;
}
// 将元素(E)添加到LinkedList中
public boolean add(E e) {
// 将节点(节点数据是e)添加到表头(header)之前。
// 即,将节点添加到双向链表的末端。
addBefore(e, header);
return true;
}
// 从LinkedList中删除元素(o)
// 从链表开始查找,如存在元素(o)则删除该元素并返回true;
// 否则,返回false。
public boolean remove(Object o) {
if (o==null) {
// 若o为null的删除情况
for (Entry<E> e = header.next; e != header; e = e.next) {
if (e.element==null) {
remove(e);
return true;
}
}
} else {
// 若o不为null的删除情况
for (Entry<E> e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
}
// 将“集合(c)”添加到LinkedList中。
// 实际上,是从双向链表的末尾开始,将“集合(c)”添加到双向链表中。
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 从双向链表的index开始,将“集合(c)”添加到双向链表中。
public boolean addAll(int index, Collection<? extends E> c) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Object[] a = c.toArray();
// 获取集合的长度
int numNew = a.length;
if (numNew==0)
return false;
modCount++;
// 设置“当前要插入节点的后一个节点”
Entry<E> successor = (index==size ? header : entry(index));
// 设置“当前要插入节点的前一个节点”
Entry<E> predecessor = successor.previous;
// 将集合(c)全部插入双向链表中
for (int i=0; i<numNew; i++) {
Entry<E> e = new Entry<E>((E)a[i], successor, predecessor);
predecessor.next = e;
predecessor = e;
}
successor.previous = predecessor;
// 调整LinkedList的实际大小
size += numNew;
return true;
}
// 清空双向链表
public void clear() {
Entry<E> e = header.next;
// 从表头开始,逐个向后遍历;对遍历到的节点执行一下操作:
// (01) 设置前一个节点为null
// (02) 设置当前节点的内容为null
// (03) 设置后一个节点为“新的当前节点”
while (e != header) {
Entry<E> next = e.next;
e.next = e.previous = null;
e.element = null;
e = next;
}
header.next = header.previous = header;
// 设置大小为0
size = 0;
modCount++;
}
// 返回LinkedList指定位置的元素
public E get(int index) {
return entry(index).element;
}
// 设置index位置对应的节点的值为element
public E set(int index, E element) {
Entry<E> e = entry(index);
E oldVal = e.element;
e.element = element;
return oldVal;
}
// 在index前添加节点,且节点的值为element
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
// 删除index位置的节点
public E remove(int index) {
return remove(entry(index));
}
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前先后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
// 从前向后查找,返回“值为对象(o)的节点对应的索引”
// 不存在就返回-1
public int indexOf(Object o) {
int index = 0;
if (o==null) {
for (Entry e = header.next; e != header; e = e.next) {
if (e.element==null)
return index;
index++;
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element))
return index;
index++;
}
}
return -1;
}
// 从后向前查找,返回“值为对象(o)的节点对应的索引”
// 不存在就返回-1
public int lastIndexOf(Object o) {
int index = size;
if (o==null) {
for (Entry e = header.previous; e != header; e = e.previous) {
index--;
if (e.element==null)
return index;
}
} else {
for (Entry e = header.previous; e != header; e = e.previous) {
index--;
if (o.equals(e.element))
return index;
}
}
return -1;
}
// 返回第一个节点
// 若LinkedList的大小为0,则返回null
public E peek() {
if (size==0)
return null;
return getFirst();
}
// 返回第一个节点
// 若LinkedList的大小为0,则抛出异常
public E element() {
return getFirst();
}
// 删除并返回第一个节点
// 若LinkedList的大小为0,则返回null
public E poll() {
if (size==0)
return null;
return removeFirst();
}
// 将e添加双向链表末尾
public boolean offer(E e) {
return add(e);
}
// 将e添加双向链表开头
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
// 将e添加双向链表末尾
public boolean offerLast(E e) {
addLast(e);
return true;
}
// 返回第一个节点
// 若LinkedList的大小为0,则返回null
public E peekFirst() {
if (size==0)
return null;
return getFirst();
}
// 返回最后一个节点
// 若LinkedList的大小为0,则返回null
public E peekLast() {
if (size==0)
return null;
return getLast();
}
// 删除并返回第一个节点
// 若LinkedList的大小为0,则返回null
public E pollFirst() {
if (size==0)
return null;
return removeFirst();
}
// 删除并返回最后一个节点
// 若LinkedList的大小为0,则返回null
public E pollLast() {
if (size==0)
return null;
return removeLast();
}
// 将e插入到双向链表开头
public void push(E e) {
addFirst(e);
}
// 删除并返回第一个节点
public E pop() {
return removeFirst();
}
// 从LinkedList开始向后查找,删除第一个值为元素(o)的节点
// 从链表开始查找,如存在节点的值为元素(o)的节点,则删除该节点
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
// 从LinkedList末尾向前查找,删除第一个值为元素(o)的节点
// 从链表开始查找,如存在节点的值为元素(o)的节点,则删除该节点
public boolean removeLastOccurrence(Object o) {
if (o==null) {
for (Entry<E> e = header.previous; e != header; e = e.previous) {
if (e.element==null) {
remove(e);
return true;
}
}
} else {
for (Entry<E> e = header.previous; e != header; e = e.previous) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
}
// 返回“index到末尾的全部节点”对应的ListIterator对象(List迭代器)
public ListIterator<E> listIterator(int index) {
return new ListItr(index);
}
// List迭代器
private class ListItr implements ListIterator<E> {
// 上一次返回的节点
private Entry<E> lastReturned = header;
// 下一个节点
private Entry<E> next;
// 下一个节点对应的索引值
private int nextIndex;
// 期望的改变计数。用来实现fail-fast机制。
private int expectedModCount = modCount;
// 构造函数。
// 从index位置开始进行迭代
ListItr(int index) {
// index的有效性处理
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size);
// 若 “index 小于 ‘双向链表长度的一半’”,则从第一个元素开始往后查找;
// 否则,从最后一个元素往前查找。
if (index < (size >> 1)) {
next = header.next;
for (nextIndex=0; nextIndex<index; nextIndex++)
next = next.next;
} else {
next = header;
for (nextIndex=size; nextIndex>index; nextIndex--)
next = next.previous;
}
}
// 是否存在下一个元素
public boolean hasNext() {
// 通过元素索引是否等于“双向链表大小”来判断是否达到最后。
return nextIndex != size;
}
// 获取下一个元素
public E next() {
checkForComodification();
if (nextIndex == size)
throw new NoSuchElementException();
lastReturned = next;
// next指向链表的下一个元素
next = next.next;
nextIndex++;
return lastReturned.element;
}
// 是否存在上一个元素
public boolean hasPrevious() {
// 通过元素索引是否等于0,来判断是否达到开头。
return nextIndex != 0;
}
// 获取上一个元素
public E previous() {
if (nextIndex == 0)
throw new NoSuchElementException();
// next指向链表的上一个元素
lastReturned = next = next.previous;
nextIndex--;
checkForComodification();
return lastReturned.element;
}
// 获取下一个元素的索引
public int nextIndex() {
return nextIndex;
}
// 获取上一个元素的索引
public int previousIndex() {
return nextIndex-1;
}
// 删除当前元素。
// 删除双向链表中的当前节点
public void remove() {
checkForComodification();
Entry<E> lastNext = lastReturned.next;
try {
LinkedList.this.remove(lastReturned);
} catch (NoSuchElementException e) {
throw new IllegalStateException();
}
if (next==lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = header;
expectedModCount++;
}
// 设置当前节点为e
public void set(E e) {
if (lastReturned == header)
throw new IllegalStateException();
checkForComodification();
lastReturned.element = e;
}
// 将e添加到当前节点的前面
public void add(E e) {
checkForComodification();
lastReturned = header;
addBefore(e, next);
nextIndex++;
expectedModCount++;
}
// 判断 “modCount和expectedModCount是否相等”,依次来实现fail-fast机制。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
// 双向链表的节点所对应的数据结构。
// 包含3部分:上一节点,下一节点,当前节点值。
private static class Entry<E> {
// 当前节点所包含的值
E element;
// 下一个节点
Entry<E> next;
// 上一个节点
Entry<E> previous;
/**
* 链表节点的构造函数。
* 参数说明:
* element —— 节点所包含的数据
* next —— 下一个节点
* previous —— 上一个节点
*/
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
// 将节点(节点数据是e)添加到entry节点之前。
private Entry<E> addBefore(E e, Entry<E> entry) {
// 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
// 修改LinkedList大小
size++;
// 修改LinkedList的修改统计数:用来实现fail-fast机制。
modCount++;
return newEntry;
}
// 将节点从链表中删除
private E remove(Entry<E> e) {
if (e == header)
throw new NoSuchElementException();
E result = e.element;
e.previous.next = e.next;
e.next.previous = e.previous;
e.next = e.previous = null;
e.element = null;
size--;
modCount++;
return result;
}
// 反向迭代器
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
// 反向迭代器实现类。
private class DescendingIterator implements Iterator {
final ListItr itr = new ListItr(size());
// 反向迭代器是否下一个元素。
// 实际上是判断双向链表的当前节点是否达到开头
public boolean hasNext() {
return itr.hasPrevious();
}
// 反向迭代器获取下一个元素。
// 实际上是获取双向链表的前一个节点
public E next() {
return itr.previous();
}
// 删除当前节点
public void remove() {
itr.remove();
}
}
// 返回LinkedList的Object[]数组
public Object[] toArray() {
// 新建Object[]数组
Object[] result = new Object[size];
int i = 0;
// 将链表中所有节点的数据都添加到Object[]数组中
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
return result;
}
// 返回LinkedList的模板数组。所谓模板数组,即可以将T设为任意的数据类型
public <T> T[] toArray(T[] a) {
// 若数组a的大小 < LinkedList的元素个数(意味着数组a不能容纳LinkedList中全部元素)
// 则新建一个T[]数组,T[]的大小为LinkedList大小,并将该T[]赋值给a。
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
// 将链表中所有节点的数据都添加到数组a中
int i = 0;
Object[] result = a;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
if (a.length > size)
a[size] = null;
return a;
}
// 克隆函数。返回LinkedList的克隆对象。
public Object clone() {
LinkedList<E> clone = null;
// 克隆一个LinkedList克隆对象
try {
clone = (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
// 新建LinkedList表头节点
clone.header = new Entry<E>(null, null, null);
clone.header.next = clone.header.previous = clone.header;
clone.size = 0;
clone.modCount = 0;
// 将链表中所有节点的数据都添加到克隆对象中
for (Entry<E> e = header.next; e != header; e = e.next)
clone.add(e.element);
return clone;
}
// java.io.Serializable的写入函数
// 将LinkedList的“容量,所有的元素值”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// 写入“容量”
s.writeInt(size);
// 将链表中所有节点的数据都写入到输出流中
for (Entry e = header.next; e != header; e = e.next)
s.writeObject(e.element);
}
// java.io.Serializable的读取函数:根据写入方式反向读出
// 先将LinkedList的“容量”读出,然后将“所有的元素值”读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// 从输入流中读取“容量”
int size = s.readInt();
// 新建链表表头节点
header = new Entry<E>(null, null, null);
header.next = header.previous = header;
// 从输入流中将“所有的元素值”并逐个添加到链表中
for (int i=0; i<size; i++)
addBefore((E)s.readObject(), header);
}
}
2.3 几点总结
关于LinkedList的源码,给出几点比较重要的总结:
1、从源码中很明显可以看出,LinkedList的实现是基于双向循环链表的,且头结点中不存放数据,如下图;
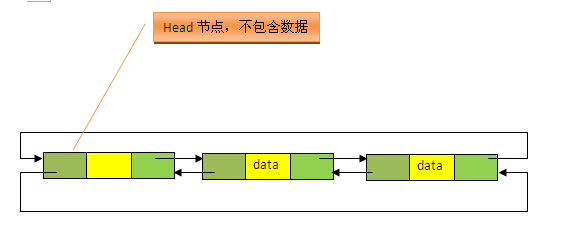
2、注意两个不同的构造方法。无参构造方法直接建立一个仅包含head节点的空链表,包含Collection的构造方法,先调用无参构造方法建立一个空链表,然后将Collection中的数据加入到链表的尾部后面。
3、在查找和删除某元素时,源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
4、LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
5、注意源码中的Entry<E> entry(int index)方法。该方法返回双向链表中指定位置处的节点,而链表中是没有下标索引的,要指定位置出的元素,就要遍历该链表,从源码的实现中,我们看到这里有一个加速动作。源码中先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。
6、注意链表类对应的数据结构Entry。如下;
// 双向链表的节点所对应的数据结构。
// 包含3部分:上一节点,下一节点,当前节点值。
private static class Entry<E> {
// 当前节点所包含的值
E element;
// 下一个节点
Entry<E> next;
// 上一个节点
Entry<E> previous;
/**
* 链表节点的构造函数。
* 参数说明:
* element —— 节点所包含的数据
* next —— 下一个节点
* previous —— 上一个节点
*/
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
7、LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。
8、要注意源码中还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。
3. LinkedHashMap源码剖析
3.1 LinkedHashMap简介
LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同。
LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析)。
LinkedHashMap同样是非线程安全的,只在单线程环境下使用。
3.2 LinkedHashMap源码剖析
LinkedHashMap源码如下(加入了详细的注释):
package java.util;
import java.io.*;
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
private static final long serialVersionUID = 3801124242820219131L;
//双向循环链表的头结点,整个LinkedHashMap中只有一个header,
//它将哈希表中所有的Entry贯穿起来,header中不保存key-value对,只保存前后节点的引用
private transient Entry<K,V> header;
//双向链表中元素排序规则的标志位。
//accessOrder为false,表示按插入顺序排序
//accessOrder为true,表示按访问顺序排序
private final boolean accessOrder;
//调用HashMap的构造方法来构造底层的数组
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false; //链表中的元素默认按照插入顺序排序
}
//加载因子取默认的0.75f
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
//加载因子取默认的0.75f,容量取默认的16
public LinkedHashMap() {
super();
accessOrder = false;
}
//含有子Map的构造方法,同样调用HashMap的对应的构造方法
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
//该构造方法可以指定链表中的元素排序的规则
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
//覆写父类的init()方法(HashMap中的init方法为空),
//该方法在父类的构造方法和Clone、readObject中在插入元素前被调用,
//初始化一个空的双向循环链表,头结点中不保存数据,头结点的下一个节点才开始保存数据。
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
//覆写HashMap中的transfer方法,它在父类的resize方法中被调用,
//扩容后,将key-value对重新映射到新的newTable中
//覆写该方法的目的是为了提高复制的效率,
//这里充分利用双向循环链表的特点进行迭代,不用对底层的数组进行for循环。
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
//覆写HashMap中的containsValue方法,
//覆写该方法的目的同样是为了提高查询的效率,
//利用双向循环链表的特点进行查询,少了对数组的外层for循环
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
//覆写HashMap中的get方法,通过getEntry方法获取Entry对象。
//注意这里的recordAccess方法,
//如果链表中元素的排序规则是按照插入的先后顺序排序的话,该方法什么也不做,
//如果链表中元素的排序规则是按照访问的先后顺序排序的话,则将e移到链表的末尾处。
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
//清空HashMap,并将双向链表还原为只有头结点的空链表
public void clear() {
super.clear();
header.before = header.after = header;
}
//Enty的数据结构,多了两个指向前后节点的引用
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
//调用父类的构造方法
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//双向循环链表中,删除当前的Entry
private void remove() {
before.after = after;
after.before = before;
}
//双向循环立链表中,将当前的Entry插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
//覆写HashMap中的recordAccess方法(HashMap中该方法为空),
//当调用父类的put方法,在发现插入的key已经存在时,会调用该方法,
//调用LinkedHashmap覆写的get方法时,也会调用到该方法,
//该方法提供了LRU算法的实现,它将最近使用的Entry放到双向循环链表的尾部,
//accessOrder为true时,get方法会调用recordAccess方法
//put方法在覆盖key-value对时也会调用recordAccess方法
//它们导致Entry最近使用,因此将其移到双向链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果链表中元素按照访问顺序排序,则将当前访问的Entry移到双向循环链表的尾部,
//如果是按照插入的先后顺序排序,则不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
//移除当前访问的Entry
remove();
//将当前访问的Entry插入到链表的尾部
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
//迭代器
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
//从head的下一个节点开始迭代
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
//key迭代器
private class KeyIterator extends LinkedHashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
//value迭代器
private class ValueIterator extends LinkedHashIterator<V> {
public V next() {
return nextEntry().value;
}
}
//Entry迭代器
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// These Overrides alter the behavior of superclass view iterator() methods
Iterator<K> newKeyIterator() { return new KeyIterator(); }
Iterator<V> newValueIterator() { return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); }
//覆写HashMap中的addEntry方法,LinkedHashmap并没有覆写HashMap中的put方法,
//而是覆写了put方法所调用的addEntry方法和recordAccess方法,
//put方法在插入的key已存在的情况下,会调用recordAccess方法,
//在插入的key不存在的情况下,要调用addEntry插入新的Entry
void addEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex);
//双向链表的第一个有效节点(header后的那个节点)为近期最少使用的节点
Entry<K,V> eldest = header.after;
//如果有必要,则删除掉该近期最少使用的节点,
//这要看对removeEldestEntry的覆写,由于默认为false,因此默认是不做任何处理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//扩容到原来的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并将其插入到数组对应槽的单链表的头结点处,这点与HashMap中相同
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//每次插入Entry时,都将其移到双向链表的尾部,
//这便会按照Entry插入LinkedHashMap的先后顺序来迭代元素,
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,符合LRU算法的实现
e.addBefore(header);
size++;
}
//该方法是用来被覆写的,一般如果用LinkedHashmap实现LRU算法,就要覆写该方法,
//比如可以将该方法覆写为如果设定的内存已满,则返回true,这样当再次向LinkedHashMap中put
//Entry时,在调用的addEntry方法中便会将近期最少使用的节点删除掉(header后的那个节点)。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
3.3 几点总结
关于LinkedHashMap的源码,给出以下几点比较重要的总结:
1、从源码中可以看出,LinkedHashMap中加入了一个head头结点,将所有插入到该LinkedHashMap中的Entry按照插入的先后顺序依次加入到以head为头结点的双向循环链表的尾部。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YlUzBgYY-1692927385674)(https://image.xiaoxiaofeng.site/blog/2023/05/18/xxf-20230518175942.png?xxfjava)]
1、实际上就是HashMap和LinkedList两个集合类的存储结构的结合。在LinkedHashMapMap中,所有put进来的Entry都保存在如第一个图所示的哈希表中,但它又额外定义了一个以head为头结点的空的双向循环链表,每次put进来Entry,除了将其保存到对哈希表中对应的位置上外,还要将其插入到双向循环链表的尾部。
2、LinkedHashMap由于继承自HashMap,因此它具有HashMap的所有特性,同样允许key和value为null。
3、注意源码中的accessOrder标志位,当它false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序;当它为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同,覆盖原有的Entry的情况下调用recordAccess方法),该方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用creatEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了),否则,什么也不做。
4、注意构造方法,前四个构造方法都将accessOrder设为false,说明默认是按照插入顺序排序的,而第五个构造方法可以自定义传入的accessOrder的值,因此可以指定双向循环链表中元素的排序规则,一般要用LinkedHashMap实现LRU算法,就要用该构造方法,将accessOrder置为true。
5、LinkedHashMap并没有覆写HashMap中的put方法,而是覆写了put方法中调用的addEntry方法和recordAccess方法,我们回过头来再看下HashMap的put方法:
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
//将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
}
当要put进来的Entry的key在哈希表中已经在存在时,会调用recordAccess方法,当该key不存在时,则会调用addEntry方法将新的Entry插入到对应槽的单链表的头部。
我们先来看recordAccess方法:
//覆写HashMap中的recordAccess方法(HashMap中该方法为空),
//当调用父类的put方法,在发现插入的key已经存在时,会调用该方法,
//调用LinkedHashmap覆写的get方法时,也会调用到该方法,
//该方法提供了LRU算法的实现,它将最近使用的Entry放到双向循环链表的尾部,
//accessOrder为true时,get方法会调用recordAccess方法
//put方法在覆盖key-value对时也会调用recordAccess方法
//它们导致Entry最近使用,因此将其移到双向链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果链表中元素按照访问顺序排序,则将当前访问的Entry移到双向循环链表的尾部,
//如果是按照插入的先后顺序排序,则不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
//移除当前访问的Entry
remove();
//将当前访问的Entry插入到链表的尾部
addBefore(lm.header);
}
}
该方法会判断accessOrder是否为true,如果为true,它会将当前访问的Entry(在这里指put进来的Entry)移动到双向循环链表的尾部,从而实现双向链表中的元素按照访问顺序来排序(最近访问的Entry放到链表的最后,这样多次下来,前面就是最近没有被访问的元素,在实现、LRU算法时,当双向链表中的节点数达到最大值时,将前面的元素删去即可,因为前面的元素是最近最少使用的),否则什么也不做。
再来看addEntry方法:
//覆写HashMap中的addEntry方法,LinkedHashmap并没有覆写HashMap中的put方法,
//而是覆写了put方法所调用的addEntry方法和recordAccess方法,
//put方法在插入的key已存在的情况下,会调用recordAccess方法,
//在插入的key不存在的情况下,要调用addEntry插入新的Entry
void addEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex);
//双向链表的第一个有效节点(header后的那个节点)为近期最少使用的节点
Entry<K,V> eldest = header.after;
//如果有必要,则删除掉该近期最少使用的节点,
//这要看对removeEldestEntry的覆写,由于默认为false,因此默认是不做任何处理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//扩容到原来的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并将其插入到数组对应槽的单链表的头结点处,这点与HashMap中相同
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//每次插入Entry时,都将其移到双向链表的尾部,
//这便会按照Entry插入LinkedHashMap的先后顺序来迭代元素,
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,符合LRU算法的实现
e.addBefore(header);
size++;
}
同样是将新的Entry插入到table中对应槽所对应单链表的头结点中,但可以看出,在createEntry中,同样把新put进来的Entry插入到了双向链表的尾部,从插入顺序的层面来说,新的Entry插入到双向链表的尾部,可以实现按照插入的先后顺序来迭代Entry,而从访问顺序的层面来说,新put进来的Entry又是最近访问的Entry,也应该将其放在双向链表的尾部。
上面还有个removeEldestEntry方法,该方法如下:
//该方法是用来被覆写的,一般如果用LinkedHashmap实现LRU算法,就要覆写该方法,
//比如可以将该方法覆写为如果设定的内存已满,则返回true,这样当再次向LinkedHashMap中put
//Entry时,在调用的addEntry方法中便会将近期最少使用的节点删除掉(header后的那个节点)。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
该方法默认返回false,我们一般在用LinkedHashMap实现LRU算法时,要覆写该方法,一般的实现是,当设定的内存(这里指节点个数)达到最大值时,返回true,这样put新的Entry(该Entry的key在哈希表中没有已经存在)时,就会调用removeEntryForKey方法,将最近最少使用的节点删除(head后面的那个节点,实际上是最近没有使用)。
6、LinkedHashMap覆写了HashMap的get方法:
//覆写HashMap中的get方法,通过getEntry方法获取Entry对象。
//注意这里的recordAccess方法,
//如果链表中元素的排序规则是按照插入的先后顺序排序的话,该方法什么也不做,
//如果链表中元素的排序规则是按照访问的先后顺序排序的话,则将e移到链表的末尾处。
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
先取得Entry,如果不为null,一样调用recordAccess方法,上面已经说得很清楚,这里不在多解释了。
7、最后说说LinkedHashMap是如何实现LRU的。首先,当accessOrder为true时,才会开启按访问顺序排序的模式,才能用来实现LRU算法。我们可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此便把该Entry加入到了双向链表的末尾(get方法通过调用recordAccess方法来实现,put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现),这样便把最近使用了的Entry放入到了双向链表的后面,多次操作后,双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除的最前面的Entry(head后面的那个Entry)便是最近最少使用的Entry。
4. HashMap源码剖析(JDK7)
4.1 HashMap概述
HashMap是基于哈希表实现的,每一个元素都是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
4.2 四个关注点在HashMap上的答案
| 关注点 | 结论 |
|---|---|
| HashMap是否允许空 | Key和Value都允许为空 |
| HashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| HashMap是否有序 | 无序,特别说明这个无序指的是遍历HashMap的时候,得到的元素的顺序基本不可能是put的顺序 |
| HashMap是否线程安全 | 非线程安全 |
4.3 HashMap源码剖析
HashMap的源码如下(加入了比较详细的注释):
package java.util;
import java.io.*;
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
// 默认的初始容量(容量为HashMap中槽的数目)是16,且实际容量必须是2的整数次幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 存储数据的Entry数组,长度是2的幂。
// HashMap采用链表法解决冲突,每一个Entry本质上是一个单向链表
transient Entry[] table;
// HashMap的底层数组中已用槽的数量
transient int size;
// HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
int threshold;
// 加载因子实际大小
final float loadFactor;
// HashMap被改变的次数
transient volatile int modCount;
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//加载因此不能小于0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 找出“大于initialCapacity”的最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 默认构造函数。
public HashMap() {
// 设置“加载因子”为默认加载因子0.75
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
//求hash值的方法,重新计算hash值
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 返回h在数组中的索引值,这里用&代替取模,旨在提升效率
// h & (length-1)保证返回值的小于length
static int indexFor(int h, int length) {
return h & (length-1);
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 获取key对应的value
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//判断key是否相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
//没找到则返回null
return null;
}
// 获取“key为null”的元素的值
// HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置!
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
// HashMap是否包含key
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
// 返回“键为key”的键值对
final Entry<K,V> getEntry(Object key) {
// 获取哈希值
// HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值
int hash = (key == null) ? 0 : hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
// 将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
}
// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果没有存在key为null的键值对,则直接题阿见到table[0]处!
modCount++;
addEntry(0, null, value, 0);
return null;
}
// 创建HashMap对应的“添加方法”,
// 它和put()不同。putForCreate()是内部方法,它被构造函数等调用,用来创建HashMap
// 而put()是对外提供的往HashMap中添加元素的方法。
private void putForCreate(K key, V value) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
// 若该HashMap表中存在“键值等于key”的元素,则替换该元素的value值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
// 若该HashMap表中不存在“键值等于key”的元素,则将该key-value添加到HashMap中
createEntry(hash, key, value, i);
}
// 将“m”中的全部元素都添加到HashMap中。
// 该方法被内部的构造HashMap的方法所调用。
private void putAllForCreate(Map<? extends K, ? extends V> m) {
// 利用迭代器将元素逐个添加到HashMap中
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
putForCreate(e.getKey(), e.getValue());
}
}
// 重新调整HashMap的大小,newCapacity是调整后的容量
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果就容量已经达到了最大值,则不能再扩容,直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
// 将HashMap中的全部元素都添加到newTable中
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
// 将"m"的全部元素都添加到HashMap中
public void putAll(Map<? extends K, ? extends V> m) {
// 有效性判断
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 计算容量是否足够,
// 若“当前阀值容量 < 需要的容量”,则将容量x2。
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
// 通过迭代器,将“m”中的元素逐个添加到HashMap中。
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
put(e.getKey(), e.getValue());
}
}
// 删除“键为key”元素
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
// 删除“键为key”的元素
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
// 删除“键值对”
final Entry<K,V> removeMapping(Object o) {
if (!(o instanceof Map.Entry))
return null;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
Object key = entry.getKey();
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中的“键值对e”
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
if (e.hash == hash && e.equals(entry)) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
// 清空HashMap,将所有的元素设为null
public void clear() {
modCount++;
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
tab[i] = null;
size = 0;
}
// 是否包含“值为value”的元素
public boolean containsValue(Object value) {
// 若“value为null”,则调用containsNullValue()查找
if (value == null)
return containsNullValue();
// 若“value不为null”,则查找HashMap中是否有值为value的节点。
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
// 是否包含null值
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
// 克隆一个HashMap,并返回Object对象
public Object clone() {
HashMap<K,V> result = null;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// assert false;
}
result.table = new Entry[table.length];
result.entrySet = null;
result.modCount = 0;
result.size = 0;
result.init();
// 调用putAllForCreate()将全部元素添加到HashMap中
result.putAllForCreate(this);
return result;
}
// Entry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
// 指向下一个节点
Entry<K,V> next;
final int hash;
// 构造函数。
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 当向HashMap中添加元素时,绘调用recordAccess()。
// 这里不做任何处理
void recordAccess(HashMap<K,V> m) {
}
// 当从HashMap中删除元素时,绘调用recordRemoval()。
// 这里不做任何处理
void recordRemoval(HashMap<K,V> m) {
}
}
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
// 创建Entry。将“key-value”插入指定位置。
void createEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
size++;
}
// HashIterator是HashMap迭代器的抽象出来的父类,实现了公共了函数。
// 它包含“key迭代器(KeyIterator)”、“Value迭代器(ValueIterator)”和“Entry迭代器(EntryIterator)”3个子类。
private abstract class HashIterator<E> implements Iterator<E> {
// 下一个元素
Entry<K,V> next;
// expectedModCount用于实现fast-fail机制。
int expectedModCount;
// 当前索引
int index;
// 当前元素
Entry<K,V> current;
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
// 将next指向table中第一个不为null的元素。
// 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
// 获取下一个元素
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
// 注意!!!
// 一个Entry就是一个单向链表
// 若该Entry的下一个节点不为空,就将next指向下一个节点;
// 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
// 删除当前元素
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
// value的迭代器
private final class ValueIterator extends HashIterator<V> {
public V next() {
return nextEntry().value;
}
}
// key的迭代器
private final class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
// Entry的迭代器
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// 返回一个“key迭代器”
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
// 返回一个“value迭代器”
Iterator<V> newValueIterator() {
return new ValueIterator();
}
// 返回一个“entry迭代器”
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
// HashMap的Entry对应的集合
private transient Set<Map.Entry<K,V>> entrySet = null;
// 返回“key的集合”,实际上返回一个“KeySet对象”
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
// Key对应的集合
// KeySet继承于AbstractSet,说明该集合中没有重复的Key。
private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
// 返回“value集合”,实际上返回的是一个Values对象
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
// “value集合”
// Values继承于AbstractCollection,不同于“KeySet继承于AbstractSet”,
// Values中的元素能够重复。因为不同的key可以指向相同的value。
private final class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
// 返回“HashMap的Entry集合”
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
// 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
// EntrySet对应的集合
// EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> e = (Map.Entry<K,V>) o;
Entry<K,V> candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
// java.io.Serializable的写入函数
// 将HashMap的“总的容量,实际容量,所有的Entry”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
Iterator<Map.Entry<K,V>> i =
(size > 0) ? entrySet0().iterator() : null;
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
// Write out number of buckets
s.writeInt(table.length);
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
if (i != null) {
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
}
private static final long serialVersionUID = 362498820763181265L;
// java.io.Serializable的读取函数:根据写入方式读出
// 将HashMap的“总的容量,实际容量,所有的Entry”依次读出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the threshold, loadfactor, and any hidden stuff
s.defaultReadObject();
// Read in number of buckets and allocate the bucket array;
int numBuckets = s.readInt();
table = new Entry[numBuckets];
init(); // Give subclass a chance to do its thing.
// Read in size (number of Mappings)
int size = s.readInt();
// Read the keys and values, and put the mappings in the HashMap
for (int i=0; i<size; i++) {
K key = (K) s.readObject();
V value = (V) s.readObject();
putForCreate(key, value);
}
}
// 返回“HashMap总的容量”
int capacity() { return table.length; }
// 返回“HashMap的加载因子”
float loadFactor() { return loadFactor; }
}
4.4 几点总结
1、首先要清楚HashMap的存储结构,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aoj2barK-1692927385674)(https://image.xiaoxiaofeng.site/blog/2023/05/18/xxf-20230518180052.png?xxfjava)]
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
2、首先看链表中节点的数据结构:
// Entry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
// 指向下一个节点
Entry<K,V> next;
final int hash;
// 构造函数。
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 当向HashMap中添加元素时,绘调用recordAccess()。
// 这里不做任何处理
void recordAccess(HashMap<K,V> m) {
}
// 当从HashMap中删除元素时,绘调用recordRemoval()。
// 这里不做任何处理
void recordRemoval(HashMap<K,V> m) {
}
}
它的结构元素除了key、value、hash外,还有next,next指向下一个节点。另外,这里覆写了equals和hashCode方法来保证键值对的独一无二。
3、HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。
下面说下加载因子,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。
另外,无论我们指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方
4、HashMap中key和value都允许为null。
5、要重点分析下HashMap中用的最多的两个方法put和get。先从比较简单的get方法着手,源码如下:
// 获取key对应的value
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
/判断key是否相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
没找到则返回null
return null;
}
// 获取“key为null”的元素的值
// HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置!
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
首先,如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。
如果key不为null,则先求的key的hash值,根据hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,没有则返回null。
put方法稍微复杂些,代码如下:
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
//将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
}
如果key为null,则将其添加到table[0]对应的链表中,putForNullKey的源码如下:
// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果没有存在key为null的键值对,则直接题阿见到table[0]处!
modCount++;
addEntry(0, null, value, 0);
return null;
}
如果key不为null,则同样先求出key的hash值,根据hash值得出在table中的索引,而后遍历对应的单链表,如果单链表中存在与目标key相等的键值对,则将新的value覆盖旧的value,比将旧的value返回,如果找不到与目标key相等的键值对,或者该单链表为空,则将该键值对插入到改单链表的头结点位置(每次新插入的节点都是放在头结点的位置),该操作是有addEntry方法实现的,它的源码如下:
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
注意这里倒数第三行的构造方法,将key-value键值对赋给table[bucketIndex],并将其next指向元素e,这便将key-value放到了头结点中,并将之前的头结点接在了它的后面。该方法也说明,每次put键值对的时候,总是将新的该键值对放在table[bucketIndex]处(即头结点处)。
另外注意最后两行代码,每次加入键值对时,都要判断当前已用的槽的数目是否大于等于阀值(容量*加载因子),如果大于等于,则进行扩容,将容量扩为原来容量的2倍。
6、关于扩容。上面我们看到了扩容的方法,resize方法,它的源码如下:
// 重新调整HashMap的大小,newCapacity是调整后的单位
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
很明显,是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。transfer方法的源码如下:
// 将HashMap中的全部元素都添加到newTable中
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
7、注意containsKey方法和containsValue方法。前者直接可以通过key的哈希值将搜索范围定位到指定索引对应的链表,而后者要对哈希数组的每个链表进行搜索。
8、我们重点来分析下求hash值和索引值的方法,这两个方法便是HashMap设计的最为核心的部分,二者结合能保证哈希表中的元素尽可能均匀地散列。
计算哈希值的方法如下:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
它只是一个数学公式,IDK这样设计对hash值的计算,自然有它的好处,至于为什么这样设计,我们这里不去追究,只要明白一点,用的位的操作使hash值的计算效率很高。
由hash值找到对应索引的方法如下:
static int indexFor(int h, int length) {
return h & (length-1);
}
这个我们要重点说下,我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。
接下来,我们分析下为什么哈希表的容量一定要是2的整数次幂。首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
5. HashMap源码剖析(JDK8)
5.1 HashMap底层数据结构
HashMap底层数据结构是 数组 + 链。如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-892DV2KL-1692927385675)(https://image.xiaoxiaofeng.site/spider/2023/7/20/xxf-1689833106507.png)]
当满足以下两个条件,链表会转为红黑树:
1、数组长度等于或大于64
2、链表长度等于或大于8
如果数组长度小于64,链表长度等于或大于8,不会把链表转为红黑树,而是扩容。扩容也大概率能降低链表的长度。
5.2 HashMap的一些重要成员变量
// 底层数组,可自动扩容,但是HashMap不支持缩容,长度总是2的N次方
transient Node<K,V>[] table;
// 初始容量大小,1左移4位结果是10000,转为十进制是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 同时满足“数组长度等于或大于64”、“链表长度等于或大于8” 两个条件,才将链表转为红黑树
*/
// 树化阀值
static final int TREEIFY_THRESHOLD = 8;
// 最小树化容量(树化是指将链表转为红黑树)
static final int MIN_TREEIFY_CAPACITY = 64;
// HashMap的数组最大长度
static final int MAXIMUM_CAPACITY = 1 << 30;
// 扩容的阈值
int threshold;
// 负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
5.3 HashMap的构造函数
HashMap共有4个构造函数,我挑选 public HashMap(int initialCapacity, float loadFactor) 讲解
/**
* 构造函数解析
*/
public HashMap(int initialCapacity, float loadFactor) {
// 判断传入的参数是否合理
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 设置负载因子,默认是 0.75
this.loadFactor = loadFactor;
// 设置扩容阀值
// initialCapacity(初始容量大小)默认是16
// 用户设置的initialCapacity可以是任何大于0的数字,tableSizeFor(initialCapacity)返回结果是2的N次方。即HashMap的容量必然是2的N次方
this.threshold = tableSizeFor(initialCapacity);
}
/**
* tableSizeFor(int cap)方法解析
* 返回值大于等于cap,且一定是2的次方数
*
* 假设 cap = 10
* n = 10 - 1 => 9 => 0b1001(0b表示二进制数)
* n |= n >>> 1; 表示 n 等于 n 或上 n右移一位
* 0b1001 | 0b0100 => 0b1101 // n |= n >>> 1;
* 0b1101 | 0b0010 => 0b1111 // n |= n >>> 2;
* 0b1111 | 0b0100 => 0b1111 // n |= n >>> 4;
* 以此类推,最终 n = 15
*
* return 16
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
5.4 put(K key, V value) 方法
HashMap的链表Node数据结构如下
/**
* 链表的Node
*/
static class Node<K,V> implements Map.Entry<K,V> {
// key的hash值
final int hash;
// key
final K key;
// value
V value;
// 下一个元素
HashMap.Node<K, V> next;
}
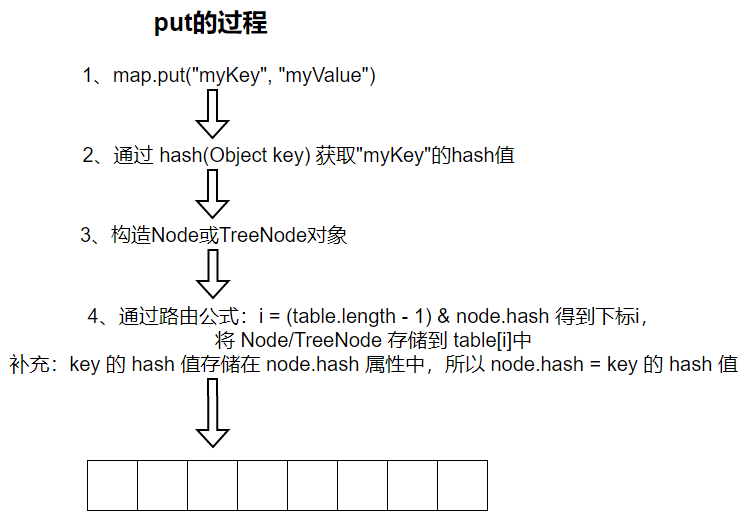
步骤2 hash(Obejct key) 方法源码解读
/**
* 如果key是null,则返回0
* 如果key不是null,则使用 key的hashCode 异或 key的hashCode右移16位
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么不直接返回key的hashCode ,而要右移16位后取“异或”结果呢?这与key的路由公式 i = (table.length - 1) & node.hash有关。
Java Object 的 hashCode() 方法返回结果是int ,int占32位,即可以将int转为32位的二进制数表示 ,假设直接使用key的hashCode,
hashCode = 1111 0101 1100 0100 1111 0001 1101 0011
把hashCode带入路由公式
i = (table.length - 1) & 1111 0101 1100 0100 1111 0001 1101 0011
table.length一定是2的N次方,则 table.length - 1 的结果转换为二进制一定是高位全为0,低位全为1。当table.length比较小的时候,例如 table.length = 1024,table.length - 1 = 1023,1023转为二进制是 0000 0000 000 0000 0000 0011 1111 1111。
0000 0000 000 0000 0000 0011 1111 1111 & 1111 0101 1100 0100 1111 0001 1101 0011 = 0000 0000 000 0000 0000 0001 1101 0011 发现特殊之处了吗?0和任何数做“与”操作结果都是0,1和任何数做“与”操作结果保持不变,这就导致key的路由公式只使用到hashCode低位值,没用到高位值。尤其是table.length越小,能使用到的hashCode位数越少。为了能把高位的hashCode也使用上,HashMap的作者做了这样的操作 (h = key.hashCode()) ^ (h >>> 16) ,让 hashCode 跟 hashCode右移16位的结果 做“异或” 操作,这样低16位数据就混入了高16位的数据,低16位数据更加散列。也可以认为key.hash()返回的值,低16位混合了key.hashCode的全部信息,路由公式 i = (table.length - 1) & node.hash,i的结果会更加散列。
put(K key, V value) 方法源码分析,方法内部是调用 putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) 方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* putVal方法分析
* @param hash key的hash值
* @param key key
* @param value value
* @param onlyIfAbsent key已经存在,是否改变value。如果为true,则不更改现有值;为false,修改value
* @param evict 如果为false,则表处于创建模式
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// tab: 引用当前HashMap的数组
// p: 数组的元素
// n:数组的长度
// i: 路由寻址的结果
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
// 执行 new HashMap() 的时候并不会创建数组,节约内存,等首次插入键值对,才创建数组,这属于延迟初始化,所以会有table==null的判断
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// i = (n - 1) & hash 是key路由公式,tab[i = (n - 1) & hash] 找到key在数组中的位置
// 如果 tab[i] == null 证明当前位置还没有键值对,创建Node放到tab[i]中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// tab[i]中已经有Node了
else {
// e: 一个临时的Node
// k: 一个临时的key
HashMap.Node<K,V> e; K k;
// key比较,桶位中的第一个元素与插入的key完全一致的情况
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// e后续要进行替换操作
e = p;
// p instanceof TreeNode 桶位是红黑树的情况
else if (p instanceof TreeNode)
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// tab[i]是链表,并且链表第一个元素key与插入的key不一致
else {
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// (e = p.next) == null 表示迭代到了最后的元素
if ((e = p.next) == null) {
// 将插入的node放到链表末尾
p.next = newNode(hash, key, value, null);
// 新node插入到链表末尾,判断是否将链表转为红黑树
// 链表长度等于或大于8,执行treeifyBin(tab, hash);
// treeifyBin(Node<K,V>[] tab, int hash)方法中会判断数组长度小于MIN_TREEIFY_CAPACITY则执行扩容,否则执行链表变红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 在遍历链表的过程中,找到了key完全相等的node元素
// 退出循环,后续进行替换
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// e != null 条件成立,说明插入的key在HashMap中已经存在,把值替换为新值即可,然后返回旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
// 替换value
e.value = value;
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 散列表被修改的次数加一
// 替换node的value不算被修改,如果是替换操作,在上面的if (e != null)判断中return了,不会运行此处的代码
++modCount;
// HashMap的node数量到达阈值,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
5.5 resize() 扩容方法
前置知识:HashMap扩容后,key只可能在两个位置。
1、key可能保持在原桶位,不发生移动,即还是在table[i]中。
2、key可能在 原桶位下标 + 原table长度 的位置。
下面举例说明
key的路由公式是 i = (table.length - 1) & node.hash ,假设 table.length = 16 且 key在table[15]的位置。代入路由公式
15 = (16 - 1) & node.hash
十进制转为二进制。用“…”表示多个。用“xxxx”表示多位二进制数,可能为0也可能是1。
00…00 1111 = 00…00 1111 & node.hash ,若要式子成立,node.hash 的低4位必然全是1,只有 1 & 1 的结果才是 1,node.hash 可表示为 xxxxxxxx 1111
接着发生扩容,table.length 变为 32,把 table.length 代入路由公式
i = 31 & node.hash ,把31转为二进制,且上面已经得出结论 node.hash 是 xxxxxxxx 1111
i = 00…01 1111 & xxxxxxxx 1111
当 node.hash = xxxxxxx0 1111 ,i = 00…01 1111 & xxxxxxx0 1111 = 00…00 1111 = 15
当 node.hash = xxxxxxx1 1111 ,i = 00…01 1111 & xxxxxxx1 1111 = 00…01 1111 = 31 = 15 + 16
其他桶位的扩容也是一样的,满足前面提出的两点:
1、key可能保持在原桶位,不发生移动,即还是在table[i]中。
2、key可能在 原桶位下标 + 原table长度 的位置。
如果觉得理解有困难,可结合下图理解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dd6XWZaD-1692927385676)(https://image.xiaoxiaofeng.site/spider/2023/7/20/xxf-1689833109430.png)]
弄清楚了扩容时 key 的规则,还需要记住一个概念:在 resize() 的源码中,把扩容后table[15]的链表称为低位链表,扩容后table[31]的链表称为高位链表。
resize()源码分析
// 扩容
final HashMap.Node<K,V>[] resize() {
// oldTab:引用扩容前的数组
HashMap.Node<K,V>[] oldTab = table;
// oldCap: 扩容前数组table的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// oldThr:扩容前的扩容阈值
int oldThr = threshold;
// newCap:扩容后数组table的大小,先给个初值0
// newThr:扩容后的扩容阈值,先给个初值0
int newCap, newThr = 0;
// oldCap > 0 表示数组table已经初始化过了,是一次正常的扩容
if (oldCap > 0) {
// oldCap >= MAXIMUM_CAPACITY 数组的长度已经到达最大值,没法扩容了,直接return
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// newCap = oldCap << 1 数字左移一位,等同于乘以2,但使用位运算更高效。新容量等于旧容量乘以2
// 例如:4 * 2 = 8 转为二进制左移操作:100 左移一位变为 1000
// (newCap = oldCap << 1) < MAXIMUM_CAPACITY -> 数组大小 < 最大限制值 ,这个判断条件基本都是true
// oldCap >= DEFAULT_INITIAL_CAPACITY 当前数组长度必须大于DEFAULT_INITIAL_CAPACITY
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容阀值也要变化,新扩容阀值 = 旧扩容阀值左移一位,等同于乘以2
newThr = oldThr << 1; // double threshold
}
/**
* oldCap == 0 && oldThr > 0 的情况
* 通过 new HashMap(int initialCapacity, float loadFactor)
* new HashMap(int initialCapacity)
* new HashMap(Map<? extends K, ? extends V> m)
* 这三种方式创建HashMap,构造函数会初始化oldThr,且 oldThr >= 16
*/
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
/**
* oldCap == 0 && oldThr == 0 的情况
* 通过 new HashMap() 创建的HashMap,构造函数不会初始化oldThr
*/
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
// 扩容阈值是 负载因子 * 默认初始容量 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
/**
* else if (oldThr > 0) 条件成立
*
* else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY
* && oldCap >= DEFAULT_INITIAL_CAPACITY) 条件不成立
*
* 这两种情况下,newThr == 0,需要计算扩容阈值
*/
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 得到扩容阈值
threshold = newThr;
// 前面的代码主要做两件事
// 1、计算出本次扩容后,table数组的长度
// 2、计算出下一次扩容的阈值
// 创建一个更大的数组,一般情况下是原数组的两倍长度
@SuppressWarnings({"rawtypes","unchecked"})
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
// oldTab != null 说明扩容前HashMap已经有数据
if (oldTab != null) {
// 遍历老数组
for (int j = 0; j < oldCap; ++j) {
// 临时节点变量
HashMap.Node<K,V> e;
// (e = oldTab[j]) != null 当前桶位有数据,但是不知道是 单个Node、链表、红黑树 中的哪一种情况
if ((e = oldTab[j]) != null) {
// 方便JVM回收内存
oldTab[j] = null;
// e.next == null 当前桶位只有一个node
if (e.next == null)
// e.hash & (newCap - 1) 是 key的路由算法
// 当前桶位只有一个元素,从未发生碰撞,可直接将当前元素放到新数组中
newTab[e.hash & (newCap - 1)] = e;
// e instanceof HashMap.TreeNode 桶位元素是红黑树
else if (e instanceof HashMap.TreeNode)
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 桶位元素是链表
else { // preserve order
// 低位链表
// 扩容之后的数组下标位置,与当前数组的下标位置一致
// 假设原数组长度是16,table[15].hash = xxx0 1111,扩容后,还是在table[15]中
HashMap.Node<K,V> loHead = null, loTail = null;
// 高位链表
// 扩容之后的数组下标位置 = 原数组下标 + 扩容之前数组的长度
// 假设原数组长度是16,table[15].hash = xxx1 1111,扩容后,在table[31]中
// 扩容之后的数组下标位置 = 当前数组下标位置 + 扩容之前数组的长度 -> 31 = 15 + 16 -> 1 1111 = 1111 + 10000
HashMap.Node<K,V> hiHead = null, hiTail = null;
// 临时变量
HashMap.Node<K,V> next;
do {
next = e.next;
// 假设原数组长度oldCap是16 ,转为二进制是 10000
// 假设 e.hash = xxx0 1111 ,xxx0 1111 & 10000 = 0 ,扩容后node在低位链表中
// 假设 e.hash = xxx1 1111 ,xxx1 1111 & 10000 = 10000 ,扩容后node在高位链表中
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// loTail != null 低位链表有数据
if (loTail != null) {
// 新链表的最后一个node.next一定要设置为null
// 因为在原链表中node.next可能还指向一个node
loTail.next = null;
// 低位链表还在原桶位中,即还在table[j]中
newTab[j] = loHead;
}
// hiTail != null 高位链表有数据
if (hiTail != null) {
hiTail.next = null;
// 高位链表放在 数组下标位置 = 当前数组下标位置 + 扩容之前数组的长度 的位置,即在table[[j + oldCap]]中
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
5.6 get(Object key) 方法
理解put方法后,get方法就比较简单了
public V get(Object key) {
HashMap.Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final HashMap.Node<K,V> getNode(int hash, Object key) {
// tab:HashMap底层数组
// first:桶位中的头元素
// e: 临时node元素
// n: table数组长度
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> first, e; int n; K k;
// table不为null
// (n - 1) & hash 是key的路由算法,first = tab[(n - 1) & hash] 找到第一个桶元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 头元素(如果是树,则称为根元素)正好是要查找的元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶位不是单个node
if ((e = first.next) != null) {
// 桶位是树
if (first instanceof HashMap.TreeNode)
return ((HashMap.TreeNode<K,V>)first).getTreeNode(hash, key);
// 桶位是链表
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
5.7 remove(Object key) 方法
remove(Object key) 方法不会对HashMap的底层数组做缩容操作,方法详细解析请看代码注释
final HashMap.Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
// tab:HashMap底层数组
// p: 当前node元素
// n: 数组长度
// index: 寻址结果
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, index;
// 通过路由公式 (n - 1) & hash 查找到key所在桶位不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
// node:查找到的结果
// e: 当前node的下一个元素
HashMap.Node<K,V> node = null, e; K k; V v;
// 要删除的元素是桶位中的第一个元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// 红黑树查找node
if (p instanceof HashMap.TreeNode)
node = ((HashMap.TreeNode<K,V>)p).getTreeNode(hash, key);
// 链表的查找
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 前面只是找到要删除的元素,并将元素赋值给node,下面执行删除操作
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 红黑树删除元素
if (node instanceof HashMap.TreeNode)
((HashMap.TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
// node == p ,则p必然是桶位第一个元素
// 删除桶位第一个元素
else if (node == p)
tab[index] = node.next;
// 链表删除node,此时p是node的前一个元素
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
6. HashMap在JDK7与JDK8的区别
看过很多文章写HashMap在jdk7和8之间的区别,这里做一下深度的剖析,以及为什么会存在这些区别
6.1 数据结构上的区别
-
JDK7中的数据结构主要是:数组+链表,数组和链表的节点的实现类是Entry类
-
JDK8中的数据结构主要是:数组+链表/红黑树,当链表的元素个数大于等于8的时候转为红黑树,元素个数小于等于6时,红黑树结构还原成链表,数组和链表的节点的实现类是Node类
剖析:
1.红黑树是解决链表查询出现的O(n)情况,那么为什么不用其他树呢?
如平衡二叉树等,我们通过以下二方面分析:
平均插入效率:链表>红黑树>平衡二叉树
平均查询效率:平衡二叉树>红黑树>链表
可以看出红黑树介于二者之间,hashMap作为各种操作频繁的容器,自然选择综合性能较好的红黑树
2.为什么阈值是6和8呢?
1.为什么8转红黑树?
红黑树的平均查找次数是log2(n),
长度为8时:
红黑树平均查找次数为3,链表平均查找长度为8/2=4,此时选择红黑树优
长度为4为:
红黑树平均查找次数为2,链表平均长度为4/2=2,此时次数一样,红黑树开销大
至于567我们在这没有讨论的必要
2.为什么6转回链表?
若选择7,在7和8链表之间的增删元素,必然会导致频繁进行链表和红黑树的转换
6.2 Hash值的计算区别
-
JDK7:
h^ =(h>>>20)^(h>>>12) return h ^(h>>>7) ^(h>>>4) -
JDK8:
(key==null)?0:(h=key.hashCode())^(h>>>16)
剖析:
jdk7中因为要保持hash函数的散列性,所以进行了多次的异或和位运算而,
8中因为链表长度超过等于8会转红黑树,所以我们可以稍微减少元素的散列性,
从而避免很多异或和位运算操作
6.2 链表数据插入的区别
-
JDK7:使用的是头插入法,扩容后与原位置相反(resize会导致环形链表)
-
JDK8:使用的尾插法,扩容后位置与原链表相同
剖析:
jdk7插入链表头部,因为这样无需遍历链表(需要判断是否为尾部,然后插入尾部),可以直接插入头部
jdk8中插入元素时,要判断个数是否需要构造红黑树,这样已存在了遍历, 所以插入尾部方便,
并且解决了jdk7中头插法导致的环状链表问题
6.2 扩容机制的不同
- JDK7扩容条件:元素个数 > 容量(16) * 加载因子 (0.75) && 插入的数组位置有元素存在
- JDK8扩容条件 :元素个数 > 容量 (16) * 加载因子(0.75)
剖析:
虽然都是进行2倍扩容,但是JDK1.7中扩容的时候,重新计算位置,
JDk8则不会,只要看看原hash值新增的那个bit位是1还是0就好了,是0的话索引没有变,
是1的话索引变成“原索引+oldCap(旧数组大小)
7. Hashtable的实现原理
Hashtable类似HashMap,使用hash表来存储键值对。hash表定义:根据设定的hash函数和处理冲突的方式(开放定址、公共溢出区、链地址、重哈希…)将一组关键字映射到一个有限的连续的地址集上(即bucket数组或桶数组),并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表称为hash表。
hash冲突发生时,通过“链表法”或叫"拉链法"来处理冲突,即通过一个链表存储键值对(Map.Entry)。每个Entry对象都有next指针用于指向下一个具有相同hashcode值的Entry。
8. HashSet的实现原理
HashSet是通过HashMap实现的,只是使用了HashMap的键,没有使用HashMap的值。
hashCode(),哈希值,HashSet的元素会根据哈希值存储,哈希值一样的元素会存储在同一个区域,也叫桶原理(bucket),这也查找起来效率会高很多
但是在元素被添加进HashSet集合后,修改元素中参与计算哈希值的属性,再调用remove()方法时不起作用,会导致内存泄露






![java八股文面试[数据结构]——HashMap扩容优化](https://img-blog.csdnimg.cn/ece8edc470414f35a7a90b9d77d6ac28.png)