背景
未来曜文有接入市场上所有面向chatGPT开发的应用,例如开源聊天组件,西部小镇等
内容介绍
- 生成代理起床,做早餐,然后去上班;艺术家作画,作家写作;他们形成意见、互相关注并发起对话;
- 他们在计划第二天时会记住并反思过去的日子。
- 为了实现生成代理,描述了一种架构,该架构扩展了大型语言模型,以使用自然语言存储代理经验的完整记录,随着时间的推移将这些记忆合成为更高级别的反射,并动态检索它们以规划行为。
- 实例化生成代理来填充受《模拟人生》启发的交互式沙箱环境,最终用户可以使用自然语言与一个由 25 个代理组成的小镇进行交互。在评估中,这些生成代理会产生可信的个人和紧急社交行为:例如,从一个用户指定的单一想法开始,即一个代理想要举办情人节派对,代理在接下来的两个时间里自主地传播派对邀请几天,结识新朋友,互相约出参加聚会的日期,并协调在正确的时间一起出现在聚会上。我们通过消融证明,我们的代理架构的组成部分——观察、规划和反思——每一个都对代理行为的可信度做出了至关重要的贡献
- 该AI应用的价值在于我们有GPT的能力,很吸引眼球,不具有实际产品价值,更像是一种构想
- 但是架构思路值得参考,可以将思路延申到实际业务场景,例如构建面试准备,用户可以安全地排练困难的、充满冲突的对话
部署
基础
代码仓库:https://github.com/joonspk-research/generative_agents
论文地址:https://arxiv.org/pdf/2304.03442.pdf
语言:javascript/python3.9
框架:Bootstrap/django/openai
设置环境
要设置您的环境,您需要生成一个utils.py包含 OpenAI API 密钥的文件并下载必要的软件包。
步骤1.生成Utils文件
在reverie/backend_server文件夹(所在reverie.py位置)中,创建一个名为的新文件utils.py,并将以下内容复制并粘贴到该文件中:
openai_api_key = "sk-xxx"
openai_api_base = "http://10.9.115.77:50000/v1" # 零时添加的
# Put your name
key_owner = "<jack>"
maze_assets_loc = "../../environment/frontend_server/static_dirs/assets"
env_matrix = f"{maze_assets_loc}/the_ville/matrix"
env_visuals = f"{maze_assets_loc}/the_ville/visuals"
fs_storage = "../../environment/frontend_server/storage"
fs_temp_storage = "../../environment/frontend_server/temp_storage"
collision_block_id = "32125"
# Verbose
debug = True
替换为您的 OpenAI API 密钥和您的姓名。
步骤2.安装requirements.txt
安装requirements.txt文件中列出的所有内容(我强烈建议首先像往常一样设置 virtualenv)。关于 Python 版本的说明:我们在 Python 3.9.12 上测试了我们的环境。
- 构建镜像
# Use the specified Python version
FROM python:3.9.12
RUN echo "deb https://mirrors.aliyun.com/debian/ buster main contrib non-free" > /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ buster-updates main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ buster-backports main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian-security/ buster/updates main contrib non-free" >> /etc/apt/sources.list
# Install supervisor to manage multiple processes
RUN apt-get update && apt-get install -y supervisor
# Set the working directory
WORKDIR /app
# Copy the requirements.txt file into the container
COPY requirements.txt ./
# Install the Python dependencies from requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the entire application (both environment and backend server)
COPY . /app
# Create a supervisor configuration file
RUN echo '[supervisord]' > /etc/supervisor/conf.d/supervisord.conf && \
echo 'nodaemon=true' >> /etc/supervisor/conf.d/supervisord.conf && \
echo '[program:environment_server]' >> /etc/supervisor/conf.d/supervisord.conf && \
echo 'command=python environment/frontend_server/manage.py runserver 0.0.0.0:8000' >> /etc/supervisor/conf.d/supervisord.conf && \
echo '[program:simulation_server]' >> /etc/supervisor/conf.d/supervisord.conf && \
echo 'command=python reverie/backend_server/reverie.py' >> /etc/supervisor/conf.d/supervisord.conf
# Expose the port the environment server will run on
EXPOSE 8000
# Start supervisor, which will manage both the environment server and the simulation server
CMD ["/usr/bin/supervisord", "-c", "/etc/supervisor/conf.d/supervisord.conf"]
运行模拟
要运行新的模拟,您需要同时启动两个服务器:环境服务器和代理模拟服务器。
步骤1.启动环境服务器
-
同样,该环境是作为 Django 项目实现的,因此,您需要启动 Django 服务器。为此,首先导航到命令行environment/frontend_server(这是所在位置)。manage.py然后运行以下命令:
-
python manage.py runserver 0.0.0.0:8000
-
然后,在您最喜欢的浏览器上,转到http://localhost:8000/。如果您看到一条消息“您的环境服务器已启动并正在运行”,则表明您的服务器运行正常。确保环境服务器在运行模拟时继续运行,因此请保持此命令行选项卡打开!(注意:我建议使用 Chrome 或 Safari。Firefox 可能会产生一些前端故障,尽管它不应该干扰实际的模拟。)
步骤 2. 启动模拟服务器
-
打开另一个命令行(您在步骤 1 中使用的命令行应该仍在运行环境服务器,因此请保持原样)。导航到reverie/backend_server并运行reverie.py.
python reverie.py -
这将启动模拟服务器。将出现命令行提示,询问以下内容:“输入分叉模拟的名称:”。要与 Isabella Rodriguez、Maria Lopez 和 Klaus Mueller 启动 3 代理模拟,请输入以下内容:
base_the_ville_isabella_maria_klaus -
然后提示将询问“输入新模拟的名称:”。输入任何名称来表示您当前的模拟(例如,现在只需“测试模拟”即可)。
test-simulation
保持模拟器服务器运行。此时会显示如下提示:“输入选项:”
步骤 3. 运行并保存模拟
在浏览器上,导航到http://localhost:8000/simulator_home。您应该会看到超人前传的地图,以及地图上的活跃特工列表。您可以使用键盘箭头在地图上移动。请保持此选项卡打开。要运行模拟,请在模拟服务器中键入以下命令以响应提示“输入选项”:
run
备注
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
if not text:
text = "this is blank"
return [-0.006929283495992422, -0.005336422007530928] # chatglm暂时没有支持该接口,多以暂时替换写死
return openai.Embedding.create(
input=[text], model=model)['data'][0]['embedding']
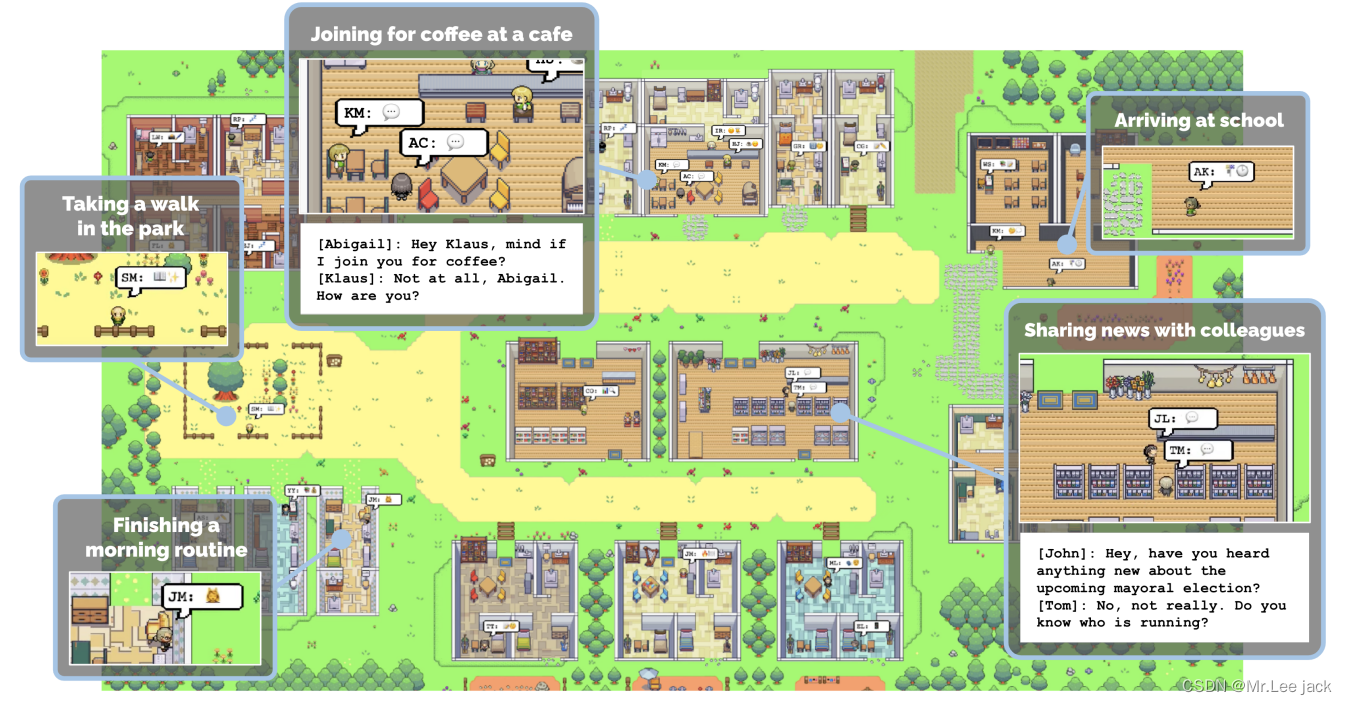
部署效果

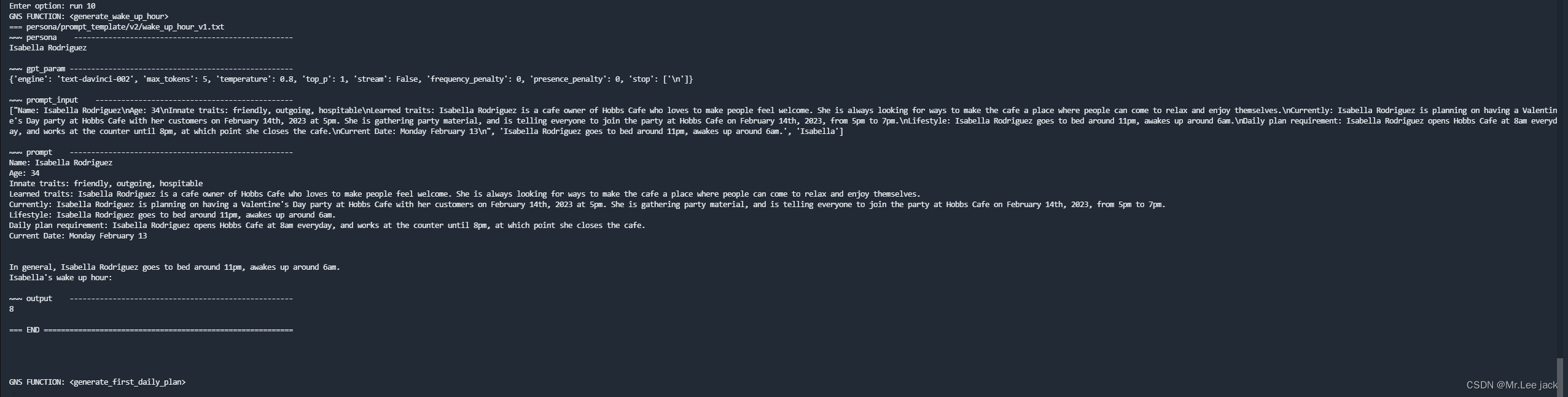
原理
总结论文贡献
In sum, this paper makes the following contributions:
• Generative agents, believable simulacra of human behavior
that are dynamically conditioned on agents’ changing experiences and environment. 生成型智能体
• A novel architecture that makes it possible for generative
agents to remember, retrieve, reflect, interact with other
agents, and plan through dynamically evolving circumstances.
The architecture leverages the powerful prompting capabilities of large language models and supplements those capabilities to support longer-term agent coherence, the ability
to manage dynamically evolving memory, and recursively
produce higher-level reflections. 一种新颖的架构,使生成代理能够记忆,检索,反映,与其他代理交互,并通过动态发展的环境进行计划
• Two evaluations, a controlled evaluation and an end-to-end
evaluation, that establish causal effects of the importance
of components of the architecture, as well as identify breakdowns arising from, e.g., improper memory retrieval. 两个评估,一个受控的评估和一个端到端评估,它们建立了体系结构组件重要性的因果关系,以及识别由不适当的内存检索引起的故障。
• Discussion of the opportunities and ethical and societal risks
of generative agents in interactive systems. We argue that
these agents should be tuned to mitigate the risk of users
forming parasocial relationships, logged to mitigate risks
stemming from deepfakes and tailored persuasion, and applied in ways that complement rath 生成代理的机会和伦理及社会风险
论文解读
代理角色和角色间的交流
Smallville中有25个独特的代理居民社区。每个代理都由一个简单的精灵形象代表。我们编写了一个自然语言段落来描述每个代理的身份,包括他们的职业和与其他代理的关系,作为种子记忆。例如,John Lin的描述如下
John Lin is a pharmacy shopkeeper at the Willow
Market and Pharmacy who loves to help people. He
is always looking for ways to make the process
of getting medication easier for his customers;
John Lin is living with his wife, Mei Lin, who
is a college professor, and son, Eddy Lin, who is
a student studying music theory; John Lin loves
his family very much; John Lin has known the old
couple next-door, Sam Moore and Jennifer Moore,
for a few years; John Lin thinks Sam Moore is a
kind and nice man; John Lin knows his neighbor,
Yuriko Yamamoto, well; John Lin knows of his
neighbors, Tamara Taylor and Carmen Ortiz, but
has not met them before; John Lin and Tom Moreno
are colleagues at The Willows Market and Pharmacy;
John Lin and Tom Moreno are friends and like to
discuss local politics together; John Lin knows
the Moreno family somewhat well — the husband Tom
Moreno and the wife Jane Moreno.
John Lin是Willow市场和药店的一名药店店主,他热爱帮助人们。他总是在寻找让顾客获得药物更加便捷的方式;John Lin与妻子Mei Lin和儿子Eddy Lin一起生活,Mei Lin是一名大学教授,Eddy Lin正在学习音乐理论;John Lin非常爱他的家人;John Lin认识隔壁老夫妇Sam Moore和Jennifer Moore已经有几年了;John Lin认为Sam Moore是个善良友好的人;John Lin很熟悉他的邻居Yuriko Yamamoto;John Lin知道他的邻居Tamara Taylor和Carmen Ortiz,但没有见过他们;John Lin和Tom Moreno是Willows市场和药店的同事;John Lin和Tom Moreno是朋友,喜欢一起讨论当地政治;John Lin对Moreno家庭有一定的了解——丈夫Tom Moreno和妻子Jane Moreno
代理角色之间的交流
代理通过它们的行动与世界互动,并通过自然语言与彼此互动。在沙盒引擎的每个时间步骤中,代理会输出一个自然语言语句,描述它们当前的行动,例如“Isabella Rodriguez正在写她的日记”、“Isabella Rodriguez正在查看她的电子邮件”、“Isabella Rodriguez正在和她的家人通电话”或“Isabella Rodriguez正在准备睡觉”。然后,这个语句被翻译成影响沙盒世界的具体动作。该动作在沙盒界面上显示为一组表情符号,提供了一个俯视图中行动的抽象表示。为了实现这一点,系统采用了一个语言模型将行动翻译成一组表情符号,出现在每个代理的话泡中。例如,“Isabella Rodriguez正在写她的日记”显示为📝,而“Isabella Rodriguez正在查看她的电子邮件”则显示为📧。通过点击代理人物,可以访问行动的完整自然语言描述
Isabella: 我还在权衡利弊,但是我和Sam Moore讨论了选举。你对他有什么看法?
Tom: 说实话,我不喜欢Sam Moore。我认为他与社区脱节,不把我们的利益放在心上
与环境的交互
- Smallville拥有一个小村庄普遍具备的设施,包括咖啡馆、酒吧、公园、学校、宿舍、房屋和商店。它还定义了子区域和对象,使这些空间具有功能性,例如房子里的厨房和厨房里的炉子。所有作为代理人主要居住地的空间都配备了床、桌子、衣柜、架子、浴室和厨房
- 用户和代理人可以像在沙盒游戏The Sims中那样影响这个世界中的物体状态。例如,当代理人在睡觉时,床会被占用,当代理人用完材料做早餐时,冰箱会变空。最终用户还可以通过自然语言重写代理人周围物体的状态来重新塑造Smallville中代理人的环境。例如,在早上Isabella在做早餐时,用户可以通过输入指令来将厨房炉子的状态从“开启”更改为“着火”,如下所示:“<Isabella的公寓:厨房:炉子>正在燃烧。” Isabella会在下一刻注意到这一点,然后去关闭炉子并重新制作自己的早餐。同样,如果用户在Isabella进入浴室时将淋浴头的状态设置为“漏水”,她会从客厅拿出工具来修理漏水
例子:生活中的一天
- 从单段描述开始,代理人开始计划他们的一天。随着时间在沙盒世界中流逝,他们的行为随着这些代理人彼此交互和与世界互动、建立记忆和关系以及协调联合活动而不断演变
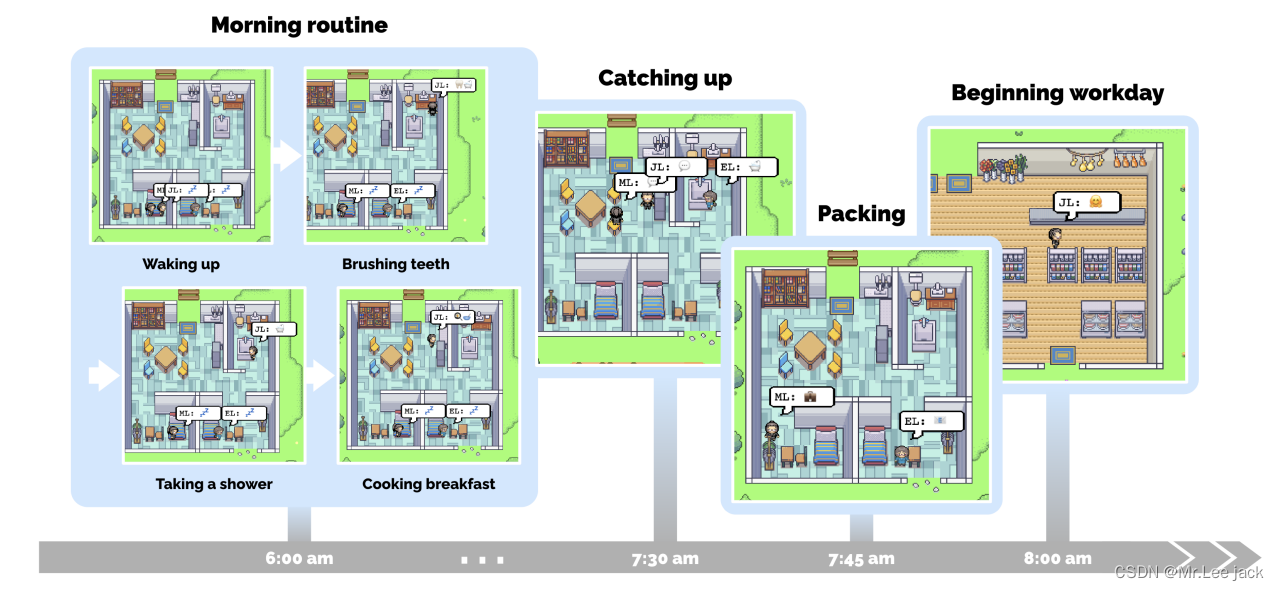
- 一位生成式角色John Lin的一天。约翰早上6点左右醒来,完成他的早晨常规活动,包括刷牙、淋浴和吃早餐。他简短地与妻子Mei和儿子Eddy交流后,便出门开始他的工作日。我们通过在代理人John Lin上演示生成型代理人的行为来跟踪系统输出的过程(图3)。在林家中,约翰是第一个在早上7点醒来的人。他刷牙、洗澡、穿衣服、吃早餐,并在客厅的餐桌上查看新闻。在早上8点,Eddy紧随其后,匆忙从床上起来准备上课。他追上约翰,就在他准备出门时:
约翰:早上好,Eddy。你睡得好吗?
Eddy:早上好,爸爸。是的,我睡得很好。
约翰:太好了。你今天在做什么?
Eddy:我正在为我的课程创作一首新的音乐作品。它要在本周交作业,所以我正在努力完成它。但我觉得做这个很有趣!
约翰:听起来很不错!
- 不久之后,Eddy出门了,梅醒来并加入了约翰的谈话。梅问起她的儿子,约翰回忆起他们刚刚的谈话:
梅:Eddy已经去上学了吗?
约翰:是的,他刚刚离开。他正在为他的课程创作一首音乐作品。
梅:哦,太棒了!告诉我详情。
约翰:我想他非常喜欢这个!他说他做这个很开心。
梅:太好了!我为他感到骄傲。
- 随着他们结束了谈话,梅和约翰开始准备。梅去教课并写研究论文,而约翰在上午9点前在Willow Market和Pharmacy开设他的药房柜台。
突发的社会行为
- 通过彼此互动,Smallville中的生成型角色交换信息、建立新的关系并协调联合活动。扩展之前的工作[79],这些社交行为是突发的,而不是预先编程的
- 例如预先设置好的计划,也可能发生变化
信息扩散
当代理人注意到彼此时,他们可能会进行对话 - 在这样做时,信息可以从一个代理人传播到另一个代理人。例如,在杂货店的Sam和Tom之间的对话中,Sam告诉Tom他参加了当地选举的候选资格:
Sam:嘿,Tom,最近怎么样?
Tom:不错,谢谢。有什么事吗?
Sam:嗯,我想和你谈谈某件事。事实上,我正在参加即将到来的地方选举,竞选市长。
Tom:真的吗?太好了!你为什么要竞选?
Sam:我已经参与本地政治多年,我真的觉得我可以改变我们的社区。另外,我还想给大家带来新的想法和观点
- 那天晚些时候,当Sam离开后,从另一个消息来源得知了这个消息的Tom和John讨论了Sam赢得选举的机会。
John: 我听说Sam Moore参加了本地选举竞选市长。你觉得他赢得选举的机会大吗?
Tom: 我认为他有很大机会。他一直在社区努力工作,我认为他会得到很多支持。你觉得呢?
John: 我认为他参选很棒。我很好奇还有谁在竞选,选举最后会是怎样的结果。
- 渐渐地,Sam的候选人资格成为了镇上的话题,一些人支持他,另一些人仍未决定
关系记忆
Smallville中的智能体随着时间形成新的关系,并记住他们与其他智能体的互动。例如,Sam一开始不认识Latoya Williams。在Johnson公园散步时,Sam遇到了Latoya,他们互相介绍,并且Latoya提到她正在进行一个摄影项目:“我在这里拍一些照片,是我正在做的一个项目。”在之后的互动中,Sam与Latoya的互动表明了对那次互动的记忆,他问道“嗨,Latoya,你的项目进展如何?”她回答:“嗨,Sam,进展得很好!”
协调
生成式智能体角色互相协调。在霍布斯咖啡馆,Isabella Rodriguez打算在2月14日的下午5点到7点举办情人节派对。从这个种子开始,智能体开始在霍布斯咖啡馆或其他地方邀请朋友和顾客参加派对。然后,Isabella在13日下午装饰咖啡馆,为派对做准备。Maria是Isabella的亲密朋友和常客,她来到了咖啡馆。Isabella请求Maria帮助她为派对做装饰,而Maria同意了。Maria的角色描述提到她喜欢Klaus。当晚,Maria邀请她的暗恋对象Klaus参加派对,而他很高兴地接受了邀请。
情人节当天下午5点,包括Klaus和Maria在内的五个智能体角色来到霍布斯咖啡馆,享受派对的氛围。在这种情况下,最终用户只设置了Isabella举办派对的初始意图和Maria对Klaus的暗恋,社交行为(传播消息、装饰、邀请、到达派对并在派对上互动)是由智能体架构发起的。
生成式智能体架构
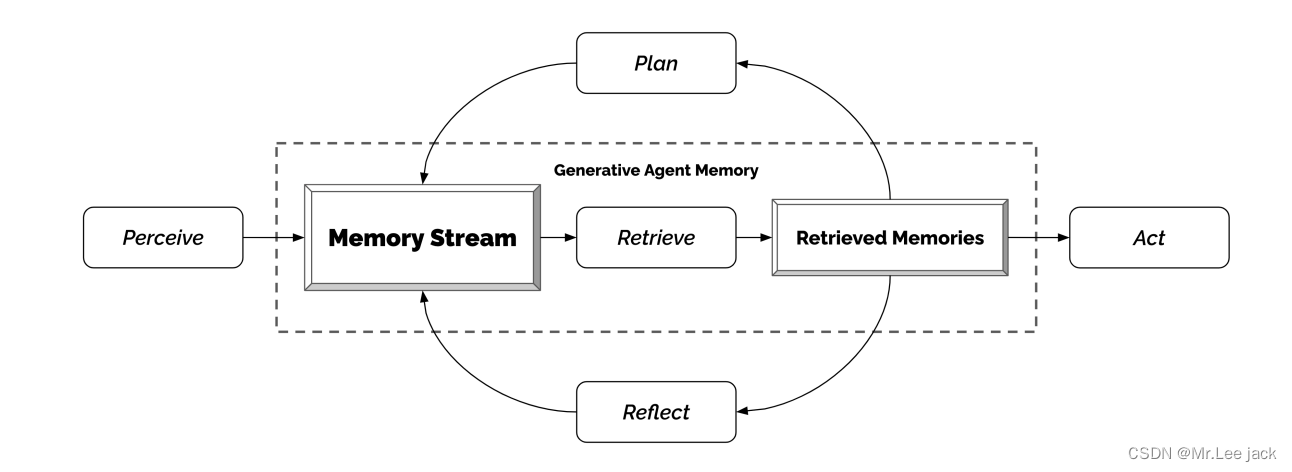
整体结构:如上图,智能体感知(perceive,比如小明在花园散步、小红7点吃了早餐)环境,所有感知都被保存在智能体经验的综合记录中,称为记忆流(memory stream)。基于它们的感知,智能体检索(retrieve)相关的记忆(retrieved memories),然后使用这些检索到的记忆来确定一个行为(act,比如做早餐)。这些检索到的记忆也被用来形成长期计划(plan,比如明天的计划),并产生更高层次的反思(reflect),这些都被输入到记忆流中以备将来使用。act、plan和reflect是通过提示大语言模型获得的结果
是不是有点知识库的感觉
Memory好比人的大脑一样
记忆和检索

通过Recency、Importance、Relevance三个维度来计算score,给每条记忆打分。用得分高的记忆来构建prompt。

Recency: 给最近访问过的内存对象赋一个更高的分数
Importance 通过给agent认为重要的内存对象分配更高的分数来区分普通记忆和核心记忆。例如,在房间里吃早餐这样的普通事件的重要性得分很低,而与另一半分手的重要性得分很高
Relevance : 我们使用语言模型来生成每个内存的文本描述的嵌入向量,通过向量计算相关程度,计算相关性,作为记忆的嵌入向量和查询记忆的嵌入向量之间的余弦相似度
反思
当只有原始的观察记忆时,生成式智能体很难进行泛化或推理。考虑这样一种情况,用户问Klaus Mueller:“如果你必须选择一个你认识的人与之共度一小时,你会选择谁?”只有观察性记忆的智能体只会选择和Klaus互动最频繁的人:他的大学宿舍邻居Wolfgang。不幸的是,Wolfgang和Klaus只是偶尔擦肩而过,没有深入的交流。更理想的回答需要智能体从Klaus在研究项目上花费的时间的记忆中进行泛化,生成一个更高层次的反思,即Klaus对研究充满热情,同时也能够认识到Maria在自己的研究中付出了努力(尽管在不同的领域),从而产生一个反思,即他们有共同的兴趣爱好。通过以下方法,当问及Klaus要和谁共度时光时,Klaus选择Maria而不是Wolfgang

对话原理
智能体在彼此互动时进行对话。我们通过智能体对彼此的记忆来生成他们的对话
[智能体概述描述]
现在是2023年2月13日下午4:56。
约翰·林的状态:约翰提前下班回到家。
观察结果:约翰看到Eddy在他的工作场所周围散步。
从约翰的记忆中总结相关的背景信息:
Eddy Lin是约翰的儿子。Eddy Lin正在为他的课程作曲。Eddy Lin喜欢在思考或听音乐时在花园里散步。
约翰正在询问Eddy关于他的作曲项目。他会对Eddy说什么?
结果是:“嘿,Eddy,你为课程的作曲项目进展如何?”从Eddy的角度来看,John开始对话被视为一个他可能想要做出反应的事件。因此,就像John一样,Eddy检索并总结了他与John的关系以及与John在对话中的最后一句话可能相关的记忆。如果他决定回应,我们将使用他总结的记忆和当前的对话历史来生成Eddy的话语:
[智能体概述描述]
现在是2023年2月13日下午4:56。
Eddy Lin的状态:Eddy正在他的工作场所周围散步。
观察结果:John正在与Eddy开始对话。
从Eddy的记忆中总结相关的背景信息:
John Lin是Eddy Lin的父亲。John Lin很关心Eddy Lin的学校工作,并且对了解更多。John Lin知道Eddy Lin正在进行一项音乐作曲。
以下是对话历史记录:
John: 嘿,Eddy,你为课程的作曲项目进展如何?
Eddy会如何回应John?
这将生成Eddy的回应:“嘿,爸爸,进展得很顺利。我一直在花园里散步,以便放松大脑并获得一些灵感。”使用相同的机制生成对话的继续,直到两个智能体中的一个决定结束对话。
从结构化的世界环境到自然语言,再回到结构化的世界环境
- 反应大语言模型结构化能力,目前国内大模型还无法满足
伦理和社会影响
- 风险:本身虚拟世界的社交就是错误的影响
- 风险:生成代理可能加剧与生成人工智能相关的现有风险,例如深度伪造、虚假信息生成和定制诱导
- 风险:过度依赖,开发人员或设计师可能会使用生成代理,从而取代人类和系统利益相关者在设计过程中的作用
代码解读
"""
File: gpt_structure.py
Description: Wrapper functions for calling OpenAI APIs.
"""
import json
import random
import openai
import time
from utils import *
openai.api_key = openai_api_key
openai.api_base = openai_api_base
def temp_sleep(seconds=0.1):
time.sleep(seconds)
def ChatGPT_single_request(prompt):
temp_sleep()
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return completion["choices"][0]["message"]["content"]
# ============================================================================
# #####################[SECTION 1: CHATGPT-3 STRUCTURE] ######################
# ============================================================================
def GPT4_request(prompt):
"""
Given a prompt and a dictionary of GPT parameters, make a request to OpenAI
server and returns the response.
ARGS:
prompt: a str prompt
gpt_parameter: a python dictionary with the keys indicating the names of
the parameter and the values indicating the parameter
values.
RETURNS:
a str of GPT-3's response.
"""
temp_sleep()
try:
completion = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return completion["choices"][0]["message"]["content"]
except:
print("ChatGPT ERROR")
return "ChatGPT ERROR"
def ChatGPT_request(prompt):
"""
Given a prompt and a dictionary of GPT parameters, make a request to OpenAI
server and returns the response.
ARGS:
prompt: a str prompt
gpt_parameter: a python dictionary with the keys indicating the names of
the parameter and the values indicating the parameter
values.
RETURNS:
a str of GPT-3's response.
"""
# temp_sleep()
try:
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return completion["choices"][0]["message"]["content"]
except:
print("ChatGPT ERROR")
return "ChatGPT ERROR"
def GPT4_safe_generate_response(prompt,
example_output,
special_instruction,
repeat=3,
fail_safe_response="error",
func_validate=None,
func_clean_up=None,
verbose=False):
prompt = 'GPT-3 Prompt:\n"""\n' + prompt + '\n"""\n'
prompt += f"Output the response to the prompt above in json. {special_instruction}\n"
prompt += "Example output json:\n"
prompt += '{"output": "' + str(example_output) + '"}'
if verbose:
print("CHAT GPT PROMPT")
print(prompt)
for i in range(repeat):
try:
curr_gpt_response = GPT4_request(prompt).strip()
end_index = curr_gpt_response.rfind('}') + 1
curr_gpt_response = curr_gpt_response[:end_index]
curr_gpt_response = json.loads(curr_gpt_response)["output"]
if func_validate(curr_gpt_response, prompt=prompt):
return func_clean_up(curr_gpt_response, prompt=prompt)
if verbose:
print("---- repeat count: \n", i, curr_gpt_response)
print(curr_gpt_response)
print("~~~~")
except:
pass
return False
def ChatGPT_safe_generate_response(prompt,
example_output,
special_instruction,
repeat=3,
fail_safe_response="error",
func_validate=None,
func_clean_up=None,
verbose=False):
# prompt = 'GPT-3 Prompt:\n"""\n' + prompt + '\n"""\n'
prompt = '"""\n' + prompt + '\n"""\n'
prompt += f"Output the response to the prompt above in json. {special_instruction}\n"
prompt += "Example output json:\n"
prompt += '{"output": "' + str(example_output) + '"}'
if verbose:
print("CHAT GPT PROMPT")
print(prompt)
for i in range(repeat):
try:
curr_gpt_response = ChatGPT_request(prompt).strip()
end_index = curr_gpt_response.rfind('}') + 1
curr_gpt_response = curr_gpt_response[:end_index]
curr_gpt_response = json.loads(curr_gpt_response)["output"]
# print ("---ashdfaf")
# print (curr_gpt_response)
# print ("000asdfhia")
if func_validate(curr_gpt_response, prompt=prompt):
return func_clean_up(curr_gpt_response, prompt=prompt)
if verbose:
print("---- repeat count: \n", i, curr_gpt_response)
print(curr_gpt_response)
print("~~~~")
except:
pass
return False
def ChatGPT_safe_generate_response_OLD(prompt,
repeat=3,
fail_safe_response="error",
func_validate=None,
func_clean_up=None,
verbose=False):
if verbose:
print("CHAT GPT PROMPT")
print(prompt)
for i in range(repeat):
try:
curr_gpt_response = ChatGPT_request(prompt).strip()
if func_validate(curr_gpt_response, prompt=prompt):
return func_clean_up(curr_gpt_response, prompt=prompt)
if verbose:
print(f"---- repeat count: {i}")
print(curr_gpt_response)
print("~~~~")
except:
pass
print("FAIL SAFE TRIGGERED")
return fail_safe_response
# ============================================================================
# ###################[SECTION 2: ORIGINAL GPT-3 STRUCTURE] ###################
# ============================================================================
def GPT_request(prompt, gpt_parameter):
"""
Given a prompt and a dictionary of GPT parameters, make a request to OpenAI
server and returns the response.
ARGS:
prompt: a str prompt
gpt_parameter: a python dictionary with the keys indicating the names of
the parameter and the values indicating the parameter
values.
RETURNS:
a str of GPT-3's response.
"""
temp_sleep()
try:
response = openai.Completion.create(
model=gpt_parameter["engine"],
prompt=prompt,
temperature=gpt_parameter["temperature"],
max_tokens=gpt_parameter["max_tokens"],
top_p=gpt_parameter["top_p"],
frequency_penalty=gpt_parameter["frequency_penalty"],
presence_penalty=gpt_parameter["presence_penalty"],
stream=gpt_parameter["stream"],
stop=gpt_parameter["stop"], )
return response.choices[0].text
except:
print("TOKEN LIMIT EXCEEDED")
return "TOKEN LIMIT EXCEEDED"
def generate_prompt(curr_input, prompt_lib_file):
"""
Takes in the current input (e.g. comment that you want to classifiy) and
the path to a prompt file. The prompt file contains the raw str prompt that
will be used, which contains the following substr: !<INPUT>! -- this
function replaces this substr with the actual curr_input to produce the
final promopt that will be sent to the GPT3 server.
ARGS:
curr_input: the input we want to feed in (IF THERE ARE MORE THAN ONE
INPUT, THIS CAN BE A LIST.)
prompt_lib_file: the path to the promopt file.
RETURNS:
a str prompt that will be sent to OpenAI's GPT server.
"""
if type(curr_input) == type("string"):
curr_input = [curr_input]
curr_input = [str(i) for i in curr_input]
f = open(prompt_lib_file, "r")
prompt = f.read()
f.close()
for count, i in enumerate(curr_input):
prompt = prompt.replace(f"!<INPUT {count}>!", i)
if "<commentblockmarker>###</commentblockmarker>" in prompt:
prompt = prompt.split("<commentblockmarker>###</commentblockmarker>")[1]
return prompt.strip()
def safe_generate_response(prompt,
gpt_parameter,
repeat=5,
fail_safe_response="error",
func_validate=None,
func_clean_up=None,
verbose=False):
if verbose:
print(prompt)
for i in range(repeat):
curr_gpt_response = GPT_request(prompt, gpt_parameter)
if func_validate(curr_gpt_response, prompt=prompt):
return func_clean_up(curr_gpt_response, prompt=prompt)
if verbose:
print("---- repeat count: ", i, curr_gpt_response)
print(curr_gpt_response)
print("~~~~")
return fail_safe_response
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
if not text:
text = "this is blank"
return [-0.006929283495992422, -0.005336422007530928]
return openai.Embedding.create(
input=[text], model=model)['data'][0]['embedding']
if __name__ == '__main__':
gpt_parameter = {"engine": "text-davinci-003", "max_tokens": 50,
"temperature": 0, "top_p": 1, "stream": False,
"frequency_penalty": 0, "presence_penalty": 0,
"stop": ['"']}
curr_input = ["driving to a friend's house"]
prompt_lib_file = "prompt_template/test_prompt_July5.txt"
prompt = generate_prompt(curr_input, prompt_lib_file)
def __func_validate(gpt_response):
if len(gpt_response.strip()) <= 1:
return False
if len(gpt_response.strip().split(" ")) > 1:
return False
return True
def __func_clean_up(gpt_response):
cleaned_response = gpt_response.strip()
return cleaned_response
output = safe_generate_response(prompt,
gpt_parameter,
5,
"rest",
__func_validate,
__func_clean_up,
True)
print(output)
- 代码块中主要使用chatgpt中大模型格式化数据的能力进行指令汇总,一般模型不具有这种能力