一、说明
二、介绍
“两条路在一片树林里分道扬镳,我走了一条人迹罕至的路,这让一切都变得不同了。
罗伯特·弗罗斯特(Robert Frost)的诗《未走的路》(The Road Not Take)就是这样一句话。这首诗雄辩地描述了一个人的决定如何对他们的生活产生持久的影响。决定不是我们生活中不可或缺的一部分吗?我们走的道路和做出的决定极大地影响着我们的命运和身份。
决策树算法就像这首诗,展示了决策如何在树中创建新分支;同样,一个小决定可以创造不同的路线并改变我们的生活。
对决策树最基本的理解是,它是一个嵌套的if-else语句的巨大结构。
这是一个包含 6 行和 3 列的小型分类数据集,我们将尝试使用嵌套的 if-else 语句来解决,如下所示:
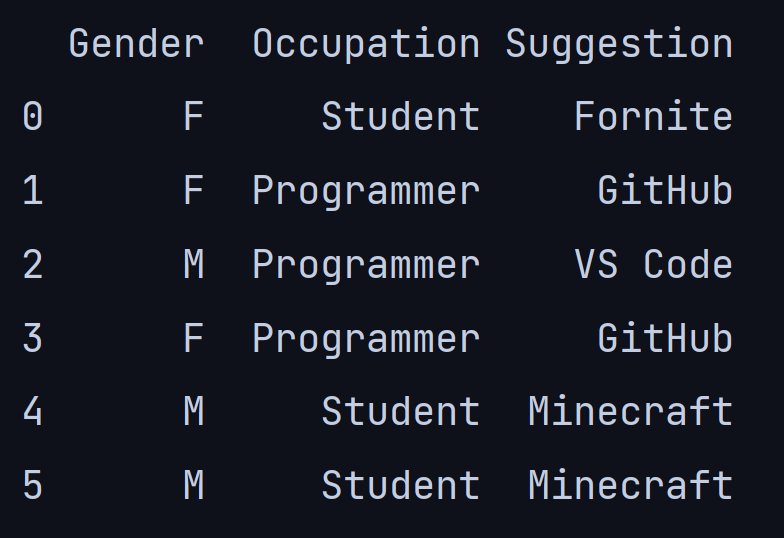
g = input("Enter gender(M/F): ")
print("Occupation: ")
print("1-> Student")
print("2-> Programmer")
o = int(input("Enter occupation: " ))
if g=='F':
if o==1:
print('Fortnite')
elif o==2:
print('GitHub')
elif g=='M':
if o==1:
print('Minecraft')
elif o==2:
print('VS Code')我问自己的第一个问题是,如果决策树只是用于解决问题的if-else语句的集合,那么为什么我们需要决策树?答案是:
- if-else 语句可能很脆弱,这意味着它们很容易受到数据中微小变化的影响。另一方面,决策树对数据的变化更可靠。
- if-else 语句的可扩展性不如决策树,这意味着它们在大型数据集上的训练和预测速度可能很慢。
- if-else 语句的解释和调试可能具有挑战性。另一方面,决策树是表示决策规则的一种更直观、更直观的方法。
从图表上看,这将如下所示:

2.1 与树数据结构相关的基本术语如下:
- 根节点:根节点是最顶层的节点。它是产生决策树的起始节点。
- 父节点:父节点是具有一个或多个子节点的节点。
- 子节点:子节点是从父节点分支出来的节点。父节点是做出决策的节点,子节点是表示该决策的可能结果的节点。
- 叶节点:决策树中的叶节点是没有任何子节点的节点。叶节点表示决策树的终端节点,它们包含模型的最终预测。
- 分裂:将节点划分为两个或多个子节点的过程。
- 修剪: 修剪与拆分相反。删除决策节点的子节点的过程称为修剪。
2.2 什么是决策树算法?
决策树是一种监督学习算法,它使用树状结构根据输入数据做出决策。它将数据划分为分支,并将结果分配给叶节点。
决策树用于分类和回归任务,提供高效、准确和易于理解的模型。
不同的库使用不同的算法来执行决策树,但在本文中,我们将讨论 CART:分类和回归树。
CART 是一种递归算法,它从树的根节点开始,并根据单个特征的值将数据拆分为两个或多个子集。重复该过程,直到每个子集都是纯的,这意味着子组中的所有数据点都属于同一类。
购物车使用各种杂质度量,例如熵和基尼杂质,来决定在每个节点上拆分哪个特征。
从数学上讲,决策树使用平行于任何一个轴的超平面将我们的坐标系切割成超长方体。
2.3 为什么我们在机器学习中需要决策树?
- 易于理解和解释,这有助于开发人员调试和理解模型。
- 抗噪声意味着决策树可以相对较好地处理噪声数据,使其成为数据不完全干净的问题的不错选择。
- 决策树训练高效且灵活。
- 决策树广泛用于信用评分、欺诈检测、医疗诊断、客户细分等。
三、与 CART 算法相关的一些关键概念是:
- 熵
- 信息获取
- 基尼指数
熵,信息增益和基尼杂质是决策树算法中的三个基本概念。它们用于测量数据的杂质并确定将数据拆分到哪个特征上。决策树算法用于使用这些概念构建准确可靠的模型。
3.1. 熵:
熵是不纯或无序的量度。简单来说,它是随机性的度量。
熵帮助我们识别预测目标变量的最重要特征。它有助于减少数据的杂质,从而使模型更加准确。熵的公式如下:

![]()
- P 是:是的概率
- P 否:否的概率
- E: 熵
熵的一些基本观察如下:
- 对于 2 类问题(“是”或“否”/“真”或“假”),最小熵为 0,最大熵为 1。
- 对于两个以上的类,最小熵为 0,但最大值可以大于 1。
- 杂质为0的数据集对学习没有帮助,但一半“是”和一半“否”熵的数据集将是1,这样的数据集适合学习。
3.2. 信息获取:
信息增益有助于算法决定应选择哪个属性作为决策节点或拆分数据哪个特征。 它是衡量拆分质量的指标。信息增益是通过拆分特定特征上的节点来实现的熵减少的度量。
构建决策树就是要找到一个返回最高信息增益的属性。具有高信息增益的特征是一个很好的拆分器,因为它将导致更纯的节点。信息增益的公式如下:
![]()
- E(家长):父项的熵
- 加权熵/信息 = {加权平均}*E(子)
- E(儿童): 子项熵
- IG: 信息获取
3.3 那么,熵和信息增益之间的关系是什么呢?
决策树算法的目标是在我们向下运行时最终解开标签,或者换句话说,在每个节点上产生可能标题的最纯粹分布。 在决策树中,熵和信息增益决定了在构造树的每一步中拆分节点的特征。选择信息增益最高的部分,因为这将导致熵和最纯节点的最显着减少。
信息增益越高,熵越低。 熵是不纯的量度。数据越不纯,不确定性就越大。通过减少数据的熵,我们使其更具体,从而获得更高的信息增益。
信息增益衡量通过拆分特定特征来减少多少数据熵。熵减少得越多,子节点就越均匀,分裂越好。
3.4. 基尼杂质/指数:
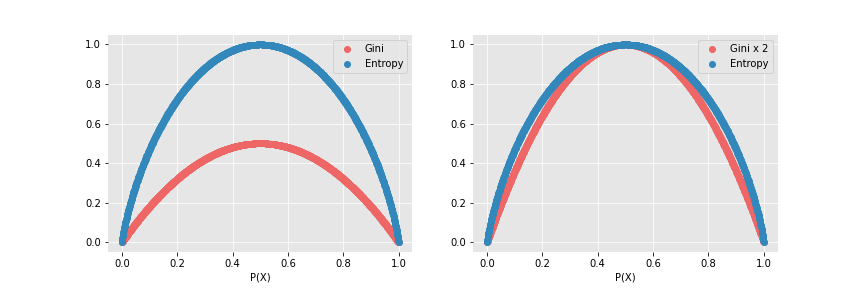
这是当数据包含多类标签时使用的误分类度量。基尼类似于熵,但它的计算速度比熵快得多。像CART(分类和回归树)这样的算法使用基尼作为杂质参数。
基尼指数的最小值为0,而基尼指数的最大值为0.5。
它比熵更快,计算成本更低,因为熵使用对数,但使用熵准则获得的结果略好。
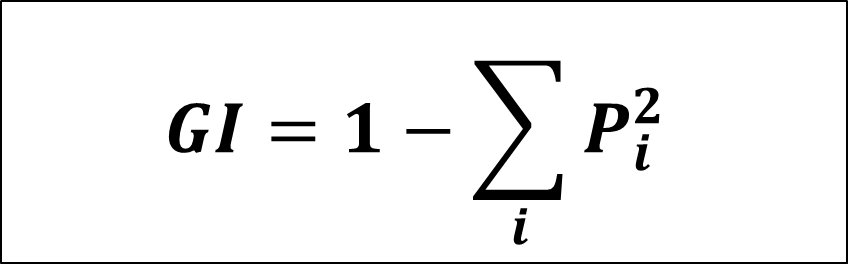
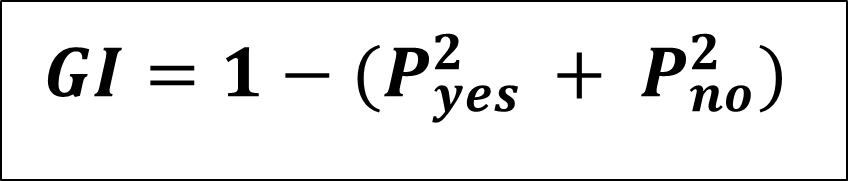
- p 是 = 是的概率
- p 否 = 否的概率
- p i = 类 i 的概率
四、决策树如何选择根节点并执行拆分?
数据集中的五列是前景、温度、湿度、风和游戏。播放列包含基于四个输入列的条件是否播放的结果。
4.1. 整个数据集的熵:
整个数据集的熵是指目标列的熵。在这里,我们的目标列是“播放”。
import pandas as pd
df = pd.read_csv('play_tennis.csv')
df = df.iloc[:,1:]
print(df)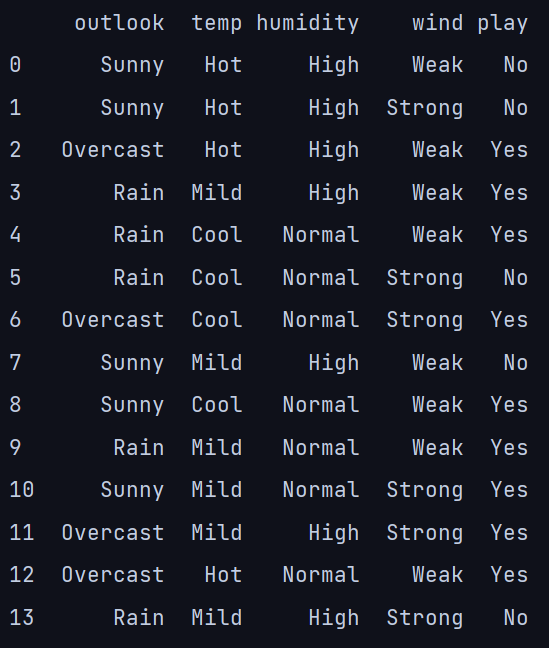

这里
9/14 = 否。样本空间中的是/总结果数
5/14 = 否。样本空间中无/总结果
4.2. 每列的信息增益:
由于有四个输入列,“展望”,“温度”,“湿度”和“风”,我们需要计算每列获得的信息。
展望列的信息增益如下:
print(df.groupby('outlook')['play'].value_counts())
在这里,我们可以看到,在我们的第一列展望中,有三个分类值:晴天、阴天和雨。
(a) 我们需要计算晴天、阴天和雨的熵:
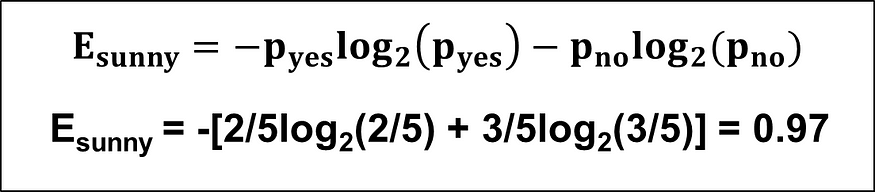
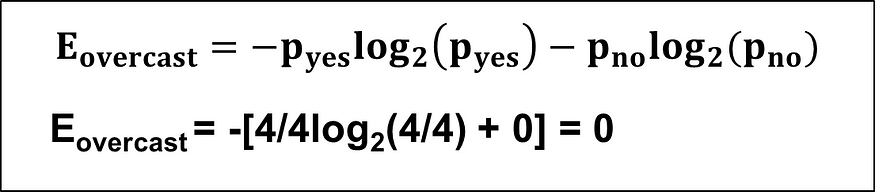


(c) 展望栏的信息增益:

(d) 其他栏目:温度、湿度和风力的信息增益如下:

选择信息增益最高的列作为根节点。 由于展望列具有最高的信息增益,因此它被视为根节点。
一旦它成功地将训练集一分为二,它就会使用相同的逻辑拆分子集,然后是子集,依此类推,递归,直到达到最大深度。
五、使用 sklearn 库的决策树含义:
- 在实现决策树分类器之前要记住的关键点之一是,即使在分类问题中,CART 算法也要求所有列都是数字。
- 这是因为,CART使用贪婪算法来构建决策树,并且它需要能够计算树中每个节点的杂质。
- 机器学习模型使用一种热编码技术将分类变量转换为数值,使用 sklearn 标签编码器可以轻松实现。
#imported the dataset:
import pandas as pd
df = pd.read_csv('play_tennis.csv')
df = df.iloc[:, 1:6]
print(df.head())
# performed one hot encoding: converted categorical to numerical columns
from sklearn.preprocessing import LabelEncoder
cols = ['outlook', 'temp', 'humidity', 'wind', 'play']
le = LabelEncoder()
def preprocess(df):
for col in cols:
df[col] = le.fit_transform(df[col])
return df
preprocess(df)
print(df.head())
#selected the input and target columns:
x = df.iloc[:, 0:4].values
y = df.iloc[:, 4]
#imported Decision Tree Classifier:
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
# trained the model:
dt.fit(x, y)
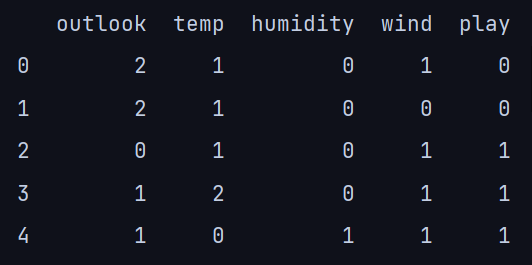
我们数据集的一个热编码
# visualization of decision tree:
from sklearn import tree
import graphviz
tree.plot_tree(dt, feature_names=cols, rounded=True, filled=True)5.1 决策树的可视化:
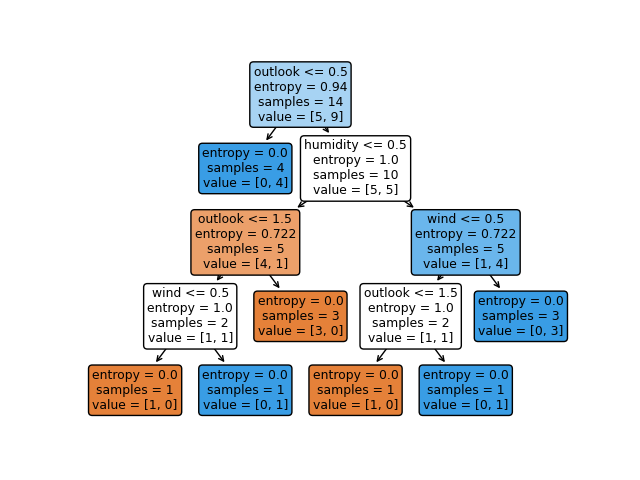
决策树
5.2、决策树的超参数
超参数是显式指定并控制训练过程的参数。它们在模型优化中起着至关重要的作用。
决策树分类器的一些最常见的超参数如下:
- max_depth:此超参数指定树的最大深度。更深的树将具有更多的拆分,并且能够捕获有关数据的更多信息,但它也可能更容易过度拟合。
- min_samples_split:此超参数指定拆分节点所需的最小样本数。较低的值将允许树拆分更多节点,这可能会导致更复杂的树。
- min_samples_leaf:此超参数指定叶节点中所需的最小样本数。较低的值将允许树具有更多的叶节点,这可以提高树的准确性。
- 标准: 此超参数指定可用于确定节点最佳拆分的拆分标准。最常见的标准是“基尼”和“熵”。
- 分配器: 此超参数指定将用于查找节点最佳拆分的拆分算法。最常见的拆分器是最佳、随机和均匀的。
六、决策树的缺点
决策树是一种强大的机器学习算法,可用于分类和回归任务。但是,它们也有一些缺点:
- 过拟合:决策树可能容易过度拟合,这意味着它们在训练数据中效果很好,但在测试集上则不然。
- 对数据微小变化的敏感性:数据中的微小变化会显著影响决策树的结构,从而导致过度拟合或不稳定。
- 可解释性:决策树可能具有挑战性,尤其是在大型且复杂的决策树中。这可能会使理解模型的工作原理并使用它来做出决策变得困难。
- 大型决策树的计算成本很高。
在这里,我添加一个 GitHub 链接,指向使用决策树算法执行的心脏病检测模型。姆林莫伊·博拉